

Пакет Statistica.
Этот пакет можно отнести к категории популярных универсальных. Наряду с пакетом SPSSон является, пожалуй, одним из двух наиболее распространенных среди специалистов различных областей, использующих статистическую обработку данных. Первая версияStatistica, разработанная компаниейStatSoftInc, вышла в 1991 году (подDOS). На момент написания этих строк появилась уже 12 версия этого программного продукта. В 1995 годуStatisticaбыла включена в список 100 лучших программных продуктов (версияWindowsMagazine).
Перечислить не то что все, а хотя бы самые основные возможности этого пакета (от широкого набора возможностей преобразовывать исходные данные до группы ныне модных методов DataMining) без где-то двух десятков страниц текста, наверное, невозможно.
Но прежде, чем говорить о некоторых (только некоторых!) доступных здесь способов решать задачи статистики перечислим недостатки этого пакета.
– Обилие возможностей. Их чересчур много! Хорошо об этом выражается А.П. Кулаичев1(*)стр.25«... Наряду с внешней красивостью, основным преимуществом перед конкурентами стал критерий разнообразия возможностей, которые добавляются в продукт без критического отбора. В результате многие пакеты ... стали напоминать своеобразные помойки. Действительно, на хорошей помойке можно найти все, что угодно, однако крайне трудно найти то, что в данный момент позарез нужно».
– Очень плохой Help. Не дает возможности понять как конкретно произвести те или иные процедуры, каким путем идти к нужным пунктам меню и как изменять в нужную сторону установки. ВHelpнет примеров. Невозможно понять какое формульное обеспечение используется в рассматриваемой процедуре обработки данных. Много смешного, например, если вLongname(панель спецификации переменной) формула набрана правильно, то появляется подсказка с некоторыми правилами правильного набора, а если неправильно – то просто «Errorinformula».
– Statisticaтабличный редактор, со свойствами частично схожими сExcel. Но в отличие отExcelв ней нет возможности работы с отдельными ячейками, преобразовывать можно только столбцы или строки целиком, результатом этих преобразований или обсчетов нельзя поместить в отдельные ячейки.
– Маленький набор математических функций преобразования переменных. Нет, например, функции факториал (!) и т.д.
И вот с этим букетом недостатков, пакет Statisticaсреди лидирующих на рынке обработки данных в экономике, медицине, психологии, географии и многих других наук. А за счет чего?
– Самая лучшая и удобная графика, среди статистических пакетов.
– Подробные отчеты по проведенным процедурам. И если ты сумел разобраться, что есть что при получении отчета о полученных результатах, то обычно получаешь ответы на подавляющее большинство своих вопросов.
– Наличие нужных способов обработки данных, не имеющихся в других пакетах.
