

VIII. Методы контроля метеорологической информации
8.1. Этапы автоматизированных систем контроля
Данные гидрометеорологических наблюдений от момента своего возникновения до выдачи в виде прогнозов или справочников проходят большой путь, на отдельных отрезках которого производят различные преобразования информации. Основные этапы прохождения информации: регистрация наблюдений, занесение на машинные носители, передача в центры обработки, ввод в ЭВМ, преобразование, контроль, обработка, вывод результатов на хранение и для использования. На каждом из этих этапов в информацию могут проникать различные ошибки. Причина их - неисправности и сбои используемой аппаратуры, каналов связи, неверные действия оператора и т. д.
В процессе практического использования ЭВМ для обработки гидрометеорологических данных удалось установить, что эти ошибки достигают больших значений. При обычных (ручных) методах работы специалист такую ошибку сразу же заметит, так как она сильно искажает естественный ход того или иного элемента во времени или пространстве. ЭВМ сама по себе такими способностями не обладает. В связи с этим разрабатываются и используются автоматические методы контроля качества исходных данных.
Широко известным является деление ошибок на две группы: систематические и случайные. Систематическими ошибками считаются те, которые обычно появляются в информации регулярно и связаны с неисправностью прибора или неверным с ним обращением оператора. Случайные ошибки бывают не всегда. Их проявление обусловлено лишь чисто случайными факторами. Большие случайные ошибки называются еще грубыми промахами. Эти ошибки могут сильно исказить естественный ход элемента и поэтому их легче обнаружить.
С позиций достоверности гидрометеорологическая информация делится на три группы: достоверная, сомнительная и ошибочная.
К достоверной информации относят те результаты наблюдений, правильность которых не вызывает сомнений в том смысле, что они хорошо согласуются с представлением опытного специалиста о характере наблюденного процесса или явления. Например, на Среднем Урале информация о температуре воздуха зимой, равной -20 °С, обычно не вызывает сомнений и может считаться достоверной.
Сомнительной информацией считается та, которая хотя и возможна, но слабо согласуется с известными представлениями о ней (например, с ходом этой величины во времени или пространстве). Такие значения при более тщательном анализе могут оказаться как достоверными, так и ошибочными.
Ошибочной информацией называется та, в которой тем или иным методом обнаружены ошибки. Эти ошибки иногда бывают такими большими, что ошибочность значений уже не вызывает сомнения.
До использования ЭВМ в обработке информации практически не существовало четких численных (числовых) критериев отнесения наблюденного гидрометеорологического элемента к той или иной из трех групп. Разработка методов автоматического контроля потребовала определения таких критериев, без которых не может быть реализована на ЭВМ ни одна программа контроля.
Назовем системой контроля технологию поиска и исправления ошибок информации. В зависимости от степени автоматизации этой технологии система может быть автоматической или автоматизированной. Автоматической называется такая система, в которой на ЭВМ осуществляются все операции по поиску и исправлению ошибок. В автоматизированной системе контроля некоторая часть информации контролируется дополнительно специалистом, который принимает окончательное решение о необходимости и возможности исправления того или иного значения. На машину в этом случае возлагается задача лишь отыскания сомнительных элементов информации. Существующие в настоящее время системы контроля результатов гидрометеорологических наблюдений являются в основном автоматизированными.
Общая технологическая схема автоматизированного контроля гидрометеорологической информации при ее обработке на ЭВМ следующая. Результаты наблюдений вводятся в ЭВМ и раскодируются. Затем каждый элемент сообщения проверяется по тем или иным правилам. При этом контролируемое значение относится к одной из трех указанных выше групп по характеру достоверности. В соответствии с отнесением данных наблюдений к той или иной группе им присваивается некоторый кодовый признак достоверности. Этот признак обычно записывается в определенных разрядах ячейки. Чаще всего используются три двоичных разряда, запись в которых может осуществляться, например, по такой системе: 0 - значение достоверное, 1 - значение сомнительное, 2 - значение ошибочное.
