

Глава II.
Метрическая теория программ (метрика Холстеда).
Вероятностная модель текста программы.
На основании исследований количественных характеристик текстов в лингвистике уже относительно давно установлен ряд эмпирических закономерностей. Одна из них, так называемый закон Ципфа [2], является зависимостью между частотой появления тех или иных слов в тексте (выбранных из словаря текста) и его длиной. В конце 70-х годов аналогичные результаты были получены М.Холстедом [3] при изучении текстов программ, написанных на различных алгоритмических языках. Также чисто эмпирически им было найдено соотношение, связывающее общее количество слов в программах с величиной их словарей. Как оказалось впоследствии, эти закономерности могут быть получены и осмыслены теоретически на основе представлений алгоритмической теории сложности, основные результаты которой приведены выше.
Если считать, что словарь любой программы (соответствующий алфавиту последовательности) состоит только из имен операторов и операндов, то тексты программ всегда удовлетворяют следующим условиям:
маловероятно появление какого-либо имени оператора или операнда много раз подряд. Как правило, языки программирования позволяют построить такую конструкцию, в которой подобные фрагменты программы имели бы минимальную длину;
циклическая организация программ исключает многократное повторение какой-либо группы операторов и операндов;
блоки программ, требующие периодического повторения при ее исполнении, обычно оформляются как процедуры или функции, так что в тексте программы присутствуют лишь их имена;
имя каждого операнда должно появляться в тексте программы хотя бы один раз.
Таким образом, каждая программа может рассматриваться как результат сжатия ее развертки (с раскрытыми циклами, подстановкой в нужных местах функций, процедур, макрокоманд и т.п.) Поэтому, используя терминологию алгоритмической теории сложности можно утверждать, что длина программы есть мера сложности развертки и ее текст не может быть существенно сокращен, так как все закономерности (периодичность) развертки уже использованы для этой цели.
Математическое ожидание длины текста программы (соотношение
Холстеда).![]()
![]()
Рассуждения
предыдущего параграфа позволяет
заключить, что текст программы, независимо
от его семантики, представляет собой
внешне случайную последовательность
слов (операторов и операндов), составляющих
словарь программы. Поэтому представляется
естественной идея поставить в соответствие
процессу написания программы некоторый
генератор случайных последовательностей
[5].
Наиболее подходящей для этой цели
является выборка с возвратом из некоторой
генеральной совокупности элементов.
Технически дело можно представить
следующим образом. Имена всех операторов
и операндов, составляющих словарь
программы, записываются на отдельных
карточках, помещаются в урну и
перемешиваются. Затем наудачу вынимают
одну карточку, фиксируют имя и снова
опускают в урну тщательно, перемешивая
ее содержимое. Опять вынимают карточку,
фиксируют имя и т.д., повторяя все сначала.
Этот процесс продолжается до тех пор,
пока каждая карточка не будет выбрана
хотя бы один раз. Задача заключается в
том, чтобы найти математическое ожидание
длины серий таких испытаний. Пусть
- число карточек (для удобства сохраним
обозначения, принятые в [3]
и [4]).
Зафиксируем имя, выпавшее при первом
извлечении. Для того, чтобы в выборку
вошла следующая карточка, отличная от
первой, потребуется некоторое число
извлечений, в общем случае больше одного.
Это число является случайной величиной.
Вообще, пусть
![]() будет числом извлечений, следующих за
выборомr-ой
карточки до выборки новой (r+1)-ой
включительно. Тогда
будет числом извлечений, следующих за
выборомr-ой
карточки до выборки новой (r+1)-ой
включительно. Тогда
Q1 = 1 + L1 + L2 + ....+ Lr-1 + Lr + ...+ L-1
будет полным объемом выборки, исчерпывающим всю генеральную совокупность (словарь программы). Аналогичным образом проводятся повторные серии испытаний, в результате которых получаются объемы выборок Q2, Q3 и т.д. Такой способ регистрации событий позволяет полиномиальное распределение их вероятностей свести к биномиальному. Ясно, что распределение случайной величины Lr совпадает с распределением номера первого успеха в последовательности испытаний Бернулли с вероятностью
![]() .
.
Следовательно, математическое ожидание
![]()
(подобный вывод этого утверждения приведен в Приложении 1) и по теореме сложения математических ожиданий
![]() .
