

4.8. Нелинейная регрессия
Шагом в нахождении более сложных моделей
является использование метода нелинейной
регрессии. Этот метод заключается в
том, что на основе имеющихся знаний об
исследуемых данных выбирается некоторый
вид регрессионной функции и требуется
найти значения регрессионных коэффициентов
![]() .
Нелинейная регрессия реализована в
многих системах анализа данных. Однако
его практическая ценность часто
ограничивается тем обстоятельством,
что пользователь должен a priori располагать
довольно подробными знаниями об искомом
решении. А именно, он должен задать вид
регрессионной функции, примерные
значения регрессионных коэффициентов
и характерные масштабы их изменения.
Знание двух последних моментов необходимо
по следующей причине. При нахождении
регрессионных коэффициентов линейной
модели в нашем распоряжении имеется
эффективный алгоритм их вычисления на
основе матричной алгебры. В случае
произвольной нелинейной модели задача
нахождения регрессионных коэффициентов
есть задача численной минимизации
величины , рассматриваемой как функция
регрессионных коэффициентов
.
Нелинейная регрессия реализована в
многих системах анализа данных. Однако
его практическая ценность часто
ограничивается тем обстоятельством,
что пользователь должен a priori располагать
довольно подробными знаниями об искомом
решении. А именно, он должен задать вид
регрессионной функции, примерные
значения регрессионных коэффициентов
и характерные масштабы их изменения.
Знание двух последних моментов необходимо
по следующей причине. При нахождении
регрессионных коэффициентов линейной
модели в нашем распоряжении имеется
эффективный алгоритм их вычисления на
основе матричной алгебры. В случае
произвольной нелинейной модели задача
нахождения регрессионных коэффициентов
есть задача численной минимизации
величины , рассматриваемой как функция
регрессионных коэффициентов![]() .
А для всех численных методов нахождения
минимума функции нескольких переменных
существует опасность нахождения
локального, а не глобального минимума,
если или начальное приближение для
точки минимума, или характерные масштабы
изменения аргументов заданы неправильно
(рис. 11).
.
А для всех численных методов нахождения
минимума функции нескольких переменных
существует опасность нахождения
локального, а не глобального минимума,
если или начальное приближение для
точки минимума, или характерные масштабы
изменения аргументов заданы неправильно
(рис. 11).
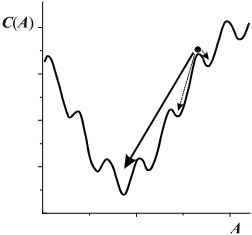
Рис. 11. Зависимость функции ошибок от параметров нелинейной модели.
Эти обстоятельства и приводят к тому, что метод нелинейной регрессии может быть отнесен к инструментарию KDD с известной натяжкой - ему явно недостает автоматизма. От пользователя фактически требуется заранее знать окончательный ответ: форму зависимости, хорошее начальное приближение для регрессионных коэффициентов и характерный масштаб их изменения. Однако в далеких от точных наук прикладных областях, таких как медицина, ни характер зависимостей, ни примерное значение переменных, соответствующих минимуму, ни их характерный масштаб, как правило, не бывает известен. Поэтому применения данных методов в при исследовании медицинских, как и большинства других баз данных весьма ограничены. Исключение составляет использование нелинейных регрессионных методов в точных науках, где, напротив, существующие теоретические модели явления позволяют, как правило, выбрать требуемые характеристики регрессионной модели.
С вычислительной точки зрения, линейная регрессия хороша не столько тем, что в нее линейно входят независимые переменные, сколько тем, что в нее линейно входят регрессионные коэффициенты. Именно это дает возможность быстро и точно решать регрессионные задачи. Поэтому прямым и эффективным обобщением метода линейной регрессии является использование нелинейных регрессионных моделей обладающих свойством линейности относительно регрессионных коэффициентов. Одним из наиболее известных методов, использующих регрессионные модели такого типа является метод группового учета атрибутов, сокращенно МГУА (Farlow, 1984; Ивахненко и Мюллер, 1985), предложенный А.Г. Ивахненко в 1968 году и затем подробно исследованный Р. Шанкаром (Shankar, 1972). В этом методе регрессионная функция выбирается в виде
![]() (7.)
(7.)
Различные варианты МГУА различаются выбором функций F и стратегий включения различных членов в сумму. Часто полагают F(x) = x. Выбор членов для введения их в модель может осуществляться пошаговым алгоритмом, аналогичным обсуждавшемуся выше алгоритму множественной линейной регрессии с автоматическим выбором независимых переменных. Другой подход основывается на механизме, часто применяемом для удаления незначимых ветвей деревьев решений. А именно, множество анализируемых записей делится на две части, и одна часть используется для получения максимально общей модели этого вида, а другая часть - для ее тестирования. При этом отдельные члены, входящие в выражение (8), отбрасывают так, чтобы рост стандартной ошибки был минимальным. Процесс отбрасывания членов останавливают после того как стандартная ошибка возрастает в некоторое заранее установленное количество раз (обычно не более 1.05 раз). В другой группе разновидностей МГУА процесс построения модели повторяют несколько раз, причем на каждом следующем этапе в качестве независимых переменных берут не только Xi, но и значения регрессионных функций, полученных на предыдущих этапах. Наконец, в ряде вариантов выбирается модель, которая минимизирует значение некоторой функции от стандартной ошибки прогноза и меры сложности модели (скажем, число членов в этой сумме).