Далее над достоверной информацией осуществляются все необходимые вычисления. Ошибочная информация в некоторых случаях может быть автоматически восстановлена, например, по данным наблюдений соседних пунктов или по данным наблюдений одного пункта в смежные сроки. Тогда дальнейшие операции с этим элементом проводятся, как и с обычной достоверной информацией.
Над сомнительными данными иногда производят и другие операции по контролю на основе привлечения некоторых дополнительных сведений (если это возможно). Если в результате таких действий сомнительное значение удастся отнести к достоверным или ошибочным данным, то над ним проводятся соответствующие этим группам операции. Если все же такое решение не будет принято, то сомнительное значение выводится на печать с уведомлением о наиболее вероятном характере ошибки. Если же весь массив информации при наличии в нем ошибок или сомнительной информации не может быть далее подвергнут обработке, то он выводится в специальный файл. Информация, отнесенная к достоверной и прошедшая полную обработку по заданной программе, записывается в другой файл.
Сведения об ошибках, напечатанные ЭВМ в виде специальной таблицы, анализируются специалистом, в результате чего составляется ведомость на исправление ошибок. Этот анализ и исправление информации могут осуществлять в центрах обработки, если количество ошибок невелико, или в пунктах наблюдений, когда количество их значительно или характер их таков, что требует привлечения дополнительных исходных данных, хранящихся в этих пунктах.
Данные из ведомости вводятся в ЭВМ, а затем исправленные значения объединяются с основным массивом. Дальнейшие действия над таким объединенным массивом осуществляются по общей схеме, т. е. производится повторный контроль. Эти циклы могут повторяться несколько раз для получения достоверной информации.
Описанная схема используется для контроля в основном режимной гидрометеорологической информации. Для отдельных видов этой информации общая схема иногда несколько видоизменяется. Что касается оперативных данных, то здесь следует учесть уменьшение возможностей для исправления ошибочных данных путем повторного запроса достоверных данных из пунктов наблюдений, так как весь цикл обработки информации осуществляется в течение всего лишь нескольких часов. Здесь, как правило, ошибочная информация просто бракуется и исключается из дальнейшей обработки.
В гидрометеорологии разработано и внедрено в практику множество методов контроля как оперативной, так и режимной информации. Все методы можно объединить в две группы: синтаксический контроль и логический контроль. Одновременно эти группы являются и двумя этапами контроля. На первом этапе выявления ошибок используются синтаксические методы контроля, на втором - логические.
Первая группа методов контроля существует для проверки структуры (синтаксиса) построения сообщения. Каждое сообщение строится по строго определенным правилам (схемам), которые и берутся за основу методов синтаксического контроля. Синтаксический контроль обычно осуществляется в ЭВМ одновременно с раскодированием информации. В числе алгоритмов, по которым проводится проверка, используются:
проверка каждого символа сообщения и исключение запрещенных комбинаций элементов. Например, форматом представления некоторых видов гидрометеорологических данных предусматривается использовать только цифровые символы кода; наличие букв в таком случае будет указывать на ошибку в сообщении;
проверка наличия тех элементов, которые должны быть в сообщении в обязательном порядке. Это относится, например, к призрачной части сообщения;
проверка знака числа у тех элементов наблюдения, для которых этот знак строго определен. Например, дата и срок наблюдений, видимость, давление и другие элементы должны быть всегда положительными величинами;
контроль формата представления величины (количество разрядов символов, занятых тем или иным элементом сообщения, не должно превышать определенного числа). Такой алгоритм используется в тех случаях, если длина групп в сообщении не является величиной постоянной;
анализ точности записи числа путем проверки положения запятой в значениях, перфорация которых осуществляется в естественном виде (т. е. со знаком запятой);
анализ сочетаний отдельных элементов или групп сообщения. Например, если общее количество облачности равно нулю, то должны быть равны нулю значения облачности верхнего и среднего ярусов;
проверка правильности общего построения сообщения: общего количества групп, наличия признаков начала и конца в сообщении и т. п.
Здесь перечислены лишь некоторые алгоритмы синтаксического контроля гидрометеорологической информации.