.
Так как
![]()
(сумма гармонического ряда), то
![]()
или, при переходе к двоичным логарифмам
![]()
(более точное выражение M(Q), подтвержденное статистикой, приводится в Приложении 3). Это и есть теоретически полученное соотношение Холстеда, представляющее собой математическое ожидание количества слов в программе (проще, ее длину N), если ее словарь состоит из слов (операторов и операндов). Ввиду практической и теоретической важности этого соотношения оно было подвергнуто тщательному статистическому анализу. Специально разработанные программные средства позволили в автоматическом режиме для многих тысяч программ проверить зависимость между и N. Оказалось, что более точным является выражение [4]
![]()
причем отклонение
расчетной длины от фактически наблюдаемой
не превосходило
![]() Словарь операндов, то есть множество
имен входных и выходных переменных,
которое должно обрабатывать проектируемое
программное средство, становится точно
известным уже на стадии постановок
задач. Как будет показано дальше, словарь
операторов также поддается достаточно
точной оценке. Таким образом, на основе
постановок задач рассчитывается длина
(количество слов) будущего программного
обеспечения, которая, в свою очередь,
позволяет с удовлетворительной для
практики точностью оценить трудоемкость
проекта и другие его характеристики.
Словарь операндов, то есть множество
имен входных и выходных переменных,
которое должно обрабатывать проектируемое
программное средство, становится точно
известным уже на стадии постановок
задач. Как будет показано дальше, словарь
операторов также поддается достаточно
точной оценке. Таким образом, на основе
постановок задач рассчитывается длина
(количество слов) будущего программного
обеспечения, которая, в свою очередь,
позволяет с удовлетворительной для
практики точностью оценить трудоемкость
проекта и другие его характеристики.
Дисперсия длины программы. Точность соотношения Холстеда.
Учитывая
независимость случайных величин
![]() согласно
теореме сложения дисперсий, будем иметь
согласно
теореме сложения дисперсий, будем иметь
![]()
Так как
![]() распределена
биномиальному закону, то
распределена
биномиальному закону, то
![]()
Следовательно,

![]()
(Полный вывод этих выражений дан в Приложении 2).
При выводе
выражений![]() и
и![]() предполагалось,
что все программы "монолитны".
Поэтому найдем эти соотношения для
модульных программ, для чего воспользуемся
известным неравенством Иенсена: если
некоторая функция
предполагалось,
что все программы "монолитны".
Поэтому найдем эти соотношения для
модульных программ, для чего воспользуемся
известным неравенством Иенсена: если
некоторая функция![]() выпуклая,
то имеет место
выпуклая,
то имеет место
![]()
Очевидно, что для
![]() условие выпуклости выполняется. Поэтому
можно записать
условие выпуклости выполняется. Поэтому
можно записать
![]()
или в окончательном виде
![]()
где
![]()
Таким образом, разбиение программы на модули не только удобно с точки зрения обозримости, но выгодно также с точки зрения сокращения длины. В этом смысле эффект модульности, как будет показано в последующих разделах, имеет принципиально важное значение.
Предположим
далее, что все модули равны (к чему всегда
стремятся на практике). Тогда количество
слов в словаре одного модуля будет
![]() а его длина и дисперсия соответственно
а его длина и дисперсия соответственно
![]()
Поэтому значения N и D(Q) для всей программы согласно теоремам сложения будут
![]()
Для оценки точности
соотношения Холстеда воспользуемся
величиной соотношения абсолютного
разброса длины
![]() N
к ее математическому ожиданию:
N
к ее математическому ожиданию:
![]()
![]()

Таким образом,
соотношение Холстеда выполняется тем
точнее, чем больше длина программы.
Чтобы оценить порядок величины ,
положим
![]() (что также, как правило, имеет место на
практике) иk=50.
Тогда для относительной точности
получим значение, равное
6%.
(что также, как правило, имеет место на
практике) иk=50.
Тогда для относительной точности
получим значение, равное
6%.
Метрические характеристики программ.
Один из наиболее важных количественных показателей - длина программы, нами уже получен. Он представляет собой математическое ожидание количества слов в тексте программы при фиксированном словаре. Ясно, что программы, реализующие один и тот же алгоритм, написанные разными программистами, будут несколько различаться длиной. Фундаментальное значение формулы Холстеда заключается в том, что это различие с ростом словаря программы весьма быстро уменьшается.
