

// Основные понятия об управлении. Понятие об управлении.
Управление - это деятельность по организации какого-либо процесса, которая обеспечивает достижение поставленных целей. Составные элементы процесса управления.
Процесс управления состоит из следующих 4-х элементов управления:
1) Получение информации о задачах управления (цель);
2) Получение информации о результатах управления;
3) Анализ полученной информации и выработка решения;
4) Исполнение решения, т.е. осуществление управляющих действий.
Отметим, что субстратом (основой) процессов управления является информация.
Решение - это некое предписание к действию для объекта управления.
Принятие решения - выбор наилучшего в некотором смысле варианта решения.
Для управления необходимо иметь:
1) Источник информации о задачах (целях) управления,
2) Источник информации о результатах управления,
3) Устройство для анализа полученной информации и выработки решения,
4) Исполнительные устройства, реализующие управляющие действия.
Обобщенная схема автоматической (автоматизированной) системы управления.
 Понятие
системы управления.
Понятие
системы управления.
Система управления (СУ) - это совокупность управляемого объекта и управляющей подсистемы, взаимодействующих между собой в соответствии с алгоритмом управления.
Схема автоматической (автоматизированной) системы управления. // Информационные основы управления.
Свойства информации, перечислить, пояснить.
Информация обладает различными свойствами, например, такими:
1) количество (мера воздействия на решения человека),
2) значимость (влияние на качество принимаемых решений),
3) адекватность (соответствие отображаемому объекту или процессу),
4) достоверность (неискаженность информации, отсутствие ошибок),
5) актуальность (своевременность внесения изменений, корректировки),
6) объем (количество информационных знаков, текста...),
7) релевантность (степень удовлетворения полученной информации сформулированной потребности),
8) стоимость (цена получения информации),
9) товар (потребительская стоимость),
10) собственность (интеллектуальная и в смысле владения),
11) информация как ресурс.
Семиотика, составные части семиотики - синтактика, семантика, прагматика.
Семиотика - теория знаковых систем, она исследует знаки как особый вид носителей информации. Составные части семиотики:
Синтактика - изучает формальные отношения между знаками независимо от содержания и ценности передаваемой информации. Она исследует структурные свойства информации.
Семантика - рассматривает отношения между знаками и отображаемыми объектами, ее интересует содержание информации, т.е. смысл, соответствие отображаемому объекту. Прагматика - исследует отношения между знаками и их потребителями, т.е. вопросы полезности и ценности информации.
 Определение
информации, данных. Характеристики
данного.
Реквизит -
наименьшая единица данных, имеющая
смысл при описании информации, наименьшая
единица поименованных данных.
Определение
информации, данных. Характеристики
данного.
Реквизит -
наименьшая единица данных, имеющая
смысл при описании информации, наименьшая
единица поименованных данных.
Данное - наименьшая семантическая единица информации.
Данное - элемент некоторого информационного множества.
Синонимы: Реквизит, поле, элемент данных, данное, атрибут, признак, терм. Характеристики реквизита(данного): 1) Наименование поля
2) Идентификатор (имя)
3) Тип поля
4) Размер поля
5) Класс значений
6) Свойство ограничения
7) Свойство интерпретации
8) Структура поля (описание значений поля в зависимости от частей поля).
9) Используемый алфавит.
10) Атрибуты поля.
Дать определения и привести примеры: наименование поля, идентификатор поля, структура поля. 1) Наименование поля - название поля, выражающее смысл и содержание поля.
Наименование поля используется при проектировании и эксплуатации информационных систем, об-щении специалистов в процессе обработки информации.
Примеры:
В базе данных “Сотрудники” содержатся следующие поля:
“Табельный номер”,
“Фамилия, имя, отчество”,
“Дата рождения”,
“Оклад”,
”Код подразделения”,
“Признаки обработки”. 2) Идентификатор (имя) - это метка поля, используемая в языках программирования, описаниях по-лей в СУБД, языках запросов и других средствах и образованная в соответствии с правилами языка.
Примеры:
Описание поля в СУБД IMS:
FIELD NAME=FIO,BYTES=25,START=1,TYPE=C
В приведенном описании поля идентификатором является метка “FIO”, размер поля 25 байт, тип поля - символьный и поле начинается с 1-й позиции записи.
Описание поля на языке программирования PASCAL:
FioSt : string[45]; {Фамилия, имя, отчество сотрудника}
В этом описании поля идентификатором является метка “FioSt”, размер поля 45 байт, поле имеет строковый тип (содержит строку символов). Наименование поля приведено в комментарии в фигурных скобках.