Уже на этапе синтаксического контроля могут быть выявлены отдельные случайные ошибки или грубые промахи. Однако после этого этапа контроля часть ошибок в информации может еще сохраниться. По этой причине наряду с методами синтаксического контроля используются методы логического контроля. В основу последних положены различные закономерности изменения того или иного элемента наблюдений во времени или пространстве, взаимосвязи отдельных элементов и их комплексов.
Одним из приемов, который используется для контроля, является установление для каждого элемента некоторых экстремальных (максимальных и минимальных) границ его изменения (контроль правдоподобия). Эти границы могут устанавливаться по известным физическим представлениям или по результатам многолетних наблюдений.
Для таких элементов, как температура воздуха, пределы изменений устанавливаются по фактическим наблюдениям. Например, если за длительный период работы метеорологической станции температура воздуха не была ниже -45 °С и не поднималась выше +35 °С, то эти значения могут быть приняты в качестве предельных (пределов) при контроле текущей информации.
В общем случае алгоритм контроля величины любого элемента (Xi) на пределы может быть представлен следующим выражением:
Хмакс ≥ Xi ≥ Хмин
где Хмин, Хмакс - минимальный и максимальный пределы для данной величины.
Эти пределы задаются в программах контроля информации на ЭВМ в виде констант (постоянных значений). Такие константы могут задаваться одинаковыми для всех пунктов наблюдения и для всех месяцев или сезонов года, но можно задавать их и более точно, выбирая для каждого месяца или сезона, а также для каждого пункта свое значение. В таком случае количество констант в программе увеличивается и несколько усложняется программа контроля, так как каждый раз в наборе констант необходимо отыскивать нужное значение, соответствующее данному месяцу и конкретному посту.
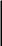
 Алгоритм
контроля на пределы нашел широкое
применение при анализе результатов
гидрометеорологических наблюдений. Он
может использоваться при контроле как
оперативной, так и режимной информации.
Метод контроля на пределы по своему
характеру близок к синтаксическому
контролю и является первым этапом
логического контроля.
Алгоритм
контроля на пределы нашел широкое
применение при анализе результатов
гидрометеорологических наблюдений. Он
может использоваться при контроле как
оперативной, так и режимной информации.
Метод контроля на пределы по своему
характеру близок к синтаксическому
контролю и является первым этапом
логического контроля.
Алгоритмы логического контроля оперативной информации строятся в основном на сравнении между собой значений элементов, наблюдаемых одновременно во многих соседних пунктах. Сюда относятся так называемые методы объективного анализа. На данном этапе проверяется согласованность наблюдений соседних станций. Этот прием называется «горизонтальным контролем» в отличие от «вертикального контроля», при котором используется аэрологическая информация только одного пункта наблюдения. В качестве одного из основных алгоритмов при этом применяется метод оптимальной интерполяции. Методика горизонтального контроля основывается на следующем.
С помощью метода оптимальной интерполяции по данным о значении элемента на окружающих станциях вычисляют значение его на проверяемой станции. Затем находят разность ΔХ=ХР – ХН между рассчитанным (ХР) и наблюденным (ХН) значениями элемента. Если разность окажется большой, то можно высказать предположение о наличии ошибки в исходной информации данной станции. Допустимое значение разности определяется экспериментальным путем по результатам предыдущих наблюдений и закладывается в программу контроля. При оптимальной интерполяции значение элемента в контролируемой точке (принимаем его за неизвестное) вычисляется сразу по нескольким соседним станциям, показания которых берутся с некоторыми весовыми коэффициентами, устанавливаемыми на основе многолетних данных. Эти коэффициенты выбираются таким образом, чтобы средняя квадратическая ошибка интерполяции была минимальной.
Наличие значительных расхождений между вычисленным и наблюденным значениями элемента в точке еще не указывает на местоположение ошибки, которая может находиться как в данных контролируемой станции, так и в показаниях соседних станций. Для определения ее местоположения из расчета последовательно исключают каждую из окружающих точек. Если в результате такого исключения разность становится допустимой, можно предположить, что ошибочны данные как раз этой точки из окружения. Если же при последовательном исключении всех точек разность не уменьшилась до требуемого значения, информация контролируемой станции предполагается ошибочной и подлежит исправлению. Исправление осуществляется путем замены ошибочного значения на значение элемента, вычисленное методом оптимальной интерполяции. В этом большое преимущество данного метода перед теми, которые не позволяют автоматически исправить ошибочное значение.
