

1. Види, переваги та недоліки numa-систем
Архітектура з неоднорідним доступом до пам'яті (NUMA - Non-Uniform Memory Access). Система складається з однорідних базових модулів (плат), що складаються з невеликої кількості процесорів і блоку пам'яті. Модулі об'єднані за допомогою високошвидкісного комутатора. Підтримується єдиний адресний простір, апаратно підтримується доступ до віддаленої пам'яті, тобто до пам'яті інших модулів. При цьому доступ до локальної пам'яті в кілька разів швидше, ніж до віддаленої. Кожен модуль досить часто є SMP-системою, яка доповнена спеціальною системою доступу до віддаленої пам'яті. Вперше ідею гібридної архітектури запропонував Стів Волох і втілив в системах серії Exemplar. Варіант Волоха - система, що складається з 8-ми SMP вузлів. Фірма HP купила ідею і реалізувала на суперкомп'ютерах серії SPP. Ідею підхопив Сеймур Крей (Seymour R.Cray) і додав новий елемент - когерентний кеш, створивши так звану архітектуру cc-NUMA (Cache Coherent Non-Uniform Memory Access), яка розшифровується як "неоднорідний доступ до пам'яті із забезпеченням когерентності кешів". Він її реалізував на системах типу Origin. Масштабованість NUMA-систем обмежується обсягом адресного простору, можливостями апаратури підтримки когерентності кешей і можливостями операційної системи з управління великим числом процесорів. На даний момент, максимальне число процесорів в NUMA-системах становить 256 (Origin2000), що набагато більше, ніж можливе число процесорів SMP-систем. Зазвичай вся система працює під управлінням єдиної ОС, як в SMP. Але можливі також варіанти динамічного "підрозділу" системи, коли окремі "розділи" системи працюють під управлінням різних ОС (наприклад, Windows NT і UNIX в NUMA-Q 2000). Операційна система повинна на відміну від SMP враховувати неоднорідність адресного простору для кожного процесора, щоб уникати частого міжмодульного доступу. Модель програмування, повністю аналогічно SMP.
Переваги і недоліки. NUMA-системи за своїми параметрами аналогічні SMP-систем. Її призначення - частково усунути головний недолік SMP - низьку масштабованість. Це досягається за рахунок створення віртуальної загальної пам'яті. Масштабованість виростає на порядок, але за це доводиться платити збільшенням вартості апаратного та програмного забезпечення. Апаратура ускладнюється за рахунок появи єдиного комунікаційного середовища, до якості якого пред'являються високі вимоги. Програмне забезпечення ускладнюється в основному за рахунок необхідності створення нової ОС, що враховує особливості архітектури.
2. Узагальнена передача даних від одного процесу всім процесам.
Узагальнена операція передачі даних від одного процесу до всіх процесів (розподіл даних) відрізняється від широкомовної розсилки тим, що процес передає процесам різні дані (див. рис. 4.4). Виконання даної операції може бути забезпечено за допомогою функції:
int MPI_Scatter(void *sbuf,int scount,MPI_Datatype stype, void *rbuf,int rcount,MPI_Datatype rtype, int root, MPI_Comm comm),
де
sbuf, scount, stype – параметри переданого повідомлення (scount
кількість елементів, переданих на кожний процес), rbuf, rcount, rtype – параметри повідомлення, прийнятого в процесах, root – ранг процесу, що пересилає дані, comm – комунікатор, в межах якого виконується передача даних.
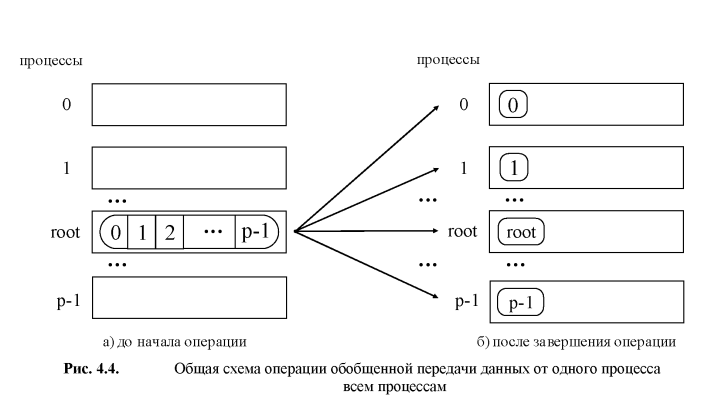
При виклику цієї функції процес з рангом root зробить передачу даних всім іншим процесам в комунікаторі. Кожному процесу буде надіслано scount елементів. Процес з рангом 0 отримає блок даних з sbuf з елементів з індексами від 0 до scount-1, процесу з рангом 1 буде відправлений блок з елементів з індексами від scount до 2 * scount-1 і т.д. Тим самим, загальний розмір повідомлення, що відправляється повинен бути рівний scount * p елементів, де p є кількість процесів в комунікаторі comm. Слід зазначити, оскільки функція MPI_Scatter визначає колективну операцію, виклик цієї функції при виконанні розсилки даних повинен бути забезпечений у кожному процесі комунікатора. Відзначимо також, що функція MPI_Scatter передає всім процесам повідомлення однакового розміру. Виконання більш загального варіанта операції розподілу даних, коли розміри повідомлень для процесів можуть бути різного розміру, забезпечується за допомогою функції MPI_Scatterv.
