

IBM Research
NAMD Benchmarks
BPTI 3K atoms
Estrogen Receptor |
ATP Synthase |
|
327K atoms |
||
36K atoms (1996) |
||
(2001) |
||
|
11 |
© 2005 IBM Corporation |
|

IBM Research
Parallel MD: Easy or Hard?
Easy |
Hard |
– Tiny working data |
– Sequential timesteps |
– Spatial locality |
– Very short iteration time |
– Uniform atom density |
– Full electrostatics |
– Persistent repetition |
– Fixed problem size |
– Multiple time-stepping |
– Dynamic variations |
12 |
© 2005 IBM Corporation |
|

IBM Research
NAMD Computation
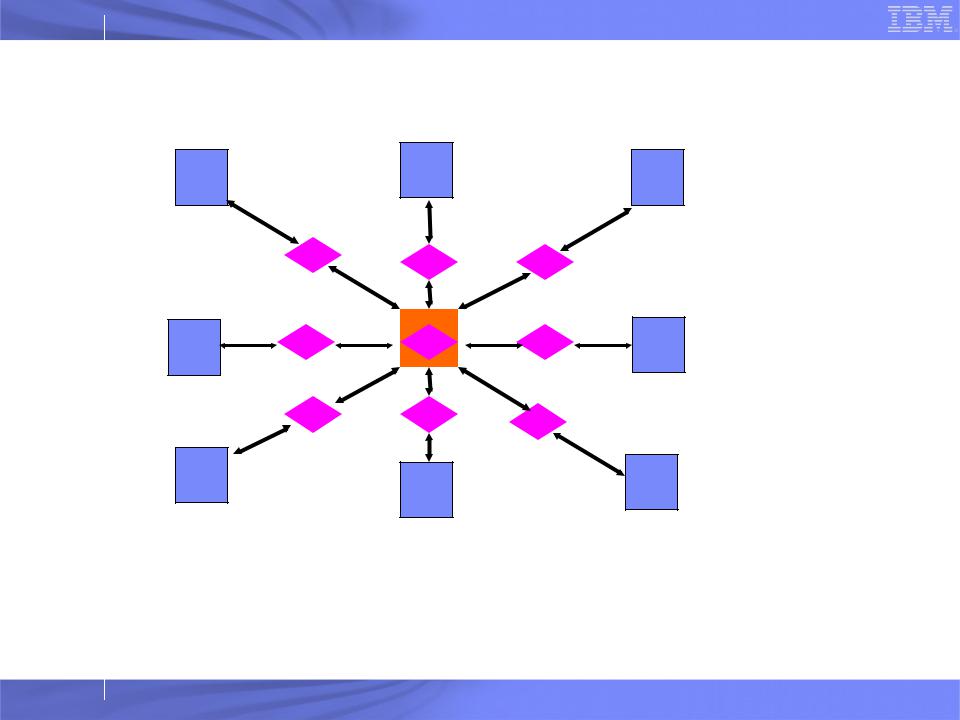
Application data divided into data objects called patches
–Sub-grids determined by cutoff
Computation performed by migratable computes
–13 computes per patch pair and hence much more parallelism
–Computes can be further split to increase parallelism
13 |
© 2005 IBM Corporation |
|
IBM Research
NAMD
Scalable molecular dynamics simulation
2 types of objects: patches and computes, to expose more parallelism
Requires more careful load balancing
14 |
© 2005 IBM Corporation |
|

IBM Research
Communication to Computation Ratio
Scalable
–Constant with number of processors
–In practice grows at a very small rate
15 |
© 2005 IBM Corporation |
|
IBM Research
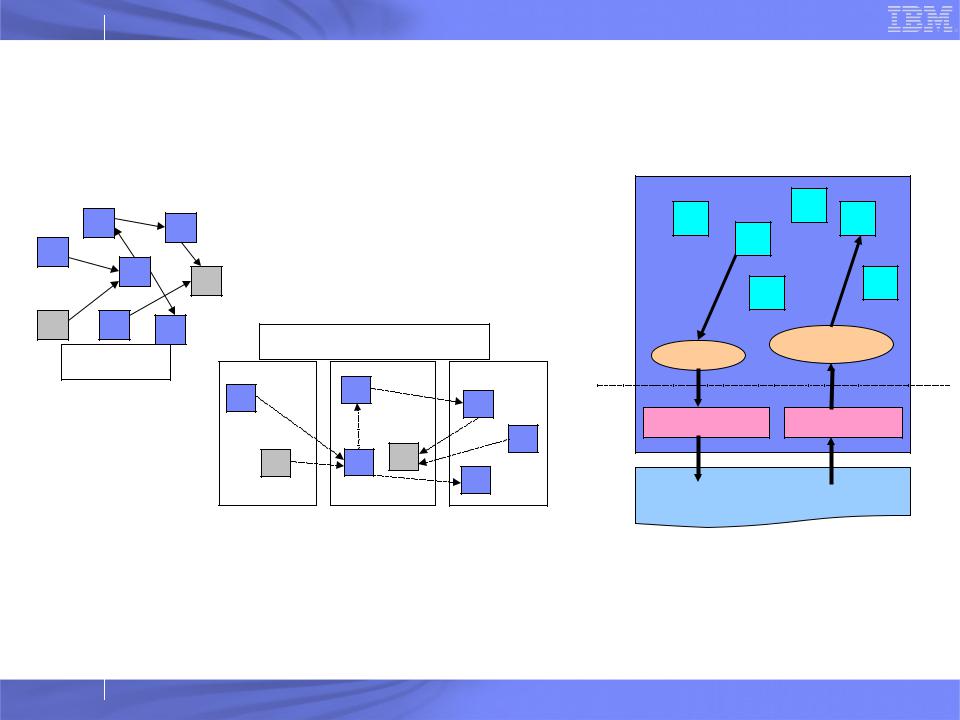
Charm++ and Converse
System implementation
User View
obj |
obj |
obj |
obj |
|
|
obj |
|
obj |
|
|
|
Interface |
Scheduler |
|
|
|
|
Send Msg Q |
Recv Msg Q |
|
Network |
|
|
Charm++: object-based asynchronous message-driven parallel programming paradigm
Converse: communication layer for Charm++
– Send, recv, progress, on node level
16 |
© 2005 IBM Corporation |
|

IBM Research
Optimizing NAMD on Blue Gene/L
© 2005 IBM Corporation

IBM Research
Single Processor Performance
Worked with IBM Toronto for 3 weeks
–Inner loops slightly altered to enable software pipelining
–Aliasing issues resolved through the use of
#pragma disjoint (*ptr1, *ptr2)
–40% serial speedup
–Current best performance is with 440
Continued efforts with Toronto to get good 440d performance
18 |
© 2005 IBM Corporation |
|

IBM Research
NAMD on BGL
Advantages
–Both application and hardware are 3D grids
–Large 4MB L3 cache
•On large number of processors NAMD will run from L3
–Higher bandwidth for short messages
•Midpoint of peak bandwidth achieved quickly
–Six outgoing links from each node
–No OS Daemons
19 |
© 2005 IBM Corporation |
|

IBM Research
NAMD on BGL
Disadvantages
–Slow embedded CPU
–Small memory per node
–Low bisection bandwidth
–Hard to scale full electrostatics
–Limited support for overlap of computation and communication
• No cache coherence
20 |
© 2005 IBM Corporation |
|