

shpory
.docx|
32. Оператор безусловного перехода goto. Оператор безусловного перехода goto имеет следующую форму: goto метка Он переносит выполнение программы к оператору, помеченному меткой метка. Метка представляет собой идентификатор или целое без знака. Чтобы пометить оператор меткой, необходимо перед оператором указать метку с последующим двоеточием: label1: оператор Метки должны быть описаны в разделе меток с использованием служебного слова label: label 1,2,3; Например, в результате выполнения программы label 1,2; begin var i := 5; 2: if i<0 then goto 1; write(i); Dec(i); goto 2; 1: end. будет выведено 543210. Метка должна помечать оператор в том же блоке, в котором описана. Метка не может помечать несколько операторов. Переход на метку может осуществляться либо на оператор в том же блоке, либо на оператор в объемлющей конструкции. Так, запрещается извне цикла переходить на метку внутри цикла. Использование оператора безусловного перехода в программе считается признаком плохого стиля программирования. Для основных вариантов использования goto в язык Паскаль введены специальные процедуры: break - переход на оператор, следующий за циклом, exit - переход за последний оператор процедуры, continue - переход за последний оператор в теле цикла. Единственный пример уместного использования оператора goto в программе - выход из нескольких вложенных циклов одновременно. Например, при поиске элемента k в двумерном массиве: var a: array [1..10,1..10] of integer; ... var found := False; for var i:=1 to 10 do for var j:=1 to 10 do if a[i,j]=k then begin found := True; goto c1; end; c1: writeln(found);
26. Реализация ветвления в ЯП. Оператор условного перехода Оператор условного перехода в Турбо Паскаль имеет вид: if условие then оператор 1 else оператор 2; условие - это логическое выражение, в зависимости от которого выбирается одна из двух альтернативных ветвей алгоритма. Если значение условия истинно (TRUE), то будет выполняться оператор 1, записанный после ключевого слова then. В противном случае будет выполнен оператор 2, следующий за словом else, при этом оператор 1 пропускается. После выполнения указанных операторов программа переходит к выполеннию команды, стоящей непосредственно после оператора if. Необходимо помнить, что перед ключевым словом else точка с запятой никогда не ставится! else - часть в операторе if может отсутствовать: if условие then оператор 1; Тогда в случае невыполнения логического условия управление сразу передается оператору, стоящему в программе после конструкции if. Следует помнить, что синтаксис языка допускает запись только одного оператора после ключевых слов then и else, поэтому группу инструкций обязательно надо объединять в составной оператор (окаймлять операторными скобками begin ... end). В противном случае возникает чаще всего логическая ошибка программы, когда компилятор языка ошибок не выдает, но программа тем не менее работает неправильно.
9. Логический тип Базовый тип данных - данные логического типа. При оформлении условий используется тип данных - логический. Другое название Булевый. Допустимые значения ["истина", "ложь"]. Данные этого типа хранят значения всевозможных условий, пори помощи которых образуются ветвления и циклы (вспомните урок про структуры алгоритмов). Способы представления (хранения).
При работе с логическими данными используются операции: унарная – отрицание. Как выполняются логические операции нетрудно разобраться с помощью таблиц истинности. В этих таблицах 1 соответствует истине, 0 обозначает ложь. отрицание │ A │not A│ ─┼───┼─────┼ │ 0 │ 1 │ │ 1 │ 0 │ Имеются бинарные (с двумя аргументами) операции: not a not a отрицание a and b a and b логическое И a or b a or b логическое ИЛИ a xor b a xor b исключающее ИЛИ Эти операции реализованы и в бейсике, и в паскале. Операции a imp b - импликация (следование) a eqv b - эквивалентность имеются только в бейсике.
Специалисты по математической логике знают, как любую логическую формулу представить в виде набора операций, состоящих из конъюнкций (логическое «И»), дизъюнкций (логическое «ИЛИ») и отрицаний (логическое «НЕ»).
таблицы истинности бинарных операций A │ B │and│ or│xor│eqv│imp ──┼───┼───┼───┼───┼───┼─── 0 │ 0 │ 0 │ 0 │ 0 │ 1 │ 1 0 │ 1 │ 0 │ 1 │ 1 │ 0 │ 1 1 │ 0 │ 0 │ 1 │ 1 │ 0 │ 0 1 │ 1 │ 1 │ 1 │ 0 │ 1 │ 1
BASIC PASCAL not a not a отрицание a and b a and b логическое И a or b a or b логическое ИЛИ a xor b a xor b исключающее ИЛИ a imp b - импликация (следование) a eqv b - эквивалентность Образуются данные логического типа при сравнении данных одинакового типа на совпадение (равны, не равны). Если тип упорядочен, допустимы сравнения: > , >= , < , >= . В языке PASCAL есть функция определения четности числа: odd(x) = true , если аргумент четный, = false , если аргумент нечетный. В языке BASIC можно перемешивать данные числовых и логического типа: функция y=F(x) при x>a =G(x) при x<=a может быть записана y=-F(x)*(x>a)-G(x)*(x<=a).
34. Переменные. Переменная – это область оперативной памяти компьютера, которая может хранить данные во время работы программы. Переменная имеет:Имя (x, text, bm,), значение (число, текст, символ ) ,тип (целый, вещественный, символьный, строковый) Имя переменной (идентификатор): начинается с буквы, содержит буквы (лучше лат) и цифры, длина имени не должна превышать 255 символов, нельзя использовать зарезервированные слова, не должно содержать пробелов и специальных символов. В объектно- ориентированных языках программирования и алгоритмическом языке Basic переменные используются для хранения и обработки данных в программах. Переменные задаются именами, определяющими области оперативной памяти компьютера, в которых хранятся значения переменных. Значениями переменных могут быть данные различных типов (целые или вещественные числа, последовательности символов, логические значения и т. д.). Переменные вводятся в программу для хранения и передачи данных внутри нее. Все переменные, которые предполагается использовать в программе должны, прежде всего, быть определены в разделе описания переменных. Описание переменных начинается со служебного слова VAR, вслед за которым располагается последовательность самих определений переменных. Определение переменной заключается в указании ее имени (идентификатора) и типа. Имя и тип разделяются двоеточием. После объявления и описания переменной должен стоять символ ";". Концом блока описания будет начало какого-либо другого блока программы или описание процедур и функций. Тип переменной определяется типом данных, которые могут быть значениями переменной. Тип переменной Целый тип (Byte, Integer)– для использования целых чисел Вещественный тип (Real)– для использования дробных чисел Символьный тип (Char)– это любые буквы алфавита, символы и цифры 0-9 (один символ). Использование отдельных символов, заключаются в знаки апострофов, например 'а', '4', '+', '-', либо код символа #126 Строковый тип (составной) (String)– для использования наборов символов, заключенных в знаки апострофов, например 'тип', '123' Напомним, что каждый модуль (процедура, функция, программа) состоит из заголовка (procedure…, function…, program…) и блока. Если блок какой-либо процедуры p1 содержит внутри процедуру p2, то говорят, что p2 вложена в p1. Любые идентификаторы, введенные внутри какого-либо блока (процедуры, функции) для описания переменных, констант, типов, процедур, называются локальными для данного блока. Такой блок вместе с вложенными в него модулями называют областью действия этих локальных переменных, констант, типов и процедур. Константы, переменные, типы, описанные в блоке program, называются глобальными. Казалось бы, проще иметь дело вообще только с глобальными переменными, описав их все в program. Но использование локальных переменных позволяет системе лучше оптимизировать программы, делать их более наглядными и уменьшает вероятность появления ошибок.
27. Реализация выбора в ЯП. Оператор выбора Часто возникают ситуации, когда приходится осуществлять выбор одного из нескольких альтернативных путей выполнения программы. Несмотря на то, что такой выбор можно организовать с помощью оператора if .. then, удобнее воспользоваться специальным оператором выбора. Его формат: case выражение of вариант : оператор; ... вариант : оператор; end; или case выражение of вариант : оператор; ... вариант : оператор; else оператор end; выражение, которое записывается после ключевого слова case, называется селектором, оно может быть любого перечисляемого типа. вариант состоит из одной или большего количества констант или диапазонов, разделенных запятыми. Они должны принадлежать к тому же типу, что и селектор, причем недопустимо более одного упоминания вариантав записи инструкции case. Из перечисленного множества операторов будет выбран только тот, перед которым записан вариант, совпадающий со значением селектора. Если такого варианта нет, выполняется оператор, следующий за словом else (если он есть).
|
31. Процедуры и функции пользователя в ЯП. Если в программе возникает необходимость частого обращения к некоторой группе операторов, то рационально сгруппировать такую группу операторов в самостоятельный блок, к которому можно обращаться, указывая его имя. Такие разработанные программистом самостоятельные программные блоки называются подпрограммами пользователя. Они являются основой модульного программирования. Разбивая задачу на части и оформляя логически обособленные модули в виде процедур и функций, программист реализует основные принципы широко используемого в практике системного подхода и методов нисходящего программирования. При вызове подпрограммы (процедуры или функции), определенной программистом, работа главной программы на некоторое время приостанавливается и начинает выполняться вызванная подпрограмма. Она обрабатывает данные, переданные ей из главной программы. По завершении выполнения подпрограмма-функция возвращает главной программе результат (подпрограмма-процедура не возвращает явно результирующего значения). Передача данных из главной программы в подпрограмму и возврат результата выполнения функции осуществляются с помощью параметров. Параметром называется переменная, которой присваивается некоторое значение в рамках указанного применения. Различают формальные параметры – параметры, определенные в заголовке подпрограммы, и фактические параметры – выражения, задающие конкретные значения при обращении к подпрограмме. При обращении к подпрограмме ее формальные параметры замещаются фактическими, переданными из главной программы. Процедуры Описание процедуры включает заголовок (имя) и тело процедуры. Заголовок состоит из зарезервированного слова procedure, идентификатора (имени) процедуры и необязательного, заключенного в круглые скобки, списка формальных параметров с указанием типа каждого параметра. Имя процедуры – идентификатор, уникальный в пределах программы. Тело процедуры представляет собой локальный блок, по структуре аналогичный программе. Описания меток, констант, типов и т.д. действительны только в пределах данной процедуры. В теле процедуры можно использовать любые глобальные константы и переменные. procedure <имя> (Формальные параметры); const ...; type ...; var ...; begin <операторы процедуры> end; Функции Функция, определенная пользователем, состоит из заголовка и тела функции. Заголовок содержит зарезервированное слово function, идентификатор (имя) функции, заключенный в круглые скобки, необязательный список формальных параметров и тип возвращаемого функцией значения. Тело функции представляет собой локальный блок, по структуре аналогичный программе: function <имя> (Формальные параметры) : тип результата; const ...; type ...; var ...; begin <операторы функции> end; В разделе операторов должен присутствовать, по крайней мере, один оператор, присваивающий имени функции значение. В точку вызова возвращается результат последнего такого присваивания. Обращение к функции осуществляется по имени с необязательным указанием списка аргументов. Каждый аргумент должен соответствовать формальным параметрам, указанным в заголовке, и иметь тот же тип. 2)«Алгоритм и его свойства» Понятие алгоритма Из отсутствия четкого определения алгоритма делаем вывод, что алгоритм - неопределяемое понятие и, как и для неопределяемых понятий в других науках, применяется Аксиоматическое построение: выбирается система аксиом, и любые объекты, которые будут удовлетворять этой системе и будут алгоритмами. Такой системой аксиом являются основные свойства алгоритмов. Основные свойства алгоритмов *ДВА СПОСОБА ИСПОЛЬЗОВАНИЯ АЛГОРИТМА - алгоритм можно 1) записать по определенным правилам 2) исполнить В языке BASIC имеются две отдельные команды: LIST – показать текст записи программы, RUN – исполнить программу В других языках для работы с записями алгоритмов используются специальные программы – редакторы, для исполнения – отдельные программы – трансляторы. * НАЛИЧИЕ ИСПОЛНИТЕЛЯ - алгоритм может быть выполнен (это система команд для кого-то или чего-то) Исполнитель может ничего не знать о цели алгоритма. Исполнитель должен понимать отдельные команды. Имеет место формальность исполнения алгоритма, то есть за результат отвечает составитель, а не исполнитель алгоритма. * РЕЗУЛЬТАТИВНОСТЬ - результат при выполнении алгоритма достигается, и за конечное число шагов. * ОДНОЗНАЧНОСТЬ - применение алгоритма к одним и тем же данным дает один и тот же результат. * ДЕТЕРМИНИРОВАННОСТЬ - строгая определенность, однозначность, непротиворечивость правил - не допускается произвола при выборе очередного шага алгоритма, фиксируется начальный и заключительный шаги алгоритма. * МАССОВОСТЬ - алгоритм дает решение не одной, а целого набора задач. * ДВА СПОСОБА ИСПОЛЬЗОВАНИЯ АЛГОРИТМА * НАЛИЧИЕ ИСПОЛНИТЕЛЯ * РЕЗУЛЬТАТИВНОСТЬ * ОДНОЗНАЧНОСТЬ * ДЕТЕРМИНИРОВАННОСТЬ * МАССОВОСТЬ Основы программирования * Программное управление Программа состоит из набора команд, которые выполняются процессором автоматически, последовательно, одна за другой (без вмешательства человека). * Однородность памяти И данные, и команды представляются одинаково. Компьютер не различает, что находится в ячейке памяти: команда, число или текст. * Адресность Основная память состоит из пронумерованных ячеек * Двоичность Информация кодируется двоичным числом. .Оформление программ С развитием компьютерной информатики все более четко выделяются ДАННЫЕ - все объекты, с которыми может работать ЭВМ и КОМАНДЫ - средства, которые при этом используются. Данные, это материалы, определяют, с чем работает компьютер, Команды, это инструменты (операторы, процедуры, функции), определяют, как поступать с данными, а иногда и с самими командами. При работе ЭВМ данные могут менять свои значения. Для обеспечения такой возможности служат ПЕРЕМЕННЫЕ. Переменная - это выделенная для хранения определенной информации область памяти, соответственно имеет адрес начала в памяти и размер. Для удобства использования и отличий между собой переменные снабжаются ИДЕНТИФИКАТОРОМ, проще говоря каждая переменная получает ИМЯ. Информацию, хранящуюся в переменной в момент обращения к этой переменной называют ЗНАЧЕНИЕМ переменной. Занесение значения в память называется операцией присваивания.
