

Объекты нотации idef1x
Диаграмма ERwin строится из трех основных блоков - сущностей, атрибутов и связей. Если рассматривать диаграмму как графическое представление правил предметной области, то сущности являются существительными, а связи - глаголами.
Обозначения сущностей:
|
Элемент диаграммы |
Обозначает |
|
|
зависимая сущность |
|
Имя
|
независимая сущность |
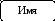
Список атрибутов приводится внутри прямоугольника, обозначающего сущность. Атрибуты, составляющие ключ сущности, группируются в верхней части прямоугольника и отделяются горизонтальной чертой.
Обозначения связей:
|
Элемент диаграммы |
Обозначает |
|
|
идентифицирующая связь |
|
|
Неидентифицирующая связь |


Обозначение кардинальности связей:
|
Элемент диаграммы |
Обозначает |
|
|
1,1 |
|
|
0,M |
|
Z |
0,1 |
|
P |
1,M |
|
N |
точно N (N - произвольное число) |





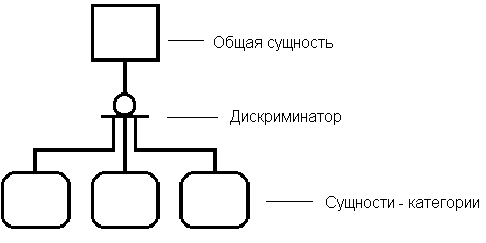
Кроме того, в IDEF1X вводится понятие “отношение категоризации”, по смыслу эквивалентное связи между супертипами и подтипами. Отношение полной категоризации (сущности-категории составляют полное множество потомков родительской сущности) обозначается:
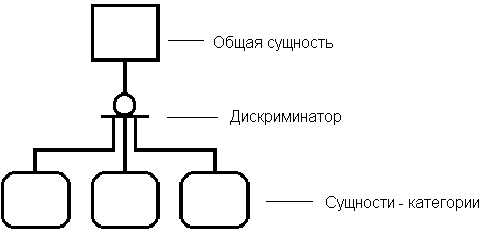
Также может существовать отношение неполной категоризации (сущности-категории составляют неполное множество потомков общей сущности):
Таким образом, при помощи указанных компонентов диаграммы ERwinбыла построена логическая модель данных “Учет проб геологических пород”, которая представлена в Приложение.
Генерация отношений
Следующим этапом проектирования модели базы данных является генерирование отношений, которое производится на основании построенной логической модели (см. Приложение).
Выделим, исходя из полученных сущностей, следующие отношения:
R0(Организация) = {ID организации, Название организации, Номер лицензии, Юридический адрес, ИНН организации, Расчетный счет}
R1(Подрядчик) = {ID подрядчика, Название подрядчика, Номер лицензии, Юридический адрес, ИНН подрядчика, Расчетный счет}
R2(Договор) = {Номер договора, Дата начала работ, Дата окончания работ, Номер сметы, ID подрядчика}
R3(Смета) = {Номер сметы, ID организации}
R4(Проба) = {Номер пробы, Дата отбора, ID места отбора, ID объекта исследования}
R5(Место отбора) = {ID отбора, Наименование места отбора}
R6(Объект исследования) = {ID объекта исследования, Название объекта исследования}
R7(Вид анализа) = {ID вида анализа, Название вида анализа}
R8(Реестр по отбору проб) = {ID вида анализа, Номер пробы, Результат, Дата анализа}
R9(Отчет) = {Номер договора, ID вида анализа, Номер пробы, Дата}
Нормализация отношений
Нормальная форма Бойса-Кодда (НФБК) учитывает функциональные зависимости, в которых участвуют все потенциальные ключи отношения, а не только его первичные ключ.
Отношение находится в НФБК, если оно находится в первой нормальной форме (1НФ) и каждый детерминант является возможным ключом или ключом является вся схема отношения.
Необходимо отметить, что отношение находится в 1НФ, если значения его атрибутов атомарны, т.е. не являются списком или выражением. В данном случае все сгенерированные отношения находятся в 1НФ.
Декомпозиция до НФБК осуществляется на минимальном покрытии.
