

должен сыграть свою роль при ужесточении проектных норм до 0,13 мкм. Дело в том, что такая упаковка позволяет улучшить отвод тепла от процессора и переместить конденсаторы, фильтрующие цепи питания, поближе к ядру. Появился и ранее отсутствовавший термодиод, расположенный прямо на кристалле процессора.
Архитектура Athlon MP
Вообще говоря, микропроцессоры Athlon MP фактически не имеют никаких особенностей в архитектуре по сравнению с Athlon 4 для мобильных систем и Athlon XP для настольных компьютеров. Архитектура кристалла, получившая название QuantiSpeed, - девятипотоковая, суперскалярная и полностью конвейерная. Благодаря этому можно выполнять до девяти команд за один такт. Напомним, что в современных высокопроизводительных х86-совместимых процессорах х86-команды декодируются в более простые и эффективные внутренние RISC-подобные инструкции фиксированной длины. В Athlon для этих целей имеются три параллельно работающих декодера. Как известно, перед непосредственным исполнением RISC-команды попадают в буфер IСU (Instruction Control Unit), величина которого у Athlon составляла 72 инструкции, что должно исключать простои из-за переполнения на самых высоких частотах. Три конвейерных блока IEU (Integer Execution Unit) для исполнения целочисленных команд всегда были сильной стороной этого микропроцессора. Кроме того, арифметический сопроцессор способен выполнять одновременно три операции: простую вещественную операцию типа сложения, сложную типа умножения и отдельно операцию хранения. Общая длина целочисленного конвейера составляет 10 ступеней, а конвейера в устройстве вещественной арифметики - 15 ступеней.
Таблица предсказания переходов BTB (Branch Target Buffer), в которой сохраняются предыдущие результаты выполнения логических операций, может хранить до 2048 адресов. На основании этих данных процессор прогнозирует их результаты при их повторном выполнении. Соответственно вероятность правильного предсказания повышается примерно до 95%. Таблица, на основании которой строится предсказание
BHT (Branch History Table), еще больше: она насчитывает 4096 ячеек.
Athlon MP стал первым немобильным процессором AMD, использующим полный набор
SSE-инструкций (Streaming SIMD Extensions). Новый набор команд (3DNow! Плюс SSE)
получил название 3DNow! Professional и включает 52 новые инструкции.
В ядре Palomino был увеличен размер буфера быстрого преобразования адреса TLB (Translation Look-aside Buffers). Задача TLB заключается в кэшировании транслируемых физических адресов памяти. Процесс трансляции необходим процессору при обращении к любым данным, хранящимся в основной памяти, а потому кэширование адресов существенно сокращает время, проходящее с момента запроса данных процессором до момента их получения. Дело в том, что в момент обращения к оперативной памяти процессор обращается не к физическому адресу ячейки, а к виртуальному (естественно, между ними есть строгое соответствие). Эти преобразованные адреса и размещаются в TLB, причем отдельно для инструкций и данных. Если процессор не найдет нужный адрес, ему придется заняться его вычислением. Учитывая совсем немаленькое количество адресов в большинстве случаев, подобные операции могут заметно притормозить процессор. Понятно, что расширение TLB должно самым положительным образом сказываться на производительности. Среди основных особенностей стоит отметить, что в TLB кэшпамяти данных первого уровня Athlon MP число строк увеличено с 32 до 40. В TLB кэшпамяти команд и кэш-памяти данных второго уровня используется так называемая специальная exclusive-архитектура. Строки TLB поддерживают опережающую загрузку.
Увеличение числа строк в TLB кэш-памяти данных повышает вероятность успешного попадания в буфер (вероятность нахождения нужного адреса). Особенность архитектуры заключается в том, что записи в TLB кэш-памяти первого уровня не дублируются в TLB кэш-памяти второго уровня. Таким образом, в последнем экономятся
строки, благодаря чему этот буфер может кэшировать больше адресов.
Задача механизма упреждающей выборки DPM (Data Prefetch Mechanism) состоит в том, чтобы правильно предсказать, какие данные из основной памяти понадобятся для обработки процессору, и заблаговременно загрузить их в кэш-память. Если механизм срабатывает правильно, то такое нововведение опять-таки положительно сказывается на производительности. Однако при этом резко возрастают требования к пропускной способности шины FSB (Front Side Bus) и памяти. У Athlon Thunderbird и в более ранних версиях кристаллов подобный механизм работал только с инструкциями 3DNow! и SSE. С появлением процессоров на ядре Palomino (Athlon MP) упреждающая выборка данных была существенно доработана. Теперь с ее помощью возможно повышать производительность любых, даже не оптимизированных приложений. Athlon МP непрерывно анализирует адреса затребованных процессором данных наряду с последовательностью, в которой они были затребованы. На основании анализа делается попытка предсказания, какие адреса данных будут затребованы, и происходит опережающая загрузка информации в кэш-память. Это может быть особенно полезно, например, при циклической обработке больших массивов. Упреждающая выборка данных хорошо работает с приложениями, которые активно используют высокую пропускную способность, так как такой трафик легче поддается предсказанию. К этим приложениям относятся программы редактирования видео, создания 3D-графики и серверы баз данных.
