

Архитектура компьютера - Таненбаум Э
..pdfМультипроцессоры с памятью совместного использования |
603 |
Мультипроцессоры UMA с координатными коммутаторами
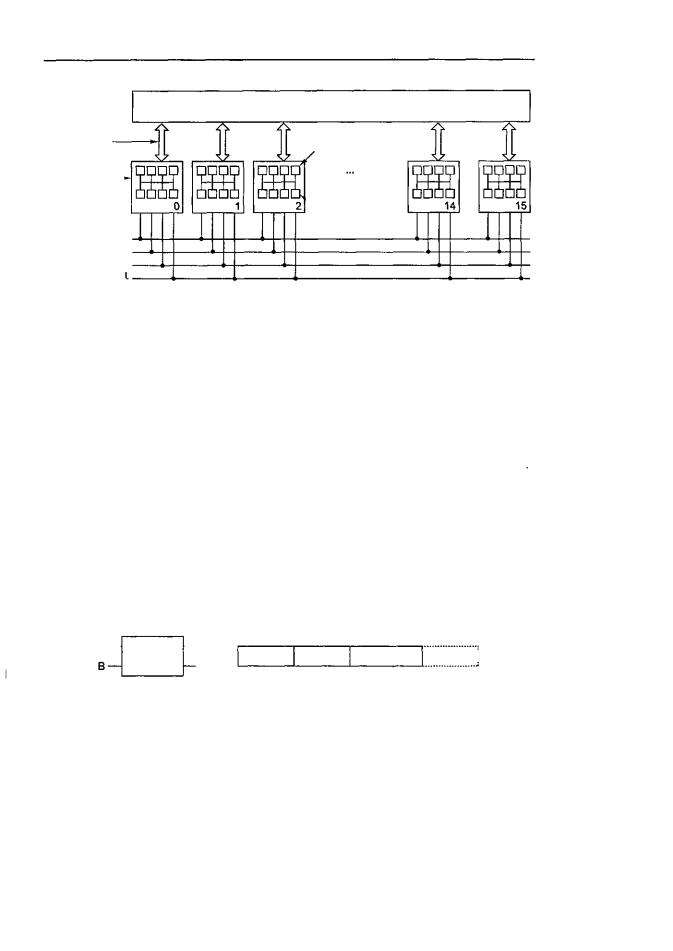
Даже при всех возможных оптимизациях использование только одной шины ограничивает размер мультипроцессора UMA до 16 или 32 процессоров. Чтобы получить больший размер, требуется другой тип коммуникационной сети. Самая простая схема соединения п процессоров с к блоками памяти — координатный коммутатор (рис. 8.19). Координатные коммутаторы используются на протяжении многих десятилетий для соединения группы входящих линий с рядом выходящих линий произвольным образом.
Модулипамяти
Координатный
коммутатор
открыт
Координатный
коммутатор
закрыт
Закрытый |
Открытый |
координатный |
координатный |
коммутатор |
коммутатор |
Рис. 8.19. Координатный коммутатор 8x8 (а); открытый узел (б); закрытый узел (в)
В каждом пересечении горизонтальной (входящей) и вертикальной (исходящей) линии находится соединение (crosspoint), которое можно открыть или закрыть в зависимости от того, нужно соединять горизонтальную и вертикальную линии или нет. На рис. 8.19, а мы видим, что три узла закрыты, благодаря чему устанавливается связь между парами (процессор, память) (001, 000), (101, 101) и (110, 010) одновременно. Возможны другие комбинации. Число комбинаций равно числу способов, которыми можно расставить 8 ладей на шахматной доске.
Координатный коммутатор представляет собой неблокируемую сеть. Это значит, что процессор всегда будет связан с нужным блоком памяти, даже если какаято линия или узел уже заняты. Более того, никакого предварительного планирования не требуется. Даже если уже установлено семь произвольных связей, всегда

6 0 4 Глава 8. Архитектуры компьютеров параллельного действия
можно связать оставшийся процессор с оставшимся блоком памяти. Ниже мы рассмотрим схемы, которые не обладают такими свойствами.
Не лучшим свойством координатного коммутатора является то, что число узлов растет как п2. При наличии 1000 процессоров и 1000 блоков памяти нам понадобится миллион узлов. Это неприемлемо. Тем не менее координатные коммутаторы вполне применимы для систем средних размеров.
