

31. Программирование сервера базы данных.
Термин "сервер баз данных" обычно используют для обозначения всей СУБД, основанной на архитектуре "клиент-сервер", включая и серверную, и клиентскую части. Такие системы предназначены для хранения и обеспечения доступа к базам данных.
Хотя обычно одна база данных целиком хранится в одном узле сети и поддерживается одним сервером, серверы баз данных представляют собой простое и дешевое приближение к распределенным базам данных, поскольку общая база данных доступна для всех пользователей локальной сети.
Серверы баз данных, интерфейс которых основан исключительно на языке SQL, обладают своими преимуществами и своими недостатками. Очевидное преимущество - стандартность интерфейса. В пределе, хотя пока это не совсем так, клиентские части любой SQL-ориентированной СУБД могли бы работать с любым SQL-сервером вне зависимости от того, кто его произвел.
Преимущества протоколов удаленного вызова процедур
Упоминавшиеся выше протоколы удаленного вызова процедур особенно важны в системах управления базами данных, основанных на архитектуре "клиент-сервер".
Во-первых, использование механизма удаленных процедур позволяет действительно перераспределять функции между клиентской и серверной частями системы, поскольку в тексте программы удаленный вызов процедуры ничем не отличается от удаленного вызова, и следовательно, теоретически любой компонент системы может располагаться и на стороне сервера, и на стороне клиента.
Во-вторых, механизм удаленного вызова скрывает различия между взаимодействующими компьютерами. Физически неоднородная локальная сеть компьютеров приводится к логически однородной сети взаимодействующих программных компонентов. В результате пользователи не обязаны серьезно заботиться о разовой закупке совместимых серверов и рабочих станций.
Типичное разделение функций между клиентами и серверами
В типичном на сегодняшний день случае на стороне клиента СУБД работает только такое программное обеспечение, которое не имеет непосредственного доступа к базам данных, а обращается для этого к серверу с использованием языка SQL.
В некоторых случаях хотелось бы включить в состав клиентской части системы некоторые функции для работы с "локальным кэшем" базы данных, т.е. с той ее частью, которая интенсивно используется клиентской прикладной программой. В современной технологии это можно сделать только путем формального создания на стороне клиента локальной копии сервера базы данных и рассмотрения всей системы как набора взаимодействующих серверов.
32. Встроенный SQL.
При таком подходе операторы SQL встраиваются непосредственно в исходный текст программы на базовом языке. При компиляции программы со встроенными операторами SQL используется специальный препроцессор SQL, который преобразует исходный текст в исполняемую программу.
Особенности встроенного SQL
При объединении операторов SQL c базовым языком программирования должны соблюдаться следующие принципы:
Операторы SQL включаются непосредственно в текст программы на исходном языке программирования. Исходная программа поступает на вход препроцессора SQL, который компилирует операторы SQL.
Встроенные операторы SQL могут ссылаться на переменные базового языка программирования.
Встроенные операторы SQL получают результаты SQL-запросов с помощью переменных базового языка программирования.
Для присвоения неопределенных значений (NULL) атрибутам отношений БД используются специальные функции.
Для обеспечения построчной обработки результатов запросов во встроенный SQL добавляются несколько новых операторов, которые отсутствуют в интерактивном SQL.
Операторы манипулирования данными не требуют изменения для их встраивания в программный SQL. Однако оператор поиска (SELECT) потребовал изменений.
Стандартный оператор SELECT возвращает набор данных, релевантный сформированным условиям запроса. В интерактивном SQL этот полученный набор данных просто выводится на консоль пользователя и он может просмотреть полученные результаты. Встроенный оператор SELECT должен создавать структуры данных, которые согласуются с базовыми языками программирования. Во встроенном SQL запросы делятся на 2 типа:
Однострочные запросы, где ожидаемые результаты соответствуют одной строке данных. Эта строка может содержать значения нескольких столбцов.
