

ГУАП1
.docГУАП
КАФЕДРА № 43
ОТЧЕТ ЗАЩИЩЕН С ОЦЕНКОЙ
ПРЕПОДАВАТЕЛЬ
Старший преподаватель __________________________________ Соколовская М.В.
ОТЧЕТ О ЛАБОРАТОРНОЙ РАБОТЕ
КОДИРОВАНИЕ ДИСКРЕТНЫХ ИСТОЧНИКОВ ИНФОРМАЦИИ МЕТОДОМ ШЕННОНА-ФАНО И МЕТОДОМ Д.ХАФФМАНА
по дисциплине: ИНФОРМАТИКА
РАБОТУ ВЫПОЛНИЛА СТУДЕНТКА ГР. 6231К ______________________________________ Федоровская А.С.
Санкт-Петербург 2012
<1>
Цель работы: освоить метод построения кодов дискретного источника информации, используя конструктивный метод, предложенный К.Шенноном и Н.Фано и методику Д.Хаффмана. На примере показать однозначность раскодирования имеющегося сообщения.
При кодировании дискретных источников информации нужно уменьшить количество символов для передачи сообщения по каналу связи- избыточность. Тогда информация будет передаваться быстрее, и потребуется меньше памяти для её хранения.
Любое сообщения можно передать, используя ноль и единицу. Тогда кодовое слово будет состоять из последовательностей нулей и единиц.
Если алфавит A состоит из N символов, то для такого кодирования необходимо слово разрядностью n, которая определяется
n = log2 N .
Это справедливо для стандартных кодовых таблиц.
В нашей работе - 50 символов. Это меньше, чем 256, что позволит удобнее сжать информацию. В ней любой символ будет кодироваться меньшим количеством нулей и единиц, а при кодировании не будет передаваться избыточная информация. У более вероятных символов кодовое слово будет короче, чем у менее вероятных символов. Такое кодирование называется эффективным.
Оно создано на основной теореме Шеннона, которая гласит, что сообщения, составленные из букв некоторого алфавита, можно закодировать так, что среднее число двоичных символов на букву будет сколь угодно близко к энтропии источника этих сообщений, но не меньше этой величины.
К.Шеннон и Н.Фано показали, как это можно сделать на практике. Этот метод назвали кодом Шеннона-Фано.
Таблица из лаб №3с отсортированными по правилу значениями энтропии
<2>
Код строится следующим образом:
буквы алфавита сообщений выписываются в таблицу в порядке убывания вероятностей. Затем они разделяются на две группы так, чтобы суммы вероятностей в каждой из групп были по возможности одинаковы. Всем буквам верхней половины в качестве первого символа приписывается 1, а всем нижним — 0. Каждая из полученных групп, в свою очередь, разбивается на две подгруппы с одинаковыми суммарными вероятностями и т. д. Процесс повторяется до тех пор, пока в каждой подгруппе останется по одной букве.

50
H=∑p(ai)log2p(ai)= 4,40839807
1
H – энтропия (entropy)
p(ai) – вероятность символа
50
Iср =∑p(ai)n(ai)= 4,620954551
1
Iср - среднее количество двоичных разрядов, используемых при кодировании символов по алгоритму Шеннона-Фано
n(ai) — число двоичных разрядов в кодовой комбинации, соответствующей символу ai
Построенный код близок к наилучшему эффективному коду по Шеннону, но не является лучшим. Следовательно, метод Шеннона выполнен правильно.
-
Пример декодирования сообщения
Мой пример: термометр.
Т – 0111 011101001001110110001101000100011110011
Е – 0100
Р – 10011
М – 10110
О – 001
М – 10100
Е – 0100
Т – 0111
Р – 10011

Алгоритм Хаффмана для двоичного кода:
<5>
|
Сим волы |
Вероятности р(а1) |
Вспомогательные вычисления |
|||||||||||||
|
|
Шаг1 |
|
Шаг2 |
|
Шаг 3 |
|
Шаг 4 |
|
Шаг 5 |
|
Шаг 6 |
|
Шаг7 |
||
|
а1 |
|
|
0,22 |
|
0,22 |
|
0,26 |
|
0,32 |
|
0,42 |
|
0,58 |
|
1,0 |
|
а2 |
0,20 |
|
0,20 |
|
0,20 |
|
0,22 |
|
0,26 |
|
0,32 |
|
0,42 |
|
|
|
а3 |
0,16 |
|
0,16 |
|
0,16 |
|
0,20 |
|
0,22 |
|
0,26 |
|
|
|
|
|
а4 |
0,16 |
|
0,16 |
|
0,16 |
|
0,16 |
|
0,20 |
|
|
|
|
|
|
|
а5 |
0,10 |
|
0,10 |
|
0,16 |
|
0,16 |
|
|
|
|
|
|
|
|
|
а6 |
0,10 |
|
0,10 |
|
0,10 |
|
|
|
|
|
|
|
|
|
|
|
а7 |
0,04 |
|
0,06 |
|
|
|
|
|
|
|
|
|
|
|
|
|
а8 |
0.02 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
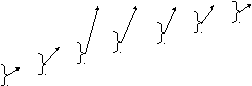 0,22
0,22То, что осталось, и полученная суммарная вероятность снова располагаются по убыванию в дополнительном столбце, а две последних вероятности складываются. Повторять пока в последнем столбике должна остаться единица. Символы выписываются в основной столбец и снова сортируются от самой большой вероятности к самой маленькой. Два последних символа объединяются в один вспомогательный, которому приписывается суммарная вероятность.
Далее строится кодовое дерево и составляются кодовые слова. «Корнем» дерева будет единица. Оттуда направляются две ветви. Ветви с большей вероятностью присваивается символ 1, а с меньшей — символ 0. Это повторяется до тех пор, пока не дойдём до каждого символа.
<6>

Кодовые слова составляются от начала к концам. Каждому ответвлению влево пишется символ 1, вправо — символ 0. Ни одно кодовое слово не будет началом другого, поскольку только концам дерева сопоставляются кодовые слова. Можно разбить последовательность кодовых слов на отдельные кодовые слова. Теперь, двигаясь по кодовому дереву сверху вниз, можно записать для каждой буквы соответствующую ей кодовую комбинацию.
|
a1 |
a2 |
a3 |
a4 |
a5 |
a6 |
a7 |
a8 |
|
01 |
00 |
111 |
110 |
100 |
1011 |
10101 |
10100 |
<7>
Вывод:
Мы освоили метод построения кодов дискретного источника информации, используя конструктивный метод, предложенный К.Шенноном и Н.Фано и методику Д.Хаффмана и на примере показали однозначность раскодирования имеющегося сообщения. Методика Хаффмана лучше, поскольку кодирование однозначно. Символ будет кодироваться меньшим количеством нулей и единиц.
<8>