

-
Система прерывания программ
По заданию требуется последовательная система прерываний с обработкой на макро уровне. Такая структура предполагает наличие одной общей для всех устройств линии запроса на прерывание.
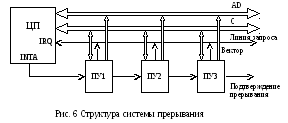
Получив запрос, процессор посылает сигнал, подтверждающий получение запроса. Сигнал подтверждения прерывания проходит от одного ПУ к другому, пока не достигнет первого ПУ, выставившего запрос. Тогда это ПУ выдает вектор прерывания на шину AD [2]. Процесс захвата шины более подробно рассмотрен в п. 2.1, здесь рассматривается только СПП. В такой структуре распределение приоритетов фиксировано, при чем больший приоритет имеет ПУ, подключенное к линии запроса ближе к ЦП.
Процессор распознает и начинает обрабатывать прерывание на границах команд, т.е. асинхронное прерывание (вырабатывается ПУ) начнет обрабатываться после завершения текущей команды. Важно отметить, что внутренние прерывания (деление на ноль, переполнение и д.р.) должны обрабатываться на микропрограммном уровне, т.е. после завершения текущей микрокоманды.
Вектор представляет собой 8-разрядный номер обработчика прерывания. Некоторые вектора назначены аппаратно (для внутренних прерываний), другие формируют внешние схемы. По этому номеру процессор выбирает один из 256 обработчиков прерываний, обращаясь к таблице дескрипторов прерываний, которая находится в ОП. Таблица дескрипторов прерываний аналогична сегментным таблицам, и для нее в процессоре есть регистр, хранящий начальный адрес. Элементы дескрипторной таблицы содержат селектор (индекс в сегментной таблице) кода и смещение внутри него, совместно они однозначно определяют точку входа обработчика [3].
Для возможности возврата к прерванной программе необходимо запомнить состояние программы до прерывания, а после прерывания восстановить это состояние. Во время сохранения и восстановления состояния программы прерывания запрещены. При обработке прерывания на командном уровне всегда необходимо запоминать селектор кода и смещение в сегменте кода, содержание регистра флагов, регистров общего назначения (программно доступные) и дополнительную информацию, в зависимости от обработчика. Эта информация запоминается в стеке в ОП. При обработке внутренних прерываний (на микропрограммном уровне) необходимо сохранять еще информацию из регистра микрокоманд, адрес следующей микрокоманды.
-
Прямой доступ к памяти
Для обмена информацией между ОП и НГМД и «винчестером» (ПУ с блочной передачей) используется прямой доступ к памяти. Это позволяет освободить ЦП от необходимости управлять обменом данных и, следовательно, предоставлять ему возможность выполнения других задач во время пересылки (не используя магистраль), а также обеспечивает высокую скорость пересылки данных [2].
Прямой доступ к памяти осуществляется под управлением предварительно настраиваемого процессором контроллера ПДП. При настройке процессор загружает в регистры контроллера начальный адрес в памяти для передаваемого блока данных, длину блока и вид операции.
Мультиплексируемая шина адреса/данных подразумевает перед передачей слова в память или из памяти передачу адреса в память (п. 2.1), снижая пропускную способность шины почти в два раза. При передаче блока данных обычно используют последовательно расположенные ячейки памяти. В таком случае в память можно передавать только начальный адрес блока данных, а формирование текущего адреса возложить на устройство управления памятью [1].
Возникает также проблема длительной монополизации интерфейса контроллером ПДП. Для высокоскоростных ПУ более предпочтительна блочная передача, при которой процессор останавливается на все время передачи (без запоминания слова состояния) или работает, не используя магистраль, т.е. если информация есть в КЭШе. Для медленных ПУ предпочтителен режим захвата цикла шины [2] (одноцикловый [1]), при котором выполнение программы (процессор не блокируется) и пересылка с ПДП совмещаются во времени. Если цикл памяти нужен одновременно и ЦП и ПУ, осуществляющему пересылку с ПДП, то приоритет отдается последнему, а ЦП ожидает окончания цикла ПДП. При длительном использовании магистрали функция регенерации ОП лежит на КПДП. В контролерах ПДП для каждого устройства (распределенный ПДП [2]) реализуется один из приведенных режимов в зависимости от их скоростных характеристик: «винчестер» - блочная передача, НГМД – с захватом цикла. Достоинством распределенного ПДП является то, что аппаратные затраты для реализации ПДП увеличиваются только при добавлении устройств ввода-вывода.
Процедура ввода-вывода с ПДП:
-
ЦП опрашивает готовность ПУ.
-
ЦП пересылает команду в КПДП.
-
КПДП передает команду в ПУ (это команда управления ПУ).
-
Процедура захвата шины:
-
КПДП выставляет сигнал DMR
-
ЦП предоставляет шину, выставляя DMG
-
КПДП выставляет сигнал SACK (шина занята).
-
КПДП начинает обмен. ЦП работает в соответствии с одним из описанных выше режимов: блочная передача или с захватом цикла шины.
После выполнения любой команды КПДП посылает запрос на прерывание. ЦП опрашивает счетчик количества слов для контроля правильности выполнения передачи. Если обнаруживается сбой, то процедура передачи повторяется с начала и в системе контроля фиксируется количество ошибок (общее и в одном месте). При превышении заданного количества ошибок попытки передачи прекращаются, и генерируется прерывание, сообщающее об ошибке.