3)Тип поля - вид значений, которые может принимать это поле. Является одной из важнейших структурных характеристик поля.
Типы поля могут быть:
а) числовое,
б) текстовое,
в) битовое,
г) логическое,
д) образ (изображение, звук).
Кроме перечисленных типов данных могут быть и другие. Например, перечислимый тип, значениями которого являются элементы некоторого множества; ссылочный тип, значениями которого являются указатели, адреса, ссылки на другие данные, и т.д.
3.1.Числовое поле выражает количественные характеристики объектов и явлений. В зависимости от конкретной реализации поля в вычислительной среде форматы представления числовых полей могут быть следующими:
- целое;
- вещественное (с плавающей точкой, с фиксированной запятой);
- десятичное;
- шестнадцатеричное;
- восьмеричное;
- двоичное.
3.2.Текстовый тип поля выражает свойства объектов и явлений в виде текста. Текстовые поля могут быть алфавитными (значения поля содержат только буквы алфавита) и алфавитно-цифровыми (буквы, цифры и другие знаки может содержать значение поля).
Например, текстовое поле “Фамилия” содержит алфавитную информацию, а текстовое поле “Адрес” содержит алфавитно-цифровую.
3.3.Битовый тип поля выражает состояние объектов и явлений по принципу “да/нет” и отображается в ЭВМ некоторым набором бит.
3.4.Логическое поле выражает состояние свершения некоторого события в терминах логики, а именно двух состояний “истина” и “ложь”.
3.5.Тип поля “образ” (изображение, звук) содержит значения, которые позволяют воспроизвести некоторый образ (изображение) с помощью СВТ, например, изображение пиктограмм. Аналогично, в качестве значения можно использовать “звук”, т.е. цифровые значения, преобразуемые в звук. В ряде СУБД, например, “Interbase” появился термин BLOB (binary large object) для такого типа полей. Обычно этот тип поля представлен двоичным числом большой длины от нескольких байт до сотен и тысяч байт.
Тип поля важнейшая характеристика в обработке данных, от которой зависят эксплуатационные параметры информационных систем. При определении типа поля необходимо учитывать возможные последствия выбора того или иного типа и проблемы преобразования типов полей в информационной системе.
Дать определения и привести примеры: используемый алфавит, схема (шаблон) поля.
1) Используемый алфавит.
Алфавит - множество символов, принятых в рамках некоторого языка.
В информационных системах может быть использовано несколько языков. В России используется, как правило, русский язык. При использовании разных языков в информационной системе могут возник-нуть существенные проблемы, например, при отображении информации, при сортировке данных и т.д.
Размер алфавита влияет на информационную емкость системы.
В информационной системе используется понятие допустимого алфавита, когда из всего множества символов алфавита выбирается некоторое подмножество. Например, подмножество прописных букв.
Алфавит может отображаться в ЭВМ различными способами. Разработан ряд стандартов (ДКОИ-8, КОИ-8, КОИ-7, МТК, ASCII, EBCDIC, Unicode и др.) как в России, так и за рубежом на отображение сим-волов в ЭВМ. Для разных устройств вычислительной техники и связи могут применяться разные наборы символов и их кодовые значения. В технических руководствах на устройства указываются применяемые стандарты для кодов. При работе в разнородных вычислительных сетях, распределенных информационных системах может потребоваться преобразование кодов, например, кодов ASCII в коды EBCDIC и обратно, машинных слов одной ЭВМ в машинные слова другого типа ЭВМ. 2) Схема (шаблон) поля: принятое в языке или системе описание поля, отражающее его характеристики.
Дать определения и привести примеры: структура данных, группа, запись, размер записи.
Под структурой данных понимается совокупность данных, связанных некоторыми отношениями, расположенных в определенном порядке и с определенной (приписанной, назначенной) смысловой нагрузкой на те или иные данные.
Примеры.
1)Пусть есть некоторые сведения об объекте “Гражданин”:
Фамилия и.о., дата рождения, место рождения, место проживания.
Эта совокупность данных может быть представлена в линейной структуре, данные в структуре объединены одним отношением - принадлежностью к одному гражданину, а данное “Фамилия и.о.” имеет дополнительную смысловую нагрузку и используется в качестве ключа при поиске и обработке информации по конкретному гражданину.
|
Фамилия и.о. |
Дата рождения |
Место рождения |
Место проживания |
2)Если вышеприведенные данные рассматривать в контексте родства граждан, то структура данных может иметь другой вид, например, иерархическую структуру:
“Гражданин”
|
Фамилия и.о. |
Дата рождения |
Место рождения |
Место проживания |