Описанный выше алгоритм позволяет довольно легко обнаружить одиночные станции с ошибочными данными наблюдений. Однако если грубые ошибки содержатся одновременно в данных наблюдений на нескольких станциях, расположенных близко друг от друга, то в отыскивании ошибок возникают определенные трудности. В этом случае ошибочные значения, используемые одновременно в обработке, могут взаимно уменьшать разность между вычисленным и наблюденным значениями контролируемого элемента и тем самым делают невозможным их поиск. Поэтому в гидрометеорологии прибегают к повторному горизонтальному контролю, а также к предварительному устранению грубых ошибок с помощью так называемого «вертикального контроля».
Методы вертикального контроля наиболее применимы для тех видов информации, которые включают в себя набор сведений об одних и тех же элементах за несколько сроков наблюдений или по нескольким высотам (уровням) в одной и той же точке (станции). К таким видам относится, например, аэрологическая информация, структура сообщения которой содержит сведения о температуре, давлении, влажности воздуха и других характеристиках на различных высотах от поверхности земли в пункте наблюдения. Другим примером информации, пригодной для вертикального контроля, являются все виды режимных данных, так как они включают большое количество сведений об одних и тех же элементах (от срока к сроку) в пункте наблюдения.
При вертикальном контроле, как и при других видах контроля, используются проверки на соответствие контролируемой величины различного рода физическим представлениям (контроль согласованности). Например, при контроле аэрологических данных некоторые из элементов сообщения (геопотенциал изобарических поверхностей и температура воздуха) должны соответствовать уравнению статики (статический контроль). При этом учитывается изменение температуры воздуха с высотой. В настоящее время статический контроль широко используется в различных системах автоматической обработки аэрологической информации. Как показывает опыт, с помощью этого метода удается обнаруживать сравнительно небольшие ошибки в значениях геопотенциала и температуры и в большинстве случаев исправлять ошибочные значения.
Еще одним способом контроля согласованности является геострофический контроль, т.е. проверка выполняемости геострофических соотношений, связывающих поля ветра и горизонтального градиента. В принципе с помощью геострофического контроля можно проверять данные как о ветре, так и о геопотенциале. Однако значения геопотенциала, как только что упоминалось, можно проверять с помощью статического контроля. Кроме того, геопотенциал менее изменчив в пространстве, нежели ветер, вследствие чего контроль непрерывности по горизонтали и по вертикали более эффективен для геопотенциала, чем для ветра. По этим причинам целесообразно применять геострофический контроль как один из методов проверки данных о ветре, считая тем самым, что данные о геопотенциале уже проконтролированы успешно другими методами. Такой геострофический контроль ветра может проводиться путем вычисления для пункта ветрового зондирования геострофического ветра по данным наблюдений о геопотенциале.
При контроле согласованности данных по высоте можно обнаруживать случайные ошибки разных типов, а именно ошибки в наблюдениях, расчете некоторых элементов, кодировании и передаче данных. Ошибки, связанные с неисправностью измерительной аппаратуры или с неправильным снятием показаний приборов, таким путем непосредственно не обнаруживаются, так как при них в данных не возникает несоответствия между значениями элемента на различных высотах. Подобные ошибки могут быть выявлены лишь с помощью приемов горизонтального контроля, в том числе и путем объективного анализа гидрометеорологических полей.
Другим примером метода вертикального контроля служит проверка согласованности данных по срокам наблюдений. Последовательность операций здесь примерно та же, что и при проверке согласованности данных по высоте. Согласно этому алгоритму, анализируется значение элемента в пункте наблюдений от срока к сроку. При этом анализ может осуществляться несколькими способами, из которых наиболее распространенным является интерполяционный.