Sun Enterprise 10000
В качестве примера мультипроцессора UMA, основанного на координатном коммутаторе, рассмотрим систему Sun Enterprise 10000 [23, 24]. Эта система состоит из одного корпуса с 64 процессорами. Координатный коммутатор Gigaplahe-XB запакован в плату, содержащую 8 гнезд на каждой стороне. Каждое гнездо вмещает огромную плату процессора (40x50 см), содержащую 4 процессора UltraSPARC на 333 МГц и ОЗУ на 4 Гбайт. Благодаря жестким требованиям к синхронизации и малому времени ожидания доступ к памяти вне платы занимает столько же времени, сколько доступ к памяти на плате.
Иметь только одну шину для взаимодействия всех процессоров и всех блоков памяти неудобно, поэтому в системе Enterprise 10000 применяется другая стратегия. Здесь есть координатный коммутатор 16x16 для перемещения данных между основной памятью и блоками кэш-памяти. Длина строки кэш-памяти составляет 64 байта, а ширина канала связи составляет 16 байтов, поэтому для перемещения строки кэш-памяти требуется 4 цикла. Координатный коммутатор работает от точки к точке, поэтому его нельзя использовать для сохранения совместимости по кэшпамяти.
По этой причине помимо координатного коммутатора имеются 4 адресные шины, которые используются для отслеживания строк в кэш-памяти (рис. 8.20). Каждая шина используется для 1/4 физического адресного пространства. Для выбора шины используется два адресных бита. В случае промаха кэш-памяти при считывании процессор должен считывать нужную ему информацию из основной памяти, и тогда он обращается к соответствующей адресной шине, чтобы узнать, нет ли нужной строки в других блоках кэш-памяти. Все 16 плат отслеживают все
адресные шины одновременно, поэтому если ответа нет, это значит, что требуемая строка отсутствует в кэш-памяти и ее нужно вызывать из основной памяти.
Вызов из памяти происходит от точки к точке по координатному коммутатору по 16 байтов. Цикл шины составляет 12 не (83,3 МГц), и каждая адресная шина может отслеживаться в каждом цикле любой другой шины, то есть всего возможно 167 млн отслеживаний/с. Каждое отслеживание может потребовать передачи строки кэш-памяти в 64 байта, поэтому узел должен быть способен передавать 9,93 Гбайт/с (напомним, что 1 Гбайт= 1,0737x109 байт/с, а не 109байт/с). Строку кэш-памяти в 64 байта можно передать через узел за 4 цикла шины (48 не) при пропускной способности 1,24 Гбайт/с за одну передачу. Поскольку узел может обрабатывать 16 передач одновременно, его максимальная пропускная способность составляет 19,87 Гбайт/с, а этого достаточно для поддержания скорости отслеживания, даже если принять во внимание конфликтную ситуацию, которая сокращает практическую пропускную способность примерно до 60% от теоретической.
|
|
Мультипроцессоры с памятью совместного использования |
605 |
Блок |
|
|
|
передачи — |
Координатный коммутатор 16x16 (Gigaplane XB) |
|
|
этоблок |
|
||
|
|
||
кэш-памяти |
|
|
|
размером |
ПроцессорUltraSPARC |
|
|
64 байта |
|
||
|
|
||
Плата |
|
, |
|
содержит |
|
|
|
4 Гбайт памяти |
Ч Модуль памяти |
|
и 4 процессора |
||
размером1Гбайт |
||
|
4-адресные Г шины для J отслеживания 1 изменений
по адресам
Рис. 8.20. Мультипроцессор Sun Enterprise 10000
Enterprise 10000 использует 4 отслеживающие шины параллельно, плюс очень широкий координатный коммутатор для передачи данных. Ясно, что такая система преодолевает предел в 64 процессора. Но чтобы существенно увеличить количество процессоров, требуется совсем другой подход.
Мультипроцессоры UMA
с многоступенчатыми сетями
В основе «совсем другого подхода» лежит небольшой коммутатор 2x2 (рис. 8.21, а). Этот коммутатор содержит два входа и два выхода. Сообщения, приходящие на любую из входных линий, могут переключаться на любую выходную линию. В нашем примере сообщения будут содержать до четырех частей (рис. 8.21, б). Поле Модуль сообщает, какую память использовать. Поле Адрес определяет адрес в этом модуле памяти. В поле Код операции содержится операция, например READ или WRITE. Наконец,дополнительное полеЗначениеможетсодержатьоперанд, например 32-битное слово, которое нужно записать при выполнении операции WRITE. Коммутатор исследует поле Модуль и использует его для определения, через какую выходную линию нужно отправить сообщение: через X или через Y.
