

ээээээ ээээээээээээээээ
.pdfi, j: ^integer;
r: ^real;
begin
New(i);
. . . . .
end. После выполнения этого фрагмента указатель i приобретет значение, которое перед этим имел указатель кучи HEAPPTR, а сам HEAPPTR увеличит свое значение на 2, так как длина внутреннего представления типа INTEGER, с которым связан указатель i, составляет 2 байта (на самом деле это не совсем так: память под любую переменную выделяется порциями, кратными 8 байтам). Оператор
new(r);вызовет еще раз смещение указателя HEAPPTR, но теперь уже на 6 байт, потому что такова длина внутреннего представления типа REAL. Аналогичным образом выделяется память и для переменной любого другого типа. После того как указатель приобрел некоторое значение, т.е. стал указывать на конкретный физический байт памяти, по этому адресу можно разместить любое значение соответствующего типа. Для этого сразу за указателем без каких-либо пробелов ставится значок ^, например:
i^ := 2; {В область памяти i помещено значение 2}
r^ := 2*pi; {В область памяти r помещено значение 6.28}
Таким образом, значение, на которое указывает указатель, т.е. собственно данные, размещенные в куче, обозначаются значком ^, который ставится сразу за указателем. Если за указателем нет значка ^, то имеется виду адрес, по которому размещены данные. Имеет смысл еще раз задуматься над только что сказанным: значением любого указателя является адрес, а чтобы указать, что
речь идет не об адресе, а о тех данных, которые размещены по этому адресу, за указателем ставится ^. Если Вы четко уясните себе это, у Вас не будет проблем при работе с динамической памятью.
Динамически размещенные данные можно использовать в любом месте программы, где это допустимо для констант и переменных соответствующего типа, например:
r^ := sqr(r^) + i^ - 17;
Разумеется, совершенно недопустим оператор
r := sqr(r^) + i^ - 17;
так как указателю R нельзя присвоить значение вещественного выражения. Точно так же недопустим оператор
r^ := sqr(r);
поскольку значением указателя R является адрес, и его (в отличие от того значения, которое размещено по этому адресу) нельзя возводить в квадрат. Ошибочным будет и такое присваивание:
r^ := i;
так как вещественным данным, на которые указывает R, нельзя присвоить значение указателя (адрес).
Динамическую память можно не только забирать из кучи, но и возвращать обратно. Для этого используется процедура DISPOSE. Например, операторы
dispose(r);
dispose(i);
вернут в кучу 8 байт, которые ранее были выделены указателям I и R.
Отметим, что процедура DISPOSE(PTR) не изменяет значения указателя PTR, а лишь возвращает в кучу память, ранее связанную с
этим указателем. Однако повторное применение процедуры к свободному указателю приведет к возникновению ошибки периода исполнения. Освободившийся указатель программист может пометить зарезервированным словом NIL. Помечен ли какой-либо указатель или нет, можно проверить следующим образом:
const
р: ^real = NIL;
begin
. . . . .
if р = NIL then
new(p);
. . . . .
dispose(p);
p := NIL;
. . . . .
end.
Никакие другие операции сравнения над указателями не разрешены. Приведенный выше фрагмент иллюстрирует предпочтительный способ объявления указателя в виде типизированной константы с одновременным присвоением ему значения NIL. Следует учесть, что начальное значение указателя (при его объявлении в разделе переменных) может быть произвольным. Использование указателей, которым не присвоено значение процедурой NEW или другим способом, не контролируется системой и может привести к непредсказуемым результатам. Чередование обращений к
процедурам NEW и DISPOSE обычно приводит к ╚ячеистой╩ структуре памяти. Дело в том, что все операции с ней выполняются под управлением особой подпрограммы, которая называется администратором кучи. Она автоматически пристыковывается к нашей программе компоновщиком Турбо Паскаля и ведет учет всех сводных фрагментов в куче. При очередном обращении к процедуре NEW эта подпрограмма отыскивает наименьший свободный фрагмент, в котором еще может разместиться требуемая переменная. Адрес начала найденного фрагмента возвращается в указателе, а сам фрагмент или его часть нужной длины помечается как занятая часть кучи.
Другая возможность состоит в освобождении целого фрагмента кучи. С этой целью перед началом выделения динамической памяти текущее значение указателя HEAPPTR запоминается в переменной-указателе с ющью процедуры MARK. Теперь можно в любой момент освободить фрагмент кучи, начиная от того адреса, который запомнила процедура MARК, и до конца динамической памяти. Для этого используется процедура RELEASE. Например:
var
p,p1,p2,р3,р4,р5: ^integer;
begin
new(p1);
new(p2);
mark(p);
new(p3);
new(p4);
new(p5);

. . . . .
release(p);
end.