Минимальное покрытие – это неизбыточное покрытие, содержащее наименьшее количество функциональных зависимостей (ФЗ). В свою очередь, неизбыточное покрытие – это множество ФЗ, не содержащее избыточное ФЗ.
В исходном отношении выявляются множества возможных ключей и детерминантов.
Детерминантом называется левая часть полной ФЗ. Функциональная зависимость называется полной, если ни одно собственное подмножество левой части не определяет правую.
Если выделенные множества ключей и детерминантов не эквивалентны, то в отдельное отношение выделяется крайняя ФЗ; если после этого множества ключей и детерминантов оказываются эквивалентными, то декомпозиция завершается, иначе декомпозиция продолжается.
R0(Организация) = {ID организации, Название организации, Номер лицензии, Юридический адрес, ИНН организации, Расчетный счет}
|
ID организации |
Название организации |
Номер лицензии |
Юридический адрес |
ИНН организации |
Расчетный счет |
|
1 |
ООО «РостПроект» |
14365 |
г.Ухта ул. Ленина 25 |
1102049744 |
40702810800170001121 |
Fmin={IDсотрудника → Название организации, Номер лицензии, Юридический адрес, ИНН организации, Расчетный счет }
R1(Подрядчик) = {ID подрядчика, Название подрядчика, Номер лицензии, Юридический адрес, ИНН подрядчика, Расчетный счет}
|
ID подрядчика |
Название подрядчика |
Номер лицензии |
Юридический адрес |
ИНН организации |
Расчетный счет |
|
1 |
ООО «Геолог-1» |
35674 |
г.Ухта ул. Кремса 3 |
1102049685 |
7702810800170001121 |
Fmin={IDподрядчика, Название подрядчика, Номер лицензии, Юридический адрес, ИНН подрядчика, Расчетный счет }
R3(Договор) = {Номер договора, Дата начала работ, Дата окончания работ, Номер сметы, ID подрядчика}
|
Номер договора |
Дата начала работ |
Дата окончания работ |
Номер сметы |
ID подрядчика |
|
57 |
23.06.2005 |
26.12.2005 |
134 |
5 |
Fmin={ Номер договора, Дата начала работ, Дата окончания работ, Номер сметы,IDподрядчика }
R4(Смета) = {Номер сметы, ID организации}
|
Номер сметы |
ID организации |
|
123 |
45 |
|
245 |
56 |
Fmin={ Номер сметы,IDорганизации }
R5(Проба) = {Номер пробы, Дата отбора, ID места отбора, ID объекта исследования}
|
Номер пробы |
Дата отбора |
ID места отбора |
IDбъекта исследования |
|
567 |
2.12.2005 |
34 |
76 |
Fmin={ Номер пробы, Дата отбора,IDместа отбора,IDобъекта исследования }
R6(Место отбора) = {ID места отбора, Наименование места отбора}
|
ID места отбора |
Наименование места отбора |
|
56 |
Река Лунвож |
|
75 |
Река Ижма |
Fmin={IDотбора, Наименование места отбора }
R7(Объект исследования) = {ID объекта исследования, Название объекта исследования}
|
ID объекта исследования |
Название объекта исследования |
|
67 |
Вода |
|
24 |
грунт |
Fmin={IDобъекта исследования, Название объекта исследования }
R8(Вид анализа) = {ID вида анализа, Название вида анализа}
|
ID вида анализа |
Название вида анализа |
|
53 |
ПХА |
|
46 |
ПАВ |
Fmin={IDвида анализа, Название вида анализа }
R9(Реестр по отбору проб) = {ID вида анализа, Номер пробы, Результат, Дата анализа}
|
ID вида анализа |
Номер пробы |
Результат |
Дата анализа |
|
59 |
43 |
0.45 |
24.10.2005 |
Fmin={IDвида анализа, Номер пробы, Результат, Дата анализа }
R10(Отчет) = {Номер договора, ID вида анализа, Номер пробы, Дата}
|
Номер договора |
ID вида анализа |
Номер пробы |
Дата |
|
38 |
74 |
356 |
29.09.2005 |
Fmin={ Номер договора,IDвида анализа, Номер пробы, Дата }