

6.4. Классификация наблюдений в случае двух генеральных совокупностей, имеющих известные многомерные нормальные распределения
Теперь
мы используем общий метод, описанный
выше, для случая двух многомерных
нормальных генеральных совокупностей
с равными ковариационными матрицами,
а именно для совокупностей с законами
распределения N(![]() )
и N(
)
и N(![]() ),
где
),
где![]() — вектор среднего значенияi-ой
генеральной
совокупности (i=1,2),
a
— вектор среднего значенияi-ой
генеральной
совокупности (i=1,2),
a
![]() — ковариационная матрица каждой
совокупности. [Этот метод впервые
был использован Валь дом [1]. Тогдаi-я
плотность
распределения вероятностей будет равна
— ковариационная матрица каждой
совокупности. [Этот метод впервые
был использован Валь дом [1]. Тогдаi-я
плотность
распределения вероятностей будет равна
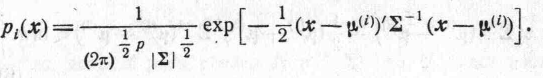
Отношение плотностей равно
 (2)
(2)
Область
![]() ,
при попадании в которую наблюдение
классифицируется как наблюдение над
,
при попадании в которую наблюдение
классифицируется как наблюдение над![]() ,
является
множеством векторов x,
для
которых величина (2) больше k
(k
выбирается
подходящим образом). Так как логарифмическая
функция монотонно возрастает, то
неравенство (2) эквивалентно неравенству
(получающемуся из (2) переходом к
логарифмам)
,
является
множеством векторов x,
для
которых величина (2) больше k
(k
выбирается
подходящим образом). Так как логарифмическая
функция монотонно возрастает, то
неравенство (2) эквивалентно неравенству
(получающемуся из (2) переходом к
логарифмам)
![]() (3)
(3)
Левую часть (3) можно представить в виде
![]()
(4)
Группируя соответствующие члены, получаем
![]() .
(5)
.
(5)
Первый член является хорошо известной дискриминантной функцией. Это линейная функция компонент вектора результатов наблюдений.
Следующая теорема является прямым следствием теоремы 6.3.1.
Теорема
6.4.1. Если
![]() имеет
плотность распределения вероятностей
(1)
(i=1,2),
то
области наилучшей классификации
определяются следующим образом:
имеет
плотность распределения вероятностей
(1)
(i=1,2),
то
области наилучшей классификации
определяются следующим образом:
 (6)
(6)
Если
априорные вероятности q1
и q![]() известны, то k
равно
известны, то k
равно
![]() (7)
(7)
В
частном случае двух равновероятных
генеральных совокупностей, которым
соответствуют одинаковые цены С(1|2) и
C(2|l),
k=1
и
lnk
= 0. Поэтому область, при попадании в
которую выборка рассматривается как
выборка из
![]() ,
определяется следующим образом:
,
определяется следующим образом:
![]() (8)
(8)
Если нам неизвестны априорные вероятности, то мы можем выбрать In k = с, например, из условия, чтобы математические ожидания потерь, связанных с ошибками классификации, были равны. Пусть X—случайное наблюдение. Нам нужно найти распределение случайной величины
![]() (9)
считая сначала, что X
распределен
N(
(9)
считая сначала, что X
распределен
N(![]() ,
,![]() ),
а затем что X
распределен
N(
),
а затем что X
распределен
N(![]() ,
,
![]() ).
ЕслиX
распределен
N(
).
ЕслиX
распределен
N(![]() ,
,![]() ),
то величина U
распределена
нормально с математическим ожиданием
),
то величина U
распределена
нормально с математическим ожиданием
 (10)
(10)
и дисперсией
![]() (11)
(11)
Будем
называть «расстоянием» между N(![]() ,
,![]() )
и N(
)
и N(![]() (2),
(2),
![]() )
величину
)
величину
![]() . (12)
. (12)
Тогда,
если X
распределен
N(![]() ,
,
![]() ),
то U
будет
распределена N(
),
то U
будет
распределена N(![]() ).
Если же X
распределен N(
).
Если же X
распределен N(![]() (2),
(2),
![]() ),
то
),
то
 (13)
(13)
Дисперсия
U
будет такой же, как и в случае, когда X
распределен
![]() ,
поскольку она зависит лишь отмоментов
второго порядка случайного вектора
X.
Таким
образом, U
будет
распределен
,
поскольку она зависит лишь отмоментов
второго порядка случайного вектора
X.
Таким
образом, U
будет
распределен
![]() .
.
Вероятность
ошибочной классификации при условии,
что наблюдение производилось над
![]() равна
равна
 (14)
(14)
а
вероятность ошибочной классификации
при условии, что наблюдение производилось
над
![]() 2,
равна
2,
равна
 (15)
(15)
На рис. 9 эти две вероятности изображены в виде заштрихованных площадей, ограниченных «хвостами» плотностей. Для минимального решения с выбирается так, чтобы
 (16)
(16)
Теорема
6.4.2. Если
![]() (i=1,2)
имеют
плотности распределения вероятностей
(1),
то
минимаксные области классификации
определяются по (6),
где
с
= 1nk
выбирается
из условия (16),
a
C(i|j)
— цены ошибочных классификаций.
(i=1,2)
имеют
плотности распределения вероятностей
(1),
то
минимаксные области классификации
определяются по (6),
где
с
= 1nk
выбирается
из условия (16),
a
C(i|j)
— цены ошибочных классификаций.

В случае, когда цены ошибочных классификаций не равны

Следует отметить, что если цены ошибочных классификаций равны между собой, то c=0 и вероятность ошибочной классификации равна
между собой, с может быть определено достаточно точно по таблицам нормального распределения методом проб и ошибок.
Оба слагаемых в (5) содержат вектор
![]() . (18)
который
получается как решение уравнения
. (18)
который
получается как решение уравнения
![]() . (19)
. (19)
полученное эффективным численным методом, как, например, метод сокращения Дулиттла.
Интересно
отметить, что х'![]()
![]() является
линейной функцией, которая дает
максимум
является
линейной функцией, которая дает
максимум
![]() (20)
(20)
при любом выборе d. Числитель (20) равен
![]() (21)
(21)
а знаменатель
d'M(X
— MХ)(Х
— MX)'d
= d’![]() d,
(22)
d,
(22)
Нам
нужно найти максимум (21) no
d,
сохраняя
(22) постоянным. Если
![]() —
множитель Лагранжа, то задача сводится
к нахождению максимума выражения
—
множитель Лагранжа, то задача сводится
к нахождению максимума выражения
![]() .
(23) -
.
(23) -
Приравнивая нулю производные (23) по компонентам вектора d, получим
![]() . (24)
. (24)
Так
как (![]() -
-![]() )’d
— скаляр, скажем v,
то (24) можно
записать в виде
)’d
— скаляр, скажем v,
то (24) можно
записать в виде
![]() -
-![]() =
=![]() . (25)
. (25)
Поэтому
вектор d,
являющийся
решением уравнения (24), пропорционален
вектору
![]() .
.
В
заключение отметим, что если мы
имеем выборку объема N
либо
из
![]() ,
либо из
,
либо из![]() 2
, то можно использовать выборочное
среднее значение и классифицировать
выборку
2
, то можно использовать выборочное
среднее значение и классифицировать
выборку
![]() как выборку из
как выборку из![]() или из
или из![]() .
.
1![]() означает,
что р2(х)
=
0,
означает,
что р2(х)
=
0,