

Линейный поиск
Рассмотрим задачу поиска элемента в одномерном массиве.
Дано:1)
![]()
число элементов массива;
число элементов массива;
2)
![]()
массив типа array
[index]
of
Elem;
массив типа array
[index]
of
Elem;
3)
![]() :
Elem
элемент для поиска;
:
Elem
элемент для поиска;
4)
искомый элемент в массиве есть, т. е.
![]()
![]()
![]() .
.
Условие
4 можно записать в виде утверждения
(![]()
![]() :
:![]() :
:![]() )
или в форме с квантором счета (
)
или в форме с квантором счета (![]()
![]() :
:![]() )
> 0.
)
> 0.
Найти
первое вхождение
![]() в массив
в массив![]() ,
т. е. найти
,
т. е. найти
![]() ,
такое, что (
,
такое, что (![]() )
& (
)
& ( ![]() :
:![]() :
:
![]() ).
).
Далее
будем записывать утверждение ( ![]() :
:![]() :
:
![]() )
более кратко, а именно
)
более кратко, а именно
![]() .
Тогда постутверждение для этой задачи
можно записать в виде
.
Тогда постутверждение для этой задачи
можно записать в виде
Post:
(![]() )
& (
)
& (![]() )
& (
)
& (![]() ).
).
Инвариант
может быть получен устранением
конъюнктивного члена (![]() )
из постусловия Post, т. е. Inv: (
)
из постусловия Post, т. е. Inv: (![]() )
& (
)
& (![]() ).
Если в качестве условия выхода из цикла
взять устраненный конъюнктивный член
(
).
Если в качестве условия выхода из цикла
взять устраненный конъюнктивный член
(![]() ),
то получим как раз требуемое: Inv &
(условие выхода)
),
то получим как раз требуемое: Inv &
(условие выхода) ![]() Post.
Post.
Это приводит к программе вида
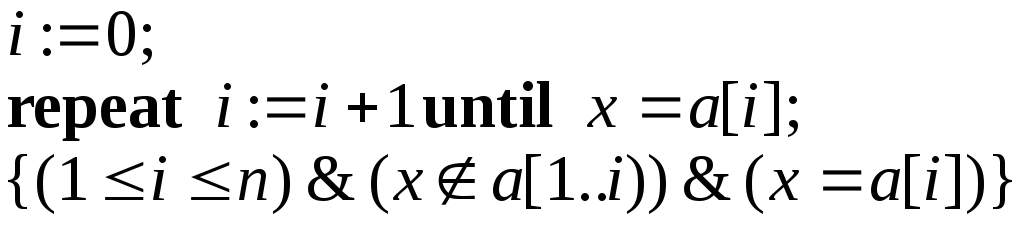
или к варианту с циклом while-do

Пусть
теперь условие 4 постановки задачи не
выполняется, т. е. заранее неизвестно,
есть ли элемент
![]() в массиве
в массиве![]() .
.
Требуется:
если
![]()
![]()
![]() ,
то установить
,
то установить![]() =true
и кроме того указать
=true
и кроме того указать
![]() ,
такое, что (
,
такое, что (![]() )
& (
)
& (![]() )
& (
)
& (![]() );
если (
);
если (![]() ),
то установить
),
то установить![]() =false.
=false.
Требуемое постусловие можно записать в виде
(![]() ), (5.1)
), (5.1)
где введено обозначение
![]() =((
=((![]() )
& (
)
& (![]() )
& (
)
& (![]() )).
)).
Очевидно,
для решения задачи необходимо просматривать
все элементы массива, пока не будет
найден элемент, равный
![]() .
Фактически
.
Фактически![]()
индуктивная ф-ция над последовательностью
индуктивная ф-ция над последовательностью
![]() со стационарным значением
со стационарным значением![]() =true.
Рассматривая «чтение» последовательности
=true.
Рассматривая «чтение» последовательности
![]() в естественном порядке, получим алгоритм
в естественном порядке, получим алгоритм

Инвариантом
цикла здесь является утверждение
(![]() ) & (
) & (![]() ).
Учитывая условие выхода из цикла,
получаем при его завершении постутверждение
((
).
