

IBM Research
BGL Parallelization
Topology driven problem mapping
Load-balancing schemes
Overlap of computation and communication
Communication optimizations
21 |
© 2005 IBM Corporation |
|

IBM Research
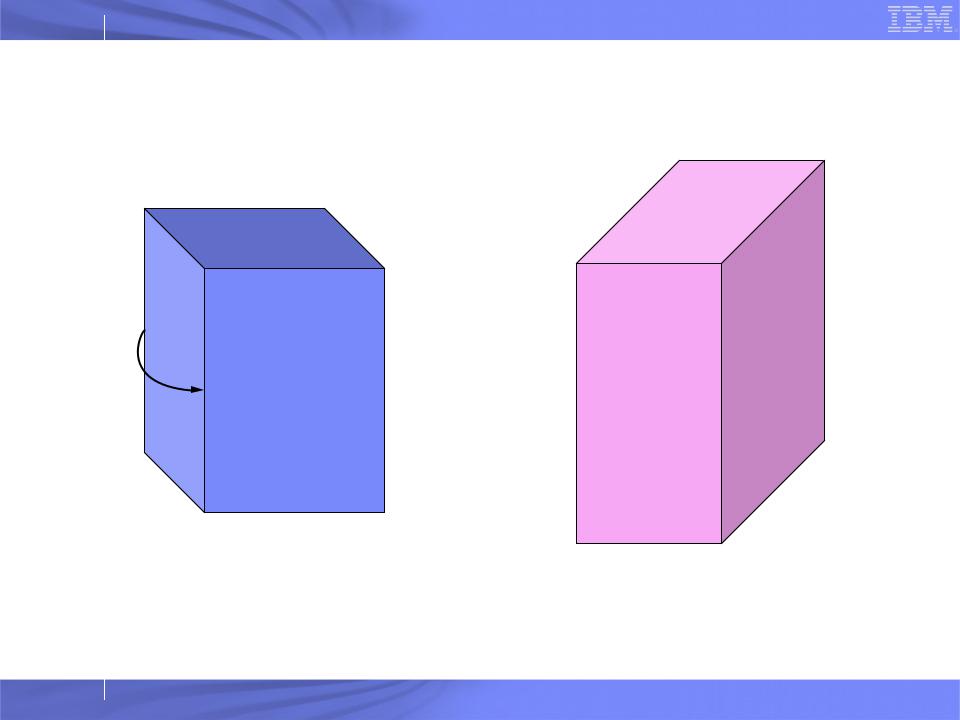
Problem Mapping
Y
Y
|
Z |
Z |
|
|
|
X |
|
X |
Application Data Space |
|
Processor Grid |
|
|
22 |
© 2005 IBM Corporation |
|
IBM Research
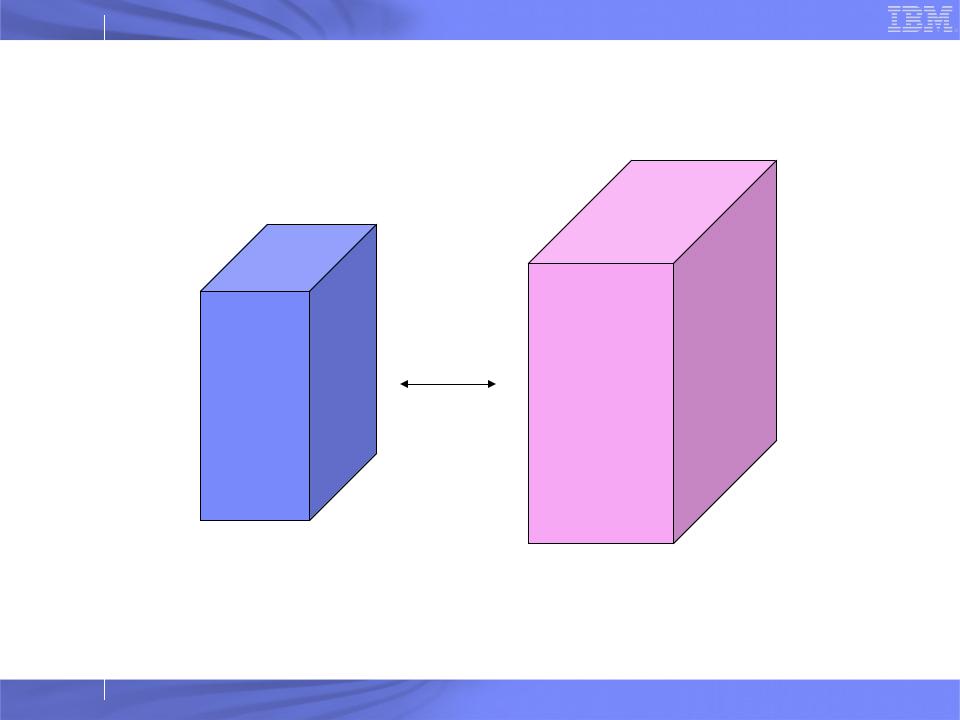
Problem Mapping
Z
X Y
Z
Y |
X |
|
|
Application Data Space |
Processor Grid |
|
23 |
© 2005 IBM Corporation |
|
IBM Research
Problem Mapping
X Y
Y |
Z |
Z |
X |
|
|
Application Data Space |
Processor Grid |
|
24 |
© 2005 IBM Corporation |
|
IBM Research
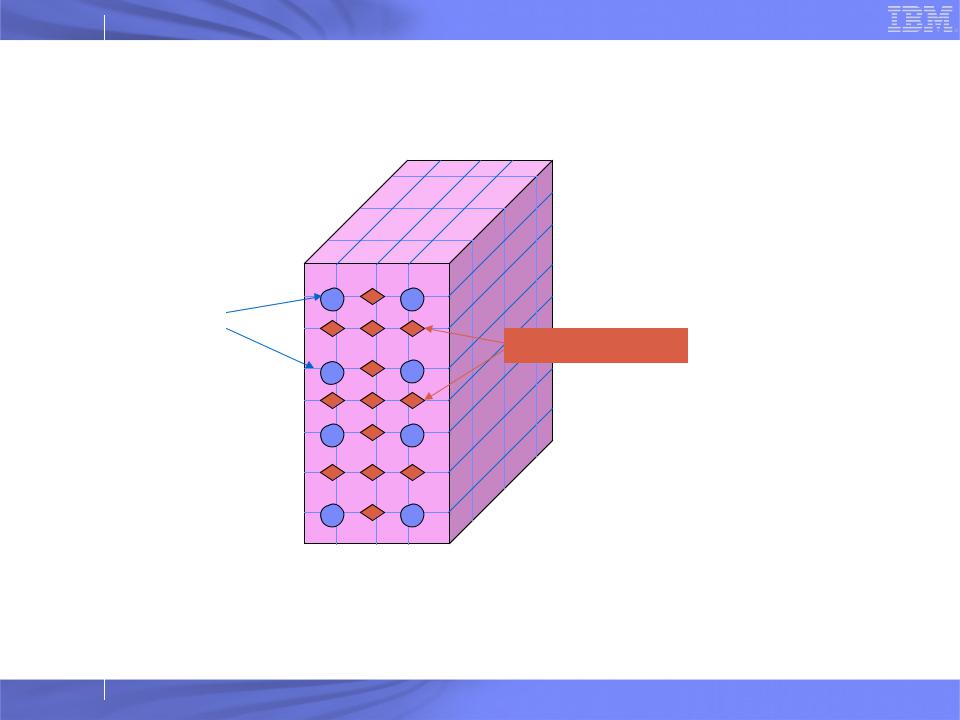
Problem Mapping
Data Objects |
|
Cutoff-driven |
Compute Objects |
|
Y
Z
X
Processor Grid
25 |
© 2005 IBM Corporation |
|

