

4.6.5 Преобразование макроблоков в-изображений
Обобщая вышеизложенные рассуждения для Р-изображений, несложно заключить, что макроблоки В-изображений могут быть следующих типов - опорные (intra), кодируемые сами по себе, предсказываемые вперед ( forward predicted) на основании предыдущего изображения, предсказываемые назад ( backward predicted) на основании последующего изображения, а также интерполируемые (interpolated) как полусумма обоих предсказаний. В данном случае кодеру предстоит наиболее сложная работа с рассмотрением множества различных вариантов и выбора наиболее эффективного из них, реализующего компромисс между длиной кода и качеством восстанавливаемого изображения. Задача облегчается тем, что ошибки этих изображений в отличие от I- и Р-типов не накапливаются, т.е. не приводят к регулярным искажениям. Более того, за счет быстрой смены изображений эти случайные ошибки менее заметны. В результате В-изображения, кодируемые по вышеописанным схемам для опорных и предсказываемых макроблоков, допускают самый короткий код.
4.6.6 Разделы макроблоков
Кратко остановимся на значении разделов (slices). Дело в том, что MPEG-стандарт предполагает передачу текущих значений многих параметров не в абсолютных величинах, а в виде разностей с предыдущими значениями. Это используется, например, при кодировании пространственных координат текущего макроблока, вектора его смещения и значения коэффициента F(0,0). В силу коррелированности этих значений формируемые разности, как правило, небольшие по величине и допускают короткий код. Но платой за это является повышенная чувствительность к ошибкам передачи разностной информации. Для повышения устойчивости и вводятся разделы, в начале которых записываются опорные (не разностные) значения этих параметров, обеспечивающие возможность их восстановления вне зависимости от ошибок передачи в предыдущем разделе. Разделы покрывают всю площадь изображения без пропусков и перехлестов, причем макроблоки каждого раздела образуют непрерывную последовательность (сканирование вдоль строк).
В заключение подчеркнем важную особенность MPEG-последовательностей - они не допускают покадрового редактирования. Действительно, в силу вышеописанной сложной зависимости изображений внесение изменений в одно из них неизбежно повлечет за собой необходимость комплексного пересчета множества параметров во всей группе. Исключением является группы, состоящие только из /-изображений. Но подобные вырожденные видеопоследовательности фактически уже реализуют не MPEG, a M-JPEG алгоритм компрессии, обсуждение которого выходит за рамки настоящего материала.
4.7 Mpeg-1
По стандарту MPEG-1 потоки видео и звуковых данных передаются со коростью 150 килобайт в секунду - с такой же скоростью, как и односкоростной CD-ROM проигрыватель - и управляются путем выборки ключевых видео кадров и заполнением только областей, изменяющихся между кадрами. К несчастью, MPEG-1 обеспечивает качество видеоизображения более низкое, чем видео, передаваемое по телевизионному стандарту.
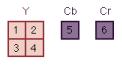
MPEG-1 был разработан и оптимизирован для работы с разрешением 352 ppl (point per line -- точек на линии) * 240 (line per frame -- линий в кадре) * 30 fps (frame per second -- кадров в секунду), что соответствует скорости передачи CD звука высокого качества. Используется цветовая схема - YCbCr (где Y - яркостная плоскость, Cb и Cr - цветовые плоскости).
Как MPEG работает:
В зависимости от некоторых причин каждый frame (кадр) в MPEG может быть следующего вида:
I (Intra) frame - кодируется как обыкновенная картинка.
P (Predicted) frame - при кодировании используется информация от предыдущих I или P кадров.
B (Bidirectional) frame - при кодировании используется информация от одного или двух I или P кадров (один предшествующий данному и один следующий за ним, хотя может и не непосредственно, см. Рис.1)
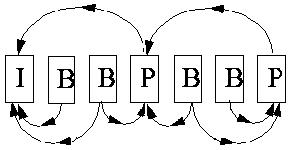
Рисунок 2.3
Последовательность кадров может быть например такая: IBBPBBPBBPBBIBBPBBPB...
Последовательность декодирования: 0312645...
Нужно заметить, что прежде чем декодировать B кадр требуется декодировать два I или P кадра. Существуют разные стандарты на частоту, с которой должны следовать I кадры, приблизительно 1-2 в секунду, соответствуюшие стандарты есть и для P кадров (каждый 3 кадр должен быть P кадром). Существуют разные относительные разрешения Y, Cb, Cr плоскостей (Таблица 2.2), обычно Cb и Cr кодируются с меньшим разрешением чем Y.
