

РЕФЕРАТ
Пояснювальна записка: 38с., 14 рис.,3 формули, 2 додатки, 5 джерел.
Курсова робота присвячена порівнянню загальних характеристик роботи різних методів сортування.
СОРТУВАННЯ МЕТОДОМ БУЛЬБАШКИ, СОРТУВАННЯ МЕТОДОМ ШЕЛЛА, ШВИДКЕ СОРТУВАННЯ, СОРТУВАННЯ ВСТАВКАМИ, СОРТУВАННЯ ВИБОРОМ, СОРТУВАННЯ МЕТОДОМ ЗНАХОДЖЕННЯ МІНІМАЛЬНОГО ЕЛЕМЕНТА
РЕФЕРАТ
Обьяснительная записка: 38с., 3 рис., 2 приложения, 5 источников.
Курсовая работа посвящена сравнению общих характерисик работы разных методов сортировки.
СОРТИРОВКА МЕТОДОМ ПУЗЫРЬКА, СОРТИРОВКА МЕТОДОМ ШЕЛЛА, БЫСТРАЯ СОРТИРОВКА, СОРТИРОВКА ВСТАВКАМИ, СОРТИРОВКА ВЫБОРОМ, СОРТИРОВКА МЕТОДОМ НАХОЖДЕНИЯ МИНИМАЛЬНОГО ЭЛЕМЕНТА .
ЗМІСТ
ВСТУП
В даний час обчислювальна техніка проникла практично в усі сфери людської діяльності. За допомогою ЕОМ можна вирішувати найрізноманітніші завдання. Але для того, щоб вирішити поставлену задачу, необхідно вказати послідовність дій, виконання яких приведе до необхідного результату, - скласти програму. Для зручності роботи з ЕОМ ця операція проводиться за допомогою мов програмування (високого або низького рівня).
Один із широко використовуваних мов програмування - це Visual C + +, який можна використовувати для написання програм, що працюють в операційному середовищі Windows. На даний час однієї з найпоширеніших його версій є Microsoft Visual C + +, і середовище програмування Visual studio.Середовище програмування Visual studio дозволяє створювати тексти програм, компілювати їх, знаходити помилки і оперативно їх виправляти; компонувати програми з окремих частин, включаючи стандартні модулі, налагоджувати і виконувати налагоджену програму.
Використовуючи перераховані можливості, можна створювати різні прикладні програми, наприклад, такі, як програма, написана при виконанні даної курсової роботи.
1.Відомості про методи сортування
Для вирішення багатьох завдань зручно спочатку упорядкувати дані за певною ознакою, так можна прискорити пошук деякого об'єкту. Наприклад, в преферансі гравці розкладають карти по мастям і за значенням. Так легше визначити, яких карт не вистачає. Або візьмемо будь енциклопедичний словник - статті в ньому впорядковані в алфавітному порядку.
Перегруповування заданої множини об'єктів в певному порядку називають сортуванням.
Чому сортування приділяється велика увага? Ви це зрозумієте, прочитавши цитати двох великих людей.
"Навіть якщо б сортування була майже марна, знайшлася б маса причин зайнятися нею! Винахідливі методи сортування говорять про те, що вона і сама по собі цікава як об'єкт дослідження." / Д. Кнут /
"Складається враження, що можна побудувати цілий курс програмування, вибираючи приклади тільки із завдань сортування." / Н. Вірт /
Відмінною особливістю сортування є та обставина, що ефективність алгоритмів, що реалізують її, прямо пропорційна складності розуміння цього алгоритму. Іншими словами, чим легше для розуміння метод сортування масиву, тим нижче його ефективність.
2.АЛГОРИТМИ
2.1 Сортування методом бульбашки
Розташуємо масив зверху вниз, від нульового елемента - до останнього.
Ідея методу: крок сортування полягає в проході знизу вгору по масиву. По дорозі проглядаються пари сусідніх елементів. Якщо елементи деякої пари знаходяться в неправильному порядку, то міняємо їх місцями (Рис. 5.1).
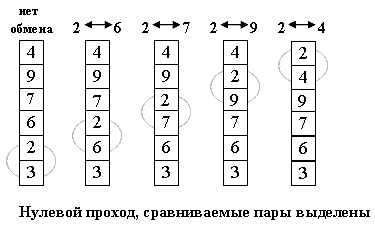
Рисунок 2.1 – Принцип роботи сортування методом бульбашки
Після нульового проходу по масиву "вгорі" виявляється самий "легкий" елемент - звідси аналогія з бульбашкою (Рис. 5.2). Наступний прохід робиться до другого зверху елемента, таким чином другий за величиною елемент піднімається на правильну позицію.
Робимо проходи по все зменшується нижній частині масиву до тих пір, поки в ній не залишиться тільки один елемент. На цьому сортування закінчується, так як послідовність упорядкована за зростанням.(Рис.2.2)