Учитывая условие выхода из цикла,
получаем при его завершении постутверждение
((![]() )
or
)
or
![]() )
& (
)
& (![]() )
& (
)
& (![]() )
& (
)
& (![]() ),
где учтено, что при
),
где учтено, что при![]() тело цикла выполняется хотя бы один
раз. Из этого утверждения следует
требуемое постусловие (5.1).
тело цикла выполняется хотя бы один
раз. Из этого утверждения следует
требуемое постусловие (5.1).
В
задаче поиска с заранее неизвестным
исходом
![]() удобно использовать следующий прием:
добавим к массиву дополнительный
элемент
удобно использовать следующий прием:
добавим к массиву дополнительный
элемент![]() ,
играющий роль «барьера», тогда задача
поиска сведется к первоначальной
постановке (известно, что
,
играющий роль «барьера», тогда задача
поиска сведется к первоначальной
постановке (известно, что![]() )
и может быть решена программой
)
и может быть решена программой
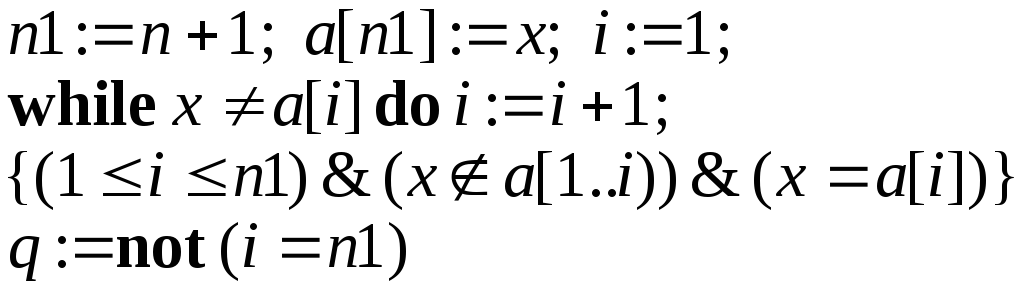
Оценивая
эффективность линейного поиска по числу
требуемых сравнений
![]() (или
(или
![]() ),
легко заметить, что в лучшем случае (при
),
легко заметить, что в лучшем случае (при
![]() )
поиск завершится за один шаг, в худшем
за
)
поиск завершится за один шаг, в худшем
за
![]() шагов (в варианте без барьера), а в среднем
за
шагов (в варианте без барьера), а в среднем
за
![]() шагов (в предположении, что все
шагов (в предположении, что все![]() различны и вероятность события
различны и вероятность события
![]() равна
равна
![]() ).
).
Билет№37 Разработка алгоритма бинарного поиска №37
Существенно лучший алгоритм, чем последовательный поиск, можно предложить в случае, когда массив упорядочен.
Дано:1)
![]() :
Integer;
:
Integer;
2)array
![]() of
Ordinal;
Pred: (
of
Ordinal;
Pred: (![]() :
:![]() :
:![]() )}
)}
3)
![]() :
Ordinal.
:
Ordinal.
Требуется:
либо найти индекс
![]() ,
определяющий место в массиве, такой,
что
,
определяющий место в массиве, такой,
что![]() при
при![]() ,
либо указать, чтоx a[1]
или a[n] < x.
,
либо указать, чтоx a[1]
или a[n] < x.
Удобно
добавить «идеальные» элементы
![]() и
и![]() ,
которые можно использовать для записи
утверждений, но которые не должны входить
в исполняемые инструкции программы.
Тогда требуемое постутверждение примет
видPost:
(
,
которые можно использовать для записи
утверждений, но которые не должны входить
в исполняемые инструкции программы.
Тогда требуемое постутверждение примет
видPost:
(![]() )
& (
)
& (![]() ).
Если такой индекс найден, то саму задачу
поиска можно решить дополнительной
проверкой:
).
Если такой индекс найден, то саму задачу
поиска можно решить дополнительной
проверкой:
![]()
что
выражается постутверждением
![]() .
.
В
качестве основной идеи алгоритма возьмем
следующую: пусть сначала о локализации
значения
![]() среди значений
среди значений![]() ничего неизвестно, т. е. предутверждение
можно дополнить утверждением
ничего неизвестно, т. е. предутверждение
можно дополнить утверждением![]() ;
далее при работе алгоритма будем
рассматривать интервал локализации
;
далее при работе алгоритма будем
рассматривать интервал локализации![]() ,
где
,
где![]() ;
причем на каждом шаге этот интервал
должен уменьшаться, т. е. величина
;
причем на каждом шаге этот интервал
должен уменьшаться, т. е. величина![]() должна убывать. Эта идея реализуется
инвариантом цикла (
должна убывать. Эта идея реализуется
инвариантом цикла (![]() )
& (
)
& (![]() )
, ограничивающей функцией
)
, ограничивающей функцией![]() и условием завершения цикла
и условием завершения цикла![]() .