В этом примере процедурой MARK(P) в указатель Р было помещено тукущее значение HEAPPTR, однако память под переменную не резервировалась.
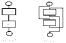
Обращение RELEASE(P) освободило динамическую память от помеченного места до конца кучи. Пирведенный ниже рисунок иллюстрирует механизм работы процедур NEW-DISPOSE и NEW- MARK-RELEASE для рассмотренного примера и для случая, когда вмемто оператора RELEASE(P) используется, например, DISPOSE(P3).
а) |
б) |
в) |
Состояние динамической памяти:
а) перед освобождением; б) после Dispose(p3); в) после Release(p)Следует учесть, что вызов RELEASE уничтожает список свободных фрагментов в куче, созданных до этого
процедурой DISPOSE, поэтому совместное использование обоих механизмов освобождения памяти в рамках одной программы не рекомендуется.
22. язык программирования алфавит, синтаксис ,лексема, семантика.Комментарии , пространство имен,ключевые слова.
Основными элементами любого языка программирования являются его алфавит, синтаксис и семантика. Алфавит – совокупность символов, отображаемых на устройствах печати и экранах и/или вводимых с клавиатуры терминала. Лексика – совокупность правил образования цепочек символов (лексем), образующих идентификаторы (переменные и метки), операторы,
операции и другие лексические компоненты языка. Сюда же включаются зарезервированные (запрещенные, ключевые) слова языка программирования, предназначенные для обозначения операторов, встроенных функций и пр. Иногда эквивалентные лексемы, в зависимости от языка программирования, могут обозначаться как одним символом алфавита, так и несколькими. Например, операция присваивания значения в языке Си обозначается как «=», а в языке Паскаль – «:=». Операторные скобки в языке Си задаются символами «{» и «}», а в языке Паскаль
– begin и end. Граница между лексикой и алфавитом, таким образом, является весьма условной, тем более что компилятор обычно на фазе лексического анализа заменяет распознанные ключевые слова внутренним кодом (например, begin – 512, end – 513) и в дальнейшем рассматривает их как отдельные символы. Синтаксис – совокупность правил образования языковых конструкций, или предложений языка программирования – блоков, процедур, составных операторов, условных операторов, операторов цикла и пр. Особенностью синтаксиса является принцип вложенности (рекурсивность) правил построения конструкций. Это значит, что элемент синтаксиса языка в своем определении прямо или косвенно в одной из его частей содержит сам себя. Например, в определении оператора цикла телом цикла является оператор, частным случаем которого является все тот же оператор цикла.Необходимо строгое соблюдение правил правописания (синтаксиса) программы. В частности, в Паскале однозначно определено назначение знаков пунктуации. Точка с запятой (;) ставится в конце заголовка программы, в конце раздела описания переменных, после каждого оператора. Перед словом End точку с запятой можно не ставить. Запятая (,) является разделителем элементов во всевозможных списках: списке переменных в разделе описания, списке вводимых и выводимых величин.В БНФ(формула Бекуса – Наура) всякое синтаксическое понятие
описывается в виде формулы, состоящей из правой и левой части, соединенных знаком ::=, смысл которого эквивалентен словам «по определению есть». Слева от знака ::= записывается имя определяемого понятия (метапеременная), которое заключается в угловые скобки <>, а в правой части записывается формула или диаграмма, определяющая все множество значений, которые может принимать метапеременная. Синтаксис языка описывается путем последовательного усложнения понятий: сначала определяются простейшие (базовые), затем все более сложные, включающие в себя предыдущие понятия в качестве составляющих.