6 рекурсия Подпрограммы в Паскале могут обращаться сами к себе. Такое обращение называется рекурсией. Для того чтобы такое обращение не было бесконечным, в тексте подпрограммы должно быть условие, по достижению которого дальнейшее обращение к подпрограмме не происходит. Пример.Рассмотрим математическую головоломку из книги Ж. Арсака «Программирование игр и головоломок». Построим последовательность чисел следующим образом: возьмем целое число i>1. Следующий член последовательности равен i/2, если i четное, и 3 i+1, если i нечетное. Если i=1, то последовательность останавливается. Математически конечность последовательности независимо от начального i не доказана, но на практике последовательность останавливается всегда. Применение рекурсии позволило решить задачу без использования циклов, как в основной программе, так и в процедуре. Пример программы с использованием рекурсии Program Arsac; Var first: word; Procedure posledov (i: word); Begin Writeln (i); If i=1 then exit; If odd(i) then posledov(3*i+1) else posledov(i div 2); End; Begin Write (‘ введите первое значение ’); readln (first); Posledov (first); Readln ; End. Виды рекурсий 1. Простая а) Хвостовая рекурсия — специальный случай рекурсии, при котором рекурсивный вызов функцией самой себя является её последней операцией. б) Если в процедуре рекурсивный вызов не является завершающей инструкцией, то такая рекурсия называется вложенной. 2. Сложная или косвенная :Функция A вызывает функцию B, а функция B — функцию A. Рекурсия и цикл Что такое цикл? Цикл – разновидность управляющей конструкции. Управляет она, очевидно, выполнением кода (как например, конструкция if (условие) [then] оператор, где оператор выполняется, только если условие истинно). Цикл состоит из двух частей: условия и тела цикла. Циклы, как и многое другое, можно классифицировать по разным признакам. В частности, существуют циклы с предусловием и постусловием, безусловные, вложенные и т.д. Простейшим из них является цикл с предусловием, т.к. в нем тело цикла (тело цикла – это набор операторов) выполняется только в случае истинности условия. На псевдокоде цикл с предусловием обычно обозначается так: while (условие) do{оператор1; оператор2; … } Здесь в круглых скобках записано условие цикла, а в фигурных – тело цикла. Например, так можно распечатать все числа от nдо 1: while (n > 0) do{// на каждом шаге цикла проверяем, не стало ли n <= 0, т.е. не выполнилось ли условие выхода из цикла print(n);// печатаем текущее значение n n = n — 1;// уменьшаем значение n, чтобы оно в конце концов стало меньше 0 и мы вышли из цикла } Этот фрагмент кода делает следующее: на каждом шаге цикла сначала проверяется условие, что n > 0, т.к. если оно не выполнено, нам будет необходимо прекратить выполнение дальнейших действий, связанных с поставленной задачей. Если условие оказалось ложно, т.е. n уже меньше либо равно нулю, тело цикла не выполняется и работа этого кода заканчивается. Если же оно окажется истинно, и n все еще больше нуля, т.е. его можно печатать, то выполняется тело цикла: n печатается и уменьшается на единицу, чтобы перейти к следующему значению n. Затем снова выполняет проверка условия, т.е. делается следующий шаг цикла. При чем здесь рекурсия? выполнение нового шага цикла – это выполнение точно такой же операции, как та, что выполнялась только что. Т.е. как будто в конце каждого шага цикл снова вызывает выполнение самого себя. Реализация этой операции в виде рекурсивной функции может иметь следующий вид: dec_print(n) {if (n > 0) then { // проверка условия, как в циклеprint(n); // печать очередного значения n dec_print(n-1); // вызов функции от следующего значения n } } На каждом шаге рекурсии проверяется условие n > 0. Если оно не выполнится, ничего больше происходить не будет, т.к. нет ветки else, точно так же, как и в цикле. Если же оно истинно, будут выполнены операторы во вторых фигурных скобках: сначала напечатано очередное значение n, а потом вызвана та же функция от уменьшенного значения n – последнее равносильно выполнению оператора n = n — 1; в цикле и переходу к следующему шагу. Этот вызов функции снова запустит выполнение аналогичных действий: сначала проверка истинности условия, а затем выполнение действий в зависимости от результатов проверки. Заметим, все ровно так же, как и в цикле, только записано иначе, но все равно очень похоже. Теперь попробуем задать такое преобразование в общем виде. Цикл с предусловием, как сказано выше, имеет следующий вид: while (условие) do{оператор1; оператор2; … } Его можно заменить такой рекурсивной функцией: cycle(...) { // параметры зависят от того, что происходит в циклеif (условие) then {// проверка такого же условия, как в циклеоператор1; // операторы из тела циклаоператор2; … cycle(...); // рекурсивный вызов функции } } При этом рекурсивный вызов функции происходит с уже другими значениями параметров, чтобы выполнение когда-нибудь завершилось, т.е. выполнилось условие выхода из рекурсии. 30.Реализация
цикла с параметром в ЯП
Цикл – это многократно
повторяющиеся фрагменты программ. Алгоритм
циклической структуры – это
алгоритм, содержащий циклы. В ТР
существует три оператора цикла:цикл
с предусловием, цикл с постусловием,
цикл с параметром. Для всех циклов
характерны следующие особенности:значения
переменных используемых в цикле, и не
изменяющиеся в нем д.б. определены до
входа в цикл;вход в цикл возможен
только через его начало;выход их цикла
осуществляется как в результате его
естественного окончания, так и с
помощью операторов перехода.
Оператор цикла с параметром
реализует следующую базовую
конструкцию:
Формат записи: 1. For P:=Pn to Pk do OP; 2. For P:=Pk downto Pn do OP; где: For - для;to – до;downto – уменьшая до;do – выполнить;OP – тело цикла; оператор (простой или составной); P - параметр цикла, переменная порядкового типа; Pn, Pk – начальное и конечное значение параметра. Работа оператора: Вычисляется начальное значение параметра цикла Pn и присваивается параметру P. Проверяется условие P?Pk, и если оно Trueвыполняются операторы тела цикла OP . После чего наращивается значение P на единицу и опять проверяется условие P?Pk . Если условие False осуществляется выход из цикла. В операторе с downto шаг изменения параметра цикла равен –1. Примеры записи: For i:=1 to n do n:=sqr(i)+1; For s:=’A’ to ‘Z’ do R:=R+ord(s)/127; For L:=False to True do H:= (False or L) And Not (L); Пример. Составить программу вычисления функции y для заданного значения n.
Program Ex_3; Uses crt; Var y, C, a, t :real; n :integer; Begin clrscr; Writeln('Введите C, a, t'); Read(C, a, n); Writeln('Результат:'); Writeln(‘n’:5,’y’:15); For n:=1 to 10 do Begin y:=C*exp(a*t)*cos(n*t); Writeln(n:4,’ ‘:5, y:10); end; End. 12)Строковый (литерный).
К базовым, с некоторой натяжкой, можно отнести тип данных «строка». Способ хранения и набор операций со строками компьютеру известны, но, фактически, строка – это упорядоченный набор знаков. По умолчанию, для хранения строки выделено 256 байт, но при желании можно длину строк уменьшить, память сэкономить. Из-за возможности доопределения, некоторые авторы учебников строковый тип данных к базовым не относят. Вместе со знаками в памяти хранится длина строки, чтобы выводить не все 256 знаков. В языке pascal для хранения длины строки используется элемент набора с номером 0. В этот байт записывается число от 0 до 255. В языке basic длина строки хранится отдельно, вместе с именем, поэтому можно использовать строки длиной 256 знаков. Тип строка в языке pascal отмечается словом string, в языке basic, после имени переменной пишут знак доллара ’$’, в некоторых версиях вместо знака доллара используется знак «солнышко» - круг поверх косого креста.
0 1 2 3 4 5 6 ... 255 б у к в ы код 5 код б код у код к код в код ы
Первый знак строки занимает 1 байт, второй – второй, ... Нулевой байт хранит длину строки. pascal basic var s:string; s$=”буквы” begin s:=’буквы’; end. (s¤=”буквы”) К операциям преобразования строк относим: Выделение части строки (с указанного места указанной длины). Конкатенация, соединение (склейка) двух строк в одну. (Часто операция обозначается знаком ‘+’ между аргументами.) Удаление части строки. Вставка одной строки внутрь другой. Не реализованные в некотором языке операции вполне заменимы набором имеющихся. Например, удалить часть строки можно путем склейки кусочка слева и кусочка справа. Средняя часть будет потеряна.
BASIC PASCAL выполняем вырезку из строки =mid$(s$,m,l) =copy(s,m,l) =left$(s,l) =right$(s,l) склеиваем две строки =s1$+s2$ =concat(s1,s2) удаляем часть строки delete(s,m,l) вставляем строку в строку insert(p,s,m) замена фрагмента строки mid$(a$,m,x)= О строке можно извлечь информацию: Число – длину строки. Номер места, начиная с которого одна строка находится внутри другой (поиск подстроки в строке). Имеются просто команды преобразования числа в строку цифр и, обратно, строки цифр в число.
BASIC PASCAL определяем длину строки =len(s$) =length(s) ищем подстроку в строке =instr(s$,p$) =pos(p,s) преобразуем число в строку =str$(x) str(n,s) =bin$(x) =oct$(x) =hex$(s) преобразуем строку в число =val(x$) val(s,n,c)
15. Указатели. Выделение и возвращение памяти. ДИНАМИЧЕСКАЯ ПАМЯТЬ Динамическая память -- это оперативная память ПК, предоставляемая программе при ее работе, за вычетом сегмента данных (64 Кбайт), стека (обычно 16 Кбайт) и собственно тела программы. Размер динамической памяти можно варьировать в широких пределах. По умолчанию этот размер определяется всей доступной памятью ПК и, как правило, составляет не менее 200...300 Кбайт. АДРЕСА И УКАЗАТЕЛИ Оперативная память ПК представляет собой совокупность элементарных ячеек для хранения информации -- байтов, каждый из которых имеет собственный номер. Эти номера называются адресами, они позволяют обращаться к любому байту памяти. .Указатель -- это переменная, которая в качестве своего значения содержит адрес байта памяти. В ПК адреса задаются совокупностью двух шестнадцатиразрядных слов, которые называются сегментом и смещением. Сегмент -- это участок памяти, имеющий длину 65536 байт (64 Кбайт) и начинающийся с физического адреса, кратного 16 (т.е. 0, 16, 32, 48 и т.д.). Смещение указывает, сколько байт от начала сегмента необходимо пропустить, чтобы обратиться к нужному адресу. Адресное пространство ПК составляет 1 Мбайт (речь идет о так называемой стандартной памяти ПК; на современных компьютерах с процессорами 80386 и выше адресное пространство составляет 4 Гбайт, однако в Турбо Паскале нет средств, поддерживающих работу с дополнительной памятью; при использовании среды Borland Pascal with Objects 7.0 такая возможность имеется). Для адресации в пределах 1 Мбайта нужно 20 двоичных разрядов, которые получаются из двух шестнадцатиразрядных слов (сегмента и смещения) следующим образом: содержимое сегмента смещается влево на 4 разряда, освободившиеся правые разряды заполняются нулями, результат складывается с содержимым смещения.
Расположение кучи в памяти ПК Память под любую динамически размещаемую переменную выделяется процедурой NEW. Параметром обращения к этой процедуре является типизированный указатель. В результате обращения указатель приобретает значение, соответствующее динамическому адресу, начиная с которого можно разместить данные, например: var i, j: ^integer; r: ^real; begin New(i); . . . . . end. После выполнения этого фрагмента указатель i приобретет значение, которое перед этим имел указатель кучи HEAPPTR, а сам HEAPPTR увеличит свое значение на 2, так как длина внутреннего представления типа INTEGER, с которым связан указатель i, составляет 2 байта (на самом деле это не совсем так: память под любую переменную выделяется порциями, кратными 8 байтам). Оператор new(r);вызовет еще раз смещение указателя HEAPPTR, но теперь уже на 6 байт, потому что такова длина внутреннего представления типа REAL. Аналогичным образом выделяется память и для переменной любого другого типа. После того как указатель приобрел некоторое значение, т.е. стал указывать на конкретный физический байт памяти, по этому адресу можно разместить любое значение соответствующего типа. Для этого сразу за указателем без каких-либо пробелов ставится значок ^, например: i^ := 2; {В область памяти i помещено значение 2} r^ := 2*pi; {В область памяти r помещено значение 6.28} Таким образом, значение, на которое указывает указатель, т.е. собственно данные, размещенные в куче, обозначаются значком ^, который ставится сразу за указателем. Если за указателем нет значка ^, то имеется виду адрес, по которому размещены данные. Имеет смысл еще раз задуматься над только что сказанным: значением любого указателя является адрес, а чтобы указать, что речь идет не об адресе, а о тех данных, которые размещены по этому адресу, за указателем ставится ^. Если Вы четко уясните себе это, у Вас не будет проблем при работе с динамической памятью. Динамически размещенные данные можно использовать в любом месте программы, где это допустимо для констант и переменных соответствующего типа, например: r^ := sqr(r^) + i^ - 17; Разумеется, совершенно недопустим оператор r := sqr(r^) + i^ - 17; так как указателю R нельзя присвоить значение вещественного выражения. Точно так же недопустим оператор r^ := sqr(r); поскольку значением указателя R является адрес, и его (в отличие от того значения, которое размещено по этому адресу) нельзя возводить в квадрат. Ошибочным будет и такое присваивание: r^ := i; так как вещественным данным, на которые указывает R, нельзя присвоить значение указателя (адрес). Динамическую память можно не только забирать из кучи, но и возвращать обратно. Для этого используется процедура DISPOSE. Например, операторы dispose(r); dispose(i); вернут в кучу 8 байт, которые ранее были выделены указателям I и R. Отметим, что процедура DISPOSE(PTR) не изменяет значения указателя PTR, а лишь возвращает в кучу память, ранее связанную с этим указателем. Однако повторное применение процедуры к свободному указателю приведет к возникновению ошибки периода исполнения. Освободившийся указатель программист может пометить зарезервированным словом NIL. Помечен ли какой-либо указатель или нет, можно проверить следующим образом: const р: ^real = NIL; begin . . . . . if р = NIL then new(p); . . . . . dispose(p); p := NIL; . . . . . end. Никакие другие операции сравнения над указателями не разрешены. Приведенный выше фрагмент иллюстрирует предпочтительный способ объявления указателя в виде типизированной константы с одновременным присвоением ему значения NIL. Следует учесть, что начальное значение указателя (при его объявлении в разделе переменных) может быть произвольным. Использование указателей, которым не присвоено значение процедурой NEW или другим способом, не контролируется системой и может привести к непредсказуемым результатам. Чередование обращений к процедурам NEW и DISPOSE обычно приводит к ╚ячеистой╩ структуре памяти. Дело в том, что все операции с ней выполняются под управлением особой подпрограммы, которая называется администратором кучи. Она автоматически пристыковывается к нашей программе компоновщиком Турбо Паскаля и ведет учет всех сводных фрагментов в куче. При очередном обращении к процедуре NEW эта подпрограмма отыскивает наименьший свободный фрагмент, в котором еще может разместиться требуемая переменная. Адрес начала найденного фрагмента возвращается в указателе, а сам фрагмент или его часть нужной длины помечается как занятая часть кучи. Другая возможность состоит в освобождении целого фрагмента кучи. С этой целью перед началом выделения динамической памяти текущее значение указателя HEAPPTR запоминается в переменной-указателе с ющью процедуры MARK. Теперь можно в любой момент освободить фрагмент кучи, начиная от того адреса, который запомнила процедура MARК, и до конца динамической памяти. Для этого используется процедура RELEASE. Например: var p,p1,p2,р3,р4,р5: ^integer; begin new(p1); new(p2); mark(p); new(p3); new(p4); new(p5); . . . . . release(p); end. В этом примере процедурой MARK(P) в указатель Р было помещено тукущее значение HEAPPTR, однако память под переменную не резервировалась. Обращение RELEASE(P) освободило динамическую память от помеченного места до конца кучи. Пирведенный ниже рисунок иллюстрирует механизм работы процедур NEW-DISPOSE и NEW-MARK-RELEASE для рассмотренного примера и для случая, когда вмемто оператора RELEASE(P) используется, например, DISPOSE(P3).