IBM Research
Two Away Computation
Each data object (patch) is split along a dimension
–Patches now interact with neighbors of neighbors
–Makes application more fine grained
–Improves load balancing
–Messages of smaller size sent to more processors
–Improves torus bandwidth
26 |
© 2005 IBM Corporation |
|

IBM Research
Two Away X
27 |
© 2005 IBM Corporation |
|
IBM Research
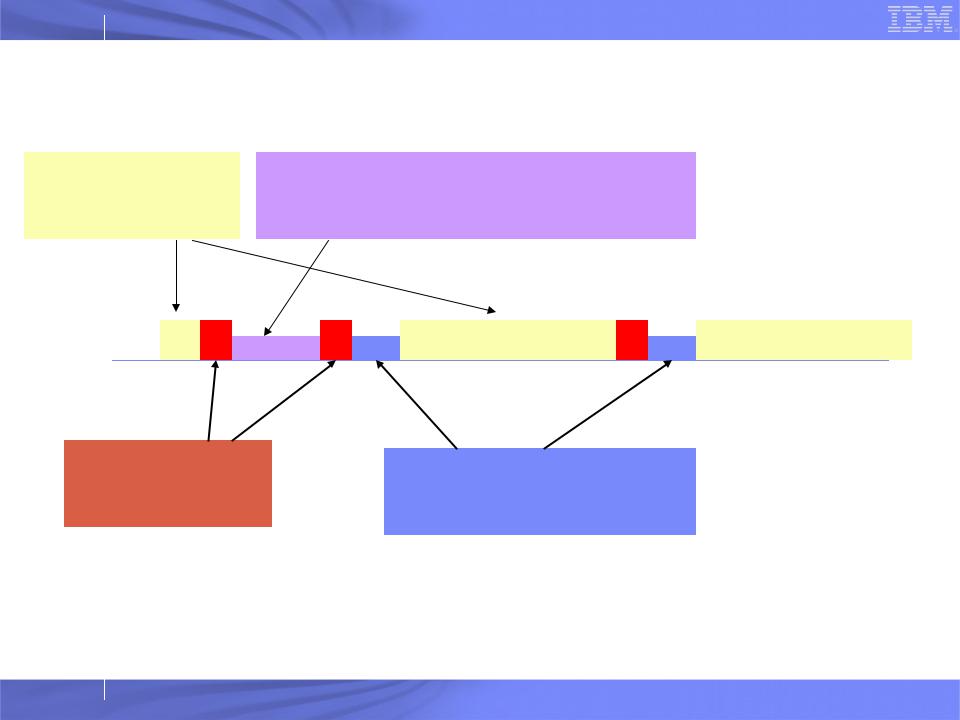
Load Balancing Steps
Regular |
Detailed, aggressive Load |
Timesteps |
Balancing |
Instrumented |
Refinement Load |
Timesteps |
Balancing |
28 |
© 2005 IBM Corporation |
|

IBM Research
Load-balancing Metrics
Balancing load
Minimizing communication hop-bytes
–Place computes close to patches
–Biased through placement of proxies on near neighbors
Minimizing number of proxies
–Effects connectivity of each data object
29 |
© 2005 IBM Corporation |
|

IBM Research
Overlap of Computation and Communication
Each FIFO has 4 packet buffers
Progress engine should be called every 4400 cycles
Overhead of about 200 cycles
– 5 % increase in computation
Remaining time can be used for computation
30 |
© 2005 IBM Corporation |
|