Длина программы - исходная величина для расчета остальных ее
характеристик.
Другая важная характеристика программы - ее объем V. В отличие от N он измеряется не количеством слов, а числом двоичных разрядов. Если в словаре имеется
 слов, то для задания номера любого из
них требуется минимум
слов, то для задания номера любого из
них требуется минимум бит. Объем программы определяется как
бит. Объем программы определяется как
![]()
Теперь, когда получены две расчетные метрические характеристики программ, имеет смысл вернуться к пункту 1.2.4. Если алфавиту поставить в соответствие словарь, а произвольной последовательности символов - последовательность слов в программе, трактуемой как результат выборки из генеральной совокупности, то с точностью до обозначений полученные соотношения
![]()
![]()
![]()
![]()
совершенно идентичны, хотя смысл их различен. В первом случае при фиксированной (заданной) длине N была определена величина словаря; во втором - решена обратная задача: по заданному словарю найдена длина программы. Идентичность этих выражений говорит о том, что соотношение между величиной словаря и длиной текста единственно и взаимнооднозначно. Во-вторых, вероятностная модель текста программы, основанная на наглядном представлении выборки из генеральной совокупности с возвратом, равносильна формальному подходу алгоритмической теории сложности.
Выше было
отмечено, что словарь программы состоит
только из операторов и операндов. Если
количество первых обозначить за
![]() ,
а вторых -
,
а вторых -![]() ,
то
,
то![]() и соотношение Холстеда примет вид
и соотношение Холстеда примет вид
![]()
При статистическом исследовании текстов программ[3] к словарю операторов отнесены: имена арифметических и логических операций, присваивания, условных и безусловных переходов, разделители, скобки, имена процедур и функций и т.п. Выражения типа BEGIN...END, IF...THEN...ELSE, DO...WHILE и др. Рассматриваются как единые операторы ( то же относится и к парам скобок).
Ясно, что
величины![]() и
и![]() независимы и могут принимать произвольные
значения. Однако этого нельзя сказать
относительноN1
и
N2,
то есть
числа всех операторов
независимы и могут принимать произвольные
значения. Однако этого нельзя сказать
относительноN1
и
N2,
то есть
числа всех операторов
![]() и
всех операндов
и
всех операндов![]() в тексте программы: между ними можно
установить приблизительное
взаимно-однозначное соответствие.
Действительно, каждый операнд входит
в текст, по крайней мере, хотя бы с одним
оператором - например, с разделителем
(запятой), отделяющим его от других
операторов. В то же время применение
нескольких операторов к одному операнду
маловероятно. Поэтому, можно утверждать,
чтоN1N2,
хотя
величины словарей 1
и 2
могут сильно отличаться друг от друга.
Это позволяет прийти к весьма важному
практическому выводу:
в тексте программы: между ними можно
установить приблизительное
взаимно-однозначное соответствие.
Действительно, каждый операнд входит
в текст, по крайней мере, хотя бы с одним
оператором - например, с разделителем
(запятой), отделяющим его от других
операторов. В то же время применение
нескольких операторов к одному операнду
маловероятно. Поэтому, можно утверждать,
чтоN1N2,
хотя
величины словарей 1
и 2
могут сильно отличаться друг от друга.
Это позволяет прийти к весьма важному
практическому выводу:
N 2N2 = 22log2.
Размер словаря операндов 2, как будет показано в п.2.4.3. легко определяется из постановок задач.
Основной исходный параметр, на котором базируются все расчеты метрических характеристик будущего ПС - это количество имен входных и выходных переменных 2, представленных в предельно краткой (сжатой, с точки зрения алгоритмической сложности) записи. Например, для задания одномерного массива (строки), каково бы ни было число его элементов, требуется всего два имени: а) указатель адреса начала массива, б) количество элементов в нем. Аналогично, для задания двумерного массива достаточно иметь три имени: а) указатель адреса первого элемента, б) число столбцов, в) число строк. Такой подход к представлению входной и выходной информации обеспечивает инвариантность программ относительно размерности решаемых задач.