“Дети”

|
Фамилия и.о. |
Дата рождения |
Место рождения |
Место проживания |
Группа - поименованная совокупность данных.
Синонимы - агрегат данных, сегмент данных, структура данных.
Данные в группы объединяются по различным признакам, например, по принципу целесообразности, взаимно-однозначного соответствия и другим соображениям.
Группы могут быть простые, например, группа “дата” состоит из полей “год”, “месяц”, “день”, группа "адрес" состоит из полей "область", "город", "улица", "дом", "квартира".
Сложные группы - это совокупность ряда простых групп и данных. Например, в составе информации зачетной книжки студента можно выделить ряд групп. Группа “Общие сведения” включает фамилию, имя, отчество студента, факультет, специальность, приказ о зачислении. Группа “Теоретический курс, экзамены” включает поля “номер семестра”, “наименование дисциплины”, “фамилия преподавателя”, “отметка”, “дата экзамена” и т.д.
Пример группы.
Представим группу в условной нотации, где имя группы отделено точкой от перечня полей группы, заключенных в скобки:
Адрес.(область, город, улица, дом, квартира)
Дата.(день, месяц, год)
Товар.(код товара, наименование, стоимость)
Лицо.(фамилия, имя, отчество)
Сложные группы.
Адресат.(лицо, адрес)
Грузополучатель.(товар, адресат)
Пример записи. Сведения о сотрудниках:
|
№ п/п |
Наименование поля |
Тип, размер |
Запись на языке ПЛ/1 |
|
|
Сведения о сотрудниках |
Запись |
DCL 1 COTP, |
|
1 |
Табельный номер |
9(5) |
2 TN PIC’9(5)’, |
|
2 |
Фамилия, имя, отчество (ФИО) |
A(30) |
2 FIO CHAR(30), |
|
3 |
Дата рождения |
9(8) |
2 DTR PIC’9(8)’, |
|
4 |
Образование |
9 |
2 OBR PIC’9’, |
|
5 |
Дата приема на работу |
9(8) |
2 DTP PIC’9(8)’ |
|
6 |
Должность |
X(20) |
2 DOL CHAR(20), |
|
7 |
Оклад |
9(7) |
2 OKLAD PIC’9(7)’, |
|
8 |
Номер отдела |
99 |
2 NOTD PIC’99’. |
Обычно, по смысловой нагрузке выделяют ФИО в качестве ключа. По этому полю осуществляется сортировка и поиск записи. В качестве ключевого поля может быть и “табельный номер”. Вид структуры данных (линейная):
COTP
|
TN |
FIO |
DTR |
OBR |
DTP |
DOL |
OKLAD |
NOTD |
Запись - поименованная совокупность данных, обладающая определенной завершенностью в описании конкретного класса объектов. Запись отражает объект, а значения полей записи содержат характеристики конкретных объектов. Понятие записи является одним из фундаментальных среди информационных структур. В качестве эквивалентных понятию записи терминов могут использоваться понятия “логическая запись”, “запись базы данных” и т.п. Пример записи. “Конструкторский документ”.
Пусть на предприятии имеются конструкторские документы (КД). Эти документы могут быть выполнены в нескольких экземплярах. Причем один из экземпляров является контрольным, другой архивным, а остальные используются в работе или находятся в архиве до их востребования. В общем виде структура записи имеет вид:
Конструкторский документ.
|
Обозначение КД |
Наименование КД |
Код разработчика |