А — |
— х |
Модуль |
Адрес Код операции Значениеi |
|
•Y |
||
|
|
|
|
а |
|
|
б |
Рис. 8.21. Коммутатор2x2(а); форматсообщения (б)
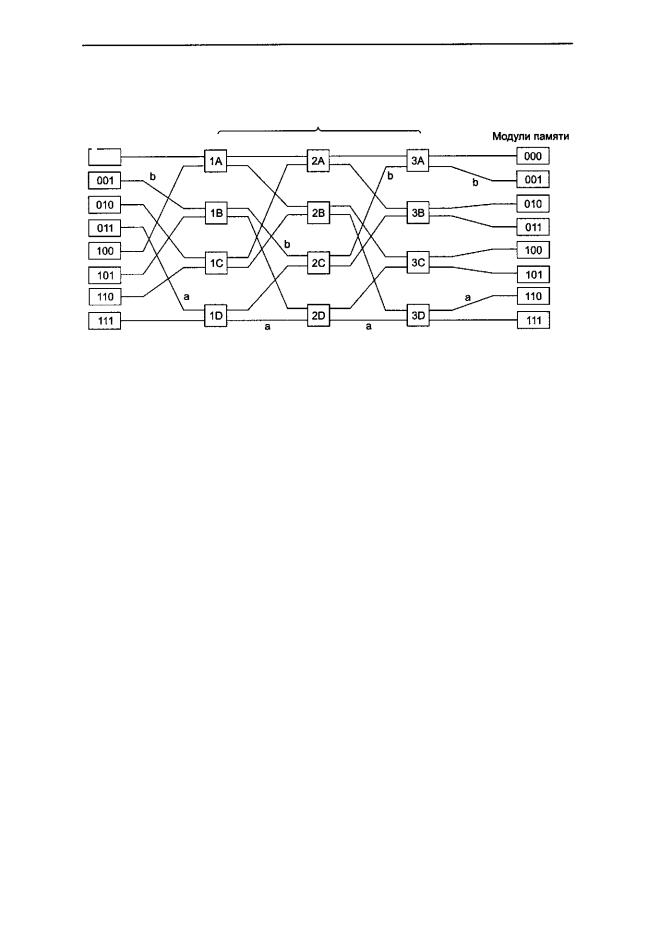
Наши коммутаторы 2x2 можно компоновать различными способами и получать многоступенчатые сети [1, 15, 78]. Один из возможных вариантов — сеть omega (рис. 8.22). Здесь мы соединили 8 процессоров с 8 модулями памяти, используя 12 коммутаторов. Для п процессоров и п модулей памяти нам понадобится log2n ступеней, п/2 коммутаторов на каждую ступень, то есть всего (n/2)log2n
6 06 Глава 8. Архитектуры компьютеров параллельного действия
коммутаторов, что намного лучше, чем п2узлов (точек пересечения), особенно для больших п.
3 ступени
Процессоры
~000
Рис. 8.22. Сеть omega
Рисунок разводки сети omega часто называют полным тасованием, поскольку смешение сигналов на каждой ступени напоминает колоду карт, которую разделили пополам, а затем снова соединили, чередуя карты. Чтобы понять, как работает сеть omega, предположим, что процессору 011 нужно считать слово из модуля памяти 110. Процессор посылает сообщение READ, чтобы переключить коммутатор ID, который содержит 110 в поле Модуль. Коммутатор берет первый (то есть крайний левый) бит от 110 и по нему узнает направление. 0 указывает на верхний выход, а 1 — на нижний. Поскольку в данном случае этот бит равен 1, сообщение отправляется через нижний выход в 2D.
Все коммутаторы второй ступени, включая 2D, для определения направления используют второй бит. В данном случае он равен 1, поэтому сообщение отправляется через нижний выход в 3D. Затем проверяется третий бит. Он равен 0. Следовательно, сообщение переходит в верхний выход и прибывает в память 110, чего мы идобивались. Путь,пройденныйданнымсообщением,обозначеннарис. 8.22буквой а.