Состояние динамической памяти: а) перед освобождением; б) после Dispose(p3); в) после Release(p)Следует учесть, что вызов RELEASE уничтожает список свободных фрагментов в куче, созданных до этого процедурой DISPOSE, поэтому совместное использование обоих механизмов освобождения памяти в рамках одной программы не рекомендуется. 22. язык программирования алфавит, синтаксис ,лексема, семантика.Комментарии , пространство имен,ключевые слова. Основными элементами любого языка программирования являются его алфавит, синтаксис и семантика. Алфавит – совокупность символов, отображаемых на устройствах печати и экранах и/или вводимых с клавиатуры терминала. Лексика – совокупность правил образования цепочек символов (лексем), образующих идентификаторы (переменные и метки), операторы, операции и другие лексические компоненты языка. Сюда же включаются зарезервированные (запрещенные, ключевые) слова языка программирования, предназначенные для обозначения операторов, встроенных функций и пр. Иногда эквивалентные лексемы, в зависимости от языка программирования, могут обозначаться как одним символом алфавита, так и несколькими. Например, операция присваивания значения в языке Си обозначается как «=», а в языке Паскаль – «:=». Операторные скобки в языке Си задаются символами «{» и «}», а в языке Паскаль – begin и end. Граница между лексикой и алфавитом, таким образом, является весьма условной, тем более что компилятор обычно на фазе лексического анализа заменяет распознанные ключевые слова внутренним кодом (например, begin – 512, end – 513) и в дальнейшем рассматривает их как отдельные символы. Синтаксис – совокупность правил образования языковых конструкций, или предложений языка программирования – блоков, процедур, составных операторов, условных операторов, операторов цикла и пр. Особенностью синтаксиса является принцип вложенности (рекурсивность) правил построения конструкций. Это значит, что элемент синтаксиса языка в своем определении прямо или косвенно в одной из его частей содержит сам себя. Например, в определении оператора цикла телом цикла является оператор, частным случаем которого является все тот же оператор цикла.Необходимо строгое соблюдение правил правописания (синтаксиса) программы. В частности, в Паскале однозначно определено назначение знаков пунктуации. Точка с запятой (;) ставится в конце заголовка программы, в конце раздела описания переменных, после каждого оператора. Перед словом End точку с запятой можно не ставить. Запятая (,) является разделителем элементов во всевозможных списках: списке переменных в разделе описания, списке вводимых и выводимых величин.В БНФ(формула Бекуса – Наура) всякое синтаксическое понятие описывается в виде формулы, состоящей из правой и левой части, соединенных знаком ::=, смысл которого эквивалентен словам «по определению есть». Слева от знака ::= записывается имя определяемого понятия (метапеременная), которое заключается в угловые скобки <>, а в правой части записывается формула или диаграмма, определяющая все множество значений, которые может принимать метапеременная. Синтаксис языка описывается путем последовательного усложнения понятий: сначала определяются простейшие (базовые), затем все более сложные, включающие в себя предыдущие понятия в качестве составляющих. В записях метаформул приняты определенные соглашения. Например, формула БНФ, определяющая понятие «двоичная цифра», выглядит следующим образом: <двоичная цифра>::=0|1 Значок «|» эквивалентен слову «или».В диаграммах стрелки указывают на последовательность расположения элементов синтаксической конструкции; кружками обводятся символы, присутствующие в конструкции.Понятие «двоичный код» как непустую последовательность двоичных цифр БНФ описывает так:<двоичный код>::=<двоичная цифра>|<двоичныйкод><двоичная цифра>Определение, в котором некоторое понятие определяется само через себя, называется рекурсивным. Рекурсивные определения характерны для БНФ.Возвратная стрелка обозначает возможность многократного повторения. Очевидно, что диаграмма более наглядна, чем БНФ.Синтаксические диаграммы были введены Н. Виртом и использованы для описания созданного им языка Паскаль.Семантика – смысловое содержание конструкций, предложений языка, семантический анализ – это проверка смысловой правильности конструкции. Например, если мы в выражении используем переменную, то она должна быть определена ранее по тексту программы, а из этого определения может быть получен ее тип. Исходя из типа переменной, можно говорить о допустимости операции с данной переменной. Семантические ошибки возникают при недопустимом использовании операций, массивов, функций, операторов и пр. Пространство имён — некоторое множество, под которым подразумевается модель, абстрактное хранилище или окружение, созданное для логической группировки уникальных идентификаторов (то есть имён). Идентификатор, определенный в пространстве имён, ассоциируется с этим пространством. Один и тот же идентификатор может быть независимо определён в нескольких пространствах. Таким образом, значение, связанное с идентификатором, определённым в одном пространстве имён, может иметь (или не иметь) такое же значение, как и такой же идентификатор, определённый в другом пространстве. Языки с поддержкой пространств имён определяют правила, указывающие, к какому пространству имён принадлежит идентификатор (то есть его определение). Например, Андрей работает в компании X, а ID (сокр. от англ. Identifier — идентификатор) его как работника равен 123. Олег работает в компании Y, а его ID также равен 123. Единственное (с точки зрения некой системы учёта), благодаря чему Андрей и Олег могут быть различимы при совпадающих ID, это их принадлежность к разным компаниям. Различие компаний в этом случае представляет собой систему различных пространств имён (одна компания — одно пространство). Наличие двух работников в компании с одинаковыми ID представляет большие проблемы при их использовании, например, по платёжному чеку, в котором будет указан работник с ID 123, будет весьма затруднительно определить работника, которому этот чек предназначается. В больших базах данных могут существовать сотни и тысячи идентификаторов. Пространства имён (или схожие структуры) реализуют механизм для сокрытия локальных идентификаторов. Их смысл заключается в группировке логически связанных идентификаторов в соответствующих пространствах имён, таким образом делая систему модульной. Ограничение видимости переменных может также производиться путём задания класса её памяти. Операционные системы, многие современные языки программирования обеспечивают поддержку своей модели пространств имён: используют каталоги (или папки) как модель пространства имён. Это позволяет существовать двум файлам с одинаковыми именами (пока они находятся в разных каталогах). В некоторых языках программирования (например, C++, Python) идентификаторы имён пространств сами ассоциированы с соответствующими пространствами. Поэтому в этих языках пространства имён могут вкладываться друг в друга, формируя дерево пространств имён. Корень такого дерева называется глобальным пространством имён.
|
4)Линейный алгоритм Изучение алгоритмических конструкций начнем с линейного алгоритма. В учебниках иногда используется термин «следование». Алгоритм назовем линейным, если:1) выполняется каждый его шаг, и 2) только один раз. Такого определения вполне достаточно. В некоторых учебниках используются слова «шаги выполняются последовательно, друг за другом», но эти слова означают наличие некоторого порядка. А порядков имеется два! Одним из свойств алгоритма является, что его можно использовать двояко: либо исполнить, либо записать по определенным правилам. Таким образом первый порядок – порядок исполнения команд, второй – порядок написания. Эти порядки могут не совпадать.
На рисунке слева – случай, когда порядок написания и порядок исполнения совпадают, справа – эти порядки различны. Может показаться, что на рисунке справа алгоритм не линеен, так как команды выполняются не «друг за другом», а сначала вторая, потом первая. Но если определить линейный алгоритм как указано выше - Алгоритм линейный, если выполняется каждый его шаг, и только один раз – то эта проблема снимается. Линеен алгоритм обмена, алгоритмы деления угла или отрезка пополам и многие другие. Ветвление неполное Вернемся к нашему определению линейного алгоритма и попытаемся определить остальные алгоритмические структуры. Для начала, откажемся от требования 1), обязательности выполнения каждого шага алгоритма. Имеем алгоритм, в котором некоторые шаги могут не выполняться. Получившаяся структура алгоритма называется. НЕПОЛНОЕ ВЕТВЛЕНИЕ Согласно принципу детерминированности алгоритмов, исполнитель должен знать, выполнять отмеченный шаг или нет. Приходится ввести понятие «условие», то есть предложение, значение которого либо «истина», либо «ложь». Если условие истинно – шаг алгоритма выполняется, иначе – нет. Всевозможные условия являются объектом работы, то есть ДАННЫМИ, которые могут иметь либо значение истина, либо значение ложь. Образуются эти значения при сравнении двух переменных или выражений одного типа. A=B;A<>B;X<>5;A>5;B<3;C<=A+B Значения этих выражений «истинно» (true) или «ложно» (false) зависит от значений используемых переменных. На языке блок-схем блок ветвления обозначается ромбом, имеет один вход и два выхода. Однако любой алгоритм должен обладать свойством результативности, то есть у него должен быть конец и только один. Обе ветви, для достижения конца соединяются, место соединения называется УЗЕЛ и на блок-схеме отмечается кружком. Наличие двух выходов так же представляет собой проблему. Выходы должны быть разными. Поэтому они маркируются словами «да» и «нет» или знаками «+» и «-». Согласно первому выходу алгоритм продолжаем при истинности условия, которое вписывается в ромб, иначе – продолжаем согласно второму выходу. Лентяи просто ставят около выхода «да» точку. Этого достаточно для однозначного определения дальнейших шагов алгоритма.
Цикл Ветвление - один из случаев нарушения линейности алгоритма.
Как уже отмечалось, на блок-схеме ветвление обозначается ромбом, внутри которого указывается условие. Блок ветвления имеет один вход и два выхода. Обе ветви, для достижения конца соединяются в узле.
Однако ветви могут соединиться и перед блоком условия! Возможна ситуация, когда команды блока выполняются несколько раз подряд. Алгоритм тоже нелинейный. Такая организация алгоритма называется ЦИКЛ. Шаги, которые могут выполняться несколько раз подряд образуют ТЕЛО цикла. Выполнять или нет тело еще раз решает УСЛОВИЕ цикла. Итак, любой цикл имеет ТЕЛО и УСЛОВИЕ ВЫХОДА. Снова вспоминаем свойство алгоритма, что его можно исполнить и его можно записать. Две составных части цикла – тело и условие – можно записать по разному: либо сначала условие, потом тело, либо сначала тело, потом условие. В первом случае цикл называется циклом типа «пока», во втором – циклом типа «до». Так выглядит оформление цикла с предусловием (цикла «пока») в разных языках программирования.
А так выглядит оформление цикла с постусловием (цикла «до») в языках программирования.
Основным различием циклов ДО и ПОКА является то, что в цикле ДО тело цикла один раз выполняется обязательно, а в цикле ПОКА возможна ситуация, когда тело цикла не выполнится ни разу.Изменив условие, для цикла ПОКА можно добиться выполнения цикла один (первый) раз, цикл будет работать как и цикл ДО.Запретить выполнение первого раза тела цикла типа ДО невозможно.Так как из цикла ПОКА можно получить цикл ДО, цикл ПОКА является более универсальным. Попытки определить тип цикла по семантическому значению слов «до» и «пока» в русском языке обречены на неудачу. Фразы: Тело цикла выполняется до тех пор ПОКА позволяет условие И Тело цикла выполняется ДО тех пор пока позволяет условие Различаются только акцентом. Как видим, задача может быть решена как использованием цикла «пока», так и использованием цикла «до». Довольно часто выбор типа цикла несущественен. Но встречаются случаи, когда только одна из этих разновидностей цикла наилучшим образом подходит к конкретной задаче. Например, если вы собираетесь удалить пробелы, стоящие в начале строки, то, скорее всего, выберете цикл с предусловием, потому что надо сначала убедиться, что пробел имеется, и только затем его удалять (глупо поступать наоборот - сначала удалять, а потом проверять, стоило ли это делать). Зато ввод текста до точки трудно построить иначе как с постусловием, поскольку сначала требуется ввести очередной символ и только потом сравнивать его с точкой. Для цикла ПОКА принято организовывать выход при значении условия "ложно", а для цикла ДО принято организовывать выход при значении условия "истина". Это следует знать, если вы работаете, скажем, на паскале. Однако, Вы можете разработать свой язык программирования, где все будет наоборот. Требование придерживаться этих условий при работе с блок-схемами мне кажется неправильным. При некорректной организации некоторых циклов может возникнуть эффект так называемого "зацикливания", когда действия внутри цикла не могут создать условия, требующиеся для его завершения. Следует всячески избегать подобных ситуаций путем тщательного анализа условий работы цикла. 7. Понятие выражения, операции, операнда. При выполнении программы осуществляется обработка данных, в ходе которой с помощью выражений вычисляются и используются различные значения. Выражение представляет собой конструкцию, определяющую состав данных, операции и порядок выполнения операций над данными. Выражение состоит из операндов, знаков операций и круглых скобок. В простейшем случае выражение может состоять из одной переменной или константы. Тип значения выражения определяется типом операндов и составом выполняемых операций. Операнды представляют собой данные, над которыми выполняются действия. В качестве операндов могут использоваться константы, переменные, элементы массивов и функции. Операции – это действия, которые выполняются над операндами. Операции бываю унарными и бинарными. Унарная операция относится к одному операнду, и ее знак записывается перед операндом, например, - x. Бинарная операция выражает отношение между двумя операндами, и знак ее записывается между операндами, например, x + y. Круглые скобки используются для указания порядка выполнения операций. Если в операциях используется несколько данных, то их типы должны быть либо идентичными, либо совместимыми.В зависимости от типов операций и операндов выражения могут быть арифметическими, логическими и строковыми. Арифметические выражения (АВ). Результатом выполнения АВ является число, тип которого зависит от типов операндов, составляющих это выражение. В АВ можно использовать числовые типы (целочисленные и вещественные), арифметические операции и функции, возвращающие числовое значение. Тип значения АВ определяется типом операндов и операциями. Если в операции участвуют целочисленные операнды, то результат операции также будет целочисленного типа. Если хотя бы один из операндов принадлежит к вещественному типу, то результат также будет вещественным. Исключением является операция деления, результат которой всегда вещественный. Унарные арифметические операции + (Сохранение знака) и –(Отрицание знака) относятся к знаку числа и не меняют типа числа.Примеры. Пусть в программе есть строки: var a, b, c, d: integer; x, y: real; . . . a:=40; b:=13 ; c:= a div b; d:= a mod b; //c=3, d=1 y:=sin(a) + b/exp(x) - 12.5; // y=sin a + b/ e x – 12,5 Над данными целочисленного типа можно выполнять также следующие побитовые (поразрядные) операции: o Shl– сдвиг влево; o Shr– сдвиг вправо; o And– И (арифметическое умножение); o Or– ИЛИ (арифметическое сложение);o Xor– арифметическое исключающее ИЛИ; o Not– Не (арифметическое отрицание). Особенностью побитовых операций является то, что они выполняются над операндами поразрядно. Примеры. Пусть в программе есть строки: var a, b, c, d: integer; . . . a:=5; b:=9 ; c:= Not a; // a= 0101, Not (0101) = 1010 =10 дес . d:= a And b; // b=1001, 0101 And 1001 = 0001 = 1 дес . Логические выражения (ЛВ). Результатом выполнения ЛВ является логическое значение Trueили False. Такие выражения чаще всего используются в условных операторах и операторах цикла. Логические выражения могут содержать: o логические константы Trueи False; o логические переменные типа Boolean; o операции сравнения (отношения); o логические операции; o круглые скобки. Для установления отношения между двумя значениями, заданными выражениями, переменными или константами, используются следующие операции сравнения: =,<,>, <=,>=,<>. Операции сравнения выполняются после вычисления соответствующих выражений. Результатом операции сравнения является значение False, если соответствующее отношение не имеет место, и значениеTrueв противном случае. Результат выполнения логических операций при применении их к логическим выражениям (операндам логического типа) будет логического типа (Boolean). Логические операции And, Or, Xor являются бинарными, операция Not– унарной.
11. Числовые типы. Операции. Выражения. 1 Базовый тип данных - действительное число Число представляется в нормальной нормированной форме, то есть разбивается на мантиссу - число в диапазоне от 0.1 до 1.0 и порядок. Диапазон значений зависит от записи (двоичная или двоично-десятичная), от размеров выделенных мест для хранения мантиссы и порядка. 2 Способы представления (хранения). Несколько байт двоичной или двоично-десятичной записи. Число представляется в нормальной форме, то есть разбивается на мантиссу - число в диапазоне от 0.1 до 1.0 и порядок. Диапазон значений зависит от записи (двоичная или двоично-десятичная), от размеров выделенных мест для хранения мантиссы и порядка. 4 Основные операции. BASIC PASCAL Как получить сложение a и b a+b a+b вычитание a и b a-b a-b умножение a на b a*b a*b деление a на b a/b a/b возведение a в степень b a^b функции возведение x в квадрат sqr(x) квадратный корень из x sqr(x) sqrt(x) экспонента от x exp(x) exp(x) 10 в степени x - exp10(x) логарифм натуральный от x log(x) ln(x) |log (x)= ln(x)/ln(a) логарифм десятичный от x - log(x) | a синус от x sin(x) sin(x) косинус от x cos(x) cos(x) тангенс от x tan(x) - | =sin(x)/cos(x) котангенс от x - - | =1/tg(x) _____ арксинус от x - - | =arctg(x/V1-x*x) арккосинус от x - - | =pi-arcsin(x) арктангенс от x atn(x) arctan(x) арккотангенс от x - | =pi/2+arctg(x) [x] - целая часть от x int(x) trunc(x) округление до целого x - round(x) | =[x+0.5] {x} - дробная часть от x - - | =x-[x] взятие модуля x abs(x) abs(x)
5 Связь с данными других типов. В операциях среди аргументов допустимы данные целого типа, автоматически произойдет их преобразование в данные действительного типа.При округлении результат будет целого типа.