Экземпляр КД

|
№ экземпляра КД |
Дата поступления КД |
Местонахождение КД |
Назначение экз. КД |
Представленная структура является иерархической, а количество данных в записи будет различным для разных документов.
Длина (размер) записи - это сумма размеров всех полей записи.
Записи могут иметь:
1) фиксированную длину,
2) переменную длину,
3) неопределенную длину.
Размер записи определяется как средняя величина:
 где ɭ - длина записи,n –
количество записей
где ɭ - длина записи,n –
количество записей
Дать определения и привести примеры: ключ, уникальный ключ, неуникальный ключ, сцепленный.
Ключ - это поле, используемое для идентификации или определения местонахождения записи (или других группировок данных). Идентификатор объекта рассматривается как ключ записи или группы записей. Ключ может быть уникальным, т.е. однозначно определяющим запись, или неуникальным, если с заданным значением ключа может быть несколько записей.
В качестве ключа могут быть использованы несколько полей, соединенных логическим союзом "И". Такой ключ называют сцепленным.
При описании логической и физической структуры данных ключи определяются, как правило, явно.
Дать определения и привести примеры: показатель, основание показателя, реквизиты-признаки.
Показатель - это единица информации, состоящая из одного реквизита числового типа, именуемого основанием показателя, отражающего тот или иной факт в количественной оценке, и ряда характеризующих его и связанных с ним логическими отношениями реквизитов-признаков (например, времени, места действия, действующих лиц, предметов и т.д.).
Показатель - это семантическая единица информации, логически завершенная.
Общий вид показателя:
П. (Р1, Р2, . . . , Рn, Q)
где: Р1, Р2, ..., Рi, ..., Рn - реквизиты-признаки;
Q - основание показателя.
Показатель - термин, которым оперируют в области экономики, статистики.
Показатель - это совокупность данных прагматического характера.
Пример. Численность постоянного населения Республики Карелия на 01.01.1994 года - 798 тыс. чел. Основание показателя - численность, значение 798. Реквизиты-признаки: 1)Территория - код 86 (Республика Карелия), 2)Дата - 01.01.1994г.
Численность постоянного населения Республики Карелия на 01.01.2004 г. – 708,7 тыс. чел., а на 01.01.2011 года – 644,2 тыс. чел.
Дать определения и привести примеры: список, "сборка мусора".
Список, списковая структура - это совокупность данных, для которых отношение следования (порядок) определено с помощью специальных адресов связи (ссылок).
Синонимы: Ссылка, указатель, адрес связи.
Изображение элементов списка:
ссылка
1)
совместное хранение ссылок и данных;

