

IBM Research
Network Progress Calls
NAMD makes progress engine calls from the compute loops
– Typical frequency is10000 cycles, dynamically tunable
for ( i = 0; i < (i_upper SELF(- 1)); ++i ){
CmiNetworkProgress();
const CompAtom &p_i = p_0[i]; //……………………………
//Compute Pairlists
for (k=0; k<npairi; ++k) { //Compute forces
}
}
void CmiNetworkProgress() { new_time = rts_get_timebase();
if(new_time < lastProgress + PERIOD) { lastProgress = new_time;
return;
}
lastProgress = new_time; AdvanceCommunication();
}
Corporation

IBM Research
MPI Scalability
Charm++ MPI Driver
–Iprobe based implementation
–Higher progress overhead of MPI_Test
–Statically pinned FIFOs for point to point communication
32 |
© 2005 IBM Corporation |
|

IBM Research
Charm++ Native Driver
BGX Message Layer (developed by George Almasi)
–Lower progress overhead
–Active messages
• Easily design complex communication protocols
–Dynamic FIFO mapping
–Low overhead remote memory access
–Interrupts
–Charm++ BGX driver was developed by Chao Huang over this summer
33 |
© 2005 IBM Corporation |
|
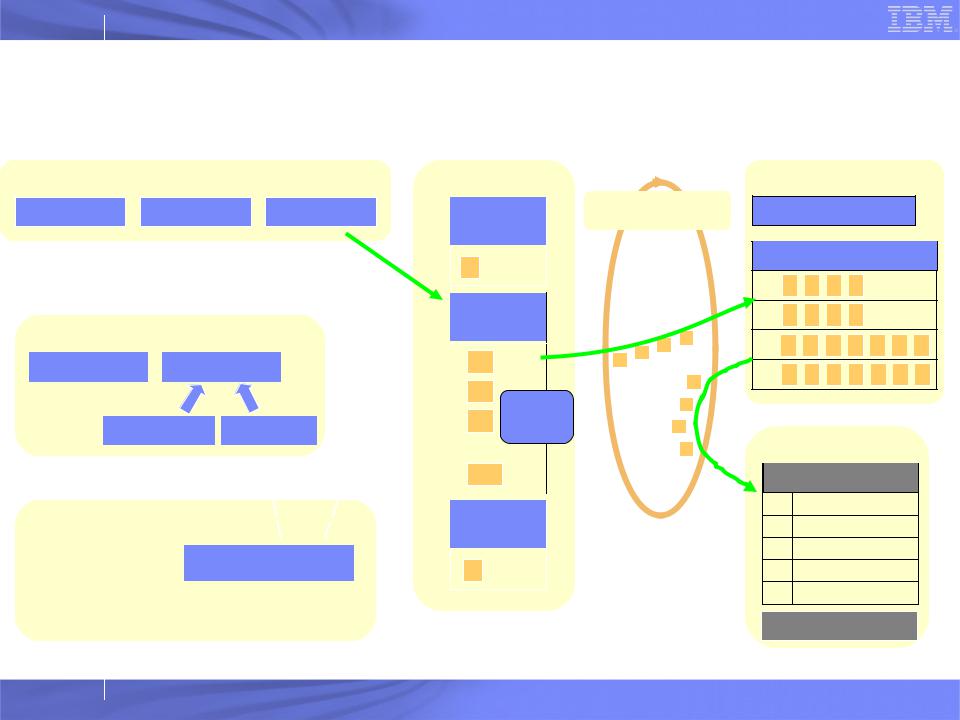
IBM Research
BG/L Msglayer
|
|
|
|
Messages |
|
|
|
|
Msg Queues |
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
SpadMessage |
|
TreeMessage |
TorusMessage |
|
Collective |
|
|||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
p |
Msq queue |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
o |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
s |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
t |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Torus |
|
|
|
|
Packets |
|
|
|
|
|
|
|
|
Msq queue |
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
TreePacket |
|
|
TorusPacket |
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
FIFO |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2 |
|
|
|
|
|
Dynamically |
|
|
Deterministically |
|
|
|
pinning |
|||||||
|
|
|
routed packet |
|
|
routed packet |
|
|
|
… |
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
n-1 |
|
|
|
|
|
Templates |
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
Scratchpad |
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Msq queue |
|
|
|
|
|
|
|
|
|
TorusDirectMessage<> |
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Advance loop
|
|
|
|
ts |
|
|
|
e |
|
|
|
k |
|
|
|
c |
|
|
|
a |
|
|
|
|
p |
|
|
|
|
( This slide is taken from G. Almási’s talk on the “new” msglayer. )
Network
Coll. network FIFO
Torus FIFOs
I0 0 
 1
1 
 2
2 
 H
H
I1 0 
 1
1 
 2
2 
 H
H
R0 x+

