

Лабораторная работа №1
Тема. Получение случайных чисел.
Цель работы. Научиться получать конечный набор значений случайной величины для разных законов распределения.
Теоретический материал. Компьютерное моделирование процессов функционирования стохастической системы, позволяющее получать статистические данные об этих процессах называют статистическим моделированием. Реализация статистического моделирования требует случайного задания исходных данных с известными законами распределения. Поэтому значения выходных переменных (характеристик исследуемых процессов) получаются как вероятностные оценки.
В соответствии с положениями математической статистики описание результатов наблюдений случайных величин использует понятие вероятности.
Фундаментальными понятиями статистической теории являются понятия генеральной совокупности и выборки. Генеральная совокупность – совокупность всех возможных результатов наблюдений над случайной величиной. Выборка – это конечный набор x1, x2, …, xn значений случайной величины, полученный в результате наблюдений. Число элементов n выборки называется ее объемом или размером.
Интуитивно понятно, что чем больше объем выборки, тем более точно она должна отражать статистические свойства случайной величины.
Основными характеристиками распределения случайной величины, являются математическое ожидание и дисперсия.
Случайной называется величина, которая в результате опыта может принимать то или иное значение (какое именно, заранее неизвестно). Вероятностные свойства случайных величин описываются законом распределения, т.е. соотношением, устанавливающим связь между возможными значениями случайной величины и соответствующими им вероятностями. Закон распределения может иметь различные формы. Различают дискретные и непрерывные случайные величины.
Дискретные случайные величины
Дискретной случайной величиной называют величину, принимающую только конечное или счетное множество значений. Для описания дискретной случайной величины X, принимающей конечное множество значений, часто применяется соотношения вида
|
xi |
x1 |
x2 |
… |
xn-1 |
xn |
|
P(X=xi) |
p1 |
p2 |
|
pn-1 |
pn |
Здесь xi — возможные значения случайной величины X, pi = Р(Х = xi) — вероятность события, что случайная величина X примет значение xi (1 < i < n). Отметим, что
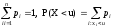
В последнем выражении суммирование ведется по всем таким номерам i, для которых хг < и. Совокупность вероятностей pi = Р(Х = xi) часто называют функцией вероятностей, а вероятность Р(Х < и) обозначают как F(u) и называют функцией распределения случайной величины X.
Непрерывные случайные величины
Непрерывной случайной величиной называется случайная величина, возможные значения которой непрерывно заполняют какой-либо интервал (в том числе, бесконечный). Для непрерывной случайной величины X в качестве закона распределения выступает функция распределения F(u), численно равная вероятности того, что случайная величина X окажется меньше заданного числа и, т.е. F(u) = Р(Х < и). Функция F(u) — непрерывная функция, неубывающая и принимающая значения в интервале от 0 до 1.
Отметим, что распределение непрерывной случайной величины невозможно задать с помощью вероятностей отдельных значений подобно распределениям дискретных случайных величин, поскольку Р(Х = x) = 0 для любого значения х. Но если функция F(u) дифференцируемая, то можно определить вероятность попадания случайной величины X в какой-либо малый интервал длиной dx, примыкающий к точке х, и при этом Р(х <= X <= х + dx) = f(x)dx, где f(x) — производная функции F(u) в точке х. Функция f(x) называется плотностью вероятности случайной величины X. Она может принимать только неотрицательные значения. Из определения плотности вероятности следует, что
U +∞ b
F(u) = ∫ f(x)dx, ∫ f(x)dx = 1, P(a < X < b) = ∫f(x)dx = F(b)- F(a).
-∞ -∞ a
Числовые характеристики случайных величин
Закон распределения полностью характеризует случайную величину. Чтобы определить закон распределения случайной величины, достаточно задать ее плотность вероятности или функцию распределения. Однако, для решения многих практических задач достаточно знать лишь некоторые числа, характеризующие распределение, так называемые числовые характеристики случайной величины. Из числовых характеристик наиболее часто используются моменты случайной величины. Первый момент называется математическим ожиданием (или средним случайной величины) и вычисляется по одной из следующих формул (первая формула применяется для дискретных случайных величин, а вторая — для непрерывных):
MX=∑xipi MX=∫xf(x)dx
Величина MX характеризует среднее положение значений случайной величины X.
Второй центральный момент характеризует разброс значений случайной величины вокруг значения MX и называется дисперсией. Дисперсию DX часто обозначение σ2 или σх2.
Равномерное непрерывное распределение. Непрерывная случайная величина ξ имеет равномерное распределение в интервале (a,b), если её функция плотности f(x) и распределения F(x) имеют вид:

