

Лекция 9. Организация памяти вычислительных систем
память, uma, sun enterprise 10000, smp, numa, dsm, coma

Системы с общей и распределенной памятью
Особенность ВС – множество параллельно работающих процессоров. Важная задача – задача организации памяти.
Две проблемы: 1) Различие между быстродействием процессора и памяти (как и в однопроцессорных системах); 2) Одновременный доступ к памяти нескольких процессоров.
В зависимости от организации памяти различают:
ВС с общей памятью (shared memory, мультипроцессоры, сильно связанные, closely coupled systems);
ВС с распределенной памятью (distributed memory, слабо связанные, loosely coupled systems, мультикомпьютеры).
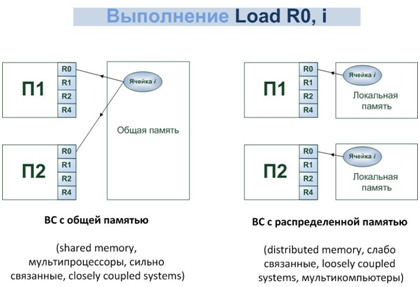
Различие между общей и распределенной памятью - это разница в структуре виртуальной памяти, то есть в том, как память выгладит со стороны процессора. Физически почти каждая система памяти разделена на автономные компоненты, доступ к которым может производиться независимо. Общую память от распределенной отличает то, каким образом подсистема памяти интерпретирует поступивший от процессора адрес ячейки. Для примера положим, что процессор выполняет команду LoadR0,i, означающую «Загрузить регистр R0 содержимым ячейки i». В случае общей памяти i - это глобальный адрес, и для любого процессора указывает на одну и ту же ячейку. В распределенной системе памяти i - это локальный адрес. Если два процессора выполняют команду LoadR0,i, то каждый из них обращается к i-й ячейке в своей локальной памяти, то есть к разным ячейкам, и в регистры R0 могут быть загружены неодинаковые значения.
Различие между двумя системами памяти должно учитываться программистом, поскольку оно определяет способ взаимодействия частей распараллеленной программы.
Мультипроцессоры сложно строить, но легко программировать. Мультикомпьютеры легко строить, но сложно программировать.
Поэтому стали предприниматься попытки создания гибридных систем, которые относительно легко конструировать и относительно легко программировать. Это привело к осознанию того, что совместную память можно реализовывать по-разному, и в каждом случае будут какие-то преимущества и недостатки.
Практически все исследования в области архитектур с параллельной обработкой направлены на создание гибридных форм, которые сочетают в себе преимущества обеих архитектур. Здесь важно получить такую систему, которая расширяема, то есть которая будет продолжать исправно работать при добавлении все новых и новых процессоров. Рассмотрим многоуровневую организацию общей памяти.
Многоуровневая организация общей памяти
Современные компьютерные системы не монолитны, а состоят из ряда уровней. Это дает возможность реализовать общую память на любом из нескольких уровней.
1) Общая память реализована на аппаратном обеспечении.
Одна копия операционной системы с одной таблицей распределения памяти. Для ОС память монолитна.
2) Общая память реализована на основе ос и аппаратного обеспечения.
Такой подход называется DSM (Distributed Shared Memory — распределенная совместно используемая память). Каждая машина содержит свою собственную виртуальную память и собственные таблицы страниц. По существу, операционная система просто
вызывает недостающие страницы не с диска, а из памяти. Но у пользователя создается впечатление, что машина содержит общую разделенную память.
3) Реализация общей разделенной памяти на уровне программного обеспечения.
При таком подходе абстракцию разделенной памяти создает язык программирования, и эта абстракция реализуется компилятором. Например, модель Linda основана на абстракции разделенного пространства кортежей (записей данных, содержащих наборы полей).