Как только сообщение пройдет через сеть, крайние левые биты номера модуля больше не требуются. Их можно использовать, записав туда номер входной линии, чтобы было известно, по какому пути посылать ответ. Для пути а входные линии — это 0 (верхний вход в ID), 1 (нижний вход в 2D) и 1 (нижний вход в 3D) соответственно. При отправке ответа тоже используется 011, только теперь число читается справа налево.
В то время как все это происходит, процессору 001 нужно записать слово в модуль памяти 001. Здесь происходит аналогичный процесс. Сообщение отправляется через верхний, верхний и нижний выходы соответственно. На рис. 8.22 этот путь отмечен буквой Ь. Когда сообщение пребывает в пункт назначения, в поле Модуль содержится 001. Это число показывает путь, который прошло сообщение. Поскольку эти два запроса используют совершенно разные коммутаторы, линии и модули памяти, они могут протекать параллельно.

Мультипроцессоры с памятью совместного использования |
|
607 |
А теперь рассмотрим, что произойдет, если процессору 000 одновременно с этим понадобился доступ к модулю памяти 000. Его запрос вступит в конфликт с запросом процессора 001 на коммутаторе ЗА. Одному из них придется подождать. В отличие от координатного коммутатора, сеть omega — это блокируемая сеть. Не всякий набор запросов может передаваться одновременно. Конфликты могут возникать при использовании одного и того же провода или одного и того же коммутатора, а также между запросами, направленными к памяти, и ответами, исходящими из памяти.
Желательно равномерно распределить обращения к памяти по модулям. Один из возможных способов — использовать младшие биты в качестве номера модуля памяти. Рассмотрим адресное пространство с побайтовой адресацией для компьютера, который в основном получает доступ к 32-битным словам. Два младших бита обычно будут 00, но следующие три бита будут равномерно распределены. Если использовать эти три бита в качестве номера модуля памяти, последовательно адресуемые слова будут находиться в последовательных модулях. Система памяти, в которой последовательные слова находятся в разных модулях памяти, называется расслоенной. Расслоенная система памяти доводит параллелизм до максимума, поскольку большая часть обращений к памяти — это обращения к последовательным адресам. Можно разработать неблокируемые сети, в которых существует несколько путей от каждого процессора к каждому модулю памяти.
Мультипроцессоры NUMA
Размер мультипроцессоров UMA с одной шиной обычно ограничивается до нескольких десятков процессоров, адля координатных мультипроцессоров или мультипроцессоров с коммутаторами требуется дорогое аппаратное обеспечение, и они ненамного больше по размеру. Чтобы получить более 100 процессоров, нужно чтото предпринять. Отметим, что все модули памяти имеют одинаковое время доступа. Это наблюдение приводит к разработке мультипроцессоров NUMA (NonUniform MemoryAccess —снеоднороднымдоступомкпамяти).Какимультипроцессоры UMA, они обеспечивают единое адресное пространство для всех процессоров, но, в отличие от машин UMA, доступ к локальным модулям памяти происходит быстрее, чем к удаленным. Следовательно, все программы UMA будут работать без изменений на машинах NUMA, но производительность будет хуже, чем на машине UMA с той же тактовой частотой.
Машины NUMA имеют три ключевые характеристики, которыми все они обладают и которые в совокупности отличают их от других мультипроцессоров:
1.Существует одно адресное пространство, видимое для всех процессоров.
2.ДоступкудаленнойпамятипроизводитсясиспользованиемкомандLOADиSTORE.
3.Доступ к удаленной памяти происходит медленнее, чем доступ к локальной памяти.
Если время доступа к удаленной памяти не скрыто (поскольку кэш-память отсутствует), то такая системаназывается NC-NUMA (No CachingNUMA — NUMA без кэширования). Если присутствуют согласованные кэши, то система называется CC-NUMA (Coherent Cache NUMA — NUMA с согласованной кэш-памятью).

608 Глава 8. Архитектуры компьютеров параллельного действия
ПрограммистычастоназываютееаппаратнойDSM (DistributedSharedMemory — распределенная совместно используемая память), поскольку она по сути сходна с программной DSM, но реализуется в аппаратном обеспечении с использованием страниц маленького размера.