33. Общая схема структуры программы в ЯП. Общая структура программы на языке Pascal имеет вид Program Имя программы; Uses Подключаемые библиотеки (модули); Label Список меток основной программы; Const Введение констант; Type Описание новых типов; Var Описание переменных и их типов; Определение процедур; Определение функций; Begin Тело основной программы; End. В языке программирования Паскаль программа состоит из заголовка, раздела описаний и исполняемой части. Служебные слова Pascal, обозначающие начало определенного блока программы, выделены жирным белым шрифтом. Program – блок описания заголовка программы в Паскале имеет декоративное значение и может отсутствовать. Uses – в Паскале вспомогательные готовые программы собранные в библиотеки (модули). Например, процедуры рисования точек, линий, окружностей на экране содержатся в модуле graph. Модули объявляются в этом блоке. Если подключать дополнительные библиотеки не нужно, блок отсутствует. Большинство важнейших ключевых системных библиотек подключаются автоматически (по умолчанию). Label – блок описания меток, содержит их имена перечисленные через запятую. Метки используются для организации переходов в программе. Если метки не нужны, блок отсутствует. Const – блок описания простых и типизированных констант. Может отсутствовать если константы в программе не предусмотрены. Type - блок описания типов данных используемых в программе. Может отсутствовать, если новые типы не вводятся. Var - блок описания переменных с указанием их типа. Может встречаться в программе несколько раз для организации глобальных и локальных переменных (т.е. в основной программе и при описании процедур и функций). Определение процедур и функций – специально оформленные вспомогательные алгоритмы в виде подпрограмм, о которых будем говорить отдельно. Begin - end. – служебные слова, обрамляющие тело основной программы, где находятся исполняемые операторы. Т.о. Begin начинает исполняемую часть программы, а end. (точка в конце обязательна) – ее завершает. Т.о. теоретически в минимально возможном наборе программа может состоять только из пустого тела begin end.
20.Дисциплина программирования, структурный подход программирования. Возникновение объектно –ориентированного программирования. Цели структурного программирования:1)Обеспечение дисциплины программирования (“Структурное программирование-это дисциплина, которую программист навязывает сам себе”- Э. Дейкстра); 2)Повышение эффективности (например, разбиение на относительно независимые модули);3)Повышение надежности (облегчение тестирования и отладки);4)Уменьшение времени и стоимости (повышение производительности программистов); 5)Улучшение читабельности программы Основные принципы структурного подхода:1)Принцип абстракции позволяет рассматривать программу по уровням. Верхний уровень показывает детали реализации (например, восходящее и нисходящие стратегии программирования).2)Разделение программы на отдельные фрагменты (методы), которые просты по управлению и допускают независимую откладку и тестирование 3)Строгий методический подход (принцип формальности) позволяет изучать программы (алгоритмы) как математические объекты, ускорить принятия решений, избежать ошибок Структурный подход включает в себя три основные составные части:1)Нисходящее проектирование;2)Структурное программирование;3)Сквозной структурный контроль. Объе́ктно-ориенти́рованное программи́рование (ООП) — парадигма программирования, в которой основными концепциями являются понятия объектов и классов (либо, в менее известном варианте языков с прототипированием — прототипов). Класс — это тип, описывающий устройство объектов — экземпляров. Класс можно сравнить с чертежом, согласно которому создаются объекты. Обычно классы разрабатывают таким образом, чтобы их объекты соответствовали объектам предметной области.Прототип — это образцовый объект, по образу и подобию которого создаются другие объекты.Объектное и объектно-ориентированное программирование (ООП) возникло в результате развития идеологии процедурного программирования, где данные и подпрограммы (процедуры, функции) их обработки формально не связаны. Кроме того, в современном объектно-ориентированном программировании часто большое значение имеют понятия события (так называемое событийно-ориентированное программирование) и компонента (компонентное программирование).Объектно-ориентированное программирование в настоящее время является абсолютным лидером в области прикладного программирования (языки Java, C#, C++, JavaScript, ActionScript и др.). В то же время в области системного программирования до сих пор лидирует парадигма процедурного программирования, и основным языком программирования является язык C. Хотя при взаимодействии системного и прикладного уровней операционных систем заметное влияние стали оказывать языки объектно-ориентированного программирования. Исторически сложилось так, что программирование возникло и развивалось как процедурное программирование, которое предполагает, что основой программы является алгоритм, процедура обработки данных. Объектно-ориентированное программирование - это методика разработки программ, в основе которой лежит понятие объекта как некоторой структуры, описывающей объект реального мира, его поведение. Задача, решаемая с использованием методики объектно-ориентированного программирования, описывается в терминах объектов и операций над ними, а программа при таком подходе представляет собой набор объектов и связей между ними. Другими словами можно сказать, что объектно-ориентированное программирование представляет собой метод программирования, который весьма близко напоминает наше поведение. Оно является естественной эволюцией более ранних нововведений в разработке языков программирования. Объектно-ориентированное программирование является более структурным, чем все предыдущие разработки, касающиеся структурного программирования. Оно также является более модульным и более абстрактным, чем предыдущие попытки абстрагирования данных и переноса деталей программирования на внутренний уровень.
25. Оформление программы в ЯП. Общая структура программы на языке Pascal имеет вид Program Имя программы; Uses Подключаемые библиотеки (модули); Label Список меток основной программы; Const Введение констант; Type Описание новых типов; Var Описание переменных и их типов; Определение процедур; Определение функций; Begin Тело основной программы; End. В языке программирования Паскаль программа состоит из заголовка, раздела описаний и исполняемой части. Служебные слова Pascal, обозначающие начало определенного блока программы, выделены жирным белым шрифтом. Program – блок описания заголовка программы в Паскале имеет декоративное значение и может отсутствовать. Uses – в Паскале вспомогательные готовые программы собранные в библиотеки (модули). Например, процедуры рисования точек, линий, окружностей на экране содержатся в модуле graph. Модули объявляются в этом блоке. Если подключать дополнительные библиотеки не нужно, блок отсутствует. Большинство важнейших ключевых системных библиотек подключаются автоматически (по умолчанию). Label – блок описания меток, содержит их имена перечисленные через запятую. Метки используются для организации переходов в программе. Если метки не нужны, блок отсутствует. Const – блок описания простых и типизированных констант. Может отсутствовать если константы в программе не предусмотрены. Type - блок описания типов данных используемых в программе. Может отсутствовать, если новые типы не вводятся. Var - блок описания переменных с указанием их типа. Может встречаться в программе несколько раз для организации глобальных и локальных переменных (т.е. в основной программе и при описании процедур и функций). Определение процедур и функций – специально оформленные вспомогательные алгоритмы в виде подпрограмм, о которых будем говорить отдельно. Begin - end. – служебные слова, обрамляющие тело основной программы, где находятся исполняемые операторы. Т.о. Begin начинает исполняемую часть программы, а end. (точка в конце обязательна) – ее завершает. Т.о. теоретически в минимально возможном наборе программа может состоять только из пустого тела begin end. Оператор присваивания Основное преобразование данных, выполняемое компьютером, - присвоение переменной нового значения. Общий вид оператора присваивания: Имя_переменной:=арифметическое выражение; При выполнении оператора присваивания рассматривается арифметические выражения, из ячеек оперативной памяти, соответствующих стоящим там именам, вносятся в процессор значения и выполняется указанные действия над данными. Полученный результат записывается в ячейку памяти, имя которой указано слева от знака присваивания. Например:x:=3.14 Переменной х присвоить значение 3.14 . a:=b+c Из ячеек b и c считываются заранее помещенные туда данные, вычисляется сумма, результат записывается в ячейку а , i:=i+1 Значение переменной увеличивается на единицу Для типов переменной слева и арифметического выражения справа от знака присваивания существуют ограничения: 1) если переменная вещественного типа, то арифметическое выражение может быть как целого, так и вещественного типа, т. е. содержать либо целые переменные и допустимые для них операции, либо вещественные, либо и те, и другие (тогда выражение преобразуется к вещественному типу); 2) если переменная слева целого типа, то арифметическое выражение только целочисленное. Это означает, что можно, например, вещественной переменной присвоить целое значение. Операторы языка Pascal 1. Составной и пустой операторы Составной оператор - это последовательность произвольных операторов программы, заключенная в операторные скобки. Begin ... Begin ... Begin ... End; End;End; Наличие ; перед End - пустой оператор. 2. Операторы ветвлений. Условный оператор IF <условие> THEN <оператор1> [ELSE <оператор2>] Условие – значение типа BOOLEAN или логическая операция. Если условие верно, выполняется оператор, или блок операторов, следующий за THEN, в противном случае выполняется блок операторов после ELSE, если он есть. Условия могут быть вложенными и в таком случае, любая встретившаяся часть ELSE соответствует ближайшей к ней "сверху" части THEN. 3. Операторы повторений. Цикл с предопределенным числом повторений. For <переменная цикла>:=<начальное значение> To(DownTo) <конечное значение> Do <блок операторов> Переменная должна быть целого или перечислимого типа. При исполнении цикла переменная цикла изменяется от начального до конечного значения с шагом 1. Если стоит to, то переменная увеличивается, если downto – уменьшается. Условия выполнения цикла проверяются перед выполнением блока операторов. Если условие не выполнено, цикл For не выполняется. Следующая программа подсчитывает сумму чисел от 1 до введенного: Условный цикл с проверкой условия перед исполнением блока операторов. While <условие> Do <блок операторов> Блок операторов будет исполняться, пока условие имеет значение true. Необходимо, чтобы значение условия имело возможность изменения при исполнении блока операторов, иначе исполнение цикла не закончится никогда (в DOS это приведет к зависанию компыютера). Если условие зарание ложно, блок операторов не исполнится ни разу. Оператор выбора одного из вариантов. Case <ключ выбора> Of <список выбора> Else <оператор> End; <ключ выбора> - выражение любого перечислимого типа, <список выбора> - одна или более конструкций вида <значение ключа>:<блок операторов>. Оператор безусловного перехода на строку с меткой. Goto <метка> Метка, должна быть описана в разделе описаний. Метка, описанная в процедуре (функции) локализуется в ней, поэтому передача управления извне процедуры (функции) на метку внутри нее невозможна.
38. Назначение модулей Модуль Паскаля – это автономно компилируемая программная единица, включающая в себя различные компоненты раздела описаний (типы, константы, переменные, процедуры и функции) и, возможно, нкоторые исполняемые операторы инициирующей части. Основным принципом модульного программирования является принцип «разделяй и властвуй». Модульное программирование – это организация программы как совокупности небольших независимых блоков, называемых модулями, структура и поведение которых подчиняются определенным правилам. Модули представляют собой прекрасный инструмент для разработки библиотек прикладных программ и мощное средство модульного программирования. Важная особенность модулей заключается в том, что компилятор размещает их программный код в отдельном сегменте памяти. Длина сегмента не может превышать 64 Кбайт, однако количество одновременно используемых модулей ограничивается лишь доступной памятью, что позволяет создавать большие программы. Структура модулей Паскаля Всякий модуль Паскаля имеет следующую структуру: Unit <имя_модуля>; interface <интерфейсная часть>; implementation < исполняемая часть >; begin <инициирующая часть>; end . Здесь UNIT – зарезервированное слово (единица); начинает заголовок модуля; <имя_модуля> - имя модуля (правильный идентификатор); INTERFACE – зарезервированное слово (интерфейс); начинает интерфейсную часть модуля; IMPLEMENTATION – зарезервированное слово (выполнение); начинает исполняемую часть модуля; BEGIN – зарезервированное слово; начинает инициирующую часть модуля; причем конструкция begin <инициирующая часть> необязательна; END – зарезервированное слово – признак конца модуля. Таким образом, модуль Паскаля состоит из заголовка и трех составных частей, любая из которых может быть пустой. Заголовок модуля Паскаля и связь модулей друг с другом Заголовок модуля Паскаля состоит из зарезервированного слова unit и следующего за ним имени модуля. Для правильной работы среды Турбо Паскаля и возможности подключения средств, облегчающих разработку больших программ, имя модуля Паскаля должно совпадать с именем дискового файла, в который помещается исходный текст модуля. Если, например, имеем заголовок модуля Паскаля Unit primer ; то исходный текст этого модуля должен размещаться на диске в файле primer .pas . Имя модуля Паскаля служит для его связи с другими модулями и основной программой. Эта связь устанавливается специальным предложением: uses<список модулей> Здесь USES – зарезервированное слово (использует); <список модулей> - список модулей, с которыми устанавливается связь; элементы списка – имена модулей через запятую. Если в Паскале модули используются, то предложение uses <список модулей> должно стоять сразу после заголовка программы , т.е. должно открывать раздел описаний основной программы. В модулях Паскаля могут использоваться другие модули. В модулях предложение uses <список модулей> может стоять сразу после слова interface или сразу после слова implementation . Допускается и два предложения uses , т.е. оно может стоять и там, и там.
|
5)Алгоритмические структуры Полное ветвление Поменяв в некотором ветвлении условие на противоположное, получим ветвление, отмеченный шаг которого будет выполняться тогда, когда не выполнялся шаг исходного случая. Сами шаги при этом могут быть различными. Объединение этих двух результатов создает структуру, которая называется полным ветвлением, или альтернативой. При истинности условия выполняется один из имеющихся шагов, при ложности – другой.
Следует отметить, что команда ветвления является "командой над командами". Не смотря на то, что в структуре могут присутствовать две совершенно различные команды, вся конструкция считается одной командой. Находящиеся внутри команды не должны иметь сигнала конца, так как они являются частью одной команды – команды ветвления. В языке программирования Pascal структура ветвления изображается оператором: IF <условие> THEN <команда 1> ELSE <команда 2>; В виде одной команды можно оформить несколько команд. В языке basic, если команда в строку не умещается, она оформляется так же, как в языке dBASE. basic IF <условие> THEN <команда 1> ELSE <команда 2> pascal IF <условие> THEN <команда 1> ELSE <команда 2>; C IF <условие> THEN <команда 1> ELSE <команда 2>; dBASE IF <условие> <команды одной группы> ELSE <команды другой группы> ENDIF Если в тексте программы строка получается очень длинной, то команду ветвления оформляют в несколько строк с отступами Внутри команды ветвления может быть другое ветвление. Выбор Внутри команды ветвления может быть другая команда ветвления. Многократное выполнение ветвлений называют ВЫБОР Особенность структуры выбора состоит в том, что выбор выполняемых операторов здесь осуществляется не в зависимости от истинности или ложности логического выражения, а является вычислимым. Оператор выбора позволяет заменить несколько условных операторов (в силу этого его еще называют оператором множественного ветвления).
Выбор, конечно, можно организовать используя набор полных ветвлений, как это было в программе определения существования треугольника. Но перевод команды полного ветвления с языка программирования высокого уровня на язык кодов процессора приводит к несколько усложненной конструкции. Для указанного в блок-схеме случая можно получить более компактный перевод. Поэтому в языках программирования есть специальная команда, организующая выбор. Запись оператора выбора: basic 100 on k goto 200,300,...,900 Pascal case k of l : команда 1 ; 2 : команда 2 ; ... 99 : команда N ; else команда N+1 end; C switch (k) {case l : команда 1; break; case 2 : команда 2; break; ... case 99 : команда N; break; default: команда N+1;} В алгоритмической структуре "выбор" вычисляется выражение k и выбирается ветвь, значение метки которой совпадает со значением k. После выполнения выбранной ветви происходит выход из конструкции выбора (в C, в отличие от Pascal, такой выход не осуществляется, а продолжают выполняться последующие операторы, поэтому для принудительного завершения оператора выбора применятся оператор break). Если в последовательности нет метки со значением, равным значению выражения k, то управление передается внешнему оператору, следующему за конструкцией выбора - (это происходит в случае отсутствия альтернативы выбора; если она есть, то выполняется следующий за ней оператор, а уже затем управление передается внешнему оператору). 28.Реализация цикла с предусловием в ЯП. Цикл – это многократно повторяющиеся фрагменты программ. Алгоритм циклической структуры – это алгоритм, содержащий циклы. В ТР существует три оператора цикла:цикл с предусловием, цикл с постусловием, цикл с параметром. Для всех циклов характерны следующие особенности:значения переменных используемых в цикле, и не изменяющиеся в нем д.б. определены до входа в цикл;вход в цикл возможен только через его начало;выход их цикла осуществляется как в результате его естественного окончания, так и с помощью операторов перехода. Оператор цикла с предусловием в Паскале. Оператор цикла с предусловием реализует следующую базовую конструкцию: Формат записи: While L do OP; где: While - пока не; do – выполнить; L – выражение логического типа; OP – тело цикла; оператор (простой или составной). Работа оператора: Вычисляется значение логического выражения, если вычисленное значение истинно, то выполняется оператор OP после чего повторяется проверка условия и выполнение операторов тела цикла. В противном случае осуществляется выход из цикла.Вычисление значения логического выражения предшествует выполнению операторов тела цикла, поэтому этот оператор цикла называется циклом с предусловием. Пример . Составить программу вычисления функции y для заданного значения x.