Рисунок 2.2 – Результат нульового кроку сортування
Середнє число порівнянь та обмінів мають квадратичний порядок зростання: Theta (n2), звідси можна зробити висновок, що алгоритм бульбашки дуже повільний і малоефективний.
Тим не менш, у нього є величезний плюс: він простий і його можна по-всякому покращувати. Чим ми зараз і займемося.
По-перше, розглянемо ситуацію, коли на якому-небудь з проходів не відбулося жодного обміну. Що це означає?
Це означає, що всі пари розташовані в правильному порядку, так що масив вже відсортований. І продовжувати процес не має сенсу (особливо, якщо масив був відсортований з самого початку!).
Отже, перше поліпшення алгоритму полягає в запам'ятовуванні, чи проводився на даному проході який-небудь обмін. Якщо ні - алгоритм закінчує роботу.
Процес поліпшення можна продовжити, якщо запам'ятовувати не тільки сам факт обміну, але і індекс останнього обміну k. Дійсно: всі пари сусіди елементів з індексами, меншими k, вже розташовані в потрібному порядку. Подальші проходи можна закінчувати на індексі k, замість того щоб рухатися до встановленої заздалегідь верхньої межі i.
Якісно інше поліпшення алгоритму можна отримати з наступного спостереження. Хоча легкий бульбашка знизу підніметься наверх за один прохід, важкі бульбашки опускаються зі мінімальною швидкістю: один крок за ітерацію. Так що масив 2 3 4 5 6 1 буде відсортований за 1 прохід, а сортування послідовності 6 1 2 3 4 5 зажадає 5 проходів.
Щоб уникнути подібного ефекту, можна змінювати напрямок наступних один за іншим проходів. Одержаний алгоритм іноді називають "шейкер-сортуванням".
Наскільки описані зміни вплинули на ефективність методу? Середня кількість порівнянь, хоч і зменшилася, але залишається O (n2), в той час як число обмінів не помінялося взагалі ніяк. Середнє (воно ж найгірше) кількість операцій залишається квадратичним.
Додаткова пам'ять, очевидно, не потрібно. Поведінка удосконаленого (але не початкового) методу досить природне, майже відсортований масив буде відсортований набагато швидше випадкового. Сортування бульбашкою стійка, проте шейкер-сортування втрачає цю якість.
На практиці метод бульбашки, навіть з поліпшеннями, працює, на жаль, занадто повільно. А тому - майже не застосовується.
2.2 Сортування методом Шелла
Сортування Шелла є досить цікавою модифікацією алгоритму сортування простими вставками.
Розглянемо наступний алгоритм сортування масиву a [0] .. a [15] (Рис. 5.3).
![]()
Рисунок 2.3 – Початковий стан масиву а
-
Спочатку сортуємо простими вставками кожні 8 груп з 2-х елементів (a [0], a [8 [), (a [1], a [9]), ... , (а [7], a [15]) (Рис. 5.4).

Рисунок 2.4 – Схема роботи методу сортування Шелла
-
Потім сортуємо кожну з чотирьох груп по 4 елемента (a [0], a [4], a [8], a [12]), ..., (a [3], a [7], a [11] , a [15]) (Рис. 5.5).

Рисунок 2.5 – Другий шаг сортування
В нульової групи будуть елементи 4, 12, 13, 18, в першій - 3, 5, 8, 9 тощо.
-
Далі сортуємо 2 групи по 8 елементів, починаючи з (a [0], a [2], a [4], a [6], a [8], a [10], a [12], a [14] ) (Рис. 5.6).