Многострочные запросы, результатом которых является получение целого набора строк. При этом приложение должно иметь возможность проработать все полученные строки. Значит, должен существовать механизм, который поддерживает просмотр и обработку полученного набора строк.
32. Восстановление баз данных.
Меры преодоления проблем нарушения физической целостности:
В
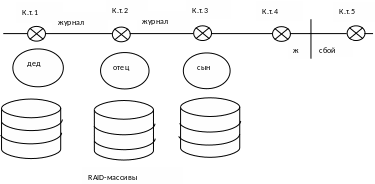 ведение
копии базы данных в
некоторый момент времени, называемый
контрольной точкой, производится копия.
Копия хранится на носителях, между
контрольными точками ведется журнал
изменений базы данных. Обычно используется
копия дед-отец-сын.
ведение
копии базы данных в
некоторый момент времени, называемый
контрольной точкой, производится копия.
Копия хранится на носителях, между
контрольными точками ведется журнал
изменений базы данных. Обычно используется
копия дед-отец-сын.
Рис.1
В 4 контрольной точке затирается дед, отец становится дедом, сын – отцом и появляется новый сын.
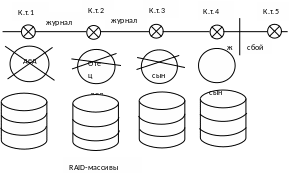
Рис.2
Пусть после 4 контрольной точки произошел сбой, тогда для восстановления базы данных осуществляется откат до 4 контрольной точки. Если копия не прочиталась, то откат осуществляется до следующей контрольной точки. Если копия прочиталась нормально, то осуществляется докат – выполнение всех операций, записанных в журнале изменений. Но изменение может произойти в момент копирования, и тогда будет несоответствие копий, в связи с этим копии делают во время перерывов.
Второй вариант решения проблемы нарушения физической целостности. В базе данных реальных изменений не происходит, все изменения фиксируются в журнале, а ночью происходят реальные изменения в базе данных.
Третий вариант предполагает наличие двух баз одновременно, с одной мы работаем, а изменения происходят в двух базах одновременно, если одна из баз данных выходит из строя, то мы работаем с другой.
34. Транзакции в базах данных.
Все операции, выполняемые с данными на SQL сервере, происходят в контексте транзакций. Транзакция - это групповая операция, т.е. набор действий с базой данных; самым существенным для этих действий является правило либо все, либо ни чего. Если во время выполнения данного набора действий, на каком-то этапе невозможно произвести очередное действие, то нужно выполнить возврат базы данных к начальному состоянию (произвести откат транзакции). Таким образом (при правильном планировании транзакций), обеспечивается целостность базы данных. В данном уроке объясняется, как начинать, управлять и завершать транзакции с помощью SQL выражений. А так же рассматривается вопрос об использовании транзакций в приложениях, созданных в Delphi. Вся приведенная информация касается InterBase.
SQL-выражения для управления транзакциями
Для управления транзакциями имеется три выражения:
SET TRANSACTION – начинает транзакцию и определяет ее поведение.
COMMIT – сохраняет изменения, внесенные транзакцией, в базе данных и завершает транзакцию.
ROLLBACK – отменяет изменения, внесенные транзакцией, и завершает транзакцию.
Запуск транзакции
В общем виде, синтаксис команды SQL для запуска транзакции:
SET TRANSACTION [Access mode] [Lock Resolution] [Isolation Level] [Table Reservation] Значения, принимаемые по-умолчанию: выражение SET TRANSACTION равносильно выражению
SET TRANSACTION READ WRITE WAIT ISOLATION LEVEL SNAPSHOT Access Mode - определяет тип доступа к данным. Может принимать два значения: READ ONLY - указывает, что транзакция может только читать данные и не может модифицировать их.
READ WRITE - указывает, что транзакция может читать и модифицировать данные.
Это значение принимается по умолчанию.