Отметим, что формально инвариант можно
получить из постутверждения (
.
Отметим, что формально инвариант можно
получить из постутверждения (![]() )
заменой границ интервала
)
заменой границ интервала![]() и
и![]() на
на![]() и
и![]() соответственно. Из предусловия
соответственно. Из предусловия![]() будет следовать инвариант, если цикл
инициализировать следующим способом:
будет следовать инвариант, если цикл
инициализировать следующим способом:![]() .
Таким образом, имеем набросок программы,
изображенной на рис. 5.1. Тело цикла должно
обеспечивать уменьшение интервала
.
Таким образом, имеем набросок программы,
изображенной на рис. 5.1. Тело цикла должно
обеспечивать уменьшение интервала![]() при сохранении инварианта. Очевидно,
уменьшить интервал можно, выбрав значение
индекса
при сохранении инварианта. Очевидно,
уменьшить интервал можно, выбрав значение
индекса![]() внутри интервала и сравнив
внутри интервала и сравнив![]() с
с![]() .
При этом
.
При этом![]() следует брать таким, что
следует брать таким, что![]() и
и![]() еще не сравнивались, т. е.
еще не сравнивались, т. е.![]() .
Пусть
.
Пусть![]() ,
тогда необходимо изменить левую границу,
причем так, чтобы удовлетворить
инвариант, т. е.
,
тогда необходимо изменить левую границу,
причем так, чтобы удовлетворить
инвариант, т. е.![]() ,
и,
,
и,
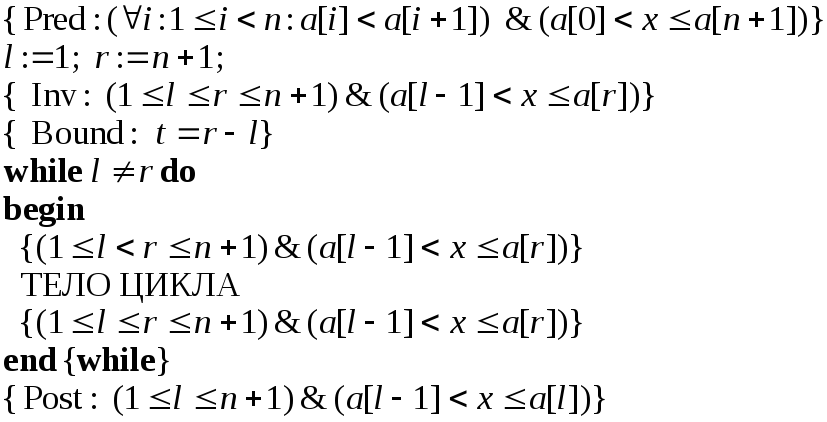
Рис.5.1. Набросок алгоритма
следовательно,
![]() .
Из аналогичных соображений при
.
Из аналогичных соображений при![]() должно получаться
должно получаться![]() .
Таким образом, тело цикла примет вид
.
Таким образом, тело цикла примет вид
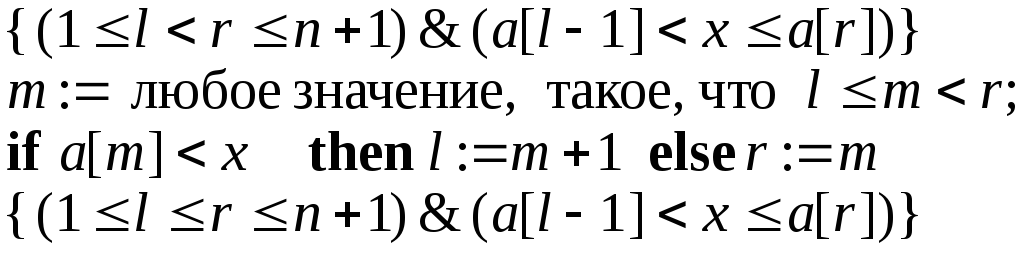
При
этом действительно, при условии
![]() ,
верном до выполнения тела цикла, получим
,
верном до выполнения тела цикла, получим![]() после завершения тела цикла.