Рисунок 2.6 – Сортування груп елементів
-
В кінці сортуємо вставками всі 16 елементів (Рис. 5.7).
![]()
Рисунок 2.7 – Результат сортування методом Шелла
Очевидно, лише останнє сортування необхідне, щоб розташувати всі елементи по своїх місцях. Так навіщо потрібні інші?
Насправді вони просувають елементи максимально близько до відповідних позицій, так що в останній стадії число переміщень буде вельми невелика. Послідовність і так майже відсортована. Прискорення підтверджено численними дослідженнями і на практиці виявляється досить суттєвим.
Єдиною характеристикою сортування Шелла є приріст - відстань між сортованими елементами, в залежності від проходу. В кінці прирощення завжди дорівнює одиниці - метод завершується звичайної сортуванням вставками, але саме послідовність збільшень визначає зростання ефективності.
Використаний в прикладі набір ..., 8, 4, 2, 1 - непоганий вибір, особливо, коли кількість елементів - ступінь двійки.
При використанні таких приростів середня кількість операцій: O (n7 / 6), в гіршому випадку - порядку O (n4 / 3).
Звернемо увагу на те, що послідовність обчислюється в порядку, протилежному використовуваному: inc [0] = 1, inc [1] = 5, ... Формула дає спочатку менші числа, потім все більші і більші, у той час як відстань між сортованими елементами, навпаки, має зменшуватися. Тому масив приростів inc обчислюється перед запуском власне сортування до максимальної відстані між елементами, яке буде першим кроком в сортуванні Шелла. Потім його значення використовуються в зворотному порядку.
2.3 Швидке сортування
Опис алгоритму:
-
вибрати елемент, званий опорним.
-
порівняти всі інші елементи з опорним, на підставі порівняння розбити безліч на три - «менші опорного», «рівні» та «великі», розташувати їх у порядку менші-рівні-великі.
-
повторити рекурсивно для «менших» і «великих».
Примітка: на практиці звичайно поділяють сортовані безліч не на три, а на дві частини: наприклад, «менші опорного» і «рівні і великі». Такий підхід в загальному випадку виявляється ефективніше, тому що для здійснення такого поділу достатньо одного проходу по сортованому безлічі і однократного обміну лише деяких обраних елементів.
Алгоритм швидкого сортування використовує стратегію «розділяй і володарюй». Кроки алгоритму наступні:
-
Вибираємо в масиві деякий елемент, який будемо називати опорним елементом. З точки зору коректності алгоритму вибір опорного елемента байдужий. З точки зору підвищення ефективності алгоритму вибиратися повинна медіана, але без додаткових відомостей про сортованих даних її зазвичай неможливо отримати. Відомі стратегії: вибирати постійно один і той же елемент, наприклад, середній або останній по положенню; вибирати елемент з випадково вибраним індексом.
-
Операція поділу масиву: реорганізуємо масив таким чином, щоб всі елементи, менші або рівні опорному елементу, виявилися зліва від нього, а всі елементи, великі опорного - праворуч від нього. Звичайний алгоритм операції:
-
Два індексу - l і r, прирівнюються до мінімального і максимального індексу розділяється масиву відповідно.
-
Обчислюється індекс опорного елемента m.
-
Індекс l послідовно збільшується до тих пір, поки l-й елемент не перевищить опорний.
-
Індекс r послідовно зменшується до тих пір, поки r-й елемент не виявиться менше або дорівнює опорному.
-
Якщо r = l - знайдена середина масиву - операція поділу закінчена, обидва індекси вказують на опорний елемент.
-
Якщо l <r - знайдену пару елементів потрібно обміняти місцями і продовжити операцію поділу з тих значень l і r, які були досягнуті. Слід врахувати, що якщо яка-небудь кордон (l або r) дійшла до опорного елемента, то при обміні значення m змінюється на r-й або l-й елемент відповідно.
-
Рекурсивно упорядковуємо подмассіва, що лежать ліворуч і праворуч від опорного елемента.
Базою рекурсії є набори, що складаються з одного або двох елементів. Перший повертається в початковому вигляді, в другому, при необхідності, сортування зводиться до перестановки двох елементів. Всі такі відрізки вже впорядковані в процесі поділу.
Оскільки в кожній ітерації (на кожному наступному рівні рекурсії) довжина оброблюваного відрізка масиву зменшується, щонайменше, на одиницю, термінальна гілку рекурсії буде досягнута завжди і обробка гарантовано завершиться.
QuickSort є істотно поліпшеним варіантом алгоритму сортування за допомогою прямого обміну (його варіанти відомі як «Бульбашкова сортування» та «Шейкерная сортування»), відомого, зокрема, своєї низькою ефективністю. Принципова відмінність полягає в тому, що після кожного проходу елементи діляться на дві незалежні групи. Цікавий факт: поліпшення самого неефективного прямого методу сортування дало в результаті ефективний покращений метод.
Кращий випадок. Для цього алгоритму найкращий випадок - якщо в кожній ітерації кожен з підмасивів ділився б на два рівних по величині масиву. В результаті кількість порівнянь, які робить швидкої сортуванням, було б дорівнює значенню рекурсивного вираження CN = 2CN / 2 + N, що в явному вираженні дає приблизно N lg N порівнянь. Це дало б найменший час сортування.
Середнє. Дає в середньому O (n log n) обмінів при упорядкуванні n елементів. В реальності саме така ситуація зазвичай має місце при випадковому порядку елементів і виборі опорного елемента з середини масиву або випадково.
На практиці (у випадку, коли обміни є більш витратною операцією, ніж порівняння) швидке сортування значно швидше, ніж інші алгоритми з оцінкою O (n lg n), через те, що внутрішній цикл алгоритму може бути ефективно реалізований майже на будь-архітектурі. 2CN / 2 покриває витрати по сортуванню двох отриманих підмасива; N - це вартість обробки кожного елемента, використовуючи один або інший вказівник. Відомо також, що приблизне значення цього виразу одно CN = N lg N.
Найгірший випадок. Найгіршим нагодою, очевидно, буде такою, при якому на кожному етапі масив буде розділятися на вироджений підмасив з одного опорного елемента і на підмасив з усіх інших елементів. Таке може статися, якщо як опорного на кожному етапі буде обраний елемент або найменший, або найбільший з усіх оброблюваних.
Найгірший випадок дає O (n ²) обмінів. Але кількість обмінів і, відповідно, час роботи - це не найбільший його недолік. Гірше те, що в такому випадку глибина рекурсії при виконанні алгоритму досягне n, що буде означати n-кратне збереження адреси повернення і локальних змінних процедури поділу масивів. Для великих значень n найгірший випадок може привести до вичерпання пам'яті під час роботи алгоритму. Втім, на більшості реальних даних можна знайти рішення, які мінімізують ймовірність того, що знадобиться квадратичне час.