или графически

В этом случае числовые характеристики случайной величины ξ, принимающей значения x – математическое ожидание, дисперсия и среднее квадратичное отклонение соответственно будут:

Если границы интервала a=0, b=1 то функции плотности и распределения имеют вид:
 а
математическое ожидание M|ζ| = 1/2 и
дисперсия D|ζ| = 1/12. Получить это
распределение на цифровой ЭВМ невозможно,
так как машина оперирует с n-разрядными
числами. Поэтому на ЭВМ вместо
непрерывной совокупности равномерных
случайных чисел интервала (0, 1)
используют дискретную последовательность
2n случайных чисел того же интервала.
Закон распределения такой дискретной
последовательности называют
квазиравномерным распределением.
а
математическое ожидание M|ζ| = 1/2 и
дисперсия D|ζ| = 1/12. Получить это
распределение на цифровой ЭВМ невозможно,
так как машина оперирует с n-разрядными
числами. Поэтому на ЭВМ вместо
непрерывной совокупности равномерных
случайных чисел интервала (0, 1)
используют дискретную последовательность
2n случайных чисел того же интервала.
Закон распределения такой дискретной
последовательности называют
квазиравномерным распределением.
Математическое ожидание и дисперсия квазиравномерной случайной величины имеют вид

Дисперсия отличается от дисперсии равномерно распределенной случайной величины только множителем (2n+1)/(2n-1.

Для этой случайной величины МХ = (4(а3+b3)-(а+b)3)/ 6(b-a)2, DX = (b-a)3/24. Если Xt и Х2 — независимые случайные величины, равномерно распределенные на интервале [a/2, b/2], то случайная величина X = X1 + Х2 имеет треугольное распределение на интервале [а,b], представленное на рис. 1.1.

Рис. 1.1. Плотность треугольного распределения
Показательное (экспоненциальное) распределение. Случайная величина X имеет показательное (экспоненциальное) распределение с параметром λ(λ> 0), если ее плотность вероятности вычисляется по формуле
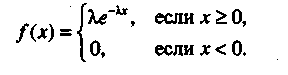
Для этой случайной величины MX = 1/ λ , DX = 1/ λ2; ее функция распределения вычисляется по простой формуле F(u) = 1 - еλu (u > 0). Эта распределение часто встречается в моделировании случайных процессов (оно обладает так называемым свойством отсутствия последействия), рис.1.2.

Рис.1.2. Плотность показательного распределения
Нормальное распределение. Случайная величина X имеет нормальное распределение с параметрами m и σ2, если ее плотность вероятности вычисляется по формуле