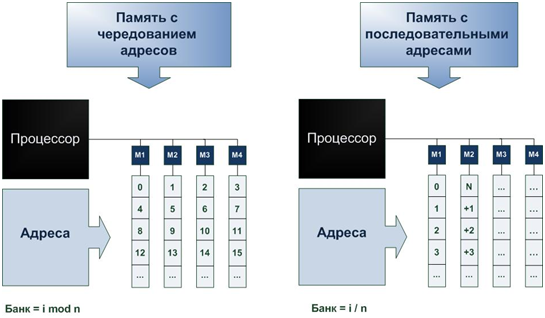
Память с чередованием адресов
Физически память вычислительной системы состоит из нескольких модулей (банков), при этом существенным вопросом является то, как в этом случае распределено адресное пространство (набор всех адресов, которые может сформировать процессор). Один из способов распределения виртуальных адресов по модулям памяти состоит в разбиении адресного пространства на последовательные блоки. Если память состоит изn банков, то ячейка с адресом i при поблочном разбиении будет находиться в банке с номером i/n. В системе памяти с чередованием адресов (interleaved memory) последовательные адреса располагаются в различных банках: ячейка с адресом i находится в банке с номером i mod n. Пусть, например, память состоит из четырех банков, по 256 байт в каждом. В схеме, ориентированной на блочную адресацию, первому банку будут выделены виртуальные адреса 0-255, второму - 256-511 и т. д. В схеме с чередованием адресов последовательные ячейки в первом банке будут иметь виртуальные адреса 0, 4, 8, … во втором банке — 1, 5, 9 и т. д.
Распределение адресного пространства по модулям дает возможность одновременной обработки запросов на доступ к памяти, если соответствующие адреса относятся к разным банкам. Процессор может в одном из циклов затребовать доступ к ячейкеi, а в следующем цикле - к ячейке j. Еслиi и j находятся в разных банках, информация будет передана в последовательных циклах. Здесь под циклом понимается цикл процессора, в то время как полный цикл памяти занимает несколько циклов процессора. Таким образом, в данном случае процессор не должен ждать, пока будет завершен полный цикл обращения к ячейкеi. Рассмотренный прием позволяет повысить пропускную способность: если система памяти состоит из достаточного числа банков, имеется возможность обмена информацией между процессором и памятью со скоростью одно слово за цикл процессора, независимо от длительности цикла памяти.
Решение о том, какой вариант распределения адресов выбрать (поблочный или с расслоением), зависит от ожидаемого порядка доступа к информации. Программы компилируются так, что последовательные команды располагаются в ячейках с последовательными адресами, поэтому высока вероятность, что после команды, извлеченной из ячейки с адресом i, будет выполняться команда из ячейки i +1. Элементы векторов компилятор также помещает в последовательные ячейки, поэтому в операциях с векторами можно использовать преимущества метода чередования. По этой причине в векторных процессорах обычно применяется какой-либо вариант чередования адресов. В мультипроцессорах с совместно используемой памятью, тем не менее, используется поблочная адресация, поскольку схемы обращения к памяти в MIMD-системах могут сильно различаться. В таких системах целью является соединить процессор с блоком памяти и задействовать максимум находящейся в нем информации, прежде чем переключиться на другой блок памяти.
Симметричные (SMP) многопроцессорные ВС. Архитектура типа UMA, COMA, NUMA
Мультипроцессор, как и все компьютеры, должен содержать устройства ввода-вывода (диски, сетевые адаптеры и т. п.). В одних мультипроцессорных системах только определенные процессоры имеют доступ к устройствам ввода-вывода и, следовательно, имеют специальную функцию ввода-вывода. В других мультипроцессорных системах каждый процессор имеет доступ к любому устройству ввода-вывода. Если все процессоры имеют равный доступ ко всем модулям памяти и всем устройствам ввода-вывода и каждый процессор взаимозаменим с другими процессорами, то такая система называется SMP (Symmetric Multiprocessor — симметричный мультипроцессор).
В системах с общей памятью все процессоры имеют равные возможности по доступу к единому адресному пространству. Единая память может быть построена как одноблочная или по модульному принципу, но обычно практикуется второй вариант.
Вычислительные системы с общей памятью, где доступ любого процессора к памяти производится единообразно и занимает одинаковое время, называют системами с однородным доступом к памяти и обозначают аббревиатурой UMA (Uniform Memory Access). Это наиболее распространенная архитектура памяти параллельных ВС с общей памятью.
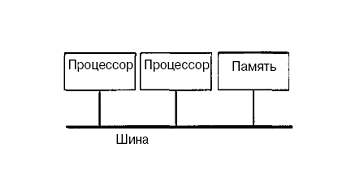
Технически UMA-системы предполагают наличие узла, соединяющего каждый изn процессоров с каждым изт модулей памяти. Простейший путь построения таких ВС - объединение нескольких процессоров (P) с единой памятью (Mp) посредством общей шины (рис.). В этом случае, однако, в каждый момент времени обмен по шине может вести только один из процессоров, то есть процессоры должны соперничать за доступ к шине. Когда процессор Рi, выбирает из памяти команду, остальные процессорыPj (i<> j) должны ожидать, пока шина освободится. Если в систему входят только два процессора, они в состоянии работать с производительностью, близкой к максимальной, поскольку их доступ к шине можно чередовать; пока один процессор декодирует и выполняет команду, другой вправе использовать шину для выборки из памяти следующей команды. Однако когда добавляется третий процессор, производительность начинает падать.