Пример: SET TRANSACTION READ WRITE
Isolation Level - определяет порядок взаимодействия данной транзакции с другими в данной базе. Может принимать значения:
SNAPSHOT - значение по умолчанию. Внутри транзакции будут доступны данные в том состоянии, в котором они находились на момент начала транзакции. Если по ходу дела в базе данных появились изменения, внесенные другими завершенными транзакциями, то данная транзакция их не увидит. При попытке модифицировать такие записи возникнет сообщение о конфликте.
SNAPSHOT TABLE STABILITY - предоставляет транзакции исключительный доступ к таблицам, которые она использует. Другие транзакции смогут только читать данные из них.
READ COMMITTED - позволяет транзакции видеть текущее состояние базы. Конфликты, связанные с блокировкой записей происходят в двух случаях: Транзакция пытается модифицировать запись, которая была изменена или удалена уже после ее старта. Транзакция типа READ COMMITTED может вносить изменения в записи, модифицированные другими транзакциями после их завершения. Транзакция пытается модифицировать таблицу, которая заблокирована другой транзакцией типа SNAPSHOT TABLE STABILITY.
Lock Resolution - определяет ход событий при обнаружении конфликта блокировки. Может принимать два значения:
WAIT - значение по умолчанию. Ожидает разблокировки требуемой записи. После этого пытается продолжить работу.
NO WAIT - немедленно возвращает ошибку блокировки записи.
Table Reservation - позволяет транзакции получить гарантированный доступ необходимого уровня к указанным таблицам. Существует четыре уровня доступа: PROTECTED READ - запрещает обновление таблицы другими транзакциями, но позволяет им выбирать данные из таблицы.
PROTECTED WRITE - запрещает обновление таблицы другими транзакциями, читать данные из таблицы могут только транзакции типа SNAPSHOT или READ COMMITTED.
SHARED READ - самый либеральный уровень. Читать могут все, модифицировать - транзакции READ WRITE.
SHARED WRITE - транзакции SNAPSHOT или READ COMMITTED READ WRITE могут модифицировать таблицу, остальные - только выбирать данные.
Завершение транзакции
Когда все действия, составляющие транзакцию успешно выполнены или возникла ошибка, транзакция должна быть завершена, для того, чтобы база данных находилась в непротиворечивом состоянии. Для этого есть два SQL-выражения:
COMMIT - сохраняет внесенные транзакцией изменения в базу данных. Это означает, что транзакция завершена успешно.
ROLLBACK - откат транзакции. Транзакция завершается и никаких изменений в базу данных не вносится. Данная операция выполняется при возникновении ошибки при выполнении операции (например, при невозможности обновить запись).
35. Хранилище данных и OLAP. Добыча данных.
Хранилище данных – очень большая предметно-ориентированная информационная корпоративная база данных, специально разработанная и предназначенная для подготовки отчётов, анализа бизнес-процессов с целью поддержки принятия решений в организации. Строится на базе клиент-серверной архитектуры, реляционной СУБД и утилит поддержки принятия решений. Данные, поступающие в хранилище данных, становятся доступны только для чтения. Данные из промышленной OLTP-системы копируются в хранилище данных таким образом, чтобы построение отчётов и OLAP-анализ не использовал ресурсы промышленной системы и не нарушал её стабильность. Данные загружаются в хранилище с определённой периодичностью, поэтому актуальность данных несколько отстает от OLTP-системы.
OLAP (англ. online analytical processing, аналитическая обработка в реальном времени) – технология обработки информации, включающая составление и динамическую публикацию отчётов и документов. Используется аналитиками для быстрой обработки сложных запросов к базе данных. Служит для подготовки бизнес-отчётов по продажам, маркетингу, в целях управления, т.н. data mining — добыча данных (способ анализа информации в базе данных с целью отыскания аномалий и трендов без выяснения смыслового значения записей).
Интеллектуальный анализ данных (англ. Data Mining) – это процесс обнаружения в сырых данных ранее неизвестных, нетривиальных, практически полезных и доступных интерпретации знаний, необходимых для принятия решений в различных сферах человеческой деятельности. Подразделяется на задачи классификации, моделирования и прогнозирования и другие.
