

САНКТ-ПЕТЕРБУРГСКАЯ ГОСУДАРСТВЕННАЯ МЕДИЦИНСКАЯ АКАДЕМИЯ
имени И.И.Мечникова
КАФЕДРА МЕДИЦИНСКОЙ ИНФОРМАТИКИ И СТАТИСТИКИ
А.А.Самусь
Дисперсионный анализ данных с помощью Microsoft Excel
Методические указания для студентов,
аспирантов, слушателей ФПК и ФУВ.
САНКТ-ПЕТЕРБУРГ
2000
1. Основные понятия дисперсионного анализа.
Основной целью дисперсионного анализа (в США называется ANOVA) является исследование значимости различия между средними нескольких групп значений наблюдаемого признака.
Откуда произошло название Дисперсионный анализ? Может показаться странным, что процедура сравнения средних называется дисперсионным анализом. В действительности, это связано с тем, что при исследовании статистической значимости различия между средними нескольких групп, мы на самом деле сравниваем (см. ниже) выборочные дисперсии.
Дисперсионный анализ позволяет оценить влияние отдельных факторов на результативный признак. Фактором называется то, что оказывает влияние на результативный признак, а конкретное значение фактора называют уровнем фактора. Например, если требуется выявить влияние состава лекарств на эффективность лечения, то фактор - это лекарство, а его уровни - состав лекарства.
В зависимости от числа факторов различают однофакторный, двухфакторный и многофакторный дисперсионный анализ.
Рассмотрим алгоритм однофакторного дисперсионного анализа подробнее.
Пусть на признак Y воздействует один фактор A, который имеет k постоянных уровней и пусть число наблюдений на каждом уровне (в каждой группе) одинаково и равно n.
Следовательно, наблюдалось N=k*n значений Yij признака, где i - номер испытаний в группе, j - номер группы. Результаты испытаний представлены в виде таблицы (дисперсионного комплекса) на рисунке 1:
Номер |
Уровни фактора |
|||
испытаний |
A1 |
A2 |
... |
Ak |
1 |
Y11 |
Y12 |
... |
Y1k |
2 |
Y21 |
Y22 |
... |
Y2k |
.. |
... |
... |
... |
... |
n |
Yn1 |
Yn2 |
... |
Ynk |
Групповая средняя |
M1 |
M2 |
... |
Mk |
Рисунок 1
Предполагается, что Y подчиняется закону нормального распределения с условным математическим ожиданием j, зависящим от уровней фактора Aj, и постоянной, хотя и неизвестной, дисперсией.
Задача сводится к проверке на уровне значимости p нулевой гипотезы Ho:
1=2=...=k (равенство всех математических ожиданий).
Другими словами, требуется установить значимо или не значимо различаются выборочные средние.
Проведение дисперсионного анализа в этом случае включает в себя следующие этапы:
Этап 1. Вычисление средних арифметических в группах:
![]()
(1)
Этап 2. Вычисление общего среднего значения всего комплекса M:
![]() (2)
(2)
Э![]() тап
3. Вычисление
общей суммы квадратов отклонений
наблюдаемых значений признака от общей
средней:
тап
3. Вычисление
общей суммы квадратов отклонений
наблюдаемых значений признака от общей
средней:
(3)
Э![]() тап
4. Вычисление
факторной суммы квадратов отклонений
групповых средних от общей средней:
тап
4. Вычисление
факторной суммы квадратов отклонений
групповых средних от общей средней:
(4)
Sфак характеризует рассеяние "между группами", обусловленное влиянием фактора.
Этап 5. При выполнении всех условий применения дисперсионного анализа общая сумма квадратов отклонений равна
![]() (5)
(5)
где Sост - остаточная сумма квадратов отклонений, которая характеризует рассеяние "внутри групп" и которая обусловлена посторонними не учитываемыми в данном эксперименте факторами. Поэтому остаточную сумму квадратов отклонений вычисляют по формуле:
![]()
(6)
Этап 6. Определение несмещенных оценок факторной и остаточной дисперсий. Разделив суммы квадратов отклонений на соответствующее число степеней свободы, получим факторную и остаточную дисперсии
![]()
(7)
![]()
(8)
Э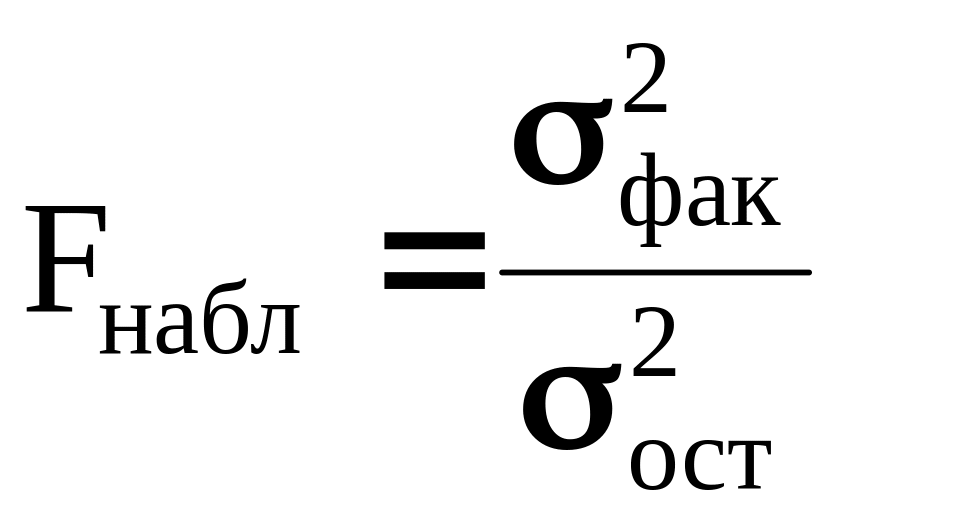 тап
7. Вычисление
отношения факторной и остаточной
дисперсий
тап
7. Вычисление
отношения факторной и остаточной
дисперсий
(9)
Этап 8. Для проверки достоверности влияния фактора на результативный признак величина Fнабл сравнивается с критическим значением Fкр, полученным по таблице F-распределения для уровня значимости p и числа степеней свободы k-1 и k(n-1).
Если Fнабл > Fкр, то нулевая гипотеза отвергается с вероятностью ошибки равной p. Из этого следует, что фактор A влияет на результативный признак Y. В противном случае принимается нулевая гипотеза: влияние фактора не подтверждается.
Компьютерные программы для статистической обработки данных кроме F-отношения вычисляют также уровень значимости наблюдаемой статистики. В этом случае для принятия решения необходимо сравнивать уровень значимости с заданным значением (обычно 0,05): если величина значимости p<0,05, то нулевая гипотеза отвергается.
Этап 9. Вычисление силы влияния фактора А, если влияние фактора А на результативный признак можно считать достоверным.
Сила влияния KА фактора А на формирование результативного признака определяется отношением факторной суммы квадратов к общей в процентах, т.е.:
![]()
(10)
Соотношения (1) - (10) описывают методику расчета для однофакторного комплекса с одинаковым числом наблюдений на каждом уровне фактора. При проведении многофакторного дисперсионного анализа вычислительные процедуры усложняются. Например, в случае двухфакторного анализа проверяется несколько нулевых гипотез об отсутствии влияния на результативный признак Y: фактора A, фактора B, взаимодействия двух факторов (A и B).