данные
Ссылка на следующий
элемент списка
Раздельное хранение


2) ссылок и данных
Ссылка на данные

Данные
(поле)
Начало списка Конец списка
. . .
Начало
Ссылка
Ссылка
Ссылка
Конец





Поле 1
Поле 2
Поле 3
Поле n
Терминатор (синоним ограничитель) - это указатель, который обозначает конец списка. Он может быть реализован несколькими способами. Наиболее распространены следующие варианты терминатора:
1)Адрес со специальным значением, как правило, 0 или Null.
2)Адрес, равный адресу начала списка (т.е. ссылка на начало списка означает последний элемент списка).
Списки простые - списки, представленные линейной последовательностью элементов списка, без ответвлений ссылок от элементов списка.
Сложные списки - это списки, которые можно представить как совокупность более простых списков (подсписков). Из отдельных элементов списка могут исходить несколько подсписков.
Однонаправленные списки - это такие списки, когда ссылки идут в одну сторону, от начала к концу, т.е. можно найти последующий элемент списка, но нельзя вернутся к предыдущему по цепочке.
Двунаправленные списки - это списки, в которых ссылки организованы вперед и назад.
Древовидный список.
начальная вершина (корневая
вершина)
Сетевые структуры.


Операции обработки:
1) удаление информации,
2) вставка информации.
"Сборка мусора" - процесс выявления неиспользуемых элементов памяти (пространства) для последующего использования.
"Сборка мусора" - процесс сбора свободных участков памяти и, если необходимо, уплотнение пространства. Схема сборки мусора изображена ниже:
|
А1 |
свободно |
А2 |
свободно |
А3 |
свободно |
А4 |
|
Сбор
свободных участков



|
А1 |
А2 |
А3 |
А4 |
свободно |
Уплотнение |
Реорганизация базы данных - процесс приведения физической организации данных к некоторому исходному состоянию, при котором физическая последовательность данных соответствует логической и отсутствуют явления "мусора".
Дать определения и привести примеры: очередь, типы очередей.
Очередь - разновидность динамических структур данных, т.е. структур, используемых в момент обработки данных (в противоположность структурам хранения, хранение - статика).
Очередь- это упорядоченный набор данных (элементов), которые могут удаляться и помещаться в этот набор только с одного или другого конца этого набора, т.е. для обработки доступны первый и последний элемент.
конец
|
А |
В |
|
Х |
начало очереди 

Типы очередей:
на обработку

1) FIFO - first-in-first-out поступление
|
1 |
|
n |

на обработку 
2) LIFO - last-in-first-out (стек) поступление
|
1 |
|
n |

3) LIFIFO поступление поступление
|
1 |
|
n |


(last-in-or- first-in-first-out)



на обработку
Стек (магазин) - упорядоченный набор данных (элементов), все изменения (включения, удаления, доступ) в котором производятся только на одном конце набора.
Логические отношения между данными, Типы отношений. Привести примеры.
Логические отношения (взаимосвязи) определяют структуру данных. Поэтому построение структуры начинается с установления логических взаимосвязей данных.
Существует четыре типа логических отношений (связей):
1) одно-однозначное соответствие (1:1):
A <--> B
Это означает, что каждому значению (экземпляру) элемента А соответствует одно и только одно значение (экземпляр) элемента В.
Например, табельный номер TN - Фамилия FIO:
TN <--> FIO.
2) одно-многозначное соответствие (1:М):
A<->>B
Каждому значению поля А соответствует несколько значений поля В.
Например, Номер группы <->> ФИО студента.
Множество значений поля В, соответствующих значению поля А, может быть пустым (нет ни одного значения соответствующего значению поля А) или представлено одним, двумя или n значениями.
3) много-однозначное соответствие (М:1):
А<<->B
Например, ФИО студента <<-> Номер группы.
4) много-многозначное соответствие (М:М):
A<<->>B
Например, Изделие <<->> Покупатель.
Изделия
Покупатели
Изделие 1
Покупатель 1 Изделие 2
Покупатель 2 Изделие 3
Покупатель 3 Изделие 4
Покупатель 4 Изделие 5
Покупатель 5 Изделие 6
Покупатель 6 Изделие 7
Покупатель ... Изделие 8
Покупатель m Изделие ...
Изделие n