Методы Data Mining разделяются на статистические (дескриптивный анализ, корреляционный и регрессионный анализ, факторный анализ, дисперсионный анализ, компонентный анализ, дискриминантный анализ, анализ временных рядов) и кибернетические (искусственные нейронные сети, эволюционное программирование, генетические алгоритмы, ассоциативная память, нечеткая логика, деревья решений, системы обработки экспертных знаний).
36. QBE – язык запросов к БД.
Реляционный язык QBE разработан М.М. Цлуфом в научно-исследовательской лаборатории фирмы IBM. QBE похож на SQL тем, что в своем первоначальном варианте обеспечивал только средства для запроса, тогда как в последующие версии были включены операции запоминания и многие другие возможности. Общий уровень языка сходен с уровнем языка SQL, хотя существуют некоторые операции запроса, возможные в QBE и не имеющие аналога в SQL или в каком-либо другом языке. Более очевидное различие между языками SQL и QBE в том, что последний разработан главным образом для работы с терминала (дисплея). Всякая операция в QBE специфицируется с помощью одной или нескольких таблиц; каждая такая таблица строится на экране дисплея частично системой, частично пользователем. Поскольку операции задаются в табличной форме, то QBE имеет двумерный синтаксис. Большинство традиционных языков, наоборот, имеют линейный синтаксис.
Операции выборки
Действительно значительной особенностью QBE является использование примеров для спецификации запросов (а также всех других операций, хотя все время мы рассматриваем только выборку). Основная идея состоит в том, что пользователь формирует запрос, занося пример возможного ответа в соответствующее место пустой таблицы. Например, рассмотрим запрос: «Получить номера поставщиков, находящихся в Париже». Первоначально система выдает на экран пользователю полностью пустую таблицу. Пользователь, знающий, что ответ на запрос находится в таблице Поставщики, запишет Поставщики в качестве имени таблицы; тогда система ответит заполнением соответствующих имен столбцов. Теперь пользователь может сформировать запрос, заполняя две позиции в таблице, как показано ниже.
Поставщики |
№поставщика |
Фамилия |
статус |
город |
Поставщики |
№поставщика |
фамилия |
статус |
город |
|
P.7 |
|
|
Париж |
«P» означает «печать» (print); эта литера указывает цель запроса, т. е. значения результата, которые должны быть выданы. 7 являются «элементом-примером», т. е. примером возможного ответа на запрос; элемент-пример выделяется подчеркиванием. Париж (не подчеркнуто) есть константа. Этот запрос может быть интерпретирован следующим образом: «Напечатать все №поставщиков, такие, как, скажем, 7, для которых соответствующий город — Париж ». Отметим, что в результирующем множестве или даже в исходном множестве не обязательно должно находиться именно 7 — элемент-пример является полностью произвольным, и мы могли бы с равным успехом использовать PIG или X, не изменяя смысла запроса.
Элементы-примеры используются для установления связей между строками в более сложных запросах. Если же связи не нужны, как в простом запросе, приведенном выше, то можно полностью опустить элементы-примеры (так, что Р. 7 сократилось бы до «Р»), однако в общем случае для ясности мы будем их включать.
Простая выборка. Получить номера всех поставляемых деталей.
|
№детали |
количество |
|
Р.2 |
|
 Поставки
№поставщика
Поставки
№поставщика
По желанию пользователь может специфицировать возрастающее или убывающее упорядочение результата. Избыточные повторяющиеся значения всегда исключаются.
Простая выборка. Получить полные данные о всех поставщиках.
Поставщики |
№поставщика |
Фамилия |
статус |
Город |
|
Р.х |
Р.фамилия |
Р.статус |
Р.город |
Сокращенное представление того же запроса
Поставщики |
№поставщика |
Фамилия |
статус |
Город |
Р. |
|
|
|
|
Здесь оператор печати относится ко всей строке.
Выборка по условию. Получить номера поставщиков, находящихся в Париже и имеющих статус >20.