Если таким
образом определенный параметр 2
рассматривать как численность
генеральной совокупности имен входных
и выходных переменных, то величина
словаря программы 2
в соответствии с соотношением Холстеда
не будет превосходить![]() Таким образом, принимаем, что
Таким образом, принимаем, что
![]()
Последнее равенство также хорошо подтверждается статистикой.
Предположим, что существует некоторый язык программирования, называемый потенциальным, в котором все программы (по крайней мере для некоторой предметной области) уже написаны и представлены в виде процедур или функций. Тогда для реализации любого алгоритма на этом языке потребуется всего два оператора (функция и присваивание) и
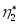 имен входных и выходных переменных.
Поскольку в такой записи никакие слова
не повторяются, то длина программы
совпадает с ее объемом и равна
имен входных и выходных переменных.
Поскольку в такой записи никакие слова
не повторяются, то длина программы
совпадает с ее объемом и равна
![]()
Эта величина называется потенциальным (минимально возможным) объемом, а отношение
![]()
-уровнем реализации программы. Данный метрический показатель характеризует степень компактности программы, экономичность использования изобразительных средств алгоритмического языка. Чем ближе значение L к единице, тем совершеннее программа.
Оптимизация количества модулей в программе и их длины.
Соотношение
Холстеда позволяет контролировать, то
есть выходить на заданную длину модулей
проектируемых ПС. Действительно, длина
модулей, в пределах точности этого
соотношения, определяется только их
словарями. В свою очередь, величина
последних зависит исключительно от
числа групп, на которые разбивается
![]() входных и выходных переменных
программируемой задачи. Таким образом,
величина словаря модуля - контролируемый
параметр, а вместе с ней и его длина.
входных и выходных переменных
программируемой задачи. Таким образом,
величина словаря модуля - контролируемый
параметр, а вместе с ней и его длина.
Итак, пусть k - число модулей. Тогда словарь операндов одного модуля будет
![]()
(в соответствии с выражением, полученным в п.2.4.3.), а всей программы
![]()
Ясно, что каждой группе присваивается имя, которое ее замещает в тексте программы. С учетом этого обстоятельства окончательно имеем
![]()
Варьирование
числом групп разбиения входных и выходных
переменных будет приводить к изменению
словаря программы. Дифференцируя
![]() поk
и приравнивая производную нулю, получим
после преобразований
поk
и приравнивая производную нулю, получим
после преобразований
![]()
или
![]()
Решив последнее уравнение методом последовательных приближений, находим наилучшее (с точки зрения минимизации длины программы) количество модулей
![]() kопт
kопт![]()
При этом число входных имен каждого модуля будет
![]() опт
опт![]()
Рассмотрим один
численный пример. Пусть
![]() = 256, что соответствует довольно большой
программе. Из полученных формул сразу
находим: число модулейkопт28,
число входных переменных одного модуля
= 256, что соответствует довольно большой
программе. Из полученных формул сразу
находим: число модулейkопт28,
число входных переменных одного модуля
![]() Вычислим длину такого модуля, используя
полученные ранее соотношения:
Вычислим длину такого модуля, используя
полученные ранее соотношения:
![]()
![]()
![]()
Итак, длина модуля
составляет 280 слов, соответственно его
объем
![]() бит.
Исследование надежности ПС показало[3],
что наименьшее количество ошибок
обнаруживается в модулях, число входных
переменных, которых не превосходит
восьми -
бит.
Исследование надежности ПС показало[3],
что наименьшее количество ошибок
обнаруживается в модулях, число входных
переменных, которых не превосходит
восьми -
![]() (при этом длина модуля составляет200
слов).
(при этом длина модуля составляет200
слов).
Программные средства реальных информационных систем имеют сложную иерархическую структуру. Как правило, самый нижний уровень - "исполнительные модули" - наиболее многочисленный, в то время как вершина управляющей "пирамиды" оканчивается одним модулем. Исследования структур больших программных систем обнаружили [6], что наиболее жизнеспособными являются те из них, число уровней которых не превосходит 78.
