

2.1.2. Схеми інформаційних потоків
Діаграма Прецедентів візуально зображає різноманітні сценарії взаємодії між акторами (користувачами) і прецедентами (випадками використання); описує функціональні аспекти системи (бізнес логіку).
Діаграми Прецедентів відіграють важливу роль не тільки у комунікації між збирачами вимог до проекту і потенційними користувачами. Діаграми Прецедентів дописані бізнес логікою і детальними специфікаціями прецедентів, як джерельна інформація, успішно використовують учасники розробки проекту на всіх його фазах (зародження, дизайн, програмування, тестування, документування..). Добре продумані і завершені специфікації прецедентів легко перевтілюються у Тестові Випадки..
Елементи Діаграми Прецедентів:
Актор - користувач;
Прецедент – випадок використання, дія. Овал;
Граничні межі системи охоплюють усі випадки використання у системі.
Діаграма послідовностей дозволяє побачити, описати дії, що з’является під час виконання прецеденту. Діаграма містить ось часу, що спрямована зверху вниз; всіх виконавців; повідомлення або запити між виконавцями; посилання на інші прецеденти. Нижче приведена діаграма послідовностей для прецеденту «Web-інтерфейс та БД» (див рис. 2.2).
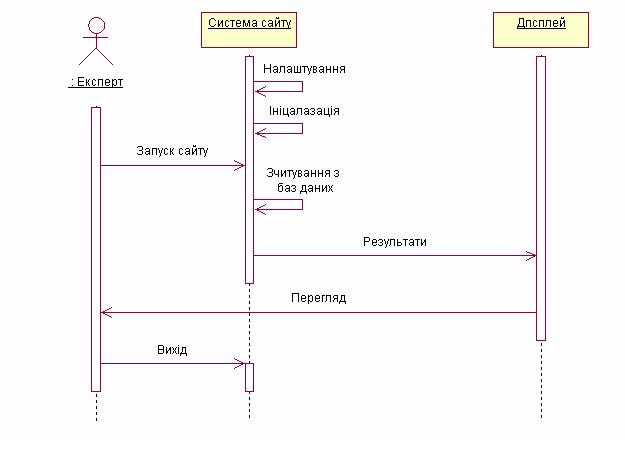
Рис. 2.2. Діаграма послідовностей для прецеденту «Запуск БД»
2.1.3. Схема Бази Даних (Діаграми)
Схема системи бази даних (від англ. Database scheme) - її структура, описана на формальному мові, підтримуваному системою управління базами даних (СКБД). В реляційних базах даних схема визначає таблиці, поля в кожній таблиці, а також відносини між полями і таблицями.[12]
Схеми в загальному випадку зберігаються в словнику даних. Хоча схема визначена на мові бази даних у вигляді тексту, термін часто використовується для позначення графічного представлення структури бази даних. [1]
Основними об'єктами схеми є таблиці і зв'язку.
 Рис.
2.3. Схема БД Прогнозного графу(Перший
варіант)
Рис.
2.3. Схема БД Прогнозного графу(Перший
варіант)
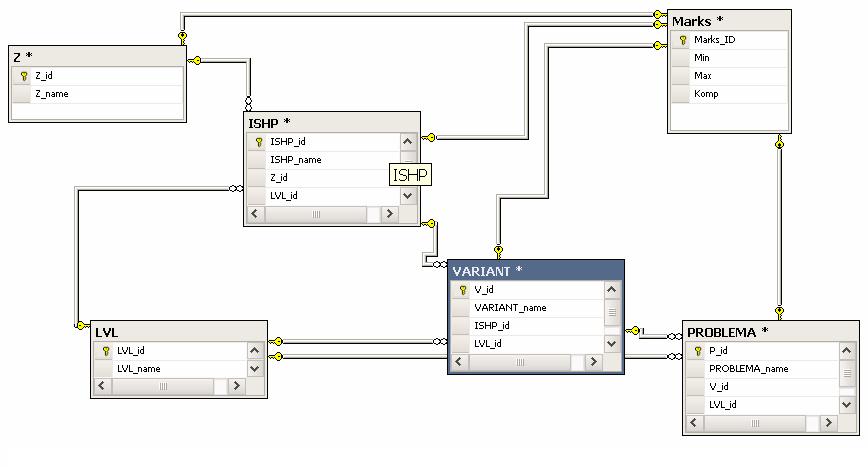 Рис.
2.4. Схема БД Прогнозного графу(Другий
варіант)
Рис.