Одной из первых машин NC-NUMA была Carnegie-Mellon Cm*. Она проиллюстрирована в упрощенной форме рис. 8.23 [143]. Машина состояла из набора процессоров LSI-11, каждый с собственной памятью, обращение к которой производится по локальной шине. (LSI-11 — это один из видов процессора DEC PDP-11 на одной микросхеме; этот мини-компьютер был очень популярен в 70-е годы.) Кроме того, системы LSI-11 были связаны друг с другом системной шиной. Когда запрос памяти приходил в блок управления памятью, производилась проверка и определялось, находится ли нужное слово в локальной памяти. Если да, то запрос отправлялся по локальной шине. Если нет, то запрос направлялся по системной шине к системе, которая содержала данное слово. Естественно, вторая операция занимала гораздо больше времени, чем первая. Выполнение программы из удаленной памяти занимало в 10 раз больше времени, чем выполнение той же программы из локальной памяти.
Процессор Память Процессор Память Процессор Память Процессор Память
Контроллер |
|
|
|
|
управления- |
|
|
|
|
памятью |
Локальная |
Локальная |
Локальная |
Локальная |
|
шина |
шина |
шина |
шина |
Системная шина
Рис. 8.23. Машина NUMA с двумя уровнями шин. Cm* — первый мультипроцессор, в котором использоваласьданная разработка
Согласованность памяти гарантирована в машине NC-NUMA, поскольку там отсутствует кэш-память. Каждое слово памяти находится только в одном месте, поэтому нет никакой опасности появления копии с устаревшими данными: здесь вообще нет копий. Имеет большое значение, в какой именно памяти находится та или иная страница, поскольку от этого зависит производительность. Машины NCNUMA используют сложное программное обеспечение для перемещения страниц, чтобы максимально увеличить производительность.
Обычно существует «сторожевой» процесс (демон), так называемый страничный сканер, который запускается каждые несколько секунд. Он должен следить за статистикой использования страниц и перемещать их таким образом, чтобы улучшить производительность. Если страница окажется в неправильном месте, страничный сканер преобразует ее таким образом, чтобы следующее обращение к ней вызвало ошибку из-за отсутствия страницы. Когда происходит такая ошибка, принимается решение о том, куда поместить эту страницу, возможно, в другую память, из которой она была взята раньше. Для предотвращения пробуксовки существует правило, которое гласит, что если страница была помещена в то или иное место, она должна оставаться в этом месте на время AT. Было рассмотрено

Мультипроцессоры с памятью совместного использования |
609 |
множество алгоритмов, но ни один из них не работает лучше других при любых обстоятельствах [80].
Мультипроцессоры CC-NUMA
Мультипроцессоры, подобные тому, который изображен на рис. 8.23, плохо расширяются, поскольку в них нет кэш-памяти. Каждый раз переходить к удаленной памяти, чтобы получить доступ к слову, которого нет в локальной памяти, очень невыгодно: это сильно снижает производительность. Однако с добавлением кэшпамяти нужно будет добавить и способ совместимости кэшей. Один из способов — отслеживать системную шину. Технически это сделать несложно, но мы уже видели (когда рассматривали Enterprise 10000), что даже с четырьмя отслеживающими шинами и высокоскоростным координатным коммутатором шириной 16 байтов для передачи данных 64 процессора — это верхний предел. Для создания мультипроцессоров действительно большого размера нужен совершенно другой подход.
Самый популярный подход для построения больших мультипроцессоров CC-
NUMA (Cache Coherent NUMA — NUMA с согласованной кэш-памятью) — муль-
типроцессор на основе каталога. Основная идея состоит в сохранении базы данных, которая сообщает, где именно находится каждая строка кэш-памяти и каково ее состояние. При обращении к строке кэш-памяти из базы данных выявляется информация о том, где находится эта строка и изменялась она или нет. Поскольку обращение к базе данных происходит на каждой команде, которая обращается к памяти, база данных должна находиться в высокоскоростном специализированном аппаратном обеспечении, которое способно выдавать ответ на запрос за долю циклашины.