где: C=2,7; n=2; a=0.5; 0<t<1; Dt=0,1. ProgramEx_2; Usescrt; Vary,C, a,t :real; n :integer; Begin clrscr; Writeln('ВведитеC,a, n'); Read(C,a, n); Writeln('Результат:'); Writeln('t’:5,’y’:15); t:=0; Whilet<1do Begin y:=C*exp(a*t)*cos(n*t); Writeln(t:4:1,’‘:5,y:10); t:=t+0.1; End;
29.Реализация цикла с постусловием в ЯМ Цикл – это многократно повторяющиеся фрагменты программ. Алгоритм циклической структуры – это алгоритм, содержащий циклы. В ТР существует три оператора цикла:цикл с предусловием, цикл с постусловием, цикл с параметром. Для всех циклов характерны следующие особенности:значения переменных используемых в цикле, и не изменяющиеся в нем д.б. определены до входа в цикл;вход в цикл возможен только через его начало;выход их цикла осуществляется как в результате его естественного окончания, так и с помощью операторов перехода. Оператор цикла с постусловием в языке Паскаль. Оператор цикла с постусловием реализует следующую конструкцию: Формат записи: Repeat OP Until L; где: Repeat - повторять; Until – пока не;L – выражение логического типа;OP – тело цикла; оператор (простой или составной). Вычисление значения логического выражения следует после выполнения операторов тела цикла, поэтому этот оператор цикла называется циклом с постусловием. В отличие от цикла с предусловием, в цикле с постусловием тело цикла выполняется о крайней мере один раз не зависимо от условия. В операторе цикла с постусловием ключевые слова Repeat и Until играют роль операторных скобок. Пример. Составить программу вычисления функции y для заданного значения x.
17) Чаще всего, из структурированных типов данных встречается массив. Массив это упорядоченный набор данных одного типа.Для хранения данных, например, чисел, используются переменные. Каждая переменная должна иметь собственное имя. Если данных немного, проблем нет. Но если потребуется хранить сотню чисел, попробуйте не заблудиться среди сотни имен. Использование массива дает всем числам одно имя, отличаются числа друг от друга по индексу – номеру. Способ представления (хранения) массива требует уточнений. Каждый раз, когда мы собираемся использовать массив, нужно указывать: тип элементов (что храним в массиве); размерность (сколько индексов выделяют один элемент массива); величина (диапазон изменения каждого индекса). Определяя массив в языке BASIC, пишем служебное слово dim, после которого указываем имя массива. Тип элементов указывается значком %, !, #, $. Размерность определяет количество чисел в скобках. Сами числа – это наибольшее значение индекса. Начальное значение индекса – 0. Наибольшая размерность массивов – 2. По умолчанию, элементы массива – действительные числа.Следует отметить, что если массив одномерный и в нем не больше 10 элементов, то его объявление не обязательно. То есть использование команды DIM не требуется. BASIC dim <имя><тип элементов>(<дополнительная информация>) При определении массива в языке PASCAL, после имени массива пишем служебное слово array, дополнительняя информация указывается не в круглых, как в бейсике, а в квадратных скобочках, после которых пишем слово of и тип элементов. Фактически, в языке паскаль, используются только одномерные массивы, но зато элементом может быть массив. Двумерный массив организуется как одномерный массив одномерных массивов определенных элементов. Одномерный массив двумерных массивов фактически является трехмерным массивом и так далее. Тип индекса – любой перечислимый, кроме чисел элементы можно выделять буквами, сами числа могут начинаться с любого значения. PASCAL <имя>:array[<дополнительная информация>] of <тип элементов> Ввод и вывод массивов обычно происходит поэлементно. Основные операции – это обращение по индексам для запоминания или считывания значений элементов. В языке Pascal можно выполнять оператор присваивания с массивами и задать константу-массив. Обобщения массива. Существует возможность хранить и обрабатывать упорядоченные данные разного типа. Набор разнотипных, логически связанных между собой данных называют записью. Элементы записи имеют разный тип, назвать их можно одним обобщающим словом – поле. В записях требует уточнений: количество и тип полей. Как это оформляется в языке pascal показано ниже. Структурированные типы данных - запись PASCAL <имя записи>:record <имя поля>:<тип поля>; <имя поля>:<тип поля>; ... end; В языке BASIC нет небазовых типов, кроме массивов. Но элемент файла прямого доступа фактически является записью. Особенностью является, что все поля – строкового типа, различаются только длиной. Хранение чисел осуществляется как строки цифр. Основной операцией при работе с записями является обращение по именам к значениям полей для запоминания или считывания.При оформлении, после имени самой записи ставится точка, затем имя поля.PASCAL <имя записи>.<имя поля>Элементы записи могут быть любого типа (кроме файлового), в том числе и массивы, и другие записи.Оформление в языке программирования PASCAL: Пусть имеем перечислимый тип t1. Тогда <имя типа> = set of t1; определяет множество. * Способ образования.Элементы нового типа - группы выбранных элементов (в том числе и пустое множество) типа t1..Операции над множествами в языке PASCAL пересечение множеств a и b a*b объединение множеств a и b a+b разность множеств a и b a-b Для множеств возможны: Проверка на равенство множеств a и b a=b Проверка на неравенство множеств a и b a<>b Проверка, является ли a подмножеством от b a<=b , b>=a Проверка на принадлежность элемента e множеству a e in a Все проверки дают результат логического типа.
23. Переменные (присваивание, сравнение) Переменные в Pascal, также как и в математике служат для хранения некоторых величин, лишь с тем отличием, что тут они помимо численных значений могут содержать в себе текст, логические значения и т.д. Переменные тождественны идентификаторам, т.е. для того, чтобы в программе объявить переменную необходимо назвать ее. Pencil: Real = 5; Типизированные константы инициализируются всего один раз – в начале программы. Локальные и глобальные переменные в Turbo Pascal'e. Все задействованные в процедуре программные объекты (переменные, константы и т.п.) можно описывать в основной программе, однако это не рационально, поскольку излишне увеличивается основной раздел описаний и не экономно используется оперативная память компьютера Кроме того, изменения, вносимые в текст процедуры и затрагивающие имена и типы переменных, потребуют соответствующих изменений в основной программе, что осложняет ее отладку Указанные трудности в Паскале устраняются благодаря ПРИНЦИПУ ЛОКАЛИЗАЦИИ, суть которого состоит в том, что вводимые (описываемые) в какой-либо процедуре программные объекты (метки, константы, переменные, процедуры и функции, используемые для внутри-процедурных потребностей) существуют только в пределах данной процедуры. Имена, используемые для описания переменных, констант и других программных объектов внутри подпрограммы, называются ЛОКАЛЬНЫМИ для данной подпрограммы. Программные объекты, описанные в основной программе, называются ГЛОБАЛЬНЫМИ. Основные правила работы с глобальными и локальными именами можно сформулировать так: Локальные имена доступны (считаются известными, "видимыми") только внутри того блока, где они описаны. Сам этот блок, и все другие, вложенные в него, называют областью видимости для этих локальных имен. Имена, описанные в одном блоке, могут совпадать с именами из других, как содержащих данный блок, так и вложенных в него. Это объясняется тем, что переменные, описанные в разных блоках (даже если они имеют одинаковые имена), хранятся в разных областях оперативной памяти. Имя, описанное в блоке, "закрывает" совпадающие с ним имена из блоков, содержащие данный. Это означает, что если в двух блоках, один из которых содержится внутри другого, есть переменные с одинаковыми именами, то после входа во вложенный блок работа будет идти с локальной для данного блока переменной. Пременная с тем же имнем, описанная в объемлющем блоке, становится временно недоступной и это продолжается до момента выхода из вложенного блока. Глобальные имена хранятся в области памяти, называемой сегментом данных (статическим сегментом) программы. Они создаются на этапе компиляции и действительны на все время работы программы. В отличие от них, локальные переменные хранятся в специальной области памяти, которая называется стек. Они являются временными, так как создаются в момент входа в подпрограмму и уничтожаются при выходе из нее. Рекомендуется все имена, которые имеют в подпрограммах чисто внутреннее, вспомогательное назначение, делать локальными. Это предохраняет от изменений глобальные объекты с такими же именами. Операторы присваивания и сравнения Обычно в качестве оператора присваивания значения объекту, переменной или константе используется знак равенства (=). Например, выражение =Now() может присваивать полю таблицы значение по умолчанию, и тогда знак равенства действует как оператор присваивания. С другой сторону, знак = представляет собой оператор сравнения, определяющий, равны ли два операнда. Оператор сравнения соотносит значения двух операндов и возвращает логические значения (True или False), соответствующие результату сравнения. Основное назначение операторов сравнения — создание условий на значение, установление критериев выборки записей в запросах, определение действий макросов и контроль выполнения программ в VBА
13. Строка. Представление а памяти ЭВМ. Строки используются для хранения последовательностей символов. В Паскале три типа строк: стандартные (string);определяемые программистом на основе string;строки в динамической памяти. Строка типа string может содержать до 255 символов. Под каждый символ отводится по одному байту, в котором хранится код символа. Еще один байт отводится под фактическую длину строки. Для коротких строк использовать стандартную строку неэффективно, поэтому в язык введена возможность самостоятельно задавать максимальную длину строки, например: type str4 = string [4]; Здесь описан собственный тип данных с именем str4. Переменная этого типа занимает в памяти 5 байт. Длина строки должна быть константой или константным выражением. Примеры описания строк: const n = 15; var s : string; { строка стандартого типа } s1 : str4; { строка типа str4, описанного выше } s2 : string [n]; { описание типа задано при описании переменной }
Инициализация строк, как и переменных других типов, выполняется в разделе описания констант: const s3 : string [15] = 'shooshpanchik' ;Операции Строки можно присваивать друг другу. Если максимальная длина результирующей строки меньше длины исходной, лишние символы справа отбрасываются: s2 := 'shooshpanchik'; s1 := s2; { в s1 будут помещены символы "shoo" } Строки можно склеивать между собой с помощью операции конкатенации, которая обозначается знаком +, например: s1 := 'ком'; s2 := s1 + 'пот'; { результат - "компот" } Строки можно сравнивать друг с другом с помощью операций отношения. При сравнении строки рассматриваются посимвольно слева направо, при этом сравниваются коды соответствующих пар символов. Строки равны, если они имеют одинаковую длину и посимвольно эквивалентны: abc' > 'ab' abc' = 'abc' abc' < 'abc ' Имя строки может использоваться в процедурах ввода-вывода: readln (s1, s2); write (s1); При вводе в строку считывается из входного потока количество символов, равное длине строки или меньшее, если символ перевода строки (Enter) встретится раньше. При выводе под строку отводится количество позиций, равное ее фактической длине.К отдельному символу строки можно обращаться как к элементу массива символов, например, s1[4]. Символ строки совместим с типом char, их можно использовать в выражениях одновременно, например: s1[4] := 'x'; writeln (s2[3] + s2[5] + 'r'); Процедуры и функции для работы со строками Функция Concat(s1, s2, ..., sn) возвращает строку, являющуюся слиянием строк s1, s2, ..., sn. Ее действие аналогично операции конкатенации. Функция Copy(s, start, len) возвращает подстроку длиной len, начинающуюся с позиции start строки s. Параметры len иstart должны быть целого типа. Процедура Delete(s, start, len) удаляет из строки s, начиная с позиции start, подстроку длиной len. Процедура Insert(subs, s, start) вставляет в строку s подстроку subs, начиная с позиции start. Функция Length(s) возвращает фактическую длину строки s, результат имеет тип byte. Функция Pos(subs, s) ищет вхождение подстроки subs в строку s и возвращает номер первого символа subs в s или 0, еслиsubs не содержится в s. Процедура Str(x, s) преобразует числовое значение x в строку s, при этом для x может быть задан формат, как в процедурах вывода write и writeln, например, Str(x:6:2, s). Процедура Val(s, x, errcode) преобразует строку s в значение числовой переменной x, при этом строка s должна содержать символьное изображение числа. В случае успешного преобразования переменная errcode равна нулю. Если же обнаружена ошибка, то errcode будет содержать номер позиции первого ошибочного символа, а значение не x определено. 21. Классификация программного обеспечения.Языки программирования и их классификация. Метаязыки. Парадигмы и технологии программирования. Трансляторы и их виды. Программное обеспечение-это совокупность программ, выполненных вычислительной системой. К программному обеспечению (ПО) относится также вся область деятельности по проектированию и разработке (ПО): технология проектирования программ (нисходящее проектирование, структурное программирование и др.); методы тестирования программ; методы доказательства правильности программ; анализ качества работы программ и др. Программное обеспечение - неотъемлемая часть ЭВМ. Оно является логическим продолжением технических средств ЭВМ, расширяющие их возможности и сферу использования. Классификация программного обеспечения: -системное програмное обеспечение; -прикладное програмное обеспечение;-инструментарий программирования. Существует три категории: 1) Прикладные программы, непосредственно обеспечивающие выполнение необходимых пользователям работ.2) Системные программы: управление ресурсами ЭВМ;создание копий используемой информации; проверку работоспособности устройств компьютера;выдачу справочной информации о компьютере и др.. 3) Инструментальные программные системы, облегчающие процесс создания новых программ для компьютера. Более или менее определенно сложились следующие группы программного обеспечения: операционные системы. системы программирования, инструментальные системы, интегрированные пакеты,динамические электронные таблицы,системы машинной графики,системы управления базами данных (СУБД),прикладное программное обеспечение. Языки программирования и их классификация
16. Перечислимый и ограниченный типы данных. Этот тип данных получил название перечисляемого, потому что он задаётся в виде перечисления некоторых значений. Эти значения образуют упорядоченное множество и являются константами этого типа. Для объявления переменной список возможных значений, разделённых запятой, указывается в круглых скобках. Например, Var month: (january, february, marth, april, may, june, jule, august, september, october, november, december); Упорядоченность элементов перечисляемого типа определяется порядком их следования. Самый левый имеет минимальное значение (значение функции ord для него равно 0), а наиболее правый - максимальное. Ограниченный тип данных представляет собой интервал значений порядкового типа, называемого базовым типом. Описание типа задаёт наименьшее и наибольшее значения, входящие в этот интервал. Например,Var a: 1..25; ch: 'a' ..'z'; Здесь переменные а и ch могут принимать значения только из указанного интервала; базовым типом для переменой а является целый тип, а для переменной ch – символьный .Переменная ограниченного типа сохраняет все свойства переменных базового типа.Для чего вводится ограниченный тип данных? Использование ограниченного типа делает программу наиболее понятной и наглядной. Например, если в программе переменная b может принимать только значения 3, 4, 5, 6, 7, 8, то лучше описать её следующим образом: Var b: 3..8;, чем Var b: Integer; так как в случае выхода значения b за диапазон 3..8 в первом случае будет выдано диагностическое сообщение, которое поможет найти ошибку. Во втором случае будет получен неправильный результат, что затруднит поиск ошибки. Таким образом, второй вариант описания переменной следует использовать в тех случаях, когда диапазон значений заранее неизвестен либо занимает весь допустимый интервал значений для рассматриваемого типа. Основные (стандартные) типы данных часто называют арифметическими, поскольку их можно использовать в арифметических операциях. Для описания основных типов определены следующие ключевые слова: int (целый); char (символьный); wchar_t (расширенный символьный); bool (логический); float (вещественный); double (вещественный с двойной точностью). Первые четыре типа называют целочисленными (целыми), последние два – типами с плавающей точкой. Код, который формирует компилятор для обработки целых величин, отличается от кода для величин с плавающей точкой. Существует четыре спецификатора типа, уточняющих внутреннее представление и диапазон значений стандартных типов: short (короткий); long (длинный); signed (знаковый); unsigned (беззнаковый).