2.4. Схема БД Прогнозного графу(Другий
варіант)
2.1.4. Опис Бази Даних
БД поділяється на два способи реалізації. Обидва способи дають змогу зберігати дані ієрархічно. Відмінність тільки в тому, що таблиця “Status”, яка містить статус проблеми, наприклад: альтернатива, проблема, вихідна проблема, варіант. У другому варіанті розбита на різні таблиці, які притаманні прогнозному графу. БД для WebФактор розроблена таким чином щоб МАІ та МПГ працювали ієрархічно та разом.
Таблиці були зроблені за допомогою SQL-запитів до БД.
Таблиця “Задачі” – в ній зберігаються задачі, які формуються перед прогнозним графом. Запит SQL мовою:
CREATE TABLE [dbo].[Z](
[Z_id] [int] IDENTITY(1,1) NOT NULL,
[Z_name] [nvarchar](50) COLLATE Cyrillic_General_CI_AS NULL,
CONSTRAINT [PK_Z] PRIMARY KEY CLUSTERED
(
[Z_id] ASC
)WITH (PAD_INDEX = OFF, IGNORE_DUP_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]
Запит 2.1.
Цим кодом створюється таблиця в якій є такі поля: авто інкремент, ідентифікатор, назва задачі.
Після цього створюється таблиця “Node”, вона зберігає всі задачі, проблеми, варіанти, вихідні проблеми, також має авто інкремент. Поля: коротка назва, звичайна назва, повна назва, зв’язок з таблицею задач полем “Node.JobNo” до поля “Job.JobNo” в таблиці вершин. SQL-запит:
CREATE TABLE [dbo].[Node](
[Node] [int] IDENTITY(1,1) NOT NULL,
[NodeShortName] [nchar](20) COLLATE Cyrillic_General_CI_AS NULL,
[NodeName] [nchar](40) COLLATE Cyrillic_General_CI_AS NULL,
[NodeFullName] [nvarchar](max) COLLATE Cyrillic_General_CI_AS NULL,
[JobNo] [int] NULL,
[Type] [int] NULL,
PRIMARY KEY CLUSTERED
(
[Node] ASC
)WITH (PAD_INDEX = OFF, IGNORE_DUP_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]
Запит 2.2.
Потім переходимо до таблиці “Double” – зберігає зв’язки між проблемами та варіантами(вершинами). Поля: ідентифікатор, зв’язок поля “Node” таблиці “double” з полем “Node” таблиці Node. SQL-запит:
CREATE TABLE [dbo].[DOUBLE](
[DOUBLE_id] [int] NOT NULL,
[Node] [int] NULL,
[Node1] [int] NULL,
PRIMARY KEY CLUSTERED
(
[DOUBLE_id] ASC
)WITH (PAD_INDEX = OFF, IGNORE_DUP_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]
Запит 2.3.
Таблиця “Status” – містить статус задачі: варіант, проблема, вихідна проблема. Поля: тип, статус. SQL-запит:
CREATE TABLE [dbo].[Status](
[Type] [int] NOT NULL,
[Status] [nvarchar](50) COLLATE Cyrillic_General_CI_AS NULL,
CONSTRAINT [PK_Status] PRIMARY KEY CLUSTERED
(
[Type] ASC
)WITH (PAD_INDEX = OFF, IGNORE_DUP_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]
Запит 2.4.
Таблиця “ExpertMarks” – зберігає оцінки які виставляються вершинам експертами: проблемам, варіантами експертами. Поля: ідентифікатор, вершина(проблема), ідентифікатор експерта, мінімальна та максимальна оцінка, компетентність.
CREATE TABLE [dbo].[ExpertNarks](
[IdExpertMark] [int] IDENTITY(1,1) NOT NULL,
[Node] [int] NULL,
[KodExptert] [int] NULL,
[MinMark] [int] NULL,
[MaxMark] [int] NULL,
[VidMark] [nchar](10) COLLATE Cyrillic_General_CI_AS NULL,
CONSTRAINT [PK__ExpertNarks__09DE7BCC] PRIMARY KEY CLUSTERED
(
Запит 2.5.
Таблиця “Expert” – зберігає дані про експертів їх ідентифікатори, паролі та логіни.
CREATE TABLE [dbo].[Expert](
[KodExptert] [int] IDENTITY(1,1) NOT NULL,
[Login] [nvarchar](10) COLLATE Cyrillic_General_CI_AS NULL,
[Password] [nvarchar](30) COLLATE Cyrillic_General_CI_AS NULL,
[Level] [int] NULL,
PRIMARY KEY CLUSTERED
(
[KodExptert] ASC
)WITH (PAD_INDEX = OFF, IGNORE_DUP_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]
Запит 2.6.