В записях метаформул приняты определенные соглашения. Например, формула БНФ, определяющая понятие «двоичная цифра», выглядит следующим образом: <двоичная цифра>::=0|1 Значок «|» эквивалентен слову «или».В диаграммах стрелки указывают на последовательность расположения элементов синтаксической конструкции; кружками обводятся символы, присутствующие в конструкции.Понятие «двоичный код» как непустую последовательность двоичных цифр БНФ описывает так:<двоичный код>::=<двоичная цифра>| <двоичныйкод><двоичная цифра>Определение, в котором некоторое понятие определяется само через себя, называется рекурсивным. Рекурсивные определения характерны для БНФ.Возвратная стрелка обозначает возможность многократного повторения. Очевидно, что диаграмма более наглядна, чем БНФ.Синтаксические диаграммы были введены Н. Виртом и использованы для описания созданного им языка Паскаль.Семантика – смысловое содержание конструкций, предложений языка, семантический анализ – это проверка смысловой правильности конструкции. Например, если мы в выражении используем переменную, то она должна быть определена ранее по тексту программы, а из этого определения может быть получен ее тип. Исходя из типа переменной, можно
говорить о допустимости операции с данной переменной. Семантические ошибки возникают при недопустимом использовании операций, массивов, функций, операторов и пр. Пространство имён — некоторое множество, под которым подразумевается модель, абстрактное хранилище или окружение, созданное для логической группировки уникальных идентификаторов (то
есть имён). Идентификатор, определенный в пространстве имён, ассоциируется с этим пространством. Один и тот же идентификатор может быть независимо определён в нескольких пространствах. Таким образом, значение, связанное с идентификатором, определённым в одном пространстве имён, может иметь (или не иметь) такое же значение, как и такой же идентификатор, определённый в другом пространстве. Языки с поддержкой пространств имён определяют правила, указывающие, к какому пространству имён принадлежит идентификатор (то есть его определение). Например, Андрей работает в компании X, а ID (сокр. от англ. Identifier — идентификатор) его
как работника равен 123. Олег работает в компании Y, а его ID также равен 123. Единственное (с точки зрения некой системы учёта), благодаря чему Андрей и Олег могут быть различимы при совпадающих ID, это их принадлежность к разным компаниям. Различие компаний в этом случае представляет собой систему различных пространств имён (одна компания — одно пространство). Наличие двух работников в компании с одинаковыми ID представляет большие проблемы при их использовании, например, по платёжному чеку, в котором будет указан работник с ID 123, будет весьма затруднительно определить работника, которому этот чек предназначается.
В больших базах данных могут существовать сотни и тысячи идентификаторов. Пространства имён (или схожие структуры) реализуют механизм для сокрытия локальных идентификаторов.
Их смысл заключается в группировке логически связанных идентификаторов в соответствующих пространствах имён, таким образом делая систему модульной.
Ограничение видимости переменных может также производиться путём задания класса её памяти. Операционные системы, многие современные языки программирования обеспечивают поддержку своей модели пространств имён: используют каталоги (или папки) как модель пространства имён. Это позволяет существовать двум файлам с одинаковыми именами (пока они находятся в разных каталогах). В некоторых языках программирования (например, C+ +, Python) идентификаторы имён пространств сами ассоциированы с соответствующими пространствами. Поэтому в этих языках пространства имён могут вкладываться друг в друга, формируя дерево пространств имён. Корень такого дерева называется глобальным пространством имён.
4)Линейный алгоритм
Изучение алгоритмических конструкций начнем с линейного алгоритма. В учебниках иногда используется термин «следование».
Алгоритм назовем линейным, если:1) выполняется каждый его шаг, и 2) только один раз.
Такого определения вполне достаточно. В некоторых учебниках используются слова «шаги выполняются последовательно, друг за другом», но эти слова означают наличие некоторого порядка. А порядков имеется два!
Одним из свойств алгоритма является, что его можно использовать двояко: либо исполнить, либо записать по определенным правилам. Таким образом первый порядок – порядок исполнения
команд, второй – порядок написания. Эти порядки могут не совпадать.
На рисунке слева – случай, когда порядок написания и порядок исполнения совпадают, справа – эти порядки различны. Может показаться, что на рисунке справа алгоритм не линеен, так как команды выполняются не «друг за другом», а сначала вторая, потом первая. Но если определить линейный алгоритм как указано выше - Алгоритм линейный, если выполняется каждый его шаг, и только один раз – то эта проблема снимается.
Линеен алгоритм обмена, алгоритмы деления угла или отрезка пополам и многие другие.
Ветвление неполное
Вернемся к нашему определению линейного алгоритма и попытаемся определить остальные алгоритмические структуры.
Для начала, откажемся от требования 1), обязательности выполнения каждого шага алгоритма.
Имеем алгоритм, в котором некоторые шаги могут не выполняться.
Получившаяся структура алгоритма называется. НЕПОЛНОЕ ВЕТВЛЕНИЕ
Согласно принципу детерминированности алгоритмов, исполнитель должен знать, выполнять отмеченный шаг или нет. Приходится ввести понятие «условие», то есть предложение, значение которого либо «истина», либо «ложь».
Если условие истинно – шаг алгоритма выполняется, иначе – нет.