 x- y+
x- y+

 y- z+
y- z+

 z-
z-
 H
H
R1 x+

 x- y+
x- y+

 y- z+
y- z+

 z-
z-
 H
H
Dispatching
Torus pkt. registry
0
1
2
…
p
Coll. pkt. disp.
34 |
© 2005 IBM Corporation |
|
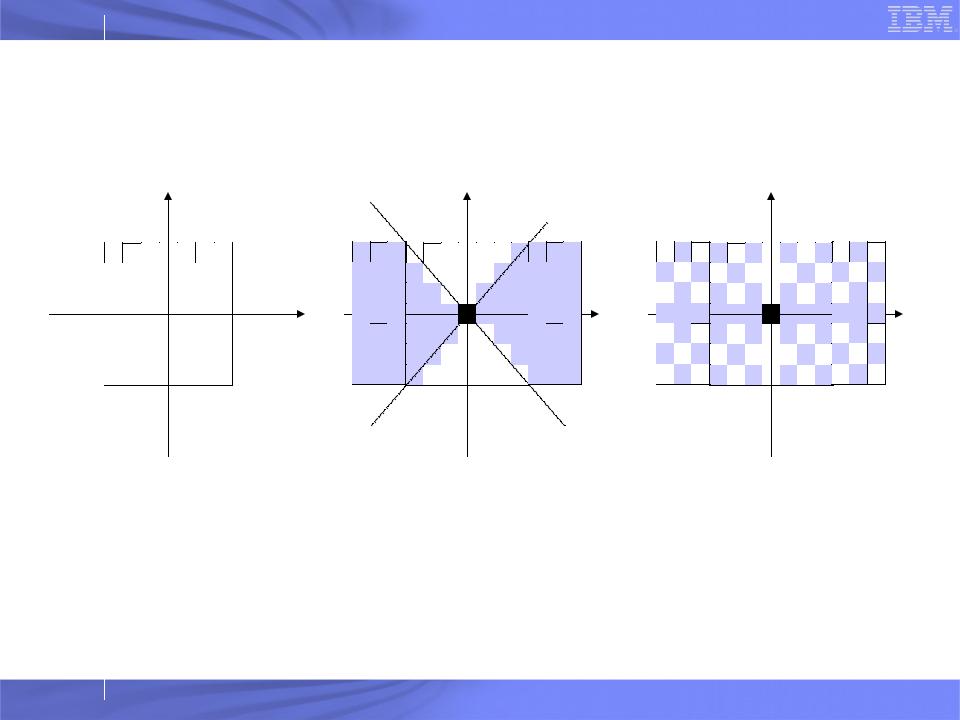
IBM Research
Optimized Multicast
pinFifo Algorithms
–Decide which of the 6 FIFOs to use when send msg to {x,y,z,t}
–Cones, Chessboard
Dynamic FIFO mapping
–A special send queue that msg can go from whichever FIFO that is not full
35 |
© 2005 IBM Corporation |
|

IBM Research
Communication Pattern in PME
108  procs
procs
108 procs
36 |
|
© 2005 IBM Corporation |
|
||
|
|

IBM Research
PME
Plane decomposition for 3D-FFT
PME objects placed close to patch objects on the torus
PME optimized through an asynchronous all-to-all with dynamic FIFO mapping
37 |
© 2005 IBM Corporation |
|

IBM Research
Performance Results
© 2005 IBM Corporation

IBM Research
BGX Message layer vs MPI
Fully non-blocking version performed below par on MPI
– Polling overhead high for a list of posted receives
BGX message layer works well with asynchronous communication
# Nodes |
Cutoff |
|
with PME |
||
Msglayer |
MPI* |
Msglayer |
MPI* |
||
|
|||||
APoA1 Benchmark
4 |
2250 |
2250 |
|
|
32 |
314 |
316 |
356 |
371 |
128 |
85 |
91.6 |
103 |
|
512 |
22.7 |
23.8 |
26.7 |
27.8 |
1024 |
13.2 |
13.9 |
14.4 |
17.3 |
2048 |
7.9 |
8.1 |
9.7 |
10.2 |
4096 |
4.8 |
4.9 |
6.8 |
7.3 |
NAMD Co-Processor Mode Performance (ms/step)
Message layer has sender side blocking communication here
39 |
© 2005 IBM Corporation |
|

IBM Research
Blocking vs Overlap
|
Cutoff |
|
with PME |
|
# Nodes |
Blocking Sender |
Non-Blocking |
Blocking Sender |
Non-Blocking |
|
||||
32 |
314 |
313 |
356 |
347 |
128 |
85 |
82 |
103 |
97.2 |
512 |
22.7 |
21.7 |
26.7 |
23.7 |
1024 |
13.2 |
11.9 |
14.4 |
13.8 |
2048 |
7.9 |
7.3 |
9.7 |
8.6 |
4096 |
4.8 |
4.3 |
6.8 |
6.2 |
8192 |
- |
3.7 |
- |
- |
APoA1 Benchmark in Co-Processor Mode
40 |
© 2005 IBM Corporation |
|