Поставщики |
№поставщика |
Фамилия |
статус |
Город |
|
P.х |
|
>20 |
Париж |
Обратите внимание, как задается условие «>20». Вообще, таким же образом может быть использован любой из операторов сравнения =, <>, <, <=, =>, > (исключение; = обычно опускается, как в столбце город приведенной выше таблицы)
Выборка по условию. Перечислить номера поставщиков, находящихся в Париже или имеющих статус >20 (или удовлетворяющих и тому и другому условию).
Поставщики |
№поставщика |
фамилия |
статус |
город |
|
P.X |
|
|
Париж |
|
P.Y |
|
>20 |
|
Условия, заданные в одной строке, рассматриваются как операнды операции «И». Для «ИЛИ», следовательно, оба условия необходимо задавать в разных строках.
В сформулированном выше запросе фактически затребовано объединение всех номеров поставщиков, находящихся в Париже, и всех номеров поставщиков со статусом >20. Необходимо два разных элемента-примера, потому что, если бы мы дважды использовали тот же самый, это бы означало, что один и тот же поставщик должен быть в Париже и иметь статус >20. Когда запрос содержит более чем одну строку, как в данном примере, их можно располагать в любом порядке.
Выборка по условию. Получить номера тех поставщиков, которые поставляют деталь 1 и деталь 2.
Поставки |
№поставщиков |
№деталей |
количество |
|
P.х |
1 |
|
|
х |
2 |
|
Здесь один и тот же элемент пример должен использоваться дважды; чтобы сформулировать запрос, нам необходимо две строки, так как нужно соединить операцией «И» два условия в одном и том же столбце.
Выборка с использованием связи. Получить имена поставщиков, поставляющих деталь 2.
Поставщики |
№поставщика |
Фамилия |
статус |
город |
|
х |
P.фамилия |
|
|
Поставки |
№поставщика |
№детали |
Количество |
|
х |
2 |
|
Элемент-пример №X используется как связь между таблицами Поставщики и Поставки. Вообще говоря, такие связи используются в языке QBE там, где в языке SQL требуется вложенное отображение, а в реляционной алгебре—операция JOIN. (На самом деле №х в предыдущем примере также выполняло роль связи, но только связываемые строки находились в одной и той же таблице.)
Выборка с использованием отрицания. Получить имена тех поставщиков, которые не поставляют деталь 2.
Поставщики |
№поставщика |
фамилия |
статус |
город |
|
Х |
Р.фамилия |
|
|
Поставки |
№поставщика |
№детали |
количество |
|
Х |
2 |
|
Обратите внимание на оператор NOT ( ) в строке таблицы Поставки. Запрос может быть интерпретирован следующим образом: «Напечатать имена таких поставщиков с номерами X, чтобы ни один поставщик X не поставлял деталь 2».
Выборка из нескольких таблиц. Для каждой поставляемой детали получить номер детали и название города, из которого она поставляется.
Результат этого запроса не является проекцией существующей таблицы, скорее, это есть проекция соединения двух существующих таблиц. Для того чтобы сформулировать такой запрос на языке QBE, пользователь должен сначала построить остов таблицы ожидаемого результата (т. е. таблицу с соответствующим количеством столбцов). Этой таблице и ее столбцам могут быть даны любые имена, какие только желает пользователь – они могут быть даже оставлены пустыми. Пользователь затем может сформулировать запрос, используя таблицу «результат» и две существующие таблицы так, как показано ниже.
Поставщики
№поставщика
фамилия
статус
город
Х
Г
|
Поставки |
№поставщика |
№детали |
количество |
||
|---|---|---|---|---|---|---|
|
|
Х |
Х |
|
||
Результат |
№детали |
город |
||||
|
Р.Х |
Р.Г |
||||
Выборка, включающая ALL. Получить номера поставщиков, поставляющих все детали.