Покажем это,
используя полученные в данном пункте
результаты. Пусть![]() число входных переменных проектируемого
программного обеспечения ИС. Тогда
число исполнительных модулей, следуя
приведенной выше практической
рекомендации, примем равным
число входных переменных проектируемого
программного обеспечения ИС. Тогда
число исполнительных модулей, следуя
приведенной выше практической
рекомендации, примем равным![]() Если их количество велико (k8),
то полученный словарь имен модулей
снова придется таким же образом разбивать
на группы и т.д. Этот процесс продолжается
до тех пор, пока не будет выполнено,
очевидно, следующее условие
Если их количество велико (k8),
то полученный словарь имен модулей
снова придется таким же образом разбивать
на группы и т.д. Этот процесс продолжается
до тех пор, пока не будет выполнено,
очевидно, следующее условие
![]()
где i - число уровней.
Логарифмируя обе части этого выражения и разрешая его относительно i, получим
![]()
где скобки означают
целую часть заключенного в них числа.
Для рассмотренного примера
![]() ,
как следует из формулы,i=3.
,
как следует из формулы,i=3.
Таким образом,
число иерархических уровней действительно
медленно (логарифмически) растет с
изменением
![]() .
.
Проблема структуризации проектируемых ПС, разумеется, имеет сугубо содержательный характер и принципиально не может быть формализована. Однако, каким бы образом она ни решалась, расчетные метрические характеристики (длина модулей, их число, количество иерархических уровней) задают оптимальные параметры структуры ПС, наиболее рациональные с точки зрения качества реализации проекта.
Количественная оценка работы программирования. Квалификационное
и фактическое время программирования.
Из теории сортировки известно, что наименьшее количество сравнений для поиска одного элемента массива имеет место при так называемой дихотомической выборке и равно logm, если m - общее количество элементов. Аналогичный результат установлен в инженерной психологии (закон Хика): длительность мысленной выборки какого-либо символа из некоторого множества также пропорциональна численности последнего. Следовательно, число сравнений выборок может служить объективной мерой работы программирования в принятой нами модели этого процесса (см. разделы 2.1. и 2.2.).
Если N - длина программы, а - словарь, то общее количество выборок - работа программирования - будет, в соответствии с законом Хика,
Nlog,
то есть, объем программы. Однако необходимо
еще учесть уровень ее реализации L:
количество выборок при этом возрастет
в![]() раз. Обозначив работу программирования
буквой Е, окончательно получим
раз. Обозначив работу программирования
буквой Е, окончательно получим
![]()
так как
![]()
В инженерной психологии также установлено, что число мысленных сравнений, производимых человеком в единицу времени (секунду), лежит в пределах s S 20. Это так называемое число Страуда. Среднее его значение принято считать равным 18. (Косвенным подтверждением этого факта является кино: при частоте кадров 25 1/сек, то есть выше верхнего значения S, движения на экране воспринимаются как непрерывные; ниже - как прерывистые). Отсюда следует, что время программирования будет
![]()
по очевидным причинам эта формула для оценки календарного времени разработки ПС не годится. Обычно она применяется для тестирования обучающихся программированию на степень усвоения того или иного алгоритмического языка, причем на небольших программах. Поэтому величину Т называют квалификационным временем.
Оценка реального календарного времени разработки нового оригинального ПС основана на статистике производительности труда программистов. Установлено, что при пересчете на команды ассемблера эта производительность составляет от 5 до 30 отлаженных (!) команд за рабочий день, принимаемый обычно за семь часов. В каждом программистском коллективе эта величина устанавливается, исходя реальных экономических условий, директивным образом[10]. Предполагается также, что за основу организации труда принята "бригада главного программиста".
Если на основе постановок задач найдено, что ПС содержит N слов, то количество команд ассемблера определяется как
![]()
где
![]() коэффициент
пересчета Кнута.
коэффициент
пересчета Кнута.
Пусть, далее, n - количество программистов и v - заданная производительность их труда (в указанном выше смысле). Тогда календарное время Тк программирования ПС будет
Тк
=
![]() (дней).
(дней).
Количественная оценка уровня языков программирования.
Одним из следствий субъективного представления об "уровне" алгоритмического языка явилась разработка в предыдущие десятилетия невероятно большого количества языков программирования, их версий и т.п. В программистском сообществе сформировалось стойкое убеждение, что возможно создание такого языка "высокого" или "сверхвысокого" уровня, который позволит осуществить прорыв в технологии производства ПС.
В начале 80-х годов Холстед [3] ввел формальное определение уровня языка программирования, определив последний как
= L2V,
где L
- уровень реализации программы, а V
- ее объем. Статистические исследования,
проведенные на огромном фактическом
материале, показали, что величина
действительно зависит только от
конкретного языка программирования и
практически не зависит от объема
программы, так как
![]()
Иными словами, =const в пределах одного и того же языка.