Первый этап.
1) составление списка всех полей (данных) для описания предметной области и их характеристик, в том числе, наименований, имен, типов, размеров полей;
2) установление логических связей между полями;
3) составление графа связей, образование групп полей, формирование записи, выделение ключей;
4) составление графического и словесного описания логической структуры данных;
5) описание логики взаимосвязи полей и содержания полей;
6) документирование в соответствии с принятыми соглашениями или ГОСТ.
В итоге получаем логическое представление данных.
Завершив первый этап логического проектирования, т.е. создав логическое описание, проводят уточнение структуры данных в зависимости от характера использования информации. На этом этапе логического структурирования выявляют (второй этап, этап уточнения):
1) периодичность и виды обработки информации и ее отдельных частей;
2) виды запросов к информации и возможность их разрешения,
3) вопросы безопасности, целостности, защиты, модифицируемости и другие возможные про-блемы обработки информации.
Далее, проводится редактирование логической схемы, ее реструктирование, усовершенствование.
В развитых СУБД имеются средства автоматизированного логического проектирования, ведения сло-варей данных, моделирования запросов и обработки данных. В качестве инструмента проектирования структур данных могут использоваться также системы CASE (Computer Aided System Engineering) - авто-матизированные системы структурного проектирования баз данных и ИС.
Перечислить характеристики совокупностей данных.
Базы данных (файлы, наборы данных) как некоторые совокупности данных обладают определенными характеристиками. Ряд характеристик аналогичен рассмотренным ранее, а ряд присущ базам данных как специфичной совокупности данных. Перечислим основные характеристики:
1) Наименование базы (файла),
2) Идентификатор (имя),
3) Структура (схема базы, логическая, физическая структура),
4) Класс объектов,
5) Размер (объем) базы (файла),
6) Целевой характер использования информации:
а) НСИ, классификаторы,
б) оперативная, постоянная,
в) входная, выходная,
г) первичная, промежуточная, результирующая,
7) Активность данных,
8) Выборочность,
9) Изменчивость,
10) Избыточность (дублирование),
11) Атрибуты (в том числе, атрибуты доступа),
12) и другие характеристики.
Дать определение и привести примеры: Размер (объем) базы данных (файла).
Объем (размер) базы - это сумма длин всех полей всех записей базы данных.
 (не уверена)
(не уверена)
где
 - длина поля j,
- длина поля j,
 - количество полей типа j в записи
i,
- количество полей типа j в записи
i,
m - количество полей в записи,
n - количество записей.
Дать определение и привести примеры: активность данных. Активность данных - это характеристика, определяемая отношением числа обращений к структурному элементу данных к общему числу обращений к информации (базе данных, файлу) в некоторый интервал времени или единицу работы.