При интерполяционном способе проверки согласованности наблюдений от срока к сроку каждое из них последовательно исключается из ряда и восстанавливается путем интерполяции между наблюдениями в смежные сроки. После такого восстановления будем иметь за один и тот же срок два значения элемента — наблюденное (ХН) и вычисленное (ХВ). Далее определяется разность между этими двумя значениями:
ΔХ = ХН –ХВ
по величине которой можно судить о достоверности контролируемого элемента наблюдения (ХН). Суждение о достоверности, сомнительности или ошибочности наблюдения принимается по схеме:
если |ΔХ| < с1 то ХН - достоверное значение;
если с1 < |Δх| < с2, то ХН - сомнительное значение;
если |ΔХ| > с2, то ХН - ошибочное значение.
Здесь с1 - некоторая числовая константа, за которую при достоверных значениях ХН не должно выходить абсолютное значение ΔХ; с2 - другая константа, выход за которую абсолютного значения ΔХ происходит только в тех случаях, когда значение ХН явно ошибочно.
Очевидно, что если величина ΔХ попадает в диапазон между с1 и с2, то соответствующее ей контролируемое значение ХН должно быть отнесено к разряду сомнительных, так как абсолютное значение ΔХ, с одной стороны, уже слишком велико, чтобы значение ХН могло быть безусловно принято за достоверное, но, с другой стороны, оно еще недостаточно велико, чтобы контролируемое значение можно было отнести к разряду ошибочных. Для значений ХН, отнесенных к сомнительным, применяются дополнительные приемы анализа в целях отнесения их либо к достоверным, либо к ошибочным. Эти приемы основаны, как правило, на использовании некоторой дополнительной информации данного или других сообщений.
Если сомнительное значение удалось отнести к разряду достоверных, то далее над ним осуществляются все необходимые вычислительные операции. Если значение признано ошибочным, оно может быть автоматически исправлено машиной. Чем меньше абсолютная разность между наблюденным и соответствующим ему вычисленным (восстановленным) значением, тем больше вероятность того, что значение контролируемого элемента является достоверным.
Константы с1 и с2 заблаговременно вводятся в ЭВМ и непосредственно включаются в состав машинных программ. Следует, однако, сказать, что при определении численного значения величин с1 и с2 для каждого конкретного элемента гидрометеорологических наблюдений встречаются серьезные трудности. Действительно, если назначить с1 и с2 слишком малыми, то очень большое количество наблюдений будет относиться машиной к сомнительным или ошибочным. При этом возникает необходимость ручного дополнительного анализа или даже исключения (бракования) правильных данных.
Некоторое распространение в программах автоматизированного контроля гидрометеорологической информации получили так называемые статистические методы. Суть их заключается в том, что результаты наблюдений за определенный промежуток времени (например, за месяц) рассматриваются как случайный стационарный ряд, к которому применимы определенные статистические законы. Эти законы устанавливают определенные соотношения между значениями элементов числового ряда и частотой их появления. Статистические методы позволяют отыскивать лишь грубые промахи. Недостатком этих методов является то, что они не позволяют исправить ошибочное значение. Для исправления ошибки приходится пользоваться другими методами.
Систематические ошибки, которые обычно не достигают больших значений, практически невозможно контролировать описанными выше способами. Контроль таких ошибок основан на том свойстве, что их влияние сказывается тем больше, чем за более длительный период времени анализируется информация. Проникая в данные каждого наблюдения с одним и тем же знаком, ошибки суммируются при суммировании наблюденных значений. Такое суммирование, как известно, производится при подсчете средних значений (за месяц, год). Именно эти средние значения и подвергаются дополнительному контролю на предмет выявления систематических ошибок. При этом используются методы горизонтального контроля. Средние значения контролируемой станции сравниваются с такими же данными той из соседних станций, по которой в предыдущие годы существовала устойчивая связь.
Большинство алгоритмов контроля дает положительный результат лишь в том случае, если количество ошибок в информации невелико и если они имеют случайный характер. Однако и в этом случае часть ошибок в информации не будет обнаружена. К ним относятся ошибки, которые находятся в пределах естественных колебаний элемента. Для получения лучших результатов в автоматизированном контроле обычно используют сочетание описанных выше методов.