Для этой случайной величины MX = m, DX = σ2. Нормальное распределение называют также гауссовским распределением.
Если m=0 и σ2 = 1, то распределение называется стандартным нормальным распределением. Линейное преобразование Y = (X - m)/σ приводит произвольную нормально распределенную величину X к стандартному нормальному распределению, показанному на рис. 1.3.
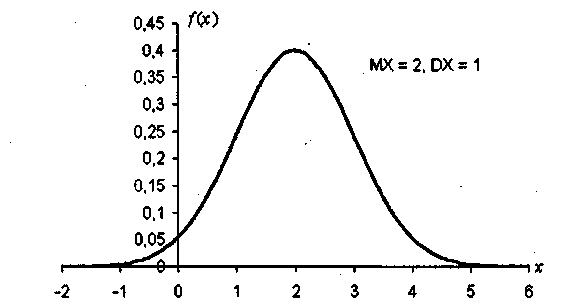
Рис.1.3. Плотность нормального распределения
Фундаментальная роль, которую играет нормальное распределение в теории вероятностей и математической статистике, объясняется тем, что при достаточно широких условиях распределение суммы случайных величин с ростом числа слагаемых асимптотически сходится к нормальному (центральная предельная теорема теории вероятностей).
Нормально распределенная случайная величина с большой вероятностью принимает значения, близкие к своему математическому ожиданию.
На ЭВМ невозможно получить идеальную последовательность случайных чисел хотя бы потому, что на ней можно оперировать только с конечным множеством чисел. Кроме того, для получения значений х случайной величины ζ используются формулы (алгоритмы). Поэтому такие последовательности, являющиеся по своей сути детерминированными, называются псевдослучайными.
Полученные с помощью генератора псевдослучайные последовательности чисел должны состоять из квазиравномерно распределенных чисел, содержать статистически независимые числа, быть воспроизводимыми, иметь неповторяющиеся числа, получаться с минимальными затратами машинного времени, занимать минимальный объем машинной памяти.
Моделирование случайных величин с помощью компьютера основано на преобразовании случайных чисел, имеющих равномерное распределение на интервале [0, 1] в случайные величины, имеющие другие распределения.
Получение случайных чисел, имеющих равномерное распределение на интервале [0, 1] возможно различными способами.
Мультипликативный способ заключается в следующем: если ri = 0,0040353607, то ri+1 = {40353607·ri }mod 1, где mod 1 означает операцию извлечения из результата только дробной части после десятичной точки. Литературные источники говорят, что числа ri, начинают повторяться после цикла из 50 миллионов чисел, так что r50000001= ri. Последовательность ri получается квазиравномерно распределенной на интервале (0, 1). Однако, наиболее часто используются стандартную функцию, имеющуюся в языках программирования. Будем называть эту функцию random().
Проверка качества последовательностей псевдослучайных чисел {xi} на соответствие закону распределения может быть выполнена с помощью гистограмм. Интервал (xmin, xmax) разбивается на т равных частей (подинтервалов), тогда при генерации последовательности {xi} каждое из чисел хj с вероятностью pj= 1/m, j= 1,2,…,m, попадает в один из подынтервалов.
Построив столбики высота которых пропорциональна количеству значений xi, попавших в подинтервал, получим гистограмму наглядно представляющую распределение значений рассматриваемой величины.
Допустим, имеется n измерений некоторой величины х1, х2, ..., хn. Для построения гистограммы выполним следующие действия.
Определим размах выборки х1, х2, ..., хn , т.е. R = xmax - xmin
Интервал R делим на m равных участков (допустим
 ),
желательно, чтобы 5<=
m<=20; тогда
ширина одного участка s
= r/m.
),
желательно, чтобы 5<=
m<=20; тогда
ширина одного участка s
= r/m.Определим количество значений xi , попавших в каждый из m участков. Для этого используем формулу для номера участка, в который попадает значение xi: k:=[(xi-xmin)/s]+1, где k - номер участка в который попадает значение xi, s - ширина одного участка, [ ] означают, что нужно взять целую часть значения в скобках. Учтем, что применение этой формулы для xmax дает k= m + 1.
Строим m столбцов равной ширины, высота столбцов пропорциональна количеству значений xi , попавших в соответствующий участок интервала.
В результате вместо n чисел получим m чисел (m<<n).
Алгоритм решения этой задачи можно представить в следующем виде (рис. 1.4).
Рассмотрим некоторые способы преобразования последовательности равномерно распределенных случайных чисел {х,} в последовательность с заданным законом распределения {yj}.
Формула, используемая для создания генератора случайных чисел равномерно распределенных на интервале (a, b), использующая функцию random(), имеет следующий вид:
a + ( b - а)* random().
Формулы для создания генераторов случайных чисел:
для симметричного треугольного распределения: a + ( b - а)*( random()+random())/2;
для нормального распределений имеющего среднее значение μ, (соответствующее максимальной вероятности) и среднеквадратическое отклонение σ, (определяющее ширину или размах распределения) числа an можно получить с помощью алгоритма:
a :=0.0;
for i=1 to 12 do a := a + random()
an:= μ + (a-6.0)* σ;
псевдослучайную последовательность, распределенную по экспоненциальному закону можно получить с помощью алгоритма:
r := log(random());
me := μ *(-r); μ – математическое ожидание.
Задание.
Изучить теоретический материал.
Написать программу, реализующую алгоритм получения случайных чисел и построения гистограммы их распределения.
Реализовать программное получение последовательности случайной величины: а) равномерно распределенной на заданном интервале, б) для симметричного треугольного распределения, в) для нормального распределения, г) для экспоненциального распределения.
С помощью гистограмм проанализировать влияние количества значений (n) на качество получаемых последовательностей.
Рассмотреть распределение случайных величин для нескольких вариантов размера выборки (20, 100, 300 значений).
Представить полученные результаты преподавателю.

Рис.1.4. Схема алгоритма получения случайных чисел и построения гистограммы их распределения (m=5).
Подготовить ответы на контрольные вопросы. Чем вызвана необходимость генерации случайных величин в имитационном моделировании? Как можно оценить качество псевдослучайных чисел, получаемых с помощью стандартной функции языка программирования random()? Какие исходные данные нужны для получения случайных чисел имеющих нормальное распределение, экспоненциальное распределение, симметричное треугольное распределение?