где Rj - активность поля j,
kj - количество обращений к полю j,
ki - количество обращений к полю i,
1 =< i <= n, n - число полей записи.
Дать определение и привести примеры: избыточность данных.
Избыточность (дублирование) - это характеристика, определяемая отношением количества дублированных (повторившихся) данных (Vd) ко всему объему данных (V).
Kd = Vd/V
Чем ближе Kd к 0, тем лучше.
В рассмотренном выше примере данных об узлах и деталях, представленных двумя структурами данных - линейной и иерархической, хорошо иллюстрируется дублирование данных в линейной структуре (дублируются значения поля “узел” для разных деталей, входящих в один узел). В иерархической структуре дублирование полей отсутствует. Уровни обработки информации. Основные процедуры обработки массивов информации.
Обработка информации - это преобразование некоторого исходного множества данных в другое множество.
В процессах обработки информации можно выделить несколько уровней операций обработки данных, в том числе:
-операции над элементарными данными (обычно выполняются аппаратными средствами, командами, операторами и функциями языков и систем программирования);
-операции над группами (агрегатами, сегментами, записями) данных;
-операции с файлами, массивами, базами данных.
Выделяют следующие основные процедуры обработки данных:
- сортировка (упорядочение);
- выборка;
- слияние;
- поиск;
- корректировка;
- сжатие.
Процедура сортировки данных. Ключи сортировки. Виды сортировок. Оценка числа сравнений при сортировке.
Сортировка - это процесс обработки данных, с помощью которого записи в массиве (файле, наборе данных) информации располагаются в установленном порядке согласно принятому критерию. Например, такому критерию, как "по возрастанию (убыванию) значения поля Х в качестве ключа сортировки".
Упорядоченность - это порядок размещения записей относительно друг друга. Обычно упорядоченность осуществляется по наиболее важному полю, называемому ключом сортировки.
Например, телефонный справочник квартирных телефонов:
а) упорядочен по возрастанию фамилий, и.о.;
б) в тоже время относительно адреса - телефонная книга имеет достаточно случайный характер.
Ключ сортировки может быть составным, т.е. состоять из нескольких полей. Причем, каждое поле может иметь свой порядок.
Как уже было рассмотрено, тип поля может быть числовым, текстовым, логическим и т.д. Наибольшее применение имеет принцип лексикографической упорядоченности (по возрастанию алфавита, кодов символов).
Существуют программы сортировки для выполнения этой процедуры обработки данных. Такие программы могут входить в состав ОС, систем программирования, комплексов утилит (сервисных программ) и т.д.
Файл (исходный) -> сортировка -> Файл (результирующий)
Для оценки методов упорядочения одним из основных критериев является количество операций сравнения в процессе сортировки.
Теоретически доказано, что минимально возможное число сравнений для упорядочения n элементов (записей) приближенно оценивается по формуле:
C(n)
С - число операций сравнения;
n - количество записей в массиве;
]x[ - наименьшее целое, не меньшее х.
Сортировка - процесс расположения записей согласно принятому критерию.
Сортировки подразделяют в зависимости от алгоритма и вида используемой при сортировке памяти на:
- внутренние (пузырьковая, Шелла, вставки, квадратичной выборки) в оперативной памяти;
- внешние (балансная, каскадная, многофазная) с использования внешних носителей информации.
Методы сортировки:
Метод пузырька.
Очень простой, но не эффективный способ. Название получил по аналогии с пузырьком, всплывающим в жидкости. Сортировка проводится по алгоритму: первый ключ сравнивается со всеми последующими, пока не будет найден ключ j-й ключ, меньший первого. Тогда ключи меняются местами, т.е. делается их перестановка. Таким образом, совершается процедура со всеми последующими ключами до конца массива. Для первого ключа требуется (n-1) сравнение. Затем берется второй ключ и процедура повторяется, осуществляется (n-2) сравнения. И т.д. до (n-1)-го ключа, который сравнивается с последним, одно сравнение.
Всего проводится сравнений:
C(n)=(n-1)+(n-2)+...+1=n(n-1)/2.
Число возможных перестановок ключей: max P(n)n(n-1)/2, среднее P(n)n(n-1)/4.
Метод вставки.