Вследствие содержательной неясности введенного таким образом параметра уровня языка последний остался неоцененным должным образом программистами.
Используя понятие работы программирования, введенное в предыдущем пункте, покажем, что имеет достаточно простой смысл [6]. При этом необходимо условиться об эталонном языке, "уровень" которого воспринимался бы как предельно высокий. Ясно, что эту роль может выполнить определенный нами в п.2.4.4. потенциальный язык. Он предполагает, что все программы, по крайней мере, в некоторой предметной области, уже написаны, так что теоретически мы будем иметь дело с огромной библиотекой функций или подпрограмм. Найдем работу программирования в этом языке. Как уже было отмечено в п.2.4.3., в записи на потенциальном языке программа имеет минимально возможную длину, и так как слова (операнды и операторы) в ней не повторяются, то она совпадает с объемом
![]()
Но при этом надо иметь ввиду, что работа программирования здесь сводится к выбору из конечного, но колоссального по величине числа имен функций:
21 + 22 +23 + ...+ 2V-1 + 2V 2V+1.
где V - объем программы. Тогда в соответствии с законом Хика работа выбора из библиотеки функций составит log2V+1 V, и полная работа программирования на потенциальном языке будет
En = VV.
Для характеристики уровня конкретного языка программирования представляется естественным сопоставить работу программирования Е в этом языке, найденную в предыдущем пункте, с En., а именно: отношение
![]()
считать количественной мерой уровня любого алгоритмического языка.
Ниже приведена таблица уровней некоторых известных языков программирования.
-
Язык
Примечание
Естественный язык
2,16
Для небольших научных текстов
PL/1
1,53
Паскаль
1,25
Бейсик
1,22
Фортран
1,14
Ассемблер
0,88
Как видно, значения заключены в довольно узком диапазоне. Это обстоятельство во многом объясняет тот факт, что длительные поиски "самого эффективного" языка ни к чему не привели. Оценим максимально возможный выигрыш производительности программирования только за счет повышения уровня языка. Так как
![]() и
и
![]()
то исключив V, получим
![]()
Тогда время программирования (квалификационное) будет
![]()
где S - число Страуда.
Допустим теперь, что один и тот же алгоритм реализован двумя разными программами, одна из которых написана на языке с уровнем 1, а другая - 2. В этом случае
![]() и
и
![]()
Очевидно, что

Положив 2 = 2,16 (предельный уровень - естественный язык), 1 = 0,88 (ассемблер), находим
![]()
Для Паскаля этот выигрыш по сравнению с Ассемблером будет только
![]()
По всей видимости, резервы повышения производительности программирования за счет повышения уровня алгоритмических языков к настоящему времени исчерпаны (имеются ввиду универсальные языки).
Оценка надежности ПС в начальный период эксплуатации.
Одна из главных
составляющих качества ПС - его надежность.
Последняя оценивается средним временем
проявления ошибок tн
- так называемой "наработкой на отказ".
Ясно, что в первое время после сдачи в
эксплуатацию интенсивность проявления
ошибок будет наибольшей и, следовательно,
надежность минимальной. Этот период в
жизненном цикле ПС является наиболее
критичным. Поэтому весьма важно оценить
величину tн
одновременно с другими метрическими
параметрами, рассмотренными выше. В
конечном итоге это позволит варьировать
временем написания и длительностью
отладки
![]() (от которой в первую очередь зависитtн)
в пределах общей календарной длительности
Тк
разработки ПС.
(от которой в первую очередь зависитtн)
в пределах общей календарной длительности
Тк
разработки ПС.
К настоящему времени разработано [6] довольно много методов оценки tн, однако наиболее просто и эффективно эта задача решена в рамках экспоненциальной модели надежности.
Предположим,
что в начале отладки ПС (![]() =0)
в нем содержалось В0
первичных ошибок; после отладки в течение
времени
=0)
в нем содержалось В0
первичных ошибок; после отладки в течение
времени
![]() устраненоb
ошибок и b0
осталось не выявленными (В0
= b
+ b0).
устраненоb
ошибок и b0
осталось не выявленными (В0
= b
+ b0).
