

Алгоритм списков в динамической памяти
Он предполагает, что фактическим значением элемента хеш-таблицы является не сама запись, а указатель на динамически размещаемый линейный список записей, при этом список по индексу iсодержит все записи, для которыхh(x) = i. Пустое значение указателя означает отсутствие таких записей. Возможен и несколько иной вариант представления данных, когда хеш-таблица содержит первую запись каждого списка и указатель на продолжение списка.
Недостаток алгоритма – дополнительный расход памяти на организацию списков, при том, что значительная часть хеш-таблицы может пустовать. Еще хуже то, что выделение динамической памяти (по newилиmalloc) – довольно медленная операция. Достоинства – отсутствие скучивания и простота удаления записей. Кроме того, в этом алгоритме невозможно переполнение таблицы, наблюдается только снижение скорости поиска при большом числе записей.
Алгоритм Уильямса
Он представляет собой компромиссное решение: записи с одинаковым h(x)организованы в линейные списки, но эти списки размещаются не в динамической памяти, а в основном массиве хеш-таблицы. При этом элементы массива должны, помимо ключа и данных, содержать еще поле связи, в котором указан индекс следующего элемента списка. Кроме того, для ускорения поиска свободного места при вставке используется переменнаяR, которая при пустой таблице равнаN, а затем всегда указывает на позицию в массиве, начиная с которой свободного места наверняка нет. При вставке новой записи, если занята позицияh(k), свободное место ищется вниз от позицииR, аRуменьшается, получая значение индекса найденной позиции. Удаление записей нежелательно, а если оно все же происходит и номер удаляемой записиi R, то переменнойRследует присвоить значениеi+1.
Эффективность хеширования и сравнение с другими методами поиска
Как уже отмечалось, скорость поиска с использованием хеширования не зависит напрямую от количества записей, среди которых выполняется поиск (формально этот факт записывается как T(n) = O(1)). Время поиска складывается из времени вычисления хеш-функции и, возможно, времени, затрачиваемого на разрешение возникших коллизий. В качестве меры времени удобно принять число попыток (проверок ключа) при поиске. Минимально возможное число попыток равно 1 (в случае отсутствия коллизии). Каждая проба другой позиции или каждое продвижение на шаг по списку увеличивает число попыток на 1.
Хотя прямой зависимости от числа записей нет, время поиска (число попыток) существенно зависит от такого показателя, как заполненность хеш-таблицы, которая представляет собой отношение числа записей к числу всех позиций хеш-таблицы: = n/N.
Характер зависимости определяется выбранным способом разрешения коллизий. Приведем приближенные формулы для двух вариантов:
если используется алгоритм линейных проб, то T() (1-/2)/(1-);
если используются списки во внешней памяти, то T() 1 +/2.
Графики обеих функций приведены на рис. 6.3.
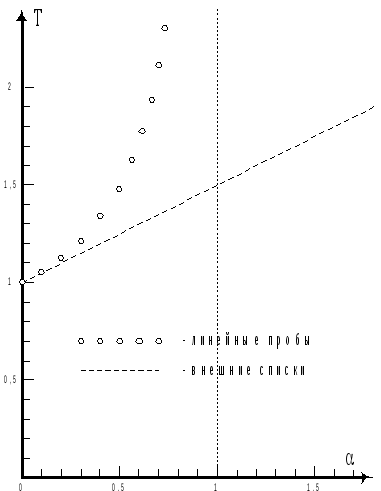
Рис. 6.3. Зависимость числа попыток от заполненности таблицы
Судя по графикам, алгоритмы разрешения коллизий ведут себя существенно по-разному при большой заполненности таблицы. Если для линейных проб значения , близкие к 1, – просто катастрофа, то алгоритм списков во внешней памяти допускает даже заполненность, значительно превышающую 1, хотя при этом хеширование будет работать не намного быстрее линейного поиска.
Общий вывод, который можно сделать из графиков, следующий. Для успешного применения хеширования мало написать хорошую хеш-функцию и выбрать удачный алгоритм разрешения коллизий. Еще одно важнейшее условие – невысокая заполненность таблицы. Желательно обеспечить условие < 1/2, в крайнем случае –< 2/3. В этом случае хеширование действительно демонстрирует очень высокую скорость работы, намного превышающую возможности бинарного поиска.
Эта скорость представляет собой единственное, но очень важное достоинство хеширования. Чтобы слегка подпортить картину, перечислим несколько мелких и средних недостатков.
Для успешного хеширования требуется заранее оценить предполагаемое количество записей и разместить в памяти хеш-таблицу избыточного размера.
Если число записей превышает предварительные оценки, то нет лучшего способа продолжить работу, чем разместить таблицу большего размера и перенести в нее все записи из старой таблицы, затратив на это немалое время. Эта трудоемкая операция называется рехешированием.
Все способы поиска, основанные на сортированных массивах или деревьях поиска, позволяют, если понадобится, легко найти минимальный и максимальный элементы таблицы, а также перечислить все элементы в порядке возрастания. Хеширование же не дает таких дополнительных возможностей.
Невозможно раз и навсегда запрограммировать универсальную процедуру «хеширования чего угодно». Выбор алгоритмов хеширования и разрешения коллизий должен производиться исходя из конкретного типа и количества ключей.
Хорошее хеширование строковых ключей требует использования всех символов ключа, что для длинных ключей может отнимать ощутимое время, сопоставимое с временем поиска по нагруженному дереву.