|
8)«Основные (базовые) типы данных» Понятие типа данных Напомним о понятии «переменная».В алгоритмических языках под переменной понимают область памяти, где хранятся обрабатываемые данные. (Исходные, промежуточные и итоговые.). Название происходит от того, что при работе ЭВМ данные могут менять свои значения.Область памяти характеризуется размером и адресом начала. Чтобы разные переменные человеку легче было отличать друг от друга, им даются имена (идентификаторы). (Компьютер отличает переменные друг от друга по их началу в памяти.) Информацию, хранящуюся в переменной в момент обращения к этой переменной называют ЗНАЧЕНИЕМ переменной. адрес начала и размер в памяти | | | +--+- память -+----------+ | | | | ПЕРЕМЕННАЯ | | / \ | +- имя значение – тип (возможный диапазон значений) В переменных хранятся разные данные, разные по размеру и назначению. Компьютер работает и с числами, и с буквами, и с картинками. Выполняемые над разными объектами действия должны быть различны. Для обеспечения принципа детерминированности (компьютер должен знать, что можно делать с разными данными), все данные разбиты на группы, с данными одной группы можно выполнять определенный набор действий. Заодно, договорились, что и размер места в памяти данных одного типа одинаков. Описанные группы данных называют данными одного типа. Типы данных так же имеют имена. Будем изучать все типы данных по одной схеме: 1) имя типа 2) размер в памяти (кодирование) 3) набор операций 4) связь с данными других типов К простейшим (базовым) типам данных относят такие, для которых достаточно только имени, чтобы компьютер понял, сколько места выделить в памяти для их хранения и какие операции с ними можно выполнять. *** Классификация типов данных
* Сложные (структурные) типы данных. Данные этих типов, как и данные базовых типов, занимают в памяти фиксированную область. Фактически, являются совокупностью данных базового или самого структурного (кроме файлов) типа. Идентификатор заложен в транслятор (массив, запись, множество, файл). Кодирование требует уточнений. Набор внутритиповых операций связан с обращением к данным. Набор операций связи с данными других типов связан с кодированием. * Динамические типы данных. Область памяти, где хранятся данные этих типов, может изменять со временем свои размеры. В современных языках программирования специальных средств не имеют. Идентификатор определяется программистом. Кодирование определяется программистом. Набор внутритиповых операций определяется программистом. Набор операций связи с данными других типов определяется программистом. ***** БАЗОВЫЕ ТИПЫ ДАННЫХ 1 Базовые (простые) типы данных (базовые способы хранения информации). Для работы с данными этих типов не требуется никаких уточнений, достаточно только указать тип. Идентификатор, кодирование и набор операций заложены в транслятор. Есть возможность увеличения набора операций (функции пользователя). 3 Получение информации базовых типов происходит специальным оператором присваивания, из константы или чтением с клавиатуры (или из файла). Вывод данных базовых типов организуется единой стандартной командой.
10)Базовый тип данных - целое число. (Имена типов приводятся согласно ЯП Паскаль) Компьютер предназначен прежде всего, для работы с числами. Выделяют несколько типов целых чисел. Целые натуральные (без знака) и целые со знаком. Кроме того, целые числа занимают разное количество байт. Для числа без знака используется двоичная запись в выделенное место памяти. Поскольку счет идет с 0, то: для одного байта диапазон [0..255] (byte) {=2^8-1}; для двух байт - [0..65535] (unsign) {=2^16-1}; для четырех байт - [0..4294967295] {=2^32-1} Для числа со знаком самый старший бит выделен для знака 0 - число положительное, 1 - отрицательное. В целом, отрицательное число образуется из положительного за два шага: 1) в двоичной записи числа обратим цифры "1" в цифры "0" и наоборот, 2) к полученному числу добавим 1 (действие выполняем в двоичной системе счисления).Очевидно появление цифры "1" на первом месте, если там был "0". Такое кодирование решает три задачи: 1) образование положительного числа из отрицательного выполняется теми же двумя операциями (убедитесь сами!) 2) числа "+0" и "-0" представляются одинаково. 3) кодирование самообратимо { k(k(x))=x } 00000101 - число 5 в 1 байте 00000101 - исходное 11111010 - после инверсии 11111011 - после добавления 1 11111011 - число -5 в 1 байте 11111011 - исходное 00000100 - после инверсии 00000101 - после добавления 1 Описанный способ представления отрицательных чисел называется «дополнительное кодирование». Дополнение до 1, которая при сложении числа А с числом –А уйдет за пределы выделенной области, останется 0. Прежде встречались:- прямое кодирование – просто у отрицательных чисел вписывалась 1 в старший бит. Тое есть число 0 можно было писать 00000000 и 10000000 (+0 и -0!!!) - обратное кодирование – у числа 0 менялись на 1, а 1 на 0. Тоже в наличии значения +0 и -0 соответственно 00000000 и 11111111 В зависимости от выделяемой памяти имеются: для одного байта диапазон [-128..+127] (shortint) для двух байт - [-32768..+32767] (integer) для четырех байт - [-2147483648..+2147483647] (longint) В языке PASCAL имя типа диапазон значений byte 1 байт, без знака, 0..255 word 1 байт, без знака, 0..65535 shortint 1 байт, со знаком, -128..+127 integer 2 байт, со знаком, -32768..+32767 longint 4 байт, со знаком, -2147483648..+2147483647 Способ кодирования – двоичное представление и дополнительный код для отрицательных чисел. Основные операции. BASIC PASCAL сложение a и b a+b a+b вычитание a и b a-b a-b умножение a на b a*b a*b Делить целые числа нельзя! – Результат – не целое число. деление нацело a на b a\b a div b остаток от деления a на b a mod b a mod b взятие модуля a abs(a) abs(a) логические И от a и b a and b a and b ИЛИ от a и b a or b a or b отрицание a not a not a Связь с данными других типов. В языке pascal различают 5 типов целочисленных данных, связь между ними автоматическая, то есть аргументы операций приводятся к одному типу, выполняется операция. Попытка сохранения результата в другом типе, например word как integer, может привести к ошибкам. Числа, большие чем 32767, будут показаны как отрицательные.Пока другие типы не изучались, связь целочисленных типов с ними рассматривать не будем. В языке basic программу можно написать не обращая внимания на типы. Имеющийся целочисленный тип соответствует паскалевскому типу integer, обозначается наличием знака % в конце имени переменной.
3) Способы записи алгоритмов Алгоритм – точная конечная последовательность команд, приводящая от исходных данных к искомому результату за конечное число шагов Способы (формы) записи алгоритмов Словесно-пошаговый, алгоритмический язык , блок-схема, структурограмма. Словесно-пошаговый способ записи алгоритмов Описывает алгоритм на естественном языке, задавая шаги в виде последовательных пунктов. Не смотря на простоту этого способа, он имеет множество недостатков: отсутствие строгой формализации, толкование шагов не всегда однозначно, описание чрезмерно многословно. Классическим примером словесно-пошагового алгоритма являются рецепты приготовления блюд. Графический способ описания алгоритмов :Существует несколько способов графического описания алгоритмов. Наиболее широко используемым на практике графическим описанием алгоритмов является использование блок-схем. Достоинство блок схем – наглядность и простота записи алгоритма. Каждому действию алгоритма соответствует геометрическая фигура
В линейном алгоритме команды выполняются последовательно,блок-схема будет иметь вид:
Т.к. в разветвляющемся алгоритме порядок следования команд может быть разный,блок-схема примет вид:
В циклическом алгоритме некоторые действия повторяются несколько раз и для него блок-схема примет вид:
Структурограммы
:
дают полное визуальное представление
деталей логических операций над
группами операторов программы.
Структурограмма (схема
Насси–Шнейдермана) – это
схема, иллюстрирующая структуру
передачи управления внутри модуля с
помощью вложенных друг в друга блоков.
Каждый
блок имеет форму прямоугольника и
может быть вписан в любой внутренний
прямоугольник любого другого блока.
Запись внутри блока производится на
естественном языке или с помощью
математических обозначений. Символ
«Обработка» содержит описание действий,
выполняемых оператором или группой
операторов. В подобном символе можно
помещать операторы присваивания,
ввода/вывода и т. д. Управление
передается в прямоугольник сверху, а
выходит из него снизу. Символ «Cледование»
объединяет ряд следующих друг за
другом процессов обработки. В отдельные
прямоугольники записываются логически
завершенные шаги программы. Управление
начинает свой путь на внешней стороне
верхнего прямоугольника, проходит
через каждый прямоугольник и завершает
путь на внешней стороне нижнего
прямоугольника. Символ «Решение»
применяется для обозначения конструкций
IF-THEN-ELSE. Условие (вопрос) располагается
в верхнем треугольнике, варианты
ответов – по его сторонам, а
процессы обработки обозначаются
прямоугольниками. В результате принятия
решения управление передается в один
из нижних прямоугольников:
Для усеченной конструкции разветвления
IF-THEN прямоугольник, соответствующий
ветви невыполнения условия – НЕТ,
следует оставить пустым. Символ
CASE представляет расширение блока
решение. Условие, называемое селектором
выбора, записывается в верхнем
треугольнике. Варианты выхода из
треугольника, соответствующие точно
определенным значениям селектора,
размещаются в маленьких треугольниках
по его левой стороне. Каждому варианту
соответствует свой символ обработки.
По правой стороне треугольника
размещается выход по несовпадению
условий и соответствующий ему
альтернативный символ обработки.
14. *** Работа с файлами. 1 Определение. Файл - информация, подготовленная для хранения во внешней памяти или к использованию на внешних устройствах (ВУ). Частным случаем файла является ТЕКСТ (TEXT) Текст - файлы последовательного доступа (чтение и запись данных начинаются всегда от начала файла) В файлах могут храниться как данные, так и команды (программы) Различают файлы программы: - хранящие текст программы на языке высокого уровня - хранящие исполняемый код для прцессора файлы данных: - последовательного доступа (чтение и запись данных начинаются всегда от начала файла) - прямого доступа (чтение и запись данных возможны для любого места) 2 Способы представления (хранения). Для различия между собой, файлы имеют имена. Имена имеют и ВУ: CON, KBD, CRT, PRN, LPT1,...LPT3, COM1, COM2 (ДОС); GRP (MSX-basic); SCRN, KYBD (GWbasic) Стандартными внешними устройствами являются клавиатура и дисплей. Используя при передаче файловой информации вместо имен файлов имена устройств, получают ввод информации с указаных устройств или вывод информации на нестандартные устройства. Поэтому имена устройств нельзя давать файлам. Полное имя файла состоит из трех частей: адресная - <имя устройства памяти>:[/<имена подкаталогов через />] именная - <имя файла до 8 знаков> расширение имени файла - <три знака> При написании, между именем файла и расширением ставится точка. При работе с текущим устройством адресная часть полного имени файла может быть пропущена (берется "по умолчанию"), важными являются только имя и расширение, которые обычно называют именем файла. ТЕКСТ - набор данных, имеющий вид упакованных строк, закачивается специальным знаком "конец файла" <26>. Файлы - программы, доступные процессору, т.е. могут сразу исполнены, имеют расширения .COM или .EXE . Имена таких файлов служат командами исполнения содержимого для операционной системы. Операционная система (ОС) - специальная программа, автоматически запускаемая при включении компьютера, основным назначением которой является поиск и исполнение файлов-программ. Файлы - программы на языке "Pascal" - содержат текст программы, являются строками. Могут быть созданы с помощью любого текстового редактора. С помощью программы-транслятора могут быть преобразованы в файлы, исполняемые процессором. Обычно специальный редактор объединяют с транслятором, куда добавляются средства контроля программ и систему подсказок (Help) - получается система программирования. Результат работы такой системы, записанный в виде .COM или .EXE - файла, в дальнейшем, присутствия системы программирования не требует. По стандарту языка "BASIC", для выполнения программ обязательно требуется присутствие BASIC-системы. При работе которой оператор находится в среде специального редактора. Набираемые команды могут быть выполнены немедленно, или, если имеют метку - номер, запомнены в оперативной памяти. Команды оперативной памяти могут быть просмотрены командой "LIST" или исполнены командой "RUN" Из оперативной памяти программа может быть перенесена во внешнюю командой SAVE"<ИМЯ ФАЙЛА>"[,A] Запись присходит в более коротком кодированном варианте или (при наличии флажка - буквы "A" в команде) в полном варианте, пригодном для просмотра и печати средствами ДОС. Командой восстановления программы в оперативную память из файла является LOAD"<ИМЯ ФАЙЛА>"[,R] Флаг 'R' служит для немедленного запуска программы после "загрузки". Загрузить в оперативную память и сразу исполнить программу можно командой RUN"<ИМЯ ФАЙЛА>" Обычно, файл - программа на языке "BASIC" имеет расширение .BAS . Запись/загрузка подпрограмм в кодах проводится командами BSAVE"<имя>" BLOAD"<имя>" При работе с кассетным магнитофоном в качестве ВУ, используют команды CSAVE"<имя>" CLOAD"<имя>" Есть возможность объединения двух текстов - программ в один. Для этого один текст должен быть в оперативной памяти, а другой, заранее подготовленный, должен быть записан в файл в полном варианте. Команда MERGE"<имя подготовленного файла>" создаст в оперативной памяти совместный текст обеих программ. Если в склеиваемых текстах были строки с одинаковами номерами, то останется только строка подготовленного файла. Итак, на примере работы с файлами-программами на языке "BASIC", имеем три вида работы с файлами - создание (SAVE), чтение (LOAD) и добавление (MERGE). Для работы с файлами данных в языке BASIC, в начале программы должно быть указано число одновременно открытых файлов MAXFILES=<N>, по умолчанию, это число =1. Каналы связи программы с файлом нумеруются, номера используются в командах. В файлах могут быть только данные базовых типов. В языке PASCAL вместо номеров каналов связи вводятся переменные файлового типа, которые описываются как :file of <тип элементов>; или :text; Элементы файлов могут быть любых типов, кроме файлового. Слово "text" указывает на файл строк произвольной длины. * Способ образования (хранения). <цифры приведены для ЭВМ "Yamaha"> В памяти компьютера, для каждого файла, выделяется буфер <256 байт> При создании файла последовательного доступа, заполняется не файл, а буфер. По заполнении буфера, все его содержимое копируется во внешне устройство (файл), буфер очищается и готов заполняться снова. При чтении, часть содержимого файла, копируется в буфер, откуда читается программой. По мере необходимости, в буфер считываются очередные порции информации. При работе файлов прямого доступа, команды смены содержимого буфера приходится программировать. Для работы буфера используются служебная информация - блок управления файлом (File Control Blok - FCB) <9 байт> * Для работы с текстами обычно используют специальный редактор. Для работы с файлами данных в языке BASIC, в начале программы должно быть указано число одновременно открытых файлов MAXFILES=<N>, по умолчанию, это число =1. Каналы связи программы с файлом нумеруются, номера используются в командах. В языке PASCAL вместо номеров каналов связи вводятся переменные файлового типа, которые описываются как :text; 3 Основные операции. С файлами проделывают две операции: открывают с какой-то целью и закрывают. (file - папка (англ)). Существуют три цели открытия файла - для занасения в него данных (заново) - для добавления в него данных (в конец) - для извлечения из него информации. BASIC PASCAL открыть open "<имя>" for output as#1 rewrite(f) для записи open "<имя>" for input as#1 reset(f) для чтения open "<имя>" for append as#1 append(f) для добавления close(#1) close(f) закрыть После открытия файла стандартные команды получения и вывода информации,при наличии указания на номер или имя канала связи, работают с файлом: PRINT #1, A;B WRITE(f,A,B); WRITELN(f,A,B); INPUT #1, X,Y READ(f,X,Y); READLN(f,X,Y); В языке PASCAL файловая переменная перед использованием связывается с именим файла - строкой знаков специальной командой ASSIGN(f,<имя>); 4 Связь с данными других типов. Элементом текста является строка. Возможны файлы данных любого вообразимого типа. В файле могут быть несколько данных одного типа.