При постоянных усилиях на отладку интенсивность обнаружения ошибок следует считать пропорциональной оставшемуся их количеству. Это предположение проверено анализом реальных характеристик процессов обнаружения ошибок. Таким образом, интенсивность - скорость - обнаружения ошибок и число устраненных ошибок могут быть связаны дифференциальным уравнением
![]()
где А - некоторый коэффициент пропорциональности.
Решением этого
уравнения (при начальных условиях
![]() является функция
является функция
![]()
Из этой зависимости следует, что интенсивность обнаружения ошибок будет
![]()
Поскольку наработка
на отказ tн
есть величина, обратная интенсивности
проявления ошибок, то![]()
![]()
![]() н
=
н
=
![]()
Непосредственное
теоретическое и практическое определение
коэффициента А весьма затруднительно,
поэтому желательно его выразить через
другие параметры, более доступные
прямому измерению на практике. Так как
![]() то
то
![]()
Логарифмируя обе части этого равенства, получим
![]()
Считая, что В0>>b0
(количество
оставшихся ошибок много меньше начального
их числа), получим
![]() или
или
![]()
Подставив это значение А в выражение для tн, окончательно будем иметь
![]() н
н
Итак, надежность ПС (в смысле наработки на отказ) пропорциональна длительности отладки и обратно пропорциональна логарифму начального количества ошибок.
![]() Если принять,
что основная масса ошибок выявляется
во время отладки, т.е. приблизительно
равна В0,
то оценка tн
по завершении отладки не составляет
труда: согласно формуле достаточно
зафиксировать
Если принять,
что основная масса ошибок выявляется
во время отладки, т.е. приблизительно
равна В0,
то оценка tн
по завершении отладки не составляет
труда: согласно формуле достаточно
зафиксировать
![]() и количество обнаруженных ошибок на
это время. На практике надежность больших
программных систем[6]
в начале опытной эксплуатации обычно
составляет 200300
часов на отказ. (Заметим, что сказанное
выше не относится к ПС, предназначенным
для работы в реальном масштабе времени).
Однако величина В0
на основе изложенной в данной главе
теории с привлечением некоторых
результатов инженерной психологии
может быть рассчитана на основе
метрических характеристик ПС.
Действительно, опытно установлено, что
количество ошибок в текстах программ
пропорционально работе программирования,
которая, как показано, может быть
вычислена. Во-вторых, "генерация"
текста программы человеком происходит
некоторыми фрагментами фиксированного
объема. Известно, что объем кратковременной
памяти человека, измеряемой числом
каких-либо символов (слов, цифр, фигур
и других объектов), которые он может
запомнить и воспроизвести сразу же
после предъявления, составляет в среднем
8. Это - так называемый закон Миллера
"72".
Тогда работа программирования каждого
фрагмента может быть оценена в соответствии
с выше изложенным как
и количество обнаруженных ошибок на
это время. На практике надежность больших
программных систем[6]
в начале опытной эксплуатации обычно
составляет 200300
часов на отказ. (Заметим, что сказанное
выше не относится к ПС, предназначенным
для работы в реальном масштабе времени).
Однако величина В0
на основе изложенной в данной главе
теории с привлечением некоторых
результатов инженерной психологии
может быть рассчитана на основе
метрических характеристик ПС.
Действительно, опытно установлено, что
количество ошибок в текстах программ
пропорционально работе программирования,
которая, как показано, может быть
вычислена. Во-вторых, "генерация"
текста программы человеком происходит
некоторыми фрагментами фиксированного
объема. Известно, что объем кратковременной
памяти человека, измеряемой числом
каких-либо символов (слов, цифр, фигур
и других объектов), которые он может
запомнить и воспроизвести сразу же
после предъявления, составляет в среднем
8. Это - так называемый закон Миллера
"72".
Тогда работа программирования каждого
фрагмента может быть оценена в соответствии
с выше изложенным как

Предположив, что с каждым из них связана, по крайней мере, одна ошибка (это доказано на основе многочисленных статистических исследований), получим
![]()
где V - расчетный объем ПС. Здесь следует обратить внимание на факт отсутствия в последнем выражении параметра L - уровня реализации программы. Он характеризует больше концептуальный подход к постановке задач и связан с выбранным алгоритмом, а не с "операторским" режимом непосредственного кодирования.