после завершения тела цикла.
Выбирая
различными способами значение
![]() ,
получим различные алгоритмы поиска.
Например, при
,
получим различные алгоритмы поиска.
Например, при![]() имеем аналог линейного поиска. Здесь в
случае
имеем аналог линейного поиска. Здесь в
случае![]() поиск заканчивается, а при
поиск заканчивается, а при![]() размер интервала уменьшается всего на
1. Ясно, что более эффективный алгоритм
можно получить, выбирая значение
размер интервала уменьшается всего на
1. Ясно, что более эффективный алгоритм
можно получить, выбирая значение![]() на каждом шаге так, чтобы длина интервала
уменьшалась быстрее. Идея деления
интервала пополам приводит к следующему
алгоритму двоичного поиска:
на каждом шаге так, чтобы длина интервала
уменьшалась быстрее. Идея деления
интервала пополам приводит к следующему
алгоритму двоичного поиска:

Отметим,
что выбор значения
![]() удовлетворяет условию
удовлетворяет условию![]() .
.
Билет№38 Разработка алгоритма бинарного поиска №38
{ Pred : (i :1 n < n : a[i+1] ) }
{Post(0 L n)&(a[L]< x a[R])&(L=10Ln-1)&(a[L+1]=x) }
L:=0 ; R:=n+1 { a[L]<xa[R] }
While L+1<>R DO
Begin { (10 L< R-1 n) &(a[L]) < x a[R] ) }
m=(L+R) div 2
if a[m] < x Then L:=m else R:=m
end;
{ (0 L n) & (a[L] < a[]L+1) }
if L<>n then q:=(x=a=a[L+1] ) else q:=false
(смотри билет № 37)
Билет№39 Анализ алгор бинарного поиска №39
При
разработке алгоритма бинарного поиска
использовались лишь сравнения вида
![]() ,
где
,
где![]() ,
,![]()
![]()
![]() .
Определим наихудшее с точки зрения
быстродействия число сравнений, требуемое
алгоритмом.
.
Определим наихудшее с точки зрения
быстродействия число сравнений, требуемое
алгоритмом.
Теорема
1.
Максимальное
число сравнений, требуемое алгоритмом
бинарного поиска для нахождения места
предъявленного значения
![]() среди
среди
![]() ,есть
,есть
![]() .
.
 Для
доказательства теоремы рассмотрим так
называемое дерево бинарного поиска.
Каждому сравнению
Для
доказательства теоремы рассмотрим так
называемое дерево бинарного поиска.
Каждому сравнению
![]() в алгоритме сопоставим узел дерева и
обозначим его так, как показано на рис.
5.2,а.
В узле дерева (в круге) записано вычисляемое
на данном шаге значение
в алгоритме сопоставим узел дерева и
обозначим его так, как показано на рис.
5.2,а.
В узле дерева (в круге) записано вычисляемое
на данном шаге значение
![]() ,
а сверху слева и справа от него
значения границ рассматриваемой части
массива
,
а сверху слева и справа от него
значения границ рассматриваемой части
массива
![]() и
и![]() соответственно. К ветвям
соответственно. К ветвям![]() и
и![]() подвешиваются аналогичные узлы: справа
для случая
подвешиваются аналогичные узлы: справа
для случая
![]() и слева
для случая
и слева
для случая
![]() .
При
.
При![]() узел не содержит продолжений (является
листом дерева) и обозначается (рис.5.2,б)
специальным образом (номером, заключенным
в квадрат). Самый верхний (первый) узел
называется корнем дерева. Построенное
таким образом дерево описывает все
возможные исходы сравнений применительно
к заданным
узел не содержит продолжений (является
листом дерева) и обозначается (рис.5.2,б)
специальным образом (номером, заключенным
в квадрат). Самый верхний (первый) узел
называется корнем дерева. Построенное
таким образом дерево описывает все
возможные исходы сравнений применительно
к заданным
![]() и
и![]() .
На рис. 5.3 изображено дерево бинарного
поиска для
.
На рис. 5.3 изображено дерево бинарного
поиска для![]() (
(![]() ).
).

Рис. 5.3.