Файлы программ считаются двоичными. В них хранятся байты кодов команд процессора (в двоичной форме). 18) Линейные списки (основные операции) Списком называется структура данных, каждый элемент которой посредством указателя связывается со следующим элементом. Из определения следует, что каждый элемент списка содержит поле данных (Data) (оно может иметь сложную структуру) и поле ссылки на следующий элемент (Next). Поле ссылки последнего элемента должно содержать пустой указатель (NIL).Чтобы список существовал, надо определить указатель на его начало. Опишем переменные: Var и, х: EXS; Создадим первый элемент: New(u); {выделим место в памяти для переменной типа S} u^.next:=nil; {указатель пуст} и^.data:=3; {информационное поле первого элемента} Продолжим формирование списка, для этого нужно добавить элемент в конец списка. х:=и; {Введем вспомогательную переменную указательного типа, которая будет хранить адрес последнего элемента списка. Сейчас последний элемент списка совпадает с его началом.} New(x^.Next)•,{выделим область памяти для следующего элемента списка} x:=x^.Next; {переменная х принимает значение адреса выделенной области памяти} x^.Data:=5; {определим значение этого элемента списка} x^.Next.=Nil: Оформим создание списка в виде процедуры, в которой его элементы вводятся с клавиатуры. Procedure Init(Var u: Exs); {создание списка} Var х, у: Exs; Digit: Integer; {значение информационной части элемента списка} Begin Writeln('Введите список '); u:=Nil; {список пуст} WriteLn('Bводите элементы списка. Конец ввода 0); Read(Digit); While Digit<>0 Do Begin New(y); {формирование элемента списка} y^.Nexf:=Nil; y^.Data:=Digit; If u=nil Then u:=y {вставляем первый элемент списка} Else x^.Next:=y; {вставляем элемент в конец списка} х:=у; {переносим значение указателя на последний элемент списка} Read(Digit); End; Writein; End; Итак, мы построили список добавлением элементов в конец списка. Вставим элемент со значением 7 в начало списка. Удаление элемента из начала списка Напишем фрагмент программы: х:=и; {запомним адрес первого элемента списка} u:=u^.next; {теперь и указывает на второй элемент списка} Dispose(x); {освободим память, занятую переменной х^} Удаление элемента из середины списка Для этого нужно знать адреса удаляемого элемента и элемента, находящегося в списке перед ним. х:=и; {переменная х для хранения адреса удаляемого элемента} {найдем адреса нужных элементов списка } While (x<>Nil) And (x^.Data<>Digit) Do Begin dx:=x; x:=x^.Next End; dx^.Next:=x^.Next; Dispose(x); Удаление элемента из конца списка Оно производится, когда указатель ах показывает на предпоследний элемент списка, а х — на последний. {найдем предпоследний элемент} х:=и; ах:=и; While x^.Next<>NIL Do Begin dx:=x; x:=x^.Next; End; {удаляем элемент х^ из списка и освобождаем занимаемую им память} dx^.Next:= Nil; Dispose(x); Стек Стек — упорядоченный набор элементов, в котором добавление новых элементов и удаление существующих производится с одного конца, называемого вершиной стека. В любой момент времени доступен лишь один элемент стека — верхний. Из определения следует, что извлекать элементы из стека можно только в порядке, обратном порядку их добавления в стек (первый пришел, последний ушел).Стек предполагает вставку и удаление элементов, поэтому он является динамической, постоянно меняющейся структурой.Стеки довольно часто встречаются в практической жизни. Процесс сборки и разборки ее подобен процессу функционирования стека. Основные операции со стеками Как было сказано выше, стек является динамической структурой, размеры которой изменяются по мере добавления и удаления элементов. Поэтому удобнее всего применить для реализации стека динамическую структуру данных, а именно список. Дадим новое определение стека. Стек — это список, в котором добавление новых элементов и извлечение имеющихся происходит с начала (или конца) списка. Значением указателя, представляющего стек, является ссылка на вершину стека, каждый элемент стека содержит поле ссылки. Таким образом, описать стек можно следующим образом: Type EXST=^ST; ST=Record Data: Integer; Next: EXST; End; Var Stack: EXST; {текущая переменная} Тогда, если стек пуст, то значением указателя равно NIL. Занесение в стек Процедура занесения элемента в стек должна содержать два параметра — первый задает нужный стек, второй — заносимое в него значение. Обозначим их соответственно х1 и с. Занесение в стек производится аналогично вставке нового элемента в начало списка: Procedure WriteStack (Var ir.EXST; digit: Integer); {запись в стек} Var x:.EXST; Begin New(x); {создание нового элемента стека} x^.Data:=diglt; х^.Nехt:=u {созданный элемент определить как вершину стека} u:=х; End; Основная программа формирования стека будет иметь вид: Var Stack: EXST; {текущая переменная} digit: Integer; Begin Stack:=Nil; WriteLn(1'Введите элементы стека. Окончание ввода — О'); Read(Digit); While Digit<>O Do Begin WriteStack(Stack, digit); Read(digit); End End. Извлечение элемента из стека. В результате выполнения этой операции некоторой переменной i должно быть присвоено значение первого элемента стека и изменено значение указателя на начало списка. Procedure ReadStack(Var u-.EXST; Var i-.Integer); Var x: EXST; Begin i:u^.Data; x:=u; u:=u^.Next; Dlspose(x); End; Недостатком описанной процедуры является предположение о том, что стек не пуст. Для его исправления следует разработать логическую функцию проверки пустоты обрабатываемого стека. function Free(u:EXST):Boolean; Очереди Очередь — это упорядоченный набор элементов, в котором извлечение элементов происходит с одного его конца, а добавление новых элементов — с другого. Очередь является динамической структурой — с течением времени изменяется и ее длина, и набор составляющих ее элементов. Поэтому удобно представить ее в виде списка. Описание очереди на языке программирования: Type ЕХО=^О; O=Record Data: Integer; Next: EXO; End; Над очередью определены две операции: занесение элемента в очередь и извлечение элемента из очереди. В очереди, в силу ее определения, доступны две позиции: ее конец, куда заносятся новые элементы, и ее начало, откуда извлекаются элементы. Поэтому для работы с очередью необходимо описать две переменные: Var xl, х2: EXO; где xl — соответствует началу очереди и будет использоваться для вывода элемента из очереди, х2 — соответствует концу очереди и будет использоваться для добавления новых элементов в очередь. Поскольку очередь представлена списком, занесение элемента в очередь соответствует занесению элемента в конец списка. Procedure WriteO (Var xl,x2: EXO; с: Integer); Varи: EXO; Begin New(u); u^.data:=c; u^.nexf:=^NIL; If xl=NIL Then xl:=u {если очередь пуста} Else x2^.next:=u; {заносим элемент в конец списка} х2:=u; End; Основная программа, создающая очередь, может быть такой: Begin xl:=NIL; x2:=NIL; Write Ln('Введите элементы очереди. Конец ввода — О'); Read(Digit); While Digit<>O Do Begin WriteO(xl,x2,Digit); Read(Digit); End End. Процедура извлечения элемента из очереди аналогична удалению элемента из начала списка. Поскольку извлечение элемента из пустой очереди осуществить нельзя, опишем логическую функцию, проверяющую, есть ли элементы в очереди. Procedure Reado(Var xl,x2:EXO; Var c:Integer); Var u:ЕХО; Function Nul (xl: ЕХО): Boolean; Begin Nul:=(xl=Nil); End; Begin If Nul(xl) Then Writeln(‘0чepeдь пуста') Else Begin c:=xl^.Data; u:=xl; xl:=xl^.Next; Dispose(u); End; End; Деревья Введение основных понятий Граф — это непустое множество точек (вершин) и множество отрезков (ребер), концы которых принадлежат заданному множеству точек. Если на каждом ребре задать направление, то граф будет ориентированный. Если, двигаясь по ребрам графа в заданном направлении, можно попасть из заданной вершины 1 в заданную вершину 2, то говорят, что эти вершины соединены путем. Замкнутый путь, состоящий из различных ребер, называется циклом.Граф называется связным, если любые две его вершины соединены путём. Связный граф без циклов называется деревом. На рис. 54 изображено дерево, в узлах которого располагаются символы. Примечание. С каждой вершиной дерева связывается конечное число отдельных деревьев, называемых поддеревьями. Для дальнейшей работы с деревьями необходимо определить ряд понятий. • Вершина у, находящаяся непосредственно ниже вершины х, называется непосредственным потомком х, а вершина х называется предком у. • Если вершина не имеет потомков, то она называется терминальной вершиной или листом, если имеет, то называется внутренней вершиной. • Количество непосредственных потомков внутренней вершины называется ее степенью. • Степенью дерева называется максимальная степень всех вершин. Например: • вершины F, D, Е являются непосредственными потомками вершины В; • вершины F, D, Е являются листьями; • вершины С, G, Н — внутренние; • степень вершины В — 3, а вершины Н — 1; • степень дерева равна 3. Двоичное дерево — это дерево, в котором из каждой вершины исходит не более двух ребер. 6.2. Представление деревьев Дерево — это сложная динамическая структура данных, применяющаяся для эффективного хранения информации. Очевидно, что для описания требуются ссылки. Опишем, как переменные с фиксированной структурой — сами вершины, тогда степень дерева будет определять число ссылочных компонент, указывающих на вершины поддеревьев. В бинарном дереве их два - левое и правое. Type TreeLink =^Tree; Tree=Record Data: <mun данных>; Left, Right: TreeLink; End; Корень дерева опишем в разделе описания переменных: Var kd: TreeLink; 6.3. Основные операции над деревом К основным операциям над деревьями относятся: • занесение элемента в дерево; • обход дерева; • удаление элемента из дерева. Рассмотрим вставку и обход дерева на примере следующей задачи. 6.5. Удаление из дерева Непосредственное удаление элемента из упорядоченного дерева реализуется достаточно просто, если эта вершина является конечной (рис. 55) или из нее выходит только одно ребро (рис. 56). Для этого нужно изменить соответствующую ссылку у предшествующей вершины. Если же из удаляемой вершины выходит две ветви, то нужно найти подходящую вершину дерева, которую можно было бы вставить на место удаляемой вершины (рис. 57).Из вышесказанного следует, что процедура удаления элемента из дерева должна различать три случая: • удаляемая вершина имеет два поддерева (В этом случае удаляемый элемент нужно заменить либо на самый правый элемент его левого поддерева, либо на самый левый элемент его правого поддерева. При этом они должны иметь не больше одного потомка); • удаляемая вершина имеет не более одного поддерева (0 или 1); • удаляемой вершины в дереве нет. Ниже приведена рекурсивная процедура deltree, решающая поставленную задачу. Она отыскивает элемент с заданным ключом и удаляет его. В процедуре deltree описана вспомогательная процедура dl, которая работает только в первом из трех перечисленных случаев.Вспомогательная процедура dl "движется" по правой ветви левого поддерева исключаемого элемента q^ и заменяет значение ключа в q^ на соответствующее значение из самого правого элемента r^ левого поддерева.
1. Базис, алфавит, основание. Система счисления - способ записи (изображения) чисел. Символы, при помощи которых записывается число, называются цифрами. Системы счисления, в которых количественный эквивалент каждой цифры зависит от ее положения (позиции) в коде(записи) числа, называются позиционными. Основанием позиционной системы счисления называется количество знаков или символов, используемых для изображения числа в данной системе счисления. Базисом позиционной системы счисления называется последовательность чисел, каждое из которых задает количественное значение или "вес" каждого разряда.
Например: Базисы некоторых позиционных систем счисления. Десятичная система: 100, 101, 102, 103, 104, ..., 10n, ... Двоичная система: 20, 21, 22, 23, 24, ..., 2n, ... Восьмеричная система: 80, 81, 82, 83, 84, ..., 8n, ... Совокупность различных цифр, используемых в позиционной системе счисления для записи чисел, называется алфавитом системы счисления. Количество цифр в алфавите равно основанию системы счисления. Уравновешенные системы счисления
---===---
Двоичная СС с большим успехом используется в компьютерной технике до сих пор. Однако выявились и существенные недостатки использования двоичной СС, влияющие на скорость работы процессора и надежность передачи информации.
Одним из этих недостатков является так называемая проблема представления отрицательных чисел. Попытка преодолеть этот и другие недостатки двоичной системы счисления стимулировала использование в компьютерах других систем счисления и развитие собственно теории систем счисления.
Выбирая систему кодирования информации в компьютере, разработчики в первую очередь думают о быстродействии процессора, т.е. о скорости обработки закодированной информации. /// Что привычно и хорошо для человека, выполняющего вычисления на бумаге, не всегда хорошо для компьютера. Для того чтобы сложить два целых числа с разными знаками, и человек, и компьютер, вообще говоря, должны выполнить следующие действия: 1) взять модули слагаемых; 2) сравнить эти модули; 3) запомнить знак большего по модулю слагаемого; 4) получившийся результат з 5) из большего модуля вычесть меньший модуль; 6) записать со знаком из п. 3. Многовато будет для простой и часто используемой операции! \\\
В десятичной системе счисления для представления отрицательных чисел человек использует знак числа. То, есть для записи отрицательных чисел имеющихся 10 знаков недостаточно. Используется еще один знак - '-'. То есть для записи отрицательных десятичных чисел потребоваломь 11 знаков! Аналогично, для записи отрицательных двоичных чисел требуется 3 знака, но в нашем распоряжении их два - 0 и 1. Для решения проблемы вначале века использовалось прямое кодирование: в старший бит регистра числа явно вписывался знак '0' для положительных и знак '1' для отрицательных чисел. При определении значения числа этот бит игнорировался. Вроде бы все нормально, но процессор не может работать с отдельными битами регистра. Для определения знака числа, число загружалось в процессор, применение маски (числа 10 или 1000) оставляло в регистре только бит знака, весь регистр проверялся (ноль или нет). Для выделения значения числа снова использовалась маска (7F или 7FFF), после чего определялось число - не слишком ли много действий процессора для выполнения простых операций? /// для 1 байта 5 = 00000101 -5 = 10000101 \\\ Чтобы сократить число действий процессора, придумали обратный код: для чисел договорились старший бит не использовать, а для получения отрицательного числа выполнять команду инвертирования - менять в записи 0 на 1, а 1 на 0. Это одна команда для процессора. Но проверка бита знака все равно остется. /// для 1 байта 5 = 00000101 -5 = 11111010 \\\
Кроме всего прочего применение прямого или обратного кодирования добавляет новую проблему: число 0 оказываеися можно хранить двумя разными способами (как?). Появились значения +0 и -0. Представьте, решаем квадратное уравнение, и начинаем проверять, равен ли он 0. Поребуется сравнивать как с число 0, так и с числом -0, - двойная работа! Использующийся в настоящее время во всех компьютерах способ хранения отрицательных чисел называется "дополнительный код". Для получения из положительного числа отрицательного, как и при дополнительном коде, выполняют инвертирование, после чего к результату добавляется 1. Неболбьшое усложнение кодирования снимает проблему двойного представления нуля: 00000000 - исходное
11111111 - после инвертирования
11111111 1 ---------- 100000000 - после добавления 1 Так как самый старший бит является девятым и в однобайтный регистр не помещается, он будет отброшен. То есть 0 представляется только как 00000000.