Дальнейшее развитие семейства микропроцессоров Athlon MP связано с переходом на новое ядро Thoroughbred, выполненное с соблюдением проектных норм 0,13 мкм. К концу года ожидается также появление ядра Barton, которое помимо новых проектных норм будет использовать технологию "кремний на изоляторе" SOI (Silicon-On-Insulator).
Особенности многопроцессорной архитектуры
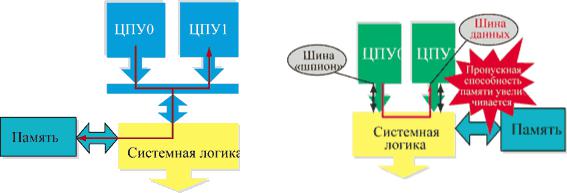
Набор микросхем AMD 760MP обладает двумя важными функциями, благодаря которым двухпроцессорные системы на его основе имеют высокую производительность. Это системная шина с топологией точка - точка и поддержка MOESI (Modified Owner Exclusive Shared Invalid) протокола когерентности. В SMP-системах, построенных на микросхемах Intel, процессоры подключаются к общей системной шине и разделяют между собой ее пропускную способность (рис. 2). В случае использования чипсета AMD 760MP каждому процессору Athlon MP выделяется своя отдельная шина. При таком соединении типа точка - точка, в котором каждый из процессоров общается с чипсетом по собственной шине (рис. 3), каждый процессор может передавать данные со скоростью до 2,1 Гбайт/c (при частоте системной шины 266 МГц) вне зависимости от того, что делает в этот момент времени другой процессор. Таким образом, теоретически оба процессора вместе могут позволить себе использование общей шины с пропускной способностью 4,2 Гбайт/c.
Рис. 2. Разделяемая шина. |
|
Рис. 3. Соединения точка - точка. |
|
|
|
В большинстве многопроцессорных систем каждый процессор отслеживает запросы по шине FSB и возвращает данные, если они находятся в кэш-памяти. Если один процессор обнаруживает, что другой обращается к памяти по какому-то из принадлежащих ему адресов (иными словами, у него имеется самая свежая копия данных), то процессор отвечает на запрос и выгружает данные из своей кэш-памяти. При необходимости записать данные по адресу процессор запрашивает права на использование ресурса и оставляет их за собой до тех пор, пока он снова не выгрузит "устаревшие" данные обратно в память или до тех пор, пока другой процессор не затребует эти права.
Рассмотрим систему на базе двух процессоров Athlon MP (ЦПУ0 и ЦПУ1). Сначала ЦПУ0 запрашивает блок данных, содержащийся в основной памяти и не содержащийся в кэшпамяти ЦПУ0 или ЦПУ1. Блок данных считывается из основной памяти, проходит через северный мост и попадает на запрашивавший процессор ЦПУ0. После этого ЦПУ0 запрашивает еще один блок данных, который теперь содержится в кэш-памяти второго уровня ЦПУ1. Последний всегда отслеживает запросы данных на FSB (такой процесс называется "слежкой", snooping). Соответственно теперь ЦПУ1 отсылает данные из своей кэш-памяти. У ЦПУ0 существует два пути получения данных: либо ЦПУ1 записывает блок в основную память и ЦПУ0 потом его считывает, либо ЦПУ1 передает данные напрямую на ЦПУ0.
При использовании разделяемой шины FSB все процессоры системы используют одно и то же соединение к северному мосту. Общение между процессорами идет через основную память, что соответствует первому способу из названных выше. При использовании FSB типа точка - точка у каждого процессора есть свое выделенное соединение к северному мосту, и обмен осуществляется через северный мост, не затрагивая основной памяти.
Конечно, использование FSB типа точка - точка или разделяемой FSB зависит от набора микросхем. Процессор лишь должен поддерживать устанавливаемый чипсетом протокол. Как уже отмечалось, в случае 760MP и Athlon MP применяется шина типа точка - точка. Этот тип шины позволяет уменьшать трафик на шине памяти, так как все межпроцессорное общение происходит без участия основной памяти.
Еще одно преимущество EV6 FSB у Athlon MP заключается в том, что она содержит два однонаправленных порта адреса (адрес на вход и адрес на выход) и один двунаправленный порт данных на каждом соединении. Это означает, что Athlon MP одновременно с выполнением запроса может "подглядывать" в поисках требуемых данных.
Обеспечение когерентности кэш-памяти
Пусть каждый (ЦПУ0 и ЦПУ1) владеет блоком данных в своей кэш-памяти. Затем ЦПУ1 изменяет эти данные у себя, и после этого ЦПУ0 будет пытаться прочитать данные у ЦПУ1. В текущем положении данные в кэш-памяти ЦПУ0 не являются актуальными, поскольку они были изменены после того, как ЦПУ0 поместил их в свой буфер. Для решения таких проблем процессоры должны обладать когерентной друг с другом кэшпамятью.
Существует множество вариаций протоколов когерентности кэш-памяти. Наиболее часто используется протокол записи с аннулированием WI (Write Invalidate). В случае возникновения конфликта когерентности этот протокол указывает, какой кэш-памяти необходимо аннулировать свои данные. Аннулирование происходит по адресной шине, так что двухпортовая адресная шина EV6 снова оказывается в выигрыше, позволяя