Поставки |
№поставщика |
№детали |
количество |
|
Р.Х |
ALL.Х |
|
Детали |
№детали |
название |
цвет |
вес |
город |
|
ALL.Х |
|
|
|
|
Выражение ALL. Х в таблице Детали относится ко всем номерам деталей, содержащимся в этой таблице. Выражение ALL.X в таблице Поставки относится ко всем номерам деталей, поставляемых поставщиком X. Так как эти выражения идентичны, то X должен быть поставщиком, который поставляет все детали. Между прочим, если столбец слишком узок для выражения, скажем, ALL.X, которое пользователь хочет в него записать, то система позволяет пользователю предварительно увеличить ширину столбца. Таким образом, каждая строка запроса может содержаться в одной строке экрана.
Операции запоминания
Простое обновление. Поменять цвет всех красных деталей на желтый.
Детали |
№детали |
название |
цвет |
вес |
город |
|
2 |
|
красный |
|
|
UPDATE. |
2 |
|
желтый |
|
|
Для того чтобы обновить строку или множество строк, пользователь (в общем случае) записывает выражение, представляющее старые данные, и выражение, представляющее новые данные. Слово UPDATE указывает, какое из двух выражений соответствует новым данным. Следовательно, в примере, приведенном выше, первая строка указывает, что любая строка таблицы, скажем, относящаяся к детали 2 и содержащая значение цвета 'красный', должна быть изменена и иметь значение цвета 'желтый’. Заметим, что и «старые» и «новые» строки должны содержать запись в позиции первичного ключа. Значения первичного ключа не могут быть изменены.
Некоторые обновления могут быть заданы одним выражением (строкой). Например: изменить цвет детали 2 на желтый независимо от того, какой цвет она имела. Пользователю необходимо записать лишь «новую» строку из двух, рассмотренных выше (и без подчеркивания 2).
Включение (INSERTION). Занести данные о детали Р7 (наименование болт, цвет серый, вес 2, город Лондон) в таблицу Р.
Р |
№поставщика |
название |
цвет |
вес |
город |
INSERT. |
Р7 |
болт |
серый |
2 |
Лондон |
Включение (INSERTION). Занести данные о детали Р7 (наименование болт, цвет серый, вес 2, город Лондон) в таблицу Р.
Р |
№поставщика |
название |
цвет |
вес |
город |
INSERT. |
Р7 |
болт |
серый |
2 |
Лондон |
Библиотечные функции
Простая выборка с использованием функции. Получить значение общего количества поставщиков.
Поставщики |
№ |
фамилия |
статус |
город |
|
Р.COUNT.ALL.SX |
|
|
|
8.5.2. Простая выборка с использованием функции. Получить значение общего количества поставщиков, поставляющих детали в настоящее время.
поставки |
№поставщика |
№детали |
количество |
|
Р.COUNT.U.ALL.SX |
|
|
«U.» означает уникальный (ALL автоматически не исключает избыточные повторяющиеся данные).
Выборка по условию с использованием функции. Получить значение общего количества поставщиков детали Р2.
Поставки |
№поставщиков |
№детали |
количество |
|
P.COUNT.ALL.SX |
Р2 |
|
Выборка по условию с использованием функции. Получить значение общего количества поставок детали Р2.
Поставки |
№поставщика |
№детали |
количество |
|
|
Р2 |
P.SUM.ALL.Q |
Выборка с группированием. Для каждой поставляемой детали получить номер детали и значение количества поставщиков этой детали.
Поставки |
№поставщика |
№детали |
количество |
|
Р.COUNT.ALL.SX |
Р.РХ |
|
Заметьте, что явного задания оператора группирования не требуется. Оператор ALL автоматически обеспечивает желаемый эффект, так как в этом запросе, например, выражение ALL.SX означает множество всех номеров поставщиков, соответствующее РХ.
Выборка по условию с использованием блока условия и функции. Получить номера всех деталей, которые поставляются более чем одним поставщиком.