Таблица 2.2
Вид Формата |
Отношения разрешений по горизонтали (Cb/Y): |
Отношение разрешений по вертикали (Cb/Y): |
4:4:4 |
1:1 |
1:1 |
4:2:2 |
1:2 |
1:1 |
4:2:0 |
1:2 |
1:2 |
4:1:1 |
1:4 |
1:1 |
4:1:0 |
1:4 |
1:4 |
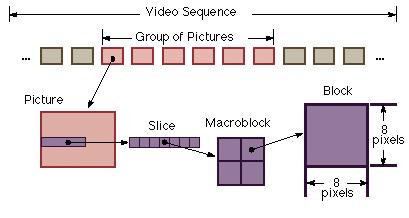
Для применения алгоритмов кодировки происходит разбивка кадров на макроблоки каждый из которых состоит из определенного количества блоков (размер блока - 8*8 пикселей). Количество блоков в макроблоке в разных плоскостях разное и зависит от используемого формата (рисунок 2.4):
 Рисунок
2.4 - Пример
для формата 4:2:0
Рисунок
2.4 - Пример
для формата 4:2:0
Техника кодирования:
Для большего сжатия в B и P кадрах используется алгоритм предсказания движения (что позволяет сильно уменьшить размер P и B кадров) на выходе которого получается:
Вектор смещения (вектор движения) блока который нужно предсказать относительно базового блока.
Разница между блоками (которая затем и кодируется).
Так как не любой блок можно предсказать на основании информации о предыдущих, то в P и B кадрах могут находиться I блоки (блоки без предсказания движения).
Таблица 2.3
Вид кадра |
I |
P |
B |
Средний размер |
Размер кадра для стандарта SIF (kilobit) |
150 |
50 |
20 |
38 |
Метод кодировки блоков (либо разницы, получаемой при методе предсказание движения) содержит в себе:
Discrete Cosine Transforms (DCT - дискретное преобразование косинусов).
Quantization (преобразование данных из непрерывной формы в дискретную).
Кодировка полученного блока в последовательность.
DCT использует тот факт, что пиксели в блоке и сами блоки связаны между собой (т.е. коррелированны), поэтому происходит разбивка на частотные фурье компоненты (в итоге получается quantization matrix - матрица преобразований данных из непрерывной в дискретную форму, числа в которой являются величиной амплитуды соответствующей частоты), затем алгоритм Quantization разбивает частотные коэффициенты на определенное количество значений. Encoder (кодировщик) выбирает quantization matrix которая определяет то, как каждый частотный коэффициент в блоке будет разбит (человек более чувствителен к дискретности разбивки для малых частот чем для больших). Так как в процессе quantization многие коэффициенты получаются нулевыми то применяется алгоритм зигзага для получения длинных последовательностей нулей (рисунок 2.5)

Рисунок 2.5
Звук в MPEG:
Форматы кодирования звука деляться на три части: Layer I, Layer II, Layer III (прообразом для Layer I и Layer II стал стандарт MUSICAM, этим именем сейчас иногда называют Layer II). Layer III достигает самого большого сжатия, но, соответственно, требует больше ресурсов на кодирование.
Принципы кодирования основаны на том факте, что человеческое ухо не совершенно и на самом деле в несжатом звуке (CD-audio) передается много избыточной информации. Принцип сжатия работает на эффектах маскировки некоторых звуков для человека (например, если идет сильный звук на частоте 1000 Гц, то более слабый звук на частоте 1100 Гц уже не будет слышен человеку, также будет ослаблена чувствительность человеческого уха на период в 100 мс после и 5 мс до возникновения сильного звука). Psycoacustic (психоакустическая) модель используемая в MPEG разбивает весь частотный спектр на части, в которых уровень звука считается одинаковым, а затем удаляет звуки не воспринимаемые человеком, благодаря описанным выше эффектам.
В Layer III части разбитого спектра самые маленькие, что обеспечивает самое хорошее сжатие. MPEG Audio поддерживает совместимость Layer'ов снизу вверх, т.е. decoder (декодировщик) для Layer II будет также распознавать Layer I.
Синхронизация и объединение звука и видео, осуществляется с помощью System Stream (рисунок 2.6), который включает в себя:
Системный слой, содержащий временную и другую информацию чтобы разделить и синхронизовать видео и аудио.
Компрессионный слой, содержащий видео и аудио потоки.
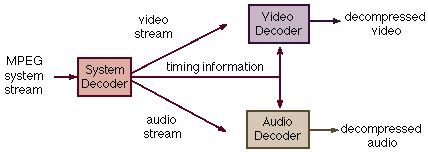
Рисунок 2.6
Видео поток (рисунок 2.7) содержит заголовок, затем несколько групп картинок (заголовок и несколько картинок необходимы для того, что бы обеспечить произвольный доступ к картинкам в группе в независимости от их порядка).
Звуковой поток состоит из пакетов каждый из которых состоит из заголовка и нескольких звуковых кадров (audio-frame).
Для синхронизации аудио и видео потоков в системный поток встраивается таймер, работающий с частотой 90 КГц (System Clock Reference -- SCR, метка по которой происходит увеличения временного счетчика в декодере) и Presentation Data Stamp (PDS, метка насала воспроизведения, вставляются в картинку или в звуковой кадр, чтобы объяснить декодеру, когда их воспроизводить. Размер PDS сотавляет 33 бита, что обеспечивает возможность представления любого временного цикла длинной до 24 часов).
 Рисунок
2.7
Рисунок
2.7