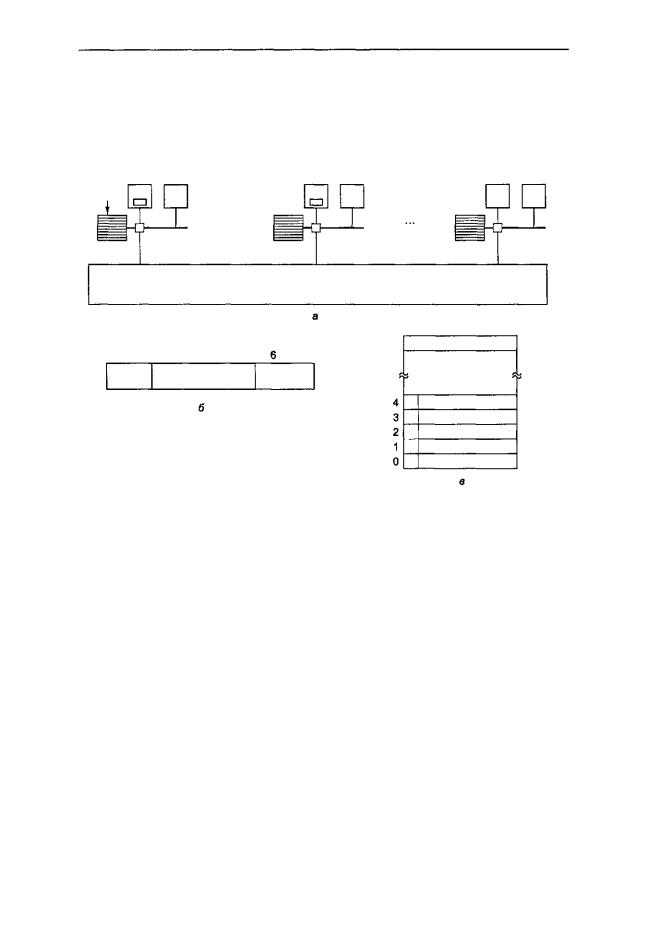
Чтобы лучше понять, что собой представляет мультипроцессор на основе каталога, рассмотрим в качестве примера систему из 256 узлов, в которой каждый узел состоит из одного процессора и 16 Мбайт ОЗУ, связанного с процессором через локальную шину. Общий объем памяти составляет 232 байтов. Она разделена на 226 строк кэш-памяти по 64 байта каждая. Память статически распределена по узлам: 0-16 М в узле 0, 16 М-32 М — в узле 1 и т. д. Узлы связаны через сеть (рис. 8.24, а). Сеть может быть в виде решетки, гиперкуба или другой топологии. Каждый узел содержит элементы каталога для 218 64-байтных строк кэш-памяти, составляя свою 224-байтную память. Наданныймоментмы предполагаем, что строка может содержаться максимум в одной кэш-памяти.
Чтобы понять, как работает каталог, проследим путь команды LOAD из процессора 20, который обращается к кэшированной строке. Сначала процессор, выдавший команду, передает ее в блок управления памятью, который переводит ее в физический адрес, например 0x24000108. Блок управления памятью разделяет этот адрес на три части, как показано на рис. 8.24, 6. В десятичной системе счисления эти три части — узел 36, строка 4 и смещение 8. Блок управления памятью видит, что слово памяти, к которому производится обращение, находится в узле 36, а не в узле 20, поэтому он посылает запрос через сеть в узел 36, где находится нужная строка, узнает, есть ли строка 4 в кэш-памяти, и если да, то где именно.
Когда запрос прибывает в узел 36, он направляется в аппаратное обеспечение каталога. Аппаратное обеспечение индексирует таблицу их 218 элементов (один
6 1 0 Глава 8. Архитектуры компьютеров параллельного действия
элемент на каждую строку кэш-памяти) и извлекает элемент 4. Из рис. 8.24, в видно, что эта строка отсутствует в кэш-памяти, поэтому аппаратное обеспечение вызывает строку 4 из локального ОЗУ, отправляет ее в узел 20 и обновляет элемент каталога 4, чтобы показать, что эта строка находится в кэш-памяти в узле 20.