БІЛЕТ №15
1. Системи з масовою паралельною обробкою MPP.
|
MPP| (massive| parallel| processing|) – масивно-паралельна архітектура. Головна особливість такої архітектури полягає в тому, що пам'ять фізично розділена. В цьому випадку система будується з|із| окремих модулів, що містять|утримують| процесор, локальний банк операційної пам'яті (ОП), комунікаційні процесори (роутери|) або мережеві|мережні| адаптери, іноді|інколи| – жорсткі диски і/або інші пристрої|устрої| введення/виводу|висновку,виведення|. По суті, такими модулями є повнофункціональні комп'ютери (див. Рисунок.3.2). Доступ до банку ОП з|із| даного модуля мають тільки|лише| процесори (ЦП) з|із| цього ж модуля. Модулі з'єднуються спеціальними комунікаційними каналами. Користувач може визначити логічний номер процесора, до якого він підключений, і організувати обмін повідомленнями|сполученнями| з|із| іншими процесорами. Використовуються два варіанти роботи операційної системи (ОС) на машинах MPP-архітектури|. У одному повноцінна операційна система (ОС) працює тільки|лише| на машині (front-end|), що управляє; на кожному окремому модулі функціонує сильно урізаний|урізати| варіант ОС, що забезпечує роботу тільки|лише| розташованою|схильною| в нім гілки паралельного застосування. У другому варіанті на кожному модулі працює повноцінна UNIX-подібна| ОС, що встановлюється окремо.

Рисунок. 3.2. Схематичний вид архітектури з|із| роздільною пам'яттю
Головною перевагою систем з|із| роздільною пам'яттю є|з'являється,являється| хороша|добра| масштабованість: на відміну від SMP-систем|, в машинах з|із| роздільною пам'яттю кожен процесор має доступ тільки|лише| до своєї локальної пам'яті, у зв'язку з чим не виникає необхідності в по тактовій| синхронізації процесорів. Практично всі рекорди по продуктивності на сьогодні встановлюються на машинах саме такої архітектури, процесорів, що складаються з декількох тисяч (ASCI| Red|, ASCI| Blue| Pacific|).
Недоліки|нестачі|:
- відсутність загальної|спільної| пам'яті помітно знижує швидкість міжпроцесорного обміну, оскільки немає загального|спільного| середовища|середи| для зберігання даних, призначених для обміну між процесорами. Потрібна спеціальна техніка програмування для реалізації обміну повідомленнями|сполученнями| між процесорами;
- кожен процесор може використовувати тільки|лише| обмежений об'єм|обсяг| локального банку пам'яті;
- унаслідок|внаслідок| вказаних архітектурних недоліків|нестач| потрібні значні зусилля для того, щоб максимально використовувати системні ресурси. Саме цим визначається висока ціна програмного забезпечення для масивно-паралельних систем з|із| роздільною пам'яттю.
Системами з|із| роздільною пам'яттю є|з'являються,являються| суперкомп'ютери БОС-1000, IBM| RS/6000 SP|, SGI/CRAY T3E|, системи ASCI|, Hitachi| SR8000|, системи Parsytec|.
Машини останньої серії CRAY| T3E| від SGI|, засновані на базі процесорів Dec| Alpha| 21164, здатні|здібні| масштабуватися до 2048 процесорів.
При роботі з|із| MPP-системами| використовують так звані Massive| Passing| Programming| Paradigm| – парадигму програмування з|із| передачею даних (MPI|, PVM|, BSPlib|).