Дерево бинарного поиска для
![]() (
(![]() )
Отметим, что в таком дереве все
внутренние узлы имеют двух сыновей,
поскольку на любом шаге цикла левая и
правая части массива не пусты. Исходам
поиска соответствуют листья дерева,
пронумерованные от 1 до
)
Отметим, что в таком дереве все
внутренние узлы имеют двух сыновей,
поскольку на любом шаге цикла левая и
правая части массива не пусты. Исходам
поиска соответствуют листья дерева,
пронумерованные от 1 до![]() .
Внутренние узлы содержат номера элементов
массива, с которыми может сравниваться
значение
.
Внутренние узлы содержат номера элементов
массива, с которыми может сравниваться
значение![]() ,
т. е. все номера от 1 до
,
т. е. все номера от 1 до![]() .
Для данных
.
Для данных![]() и
и![]() последовательность сравнений, требуемых
алгоритмом бинарного поиска, задает
путь в дереве от корня к результирующему
листу.
последовательность сравнений, требуемых
алгоритмом бинарного поиска, задает
путь в дереве от корня к результирующему
листу.
Определим уровень узла в дереве следующим образом: уровень корня равен нулю, уровень любого другого узла на единицу больше уровня его непосредственного предка (отца). Глубину дерева определим как значение максимального из уровней его листьев.
 При
При
![]() получится ровное дерево с листьями
только на последнем
получится ровное дерево с листьями
только на последнем![]() -м
уровне. Например, для
-м
уровне. Например, для![]() дерево имеет вид, изображенный на
рис. 5.4,а.
Очевидно, максимальное число сравнений
алгоритма бинарного поиска для заданного
дерево имеет вид, изображенный на
рис. 5.4,а.
Очевидно, максимальное число сравнений
алгоритма бинарного поиска для заданного
![]() определяется глубиной дерева бинарного
поиска. Пусть
определяется глубиной дерева бинарного
поиска. Пусть![]() ,
или в иной форме записи
,
или в иной форме записи
![]() .
.
Покажем,
что
![]()
глубина дерева бинарного поиска в
массиве из
глубина дерева бинарного поиска в
массиве из
![]() элементов. Доказательство проведем
индукцией по
элементов. Доказательство проведем
индукцией по![]() .
При
.
При![]() = 1
имеем
= 1
имеем![]() (
(![]() ),
дерево изображено на рис. 5.4,б
и
его глубина равна 1.
),
дерево изображено на рис. 5.4,б
и
его глубина равна 1.
Пусть
для некоторого
![]() имеем
имеем![]() и глубина дерева есть
и глубина дерева есть![]() (индуктивное предположение). Покажем,
что при
(индуктивное предположение). Покажем,
что при![]() глубина дерева равна
глубина дерева равна![]() + 1.
Пусть
+ 1.
Пусть![]() чётно. На первом шаге алгоритма бинарного
поиска перейдем к одной из двух задач:
в левом поддереве с кол-ом исходов
чётно. На первом шаге алгоритма бинарного
поиска перейдем к одной из двух задач:
в левом поддереве с кол-ом исходов![]() /2
либо в правом поддереве с кол-ом исходов
/2
либо в правом поддереве с кол-ом исходов![]() /2.
Поскольку из неравенства
/2.
Поскольку из неравенства![]() при чётном
при чётном![]() следует неравенство
следует неравенство![]() ,
то с учетом индуктивного предположения
получим глубину дерева
,
то с учетом индуктивного предположения
получим глубину дерева![]() + 1.
При нечётном
+ 1.
При нечётном![]() на первом шаге задача разделится на две
подзадачи: в левом поддереве с числом
исходов
на первом шаге задача разделится на две
подзадачи: в левом поддереве с числом
исходов![]() ,
в правом
,
в правом
![]() .
Поскольку из неравенства
.
Поскольку из неравенства![]() при нечётном
при нечётном![]() следует
следует![]() и далее
и далее![]() ,
то с учётом индуктивного предположения
глубина дерева равна
,
то с учётом индуктивного предположения
глубина дерева равна![]() + 1.
Теорема доказана.
+ 1.
Теорема доказана.
Как
видно, число сравнений в алгоритме равно
либо
![]() (лист на последнем уровне), либо
(лист на последнем уровне), либо![]() 1
(лист на предпоследнем уровне). Число
листьев на этих уровнях легко определить
следующим образом. Пусть
1
(лист на предпоследнем уровне). Число
листьев на этих уровнях легко определить
следующим образом. Пусть
![]() или
или![]() ,
где
,
где![]() .