При наличии на шине десяти процессоров, кривая быстродействия шины становится горизонтальной, так что добавление 11-го процессора уже не дает повышения производительности. Нижняя кривая на рисунке иллюстрирует тот факт, что память и шина обладают фиксированной пропускной способностью, определяемой комбинацией длительности цикла памяти и протоколом шины, и в многопроцессорной системе с общей шиной эта пропускная способность распределена между несколькими процессорами. Если длительность цикла процессора больше по сравнению с циклом памяти, к шине можно подключать много процессоров. Однако фактически процессор обычно намного быстрее памяти, поэтому данная схема широкого применения не находит.
Архитектура UMA
Можно оптимизировать архитектуру UMA, добавляя локальный кэш и локальную память к каждому из процессоров.
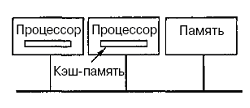
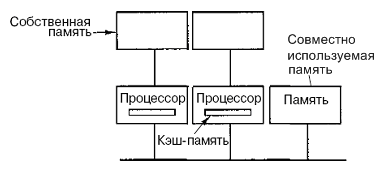
Чтобы оптимально использовать последнюю конфигурацию, компилятор должен поместить в локальные модули памяти весь текст программы, цепочки, константы, другие данные, предназначенные только для чтения, стеки и локальные переменные. Общая разделенная память используется только для общих переменных. В большинстве случаев такое разумное размещение сильно сокращает количество данных, передаваемых по шине, и не требует активного вмешательства со стороны компилятора.
Мультипроцессоры UMA с координатными коммутаторами
Даже при всех возможных оптимизациях использование только одной шины ограничивает размер мультипроцессора UMA до 16 или 32 процессоров. Чтобы получить больший размер, требуется другой тип коммуникационной сети. Самая простая схема соединения n процессоров с к блоками памяти — координатный коммутатор (рис). Координатные коммутаторы используются на протяжении многих десятилетий для соединения группы входящих линий с рядом выходящих линий произвольным образом.
Координатный коммутатор представляет собой неблокируемую сеть. Это значит, что процессор всегда будет связан с нужным блоком памяти, даже если какая-то линия или узел уже заняты. Более того, никакого предварительного планирования не требуется.
Недостаток системы: рост узлов как n2. При наличии 1000 процессоров и 1000 модулей памяти получаем число узлов – 1 млн. Это неприемлемо. Тем не менее координатные коммутаторы вполне применимы для систем средних размеров.
Мультипроцессоры UMA с многоступенчатымисетями
В основе подхода – коммутатор 2x2. Этот коммутатор содержит два входа и два выхода. Сообщения, приходящие на любую из входных линий, могут переключаться на любую выходную линию. В нашем примере сообщения будут содержать до четырех частей.
Поле Модуль сообщает, какую память использовать. Поле Адрес определяет адрес в этом модуле памяти. В поле Код операции содержится операция, например READ или WRITE. Наконец, дополнительное поле Значение может содержать операнд, например 32-битное слово, которое нужно записать при выполнении операции WRITE. Коммутатор исследует поле Модуль и использует его для определения, через какую выходную линию нужно отправить сообщение: через X или через Y.
Наши коммутаторы 2x2 можно компоновать различными способами и получать многоступенчатые сети.
Один из возможных вариантов — сеть omega. Здесь мы соединили 8 процессоров с 8 модулями памяти, используя 12 коммутаторов. Для n процессоров и n модулей памяти нам понадобится log2n ступеней, n/2 коммутаторов на каждую ступень, то есть всего (n/2)log2n коммутаторов, что намного лучше, чем n2 узлов (точек пересечения), особенно для больших n.
Каждая ступень для передачи сигнала в соответствующем направлении использует биты в поле Модуль (0 – верхний выход, 1 – нижний). При этом после прохождения ступени соответствующие биты становятся не нужны и они заменяются на номер входной линии. Рассматривая пути a и b (на рис.), видим, что они используют разные коммутаторы, следовательно, запросы могут выполняться параллельно.
В отличие от координатного коммутатора, сеть omega — это блокируемая сеть. Не всякий набор запросов может передаваться одновременно. Конфликты могут возникать при использовании одного и того же провода или одного и того же коммутатора, а также между запросами, направленными к памяти, и ответами, исходящими из памяти.