Кодирование называется дополнительным, потому что положительное и отрицательное числа "дополняют" друг друга до той самой единицы, бит для хранения которой выходит за пределы регистра. Поэтому и преобразование отрицательного числа в положительное происходит по тому же правилу: инверсия и увеличение на 1.
Еще одно преимущество такого представления чисел: появилась возможность отказаться от операции вычитания. Вместо нее применяется сложение с отрицательным числом. Попробуйте выполнить сложение над двоичными числами, записанными в дополнительном коде. /// !!! подобрать примеры сложения положительных, отрицательных, смешанных чисел !!! \\\
Все вроде хорошо, но попробуйте в переменную X, объявленную как var x:integer; записать положительное число 37000, хранимое без знака (как word), получим, неожидано, отрицательный результат -28536! Подобные фокусы могут привести к ошибочной интерпретации результатов работы программы. /// var x:integer; y:word; begin y:=37000; x:=y; writeln(x); readln; end. \\\ Ошибка произошла потому, что типы integer и word по разному понимают содержимое старшего бита регистра.
---===---
Троичная система
Можно ли записывать целые отрицательные числа без знака, но и без дополнительного кодирования? Можно! Например, в любой P-ичной уравновешенной системе счисления.
Уравновешенная система с наименишим основанием - это троичная. В 60-х годах XX столетия в МГУ им. М.В. Ломоносова была создана троичная ЭВМ "Сетунь", запущенная потом в серию. Для кодирования информации в этой машине использовалась троичная уравновешенная система счисления, вместо бита использовался трит, вместо привычной двоичной логики - троичная. Разработчик этой ЭВМ Николай Петрович Брусенцов.
|||"бит" - место для хранения двоичной цифры - 0 или 1, |||"трит" - место для хранения цифры троичной системы счисления.
Троичную систему счисления можно построить, как и другие, взяв за основание число 3. Базой при этом будут числа 1, 3, 9, 27, 81, ..., а цифрами (алфавитом) 0, 1 и 2. Но кто нам мешает в качестве цифр взять символы { a, 0, 1}, где a равно -1. Глядя на набор цифр, понятно, почему эту систему назвали уравновешенной, или симметричной. Количество цифр до цифры 0 такое же ("уравновешено с"), что количество цифр после цифры 0. "Уравновесить" можно любые системы счисления с нечетным основанием.
Десятичное число Число в троичной уравновешенной системе положительное отрицательное положительное отрицательное 1 -1 1 a 2 -2 1a a1 3 -3 10 a0 4 -4 11 aa 5 -5 1aa a11 6 -6 1a0 a10 7 -7 1a1 a1a
Очевидно, знак для представления отрицательных чисел в урвновешенных системах счисления не нужен! Если у нас есть хотя бы трицифры, обязательно 0, обязательно 1, для третьей цифры можем ставить в соответствие отрицательное значение (-1). Можно ввести отрицательные значения для некотрых цифр СС с четным основанием, но это приводит к тому, что некоторые числа можно будет записать разными способами. /// Для "четверичной" системы счисления можно выбрать и {-1, 0, 1, 2}, и {-2, -1, 0, 1}. \\\
---===---
Рассмотрим операции сложения и вычитания в троичных системах:
в троичной системе Сложение
+ 0 1 2 0 0 1 2 1 1 2 10 2 2 10 11
Умножение
* 0 1 2 0 0 0 0 1 0 1 2 2 0 2 11
в троичной уравновешенной системе сложение + 1 0 1 1 11 1 0 0 1 0 1 1 0 1 11
умножение * 1 0 1 1 1 0 1 0 0 0 0 1 1 0 1
/// сформировать правила построения таблиц сложения и умножения и правила арифметических операций для целых чисел. \\\ Числа Фибона́ччи — элементы числовой последовательности, где каждое следующее число образуется суммой двух перед ним стоящих чисел (кроме первых двух). Фибоначчиева система счисления (фсс) Для компьютеров, основанных на классической двоичной системе счисления, не всегда можно эффективно решать проблему отсутствия механизма обнаружения ошибок. В 80-х годах XX столетия группа ученых под руководством профессора Алексея Петровича Стахова из Таганрогского радиотехнического института создала опытный экземпляр помехоустойчивого процессора [3]. Этот процессор мог сам контролировать возникающие в его работе сбои. Для кодирования информации была выбрана фибоначчиева система счисления. Ее использование позволило построить удивительный процессор, на званный “Фибоначчи-процессор”, или “Ф-процессор”. И хотя успешная попытка построения помехоустойчивого процессора на основе фибоначчиевой системы счисления носила скорее теоретический, чем практический интерес, изучение этой замечательной системы счисления заслуживает внимания. Для указания, что число записано в ФСС, будем использовать в нижнем индексе сокращение fib. Например, 10000101fib = 3810. Числа Фибоначчи — элементы числовой последовательности 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584, 4181, 6765, 10 946, …, в которой каждое последующее число, начиная с третьего, равно сумме двух предыдущих чисел. Для формального определения чисел Фибоначчи используют следующее рекуррентное соотношение: F0 = 1, F1 = 1, Fn = Fn2 + Fn1 . Последовательность, известная у нас как числа Фибоначчи, использовалась в Древней Индии задолго до того, как стала известна в Европе после изучения и описания ее Леонардо Пизанским Фибоначчи (1170-1250). ФСС относится к позиционным системам. Алфавитом ФСС являются цифры 0 и 1, а ее базисом — последовательность чисел Фибоначчи 1, 2, 3, 5, 8, 13, 21, 34, 55, 89 … . Обратите внимание, что F0 = 1 в базис не включается. В табл. перечислены некоторые числа в двоичной и фибоначчиевой системах счисления.
Фибоначчиева система является разновидностью двоичной системы — ее алфавит составляют цифры 0 и 1. Следовательно, эту неклассическую двоичную систему счисления, вообще говоря, можно использовать для кодирования информации в компьютере, так как элементная база современной компьютерной техники ориентирована на обработку двоичных последовательностей. Избыточность ФСС проявляется в различных кодовых представлениях одного и того же числа. 4.1. Алгоритмы перевода целых чисел из ФСС в десятичную систему и обратно Как известно, все позиционные системы устроены одинаково и, следовательно, перевод из любой позиционной системы счисления в десятичную осуществляется по одному и тому же алгоритму. В P-ичных системах счисления базис является геометрической прогрессией. Вклад в значение числа цифры a, стоящей на k-м месте слева, равен a-Pk, где P — основание системы счисления. Часто говорят, что “вес” k-го разряда равен Pk. В ФСС “вес” каждого разряда числа также определяется базисом этой системы. Для удобства дальнейшей работы выпишем “веса” первых 10 разрядов ФСС (нумерацию разрядов ведем справа налево, начиная с первого). Такая нумерация разрядов удобна, поскольку в качестве веса k-го разряда используется k-е число Фибоначчи.
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

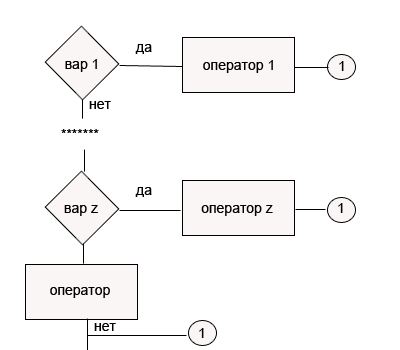
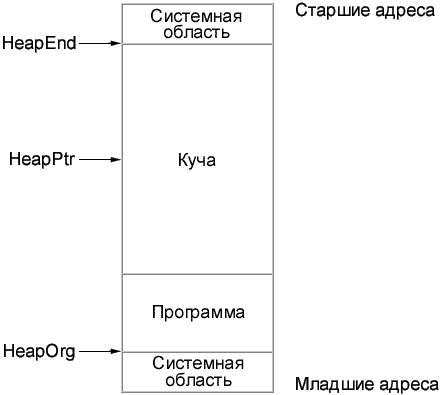
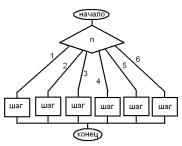
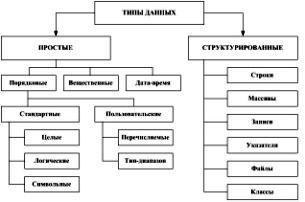
 Символ
«Цикл» служит для обозначения
конструкций WHILE-DO и REPEAT-UNTIL. Изображенный
внутренним прямоугольником процесс
повторяется некоторое число раз либо
пока выполняется некоторое условие
(WHILE), либо до тex пор пока не выполнится
некоторое условие (UNTIL). Затем управление
выходит из нижней стороны внешнего
прямоугольника. Условие окончания
цикла размещается в верхней полосе
внешнего прямоугольника для цикла
WHILE-DO и в нижней полосе – для
цикла REPEAT-UNTIL. Горизонтальная линия
внутри символа показывает место
проверки условия завершения цикла – в
его начале для цикла WHILE-DO и в его конце
для цикла REPEAT-UNTIL.ПОНЯТИЕ
АЛГОРИТМИЧЕСКОГО ЯЗЫКАДостаточно
распространенным способом представления
алгоритма является его запись на
алгоритмическом языке, представляющем
в общем случае систему обозначений и
правил для единообразной и точной
записи алгоритмов и исполнения их.
Под исполнителем в алгоритмическом
языке может подразумеваться не только
компьютер, но и устройство для работы
«в обстановке». Программа, записанная
на алгоритмическом языке, не обязательно
предназначена компьютеру. Как и каждый
язык, алгоритмический язык имеет свой
словарь. Основу этого словаря составляют
слова, употребляемые для записи команд,
входящих в систему команд исполнителя
того или иного алгоритма. Такие команды
называют простыми командами. В
алгоритмическом языке используют
слова, смысл и способ употребления
которых задан раз и навсегда. Эти слова
называют служебными. Использование
служебных слов делает запись алгоритма
более наглядной, а форму представления
различных алгоритмов - единообразной.При
построении новых алгоритмов могут
использоваться алгоритмы, составленные
ранее. Алгоритмы, целиком используемые
в составе других алгоритмов, называют
вспомогательными алгоритмами.
Вспомогательным может оказаться любой
алгоритм из числа ранее составленных.
Не исключается также, что вспомогательным
в определенной ситуации может оказаться
алгоритм, сам содержащий ссылку на
вспомогательные алгоритмы.Очень часто
при составлении алгоритмов возникает
необходимость использования в качестве
вспомогательного одного и того же
алгоритма, который к тому же может
быть весьма сложным и громоздким. Было
бы нерационально, начиная работу,
каждый раз заново составлять и
запоминать такой алгоритм для его
последующего использования. Поэтому
в практике широко используют, так
называемые, встроенные (или стандартные)
вспомогательные алгоритмы, т.е. такие
алгоритмы, которые постоянно имеются
в распоряжении исполнителя. Обращение
к таким алгоритмам осуществляется
так же, как и к «обычным» вспомогательным
алгоритмам. У исполнителя-робота
встроенным вспомогательным алгоритмом
может быть перемещение в склад из
любой точки рабочего поля; у
исполнителя-язык программирования
Бейсик это, например, встроенный
алгоритм «SIN».Алгоритм может содержать
обращение к самому себе как
вспомогательному и в этом случае его
называют рекурсивным. Если команда
обращения алгоритма к самому себе
находится в самом алгоритме, то такую
рекурсию называют прямой. Возможны
случаи, когда рекурсивный вызов данного
алгоритма происходит из вспомогательного
алгоритма, к которому в данном алгоритме
имеется обращение. Такая рекурсия
называется косвеннойАлгоритмы, при
исполнении которых порядок следования
команд определяется в зависимости от
результатов проверки некоторых
условий, называют разветвляющимися.
Для их описания в алгоритмическом
языке используют специальную составную
команду - команда ветвления. Она
соответствует блок-схеме «альтернатива»
и также может иметь полную или
сокращенную формуАлгоритмы, при
исполнении которых отдельные команды
или серии команд выполняются
неоднократно, называют циклическими.
Для организации циклических алгоритмов
в алгоритмическом языке используют
специальную составную команду цикла.
Символ
«Цикл» служит для обозначения
конструкций WHILE-DO и REPEAT-UNTIL. Изображенный
внутренним прямоугольником процесс
повторяется некоторое число раз либо
пока выполняется некоторое условие
(WHILE), либо до тex пор пока не выполнится
некоторое условие (UNTIL). Затем управление
выходит из нижней стороны внешнего
прямоугольника. Условие окончания
цикла размещается в верхней полосе
внешнего прямоугольника для цикла
WHILE-DO и в нижней полосе – для
цикла REPEAT-UNTIL. Горизонтальная линия
внутри символа показывает место
проверки условия завершения цикла – в
его начале для цикла WHILE-DO и в его конце
для цикла REPEAT-UNTIL.ПОНЯТИЕ
АЛГОРИТМИЧЕСКОГО ЯЗЫКАДостаточно
распространенным способом представления
алгоритма является его запись на
алгоритмическом языке, представляющем
в общем случае систему обозначений и
правил для единообразной и точной
записи алгоритмов и исполнения их.
Под исполнителем в алгоритмическом
языке может подразумеваться не только
компьютер, но и устройство для работы
«в обстановке». Программа, записанная
на алгоритмическом языке, не обязательно
предназначена компьютеру. Как и каждый
язык, алгоритмический язык имеет свой
словарь. Основу этого словаря составляют
слова, употребляемые для записи команд,
входящих в систему команд исполнителя
того или иного алгоритма. Такие команды
называют простыми командами. В
алгоритмическом языке используют
слова, смысл и способ употребления
которых задан раз и навсегда. Эти слова
называют служебными. Использование
служебных слов делает запись алгоритма
более наглядной, а форму представления
различных алгоритмов - единообразной.При
построении новых алгоритмов могут
использоваться алгоритмы, составленные
ранее. Алгоритмы, целиком используемые
в составе других алгоритмов, называют
вспомогательными алгоритмами.
Вспомогательным может оказаться любой
алгоритм из числа ранее составленных.
Не исключается также, что вспомогательным
в определенной ситуации может оказаться
алгоритм, сам содержащий ссылку на
вспомогательные алгоритмы.Очень часто
при составлении алгоритмов возникает
необходимость использования в качестве
вспомогательного одного и того же
алгоритма, который к тому же может
быть весьма сложным и громоздким. Было
бы нерационально, начиная работу,
каждый раз заново составлять и
запоминать такой алгоритм для его
последующего использования. Поэтому
в практике широко используют, так
называемые, встроенные (или стандартные)
вспомогательные алгоритмы, т.е. такие
алгоритмы, которые постоянно имеются
в распоряжении исполнителя. Обращение
к таким алгоритмам осуществляется
так же, как и к «обычным» вспомогательным
алгоритмам. У исполнителя-робота
встроенным вспомогательным алгоритмом
может быть перемещение в склад из
любой точки рабочего поля; у
исполнителя-язык программирования
Бейсик это, например, встроенный
алгоритм «SIN».Алгоритм может содержать
обращение к самому себе как
вспомогательному и в этом случае его
называют рекурсивным. Если команда
обращения алгоритма к самому себе
находится в самом алгоритме, то такую
рекурсию называют прямой. Возможны
случаи, когда рекурсивный вызов данного
алгоритма происходит из вспомогательного
алгоритма, к которому в данном алгоритме
имеется обращение. Такая рекурсия
называется косвеннойАлгоритмы, при
исполнении которых порядок следования
команд определяется в зависимости от
результатов проверки некоторых
условий, называют разветвляющимися.
Для их описания в алгоритмическом
языке используют специальную составную
команду - команда ветвления. Она
соответствует блок-схеме «альтернатива»
и также может иметь полную или
сокращенную формуАлгоритмы, при
исполнении которых отдельные команды
или серии команд выполняются
неоднократно, называют циклическими.
Для организации циклических алгоритмов
в алгоритмическом языке используют
специальную составную команду цикла.