Поставщики |
№поставщика |
№детали |
количество |
|
ALL.SX |
P.PX |
|
-
Блок условия
COUNT.ALL.SX >1
Пользователю языком QBE предоставлена свободе построения запроса тем способом, который кажется пользователю наиболее естественным. Действительно, запрос может быть построен в том порядке, который нравится пользователю: порядок строк в таблице запроса совершенно безразличен. Более того, порядок, в котором пользователь заносит записи, составляющие эти строки, также совершенно произволен.
37. Современные СУБД: Access, MS SQL Server, SQLite.
Microsoft Access – реляционная СУБД корпорации Microsoft. Имеет широкий спектр функций, включая связанные запросы, связь с внешними таблицами и базами данных. Благодаря встроенному языку VBA, в самом Access можно писать приложения, работающие с базами данных.
Основные компоненты MS Access:
построитель таблиц;
построитель экранных форм;
построитель SQL-запросов (язык SQL в MS Access не соответствует стандарту ANSI);
построитель отчётов, выводимых на печать.
Они могут вызывать скрипты на языке VBA, поэтому MS Access позволяет разрабатывать приложения и БД практически «с нуля» или написать оболочку для внешней БД.
MS Access является файл-серверной СУБД и потому применима лишь к маленьким приложениям. Отсутствует ряд механизмов, необходимых в многопользовательских БД, таких, например, как триггеры.
Существенно расширяет возможности MS Access по написанию приложений механизм связи с различными внешними СУБД: "связанные таблицы" (связь с таблицей СУБД) и "запросы к серверу" (запрос на диалекте SQL, который "понимает" СУБД). Также MS Access позволяет строить полноценные клиент-серверные приложения на СУБД MS SQL Server. При этом имеется возможность совместить с присущей MS Access простотой инструменты для управления БД и средства разработки.
Microsoft SQL Server – система управления реляционными базами данных (СУБД), разработанная корпорацией Microsoft. Основной используемый язык запросов — Transact-SQL, создан совместно Microsoft и Sybase. Transact-SQL является реализацией стандарта ANSI/ISO по структурированному языку запросов (SQL) с расширениями. Используется для работы с базами данных размером от персональных до крупных баз данных масштаба предприятия.
Для обеспечения доступа к данным Microsoft SQL Server поддерживает Open Database Connectivity (ODBC) – интерфейс взаимодействия приложений с СУБД. Версия SQL Server 2005 обеспечивает возможность подключения пользователей через веб-сервисы, использующие протокол SOAP. Это позволяет клиентским программам, не предназначенным для Windows, кроссплатформенно соединяться с SQL Server. Компания Microsoft также выпустила сертифицированный драйвер JDBC, позволяющий приложениям под управлением Java (таким как BEA и IBM WebSphere) соединяться с Microsoft SQL Server 2000 и 2005.
Также SQL Server поддерживает зеркалирование и кластеризацию баз данных. Кластер сервера SQL — это совокупность одинаково конфигурированных серверов; такая схема помогает распределить рабочую нагрузку между несколькими серверами. Все сервера имеют одно виртуальное имя, и данные распределяются по IP-адресам машин кластера в течение рабочего цикла. Также в случае отказа или сбоя на одном из серверов кластера доступен автоматический перенос нагрузки на другой сервер.
SQLite – это реляционная база данных, запросы к которой можно осуществлять при помощи языка запросов SQL. База данных не поддерживает все особенности SQL и уступает в функциональности другим развитым СУБД, но вполне подходит для хранения и извлечения информации.
Классические СУБД, такие как MySQL (а так же MS SQL, Oracle, PostgreeSQL) состоят из отдельного сервера, поддерживающего работу базы данных и прослушивающих определённый порт, на предмет обращения клиентов. В качестве клиента может выступать в том числе и расширение PHP, реализующего интерфейс, с помощью которого осуществляются запросы к базе. Движок SQLite и интерфейс к ней реализованы в одной библиотеке, что увеличивает скорость выполнения запросов. Такой сервер часто называют встроенным.
