

1.2 Введение вStl
Когда проектировали STL, хотели, чтобы она могла как со своими типами данных работать – контейнерами, так и с существующими типами данных – массивами и др.
У библиотеки могут быть различные реализации. Однако какова бы реализация ни была, она должна удовлетворять спецификации работы и заданным метрикам производительности.
В качестве метрик производительности использовался О-синтаксис. Для себя можете посмотреть, как оценивается производительность алгоритма в этом синтаксисе, а также критику этого подхода.
1.2.1 Обзор библиотеки
Концептуально библиотека состоит из четырех вещей: алгоритмов, контейнеров, итераторов, функторов.
Их легко представлять в виде схемы: микросхемы – контейнеры, функторы, алгоритмы, провода – итераторы. Идея за итераторами такая: как связать различные алгоритмы с различными контейнерами? Не хочется дублировать каждый алгоритм под каждый тип контейнера: у каждого контейнера разный набор методов. Придумали идею с итераторами. Пусть алгоритмы работают не напрямую с контейнером, а через прослойку, которая умеет ходить по элементам. И пусть все контейнеры смогут эту прослойку предоставлять. Завели итератор. Итератор – некоторая сущность, которая позволяет ходить в каком-то направлении по содержимому контейнера, а также получать и менять данные.
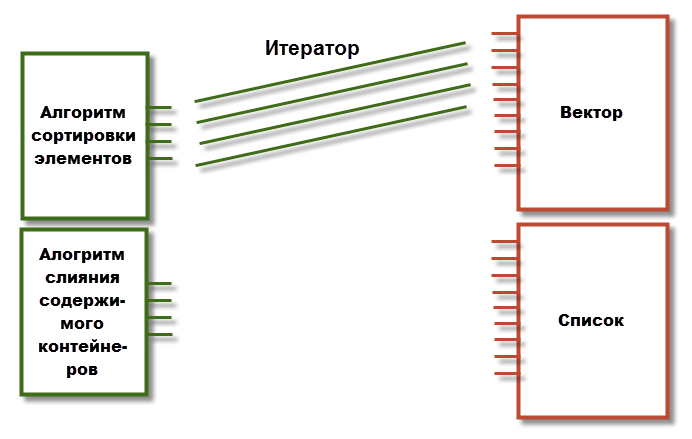
1.2.2 Базовые понятия
Алгоритм – вычислительная процедура.
Контейнер – класс, управляющий набором объектов в памяти.
Итератор – прослойка между конкретным контейнером и обобщенным алгоритмом.
Функциональный объект / функтор / - инкапсулирует функцию в объекте для использования другими. Лямбда-выражение – анонимный функтор со специальным синтаксисом.
2 Контейнеры
В контейнерах можно выделить основные используемые типы данных: пара, вектор, список, очередь, стек, словарь.
2.1 Простые контейнеры
2.1.1 Пара (Pair/Tuple)
Пара значений состоит из двух связанных как-то значений. Часто бывает лениво плодить отдельную структуру или класс только для того, чтобы объединить данные, списками которых обмениваются подпрограммы (смотрите подпрограмму в примере, типичный случай)… Когда количество данных невелико, используются пары. Пара агрегирует 2 значения и предоставляет к ним доступ.
Примеры создания пар ниже.
#include "stdafx.h"
#include <utility>
#include <vector>
using namespace std;
vector<pair<int, int> > GetPoints()
{
vector<pair<int, int> > points;
points.push_back(make_pair(1, 1));
points.push_back(make_pair(1, 3));
points.push_back(make_pair(2, 4));
return points;
}
int _tmain(int argc, _TCHAR* argv[])
{
pair <int, int> point(13, 555); // конструкторы инициализации
pair <int, int> point2; // по-умолчанию
pair <int, int> point3(point); // копирования
auto point4 = make_pair(3, 4); // pair <int, int> point(3, 4);
auto points = GetPoints();
return 0;
}
Зачем добавили make_pair подпрограмму?
Чтобы не писать явно типы, вида pair<int,int>.
Как достать агрегированные данные?
Структура позволяет получить данные через поля firstиsecond.
Как в дальнейшем развивался этот концепт?
Выяснилось, что иногда хочется агрегировать не 2, а больше данных: поэтому пару подогнули в других языках программирования, чтобы количество аргументов было опциональным. Также концепт переименовали в Tuple.
Насколько кошерно пользоваться парой?
Ведь исчезает смысл полей. Легко перепутать и ошибиться.
В принципе, когда передается много данных в паре, то приходится помнить, что за оно. Легко ошибиться, например, пришла пара tuple<int,int,int>(13,333,333), без просмотра исходного кода, сложно понять, какое число что обозначает. Подход: если где-то в одном месте это понадобилось сделать – то это еще ничего, а если внутри системы циркулируют только пары, то это некошерно: тяжело читать код, лучше завести структуру.