При этом методе сортировки каждый ключ (обозначим его номером j) сравнивается с предыдущим до тех пор, пока не будет найден ключ с меньшим значением, чем ключ с номером j. Пусть это будет ключ с номером k (k<j). Тогда все ключи с номерами k+1,....j-1 сдвигаются на одну позицию вниз, а ключ j ставится на место ключа к+1. Если все впереди стоящие ключи больше ключа j, то все предыдущие сдвигаются вниз и ключ j ставится первым. Таким образом, доходят до последнего ключа n.
Оценка числа сравнений C(n)n(n-1)/4.
Число перестановок ключей в процессе сортировки оценивается как P(n)n(n-1)/4.
Метод Шелла.
Этот метод заключается в разбивке массива на группы и сортировке внутри этих групп. Затем группы попарно сливаются и производится сортировка внутри вновь образованных групп и т.д. На последнем этапе, когда массив представляет две отсортированные группы, он сортируется методом вставки или с помощью слияния с одновременным итоговым упорядочением.
Первоначально группы состоят из двух элементов, например, из 1-го и [n/2]+1-го, 2-го и [n/2]+2-го и т.д.
При использовании метода Шелла время
сортировки пропорционально, как
подтверждено экспериментально,
 .
.
Число сравнений С(n)
0.5n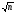 .
.
Внешние сортировки (на внешнем носителе):
Для больших объемов информации используются, как правило, внешние запоминающие устройства (ВЗУ) - магнитные ленты, диски. Сортировки с применением ВЗУ называются внешними. Внешние сортировки проводятся обычно в два этапа. На первом этапе выполняется внутренняя сортировка отдельных блоков информации и эти блоки записываются на внешние носители. На втором этапе эти блоки сливаются в один массив. Под слиянием будем понимать формирование из нескольких блоков такой части массива, которая упорядочена по тем же правилам, что и исходные блоки.
Существует несколько видов внешних сортировок.
Балансная сортировка.
Известны модификации этой сортировки - метод слияния, обменная сортировка.
При сортировке этим методом рабочий объем оперативной памяти делится на р-вводных и одну выводную зону. Обычно р=2. Для сортировки требуется 2р магнитных лент или файлов на магнитном диске. Исходный массив записывается на р лентах упорядоченными блоками равной длины. Другие р-лент считаются выходными. С каждой ленты считывается блок (всего р-блоков) в одну зону, информация в которой сортируется и выводится на очередную выходную ленту. Упорядоченная порция будет в р-раз больше, чем были входные порции. Это выполняется до тех пор, пока выходной порцией не окажется весь массив.
Рассмотрим пример. Пусть р=2. Массив состоит из 10 записей. Схема сортировки будет выглядеть следующим образом.
Исходный 1-й этап 2-й этап 3-й этап Выходной
|
1 |
|
6 |
|
2 |
|
8 |
|
9 |
|
10 |
|
|
|
|
|
|
|
|
|
3 |
|
4 |
|
5 |
|
7 |
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
3 |
|
4 |
|
6 |
|
9 |
|
10 |
|
|
|
|
|
|
|
|
|
2 |
|
5 |
|
7 |
|
8 |
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
2 |
|
3 |
|
4 |
|
5 |
|
6 |
|
7 |
|
8 |
|
|
|
|
|
9 |
|
10 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
2 |
|
3 |
|
4 |
|
5 |
|
6 |
|
7 |
|
8 |
|
9 |
|
10 |
массив массив
|
6 |
|
1 |
|
3 |
|
4 |
|
2 |
|
8 |
|
7 |
|
5 |
|
10 |
|
9 |
Процедура выборки информации. Критерии отбора информации.
Выборка информации - это процесс обработки массива информации (файла, набора данных), с помощью которого создается новый массив информации по заданным критериям отбора данных и со структурой данных, являющейся подмножеством данных исходного массива.
Пример.
Пусть есть список студентов некоторого факультета. Запись имеет вид:
|
Фамилия, и.о. |
Группа |
Пол |
Дата рождения |
Служба в ВС |
Задача: Выбрать всех призывников и сформировать файл.
Определим условие выборки:
(пол=“М”).”И”.((16=<(Текущая дата - Дата рождения).”И”.(Текущая дата - Дата рождения)<28) *
.“И”.”НЕ”(Служба в ВС))
Структура записи результирующего файла:
|
Фамилия, и.о. |
Группа |
Дата рождения |
Графическое изображение
выборки:
Исходный файл
Файл выборки
Документ
Число выбранных записей может быть от 0 до n, где - n число записей в исходном массиве.
Критерии отбора - это логические условия, которым должны удовлетворять заданные поля исходного массива. Элементами логических условий являются поля, отношения между ними и заданными значениями полей, логические связки - и, или, нет.
Процедура поиска информации. Понятие запроса. Виды условий поиска. Эффективность поиска.
Поиск - это процедура извлечения (выделения) из некоторого множества записей такого подмножества, записи которого удовлетворяют заранее заданному условию. Условия поиска называют запросом на поиск, поисковым признаком.