Особенности SQLite
SQLite является бестиповой базой данных. Точнее, есть только два типа – целочисленный "integer" и текстовый "text". Причём "integer" используется преимущественно для первичного ключа таблицы, а для остальных данных пойдёт "text". Длина строки, записываемой в текстовое поле, может быть любой.
Все базы данных хранятся в файлах, по одному файлу на базу. Количество баз данных, а так же таблиц в них, ограниченно только свободным местом, имеющимся на сайте. А максимально возможный объём одной базы данных составляет 2 Тб.
Так как все данные хранятся в файлах, проблем с переносом базы данных с одного хостинга на другой не существует – достаточно лишь скопировать соответствующие файлы.
38. Современные СУБД: PostgreSQL, MySQL, Cashé.
PostgreSQL - кросс-платформенная свободная объектно-реляционная система управления базами данных (СУБД).
Основные особенности PostgreSQL:
- поддержка БД практически неограниченного размера;
- мощные и надежные механизмы транзакций и репликации;
- расширяемая система встроенных языков программирования:
- легко расширяемая система типов.
MySQL – свободная система управления базами данных (СУБД). Распространяется под GNU General Public License или под собственной коммерческой лицензией. Помимо этого разработчики создают функциональность по заказу лицензионных пользователей, именно благодаря такому заказу почти в самых ранних версиях появился механизм репликации.
MySQL является решением для малых и средних приложений. Входит в состав серверов WAMP, LAMP и в портативные сборки серверов Денвер, XAMPP. Обычно MySQL используется в качестве сервера, к которому обращаются локальные или удалённые клиенты, однако в дистрибутив входит библиотека внутреннего сервера, позволяющая включать MySQL в автономные программы.
Гибкость СУБД MySQL обеспечивается поддержкой большого количества типов таблиц: пользователи могут выбрать как таблицы типа MyISAM, поддерживающие полнотекстовый поиск, так и таблицы InnoDB, поддерживающие транзакции на уровне отдельных записей. Более того, СУБД MySQL поставляется со специальным типом таблиц EXAMPLE, демонстрирующим принципы создания новых типов таблиц. Благодаря открытой архитектуре и GPL-лицензированию, в СУБД MySQL постоянно появляются новые типы таблиц.
Cache’ – промышленная СУБД, интегрированная с технологией разработки веб-приложений. Единая архитектура данных Caché позволяет разработчикам использовать объектный, реляционный и прямой доступ к одним и тем же данным, хранение которых обеспечивается ориентированным на транзакции многомерным ядром СУБД.
Отличительной особенностью СУБД Cache является независимость хранения данных от способа их представления. Это реализуется с помощью так называемой единой архитектуры данных Cache . В рамках данной архитектуры существует единое описание объектов и таблиц, отображаемых непосредственно в многомерные структуры ядра базы данных, ориентированного на обработку транзакций. Как только определяется класс объектов, Cache автоматически генерирует реляционное представление данных этого класса. Подобным же образом, как только в Словарь данных поступает DDL-описание на языке SQL, Cache автоматически генерирует реляционное и объектное описание данных. При этом все описания ведутся согласованно, но все операции по редактированию проводятся только с одним описанием данных. Это позволяет сократить время разработки. Одновременно улучшается совместимость со старыми SQL-ориентированными приложениями.
На рисунке представлена архитектура Cache.
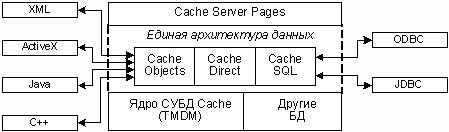 Основные
компоненты СУБД Cache:
Основные
компоненты СУБД Cache:
TMDM. Многомерное ядро системы, ориентированное на работу с транзакциями.
Сервер Cache Objects. Представление многомерных структур данных ядра системы в виде объектов, инкапсулирующих как данные, так и методы их обработки.
Сервер Cache SQL. Представление многомерных структур данных в виде реляционных таблиц.
Сервер прямого доступа (Cache Direct). Предоставление прямого доступа к многомерным структурам данных ядра системы.