Пусть
.
Пусть![]() и
и![]()
число листьев на уровнях
число листьев на уровнях
![]() и
и![]() 1
соответственно. Тогда
1
соответственно. Тогда
![]() +
+![]() =
=![]()
общее число листьев. С другой стороны,
число внутренних узлов на предпоследнем
уровне равно
общее число листьев. С другой стороны,
число внутренних узлов на предпоследнем
уровне равно
![]() и к каждому из них подвешены по два узла
последнего уровня (листа), т. е.
и к каждому из них подвешены по два узла
последнего уровня (листа), т. е.![]() .
Таким образом, имеем два уравнения для
определения
.
Таким образом, имеем два уравнения для
определения![]() и
и
![]() :
:
![]() +
+![]() =
=![]() ,
,![]() ,
,
из
которых следует
![]() и
и![]() .
.
Отсюда
легко подсчитать среднее число сравнений,
требуемое алгоритмом бинарного поиска,
при условии, что все исходы (варианты
попадания
![]() в различные интервалы) равновероятны.
Действительно,
в различные интервалы) равновероятны.
Действительно,
![]() Очевидно,
что
Очевидно,
что
![]() ,
причем
,
причем![]() при
при![]() (
(![]() ),
т. е. в случае ровного дерева.
),
т. е. в случае ровного дерева.
Насколько хорош алгоритм бинарного поиска? Можно ли предложить лучший по числу сравнений алгоритм? На эти вопросы отвечает следующая теорема.
Теорема
2.
Для произвольного алгоритма поиска в
массиве, использующего сравнения, можно
подобрать такие исходные данные
![]() и
и
![]() ,что
применение к ним этого алгоритма
потребует не менее
,что
применение к ним этого алгоритма
потребует не менее
![]() сравнений.
сравнений.
Для
доказательства теоремы рассмотрим
последовательности вопросов, на каждый
из которых дается ответ:
да
или нет.
Каждой такой последовательности можно
сопоставить последовательность из
нулей и единиц. Если применение алгоритма
к исходным данным
![]() и
и![]() потребовало ровно
потребовало ровно![]() сравнений, а его применение к данным
сравнений, а его применение к данным![]() и
и![]() дало тот же результат (ту же
«01»-последовательность)
за первые
дало тот же результат (ту же
«01»-последовательность)
за первые
![]() шагов, то дальнейших сравнений уже не
потребуется и итог будет таким же, как
и в первом случае, поскольку порожденная
алгоритмом последовательность сравнений
рассматриваемого вида определит один
и тот же интервал локализации элементов
шагов, то дальнейших сравнений уже не
потребуется и итог будет таким же, как
и в первом случае, поскольку порожденная
алгоритмом последовательность сравнений
рассматриваемого вида определит один
и тот же интервал локализации элементов![]() и
и![]() (с точки зрения сравнения с элементами
массива
(с точки зрения сравнения с элементами
массива![]() предъявляемые
предъявляемые![]() и
и![]() «выглядят» одинаково). Следовательно,
среди получающихся «01»-последовательностей:
а) ни одна не является началом другой и
б) нет совпадающих последовательностей,
соответствующих разным интервалам
локализации. Если ограничиться длиной
последовательности
«выглядят» одинаково). Следовательно,
среди получающихся «01»-последовательностей:
а) ни одна не является началом другой и
б) нет совпадающих последовательностей,
соответствующих разным интервалам
локализации. Если ограничиться длиной
последовательности
![]() ,
то всего таких последовательностей
будет
,
то всего таких последовательностей
будет![]() .
Ясно также, что их должно быть не меньше,
чем число исходов применения алгоритма
(число распознаваемых ситуаций), т. е.
.
Ясно также, что их должно быть не меньше,
чем число исходов применения алгоритма
(число распознаваемых ситуаций), т. е.![]() и, следовательно,
и, следовательно,![]() или,
так какm
целое число, то
или,
так какm
целое число, то
![]() .
.
Теорема доказана.
Сопоставление теорем 1 и 2 показывает, что алгоритм бинарного поиска является оптимальным (наилучшим по числу сравнений).
Билет№40 Алгоритм програм бинар поиска №40