|
Узел 0 |
Узел 1 |
Узел 256 |
Процессор Память |
Процессор Память |
Процессор Память |
|
Каталог |
|
|
СП |
|
|
|
|
|
Локальная |
Локальная |
Локальная |
|
шина |
шина |
шина |
|
|
Сеть межсоединений |
|
Биты 8 |
18 |
21 8 -1 |
I |
|
|
||
Узел |
Блок |
Смещение |
|
|
|
0 |
|
|
|
0 |
|
|
|
J l |
82 |
|
|
~ol |
|
|
|
0 |
|
Рис. 8.24. Мультипроцессор на основе каталога, содержащий 256 узлов (а); разбиение 32-битного адреса памяти на поля (б); каталог в узле 36 (в)
А теперь рассмотрим второй запрос, на этот раз о строке 2 из узла 36. Из рис. 8.24, в видно, что эта строка находится в кэш-памяти в узле 82. В этот момент аппаратное обеспечение может обновить элемент каталога 2, чтобы сообщить, что строка находится теперь в узле 20, а затем может послать сообщение в узел 82, чтобы строка из него была передана в узел 20, и объявить недействительной его кэш-память. Отметим, что даже в так называемом мультипроцессоре с памятью совместного использования перемещение многих сообщений проходит скрыто.
Давайте вычислим, сколько памяти занимают каталоги. Каждый узел содержит 16 Мбайт ОЗУ и 218 9-битных элементов для слежения за этим ОЗУ. Таким образом, непроизводительные затраты каталога составляют примерно 9х218 битов от 16 Мбайт или около 1,76%, что вполне допустимо. Даже если длина строки кэш-памяти составляет 32 байта, непроизводительные затраты составят всего 4%. Если длина строки кэш-памяти равна 128 байтов, непроизводительные затраты будут ниже 1%.
Очевидным недостатком этой разработки является то, что строка может быть кэширована только в одном узле. Чтобы строки можно было кэшировать в нескольких узлах, потребуется какой-то способ их нахождения (например, чтобы объявлять недействительными илиобновлятьихпризаписи). Возможныразличныеварианты.

Мультипроцессоры с памятью совместного использования |
|
611 |
Одна из возможностей — предоставить каждому элементу каталога к полей для определения других узлов, что позволит сохранять каждую строку в нескольких блоках кэш-памяти (допустимо до k различных узлов). Вторая возможность — заменить номер узла битовым отображением, один бит на узел. Здесь нет ограничений на количество копий, но существенно растут непроизводительные затраты. Каталог, содержащий 256 битов для каждой 64-байтной (512-битной) строки кэш-памяти, подразумевает непроизводительные затраты выше 50%. Третья возможность — хранить в каждом элементе каталога 8-битное поле и использовать это поле как заголовок связанного списка, который связывает все копии строки кэш-памяти вместе. При такой стратегии требуется дополнительное пространство в каждом узле для указателей связанного списка. Кроме того, требуется просматривать связанный список, чтобы в случае необходимости найти все копии. Каждая из трех стратегий имеет свои преимущества и недостатки. На практике используются все три стратегии.
Еще одна проблема данной разработки — как следить за тем, обновлена ли исходная память или нет. Если нужно считать строку кэш-памяти, которая не изменялась, запрос может быть удовлетворен из основной памяти, и при этом не нужно направлять запрос в кэш-память. Если нужно считать строку кэш-памяти, которая была изменена, то этот запрос должен быть направлен в тот узел, в котором находится нужная строка кэш-памяти, поскольку только здесь имеется действительная копия. Если разрешается иметь только одну копию строки кэш-памяти, как на рис. 8.24, то нет никакого смысла в отслеживании изменений в строках кэш-памя- ти, поскольку любой новый запрос должен пересылаться к существующей копии, чтобы объявить ее недействительной.
Когда строка кэш-памяти меняется, нужно сообщить в исходный узел, даже если существует только одна копия строки кэш-памяти. Если существует несколько копий, изменение одной из них требует объявления всех остальных недействительными. Поэтому нужен какой-либо протокол, чтобы устранить ситуацию состояния гонок. Например, чтобы изменить общую строку кэш-памяти, один издержателей этой строки должен запросить монопольный доступ к ней перед тем, как изменить ее. В результате все другие копии будут объявлены недействительными. Другие возможные оптимизации CC-NUMA обсуждаются в книге [140].
Мультипроцессор Stanford DASH
Первый мультипроцессор CC-NUMA на основе каталога — DASH (Directory
Architecture for SHared memory — архитектура на основе каталога для памяти совместного использования) — был создан в Стенфордском университете как исследовательский проект [81]. Данная разработкапростадля понимания. Онаповлияла на ряд промышленных изделий, например SGI Origin 2000. Мы рассмотрим 64-процессорный прототип данной разработки, который был реально сконструирован. Он подходит и для машин большего размера.
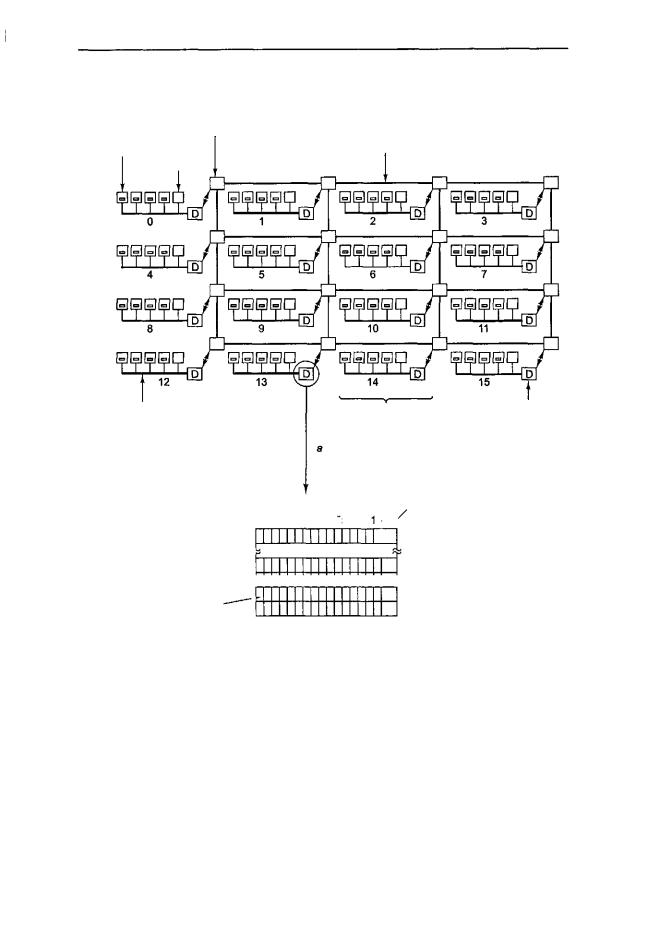
Схема машины DASH в немного упрощенном виде представлена на рис. 8.25, а. Она состоит из 16 кластеров, каждый из которых содержит шину, 4 процессора MIPS R3000, 16 Мбайт глобальной памяти, а также некоторые устройства вво- да-вывода (диски и т. д.), которые на схеме не показаны. Каждый процессор отслеживает только свою локальную шину. Локальная совместимость поддерживается
6 1 2 Глава 8. Архитектуры компьютеров параллельного действия
с помощью отслеживания; для глобальной согласованности нужен другой механизм, поскольку глобального отслеживания не существует.
Межкластерный интерфейс |
Межкластерная шина |
Процессор |
(без отслеживания |
с кэш-памятью |
изменений по адресам) |
Память |
|
Локальная шина |
|
|
|
Кластер |
Каталог |
(с отслеживанием |
|
|
|
|
|
изменений по адресам) |
|
|
|
|
|
|
|
|
Кластер |
Состояние |
|
|
Блок |
0 1 2 3 4 5 6 7 8 9 И |
Ь / |
|
|
|
|
Р |
|
I |
|
|
|
|
|
|
|
|
|
3 |
|
|
|
Это каталог кластера13. |
|
2 |2| | | | | | | [ | | | | | | | | -+\— Uncached, shared, modified |
|||
Этот бит показывает, |
|
Г, |
|
|
|
содержится ли блок 1 |
|
|
|
|
|
|
0 |
|
|
|
|
в какой-нибудь кэш-памяти |
|
|
|
||
|
|
|
|
||
кластера 0 |
|
|
g |
|
|
Рис. 8.25. Архитектура DASH (а); каталог DASH (б)
Полный объем адресного пространства в данной системе равен 256 Мбайт. Адресное пространство разделено на 16 областей по 16 Мбайт каждая. Глобальная память кластера 0 включает адреса с 0 по 16 М. Глобальная память кластера 1 включает адреса с 16 М по 32 М и т. д. Размер строки кэш-памяти составляет 16 байтов. Передача данных также осуществляется по строкам в 16 байтов. Каждый кластер содержит 1 М строк.
Каждый кластер содержит каталог, который следит за тем, какие кластеры в настоящий момент имеют копии своих строк. Поскольку каждый кластер содержит