Перечислим задачи из приведенного выше списка, которые нельзя решить в Statistica. Это Задача 1, Задача 8, Задача 15. Остальные задачи со всеми подвопросами легко решаются в этом пакете.
Вот так выглядит один из графиков к Задаче 4
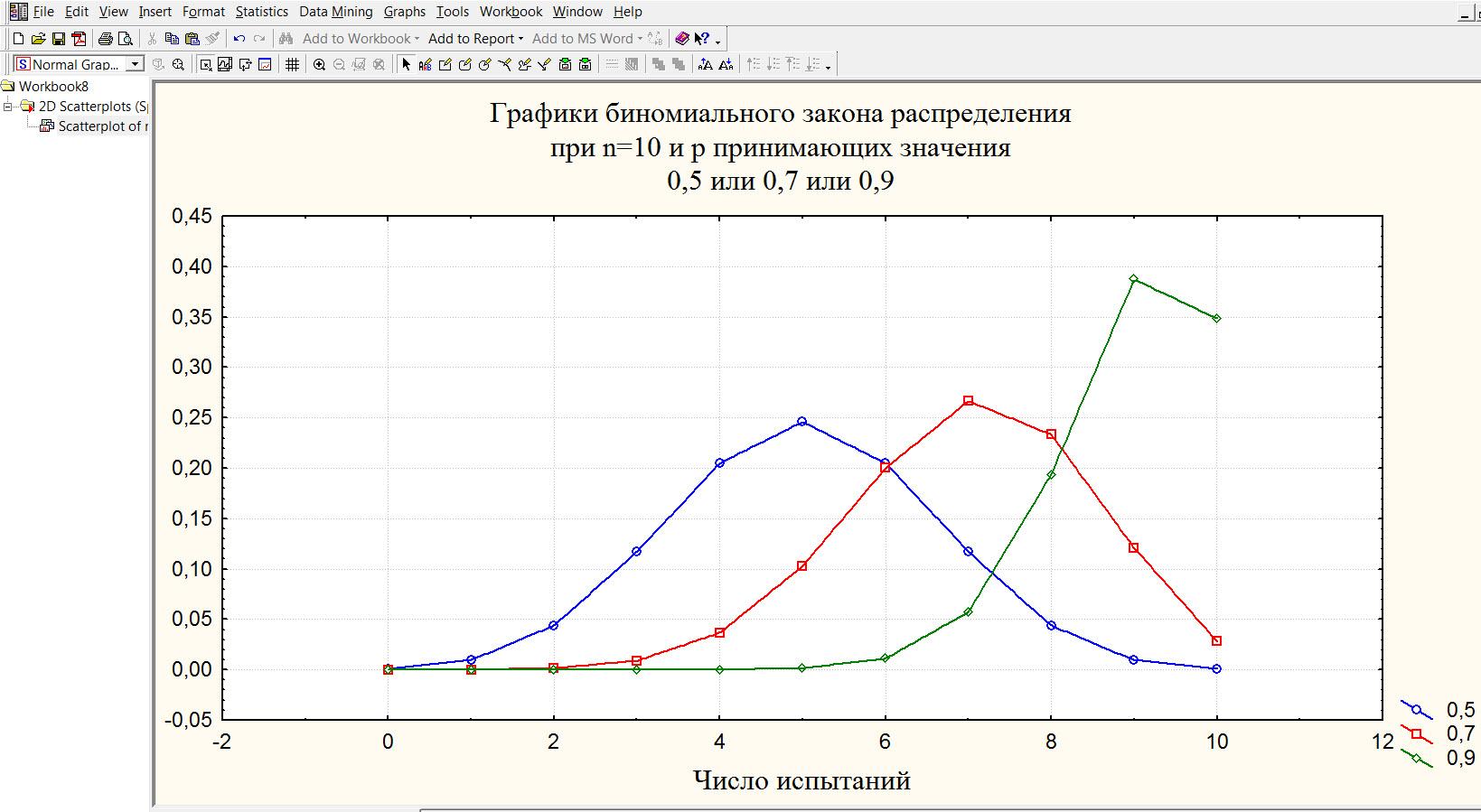
А вот так выглядит отчет к Задаче 16 пункт 7. Решение предполагает использование однофакторного дисперсионного анализа (ANOVA).

Сразу видно, что эмпирическое значение
уровня значимости
![]() 0,587280
больше чем 0,05. Следовательно принимается
гипотезаH0 –
статистически значимых различий в весе
у респондентов с различным цветом волос
не наблюдается. Здесь же получаем и
ответ на вопрос из 12 пункта этой задачи.
0,587280
больше чем 0,05. Следовательно принимается
гипотезаH0 –
статистически значимых различий в весе
у респондентов с различным цветом волос
не наблюдается. Здесь же получаем и
ответ на вопрос из 12 пункта этой задачи.
Просто сравниваем 0,01 с
![]() .
.
Вот получение уравнение линейной функции регрессии веса на возраст; и оценка статистической значимость коэффициентов полученного уравнения (Задача 16, пункт 9).
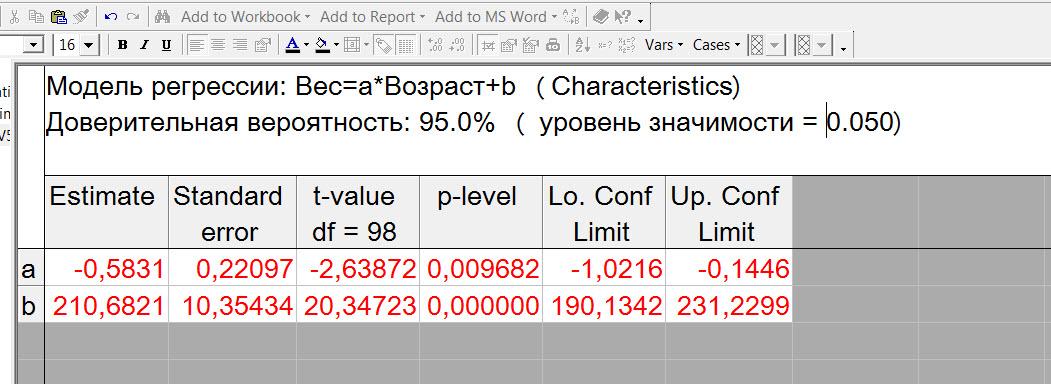
Вся нужная информация представлена компактно и удобно читается.
– Само уравнение имеет вид
![]() .
.
– Эмпирические уровни значимости
коэффициентов уравнения равны 0,009682 и
0,000000 соответственно. Эти значения
позволяют говорить о статистической
значимости этих коэффициентов на уровне
0,05. Более того, мы получаем границы
доверительных интервалов для них!
Эмпирические уровни значимости
коэффициентов уравнения равны 0,009682 и
0,000000 соответственно. Эти значения
позволяют говорить о статистической
значимости этих коэффициентов на уровне
0,05. Более того, мы получаем границы
доверительных интервалов для них!
Ниже Вы видите (Statistica10) список самых современных возможностей обработки данных изDataMiningдоступных в этом пакете.
Вывод: если бы был бы доступным по цене, то для преподавания статистики очень удобный и богатый возможностями пакет.
R
R– это язык программирования для статистической обработки данных и работы с графикой, а также это свободная программная среда с открытым исходным кодом, развиваемая в рамках проектаGNU. Он может быть применяться везде где нужна работа с данными и это не только статистика в узком смысле понимания слова. Но наиболее часто он находит применению именно при статистическом анализе – от вычисления средних величин до вейвлет – преобразований временных рядов. Сейчас трудно найти американский или западноевропейский университет, где бы не работали сR. Многие весьма солидные коммерческие компании (например,Boeing) используют его в своей работе.
Чем же обусловлено также широкое (на Западе!, но не в России) распространение этого программного продукта? Проведем аналогию. Пусть имеется большая, очень большая, группа людей. Одному нужно что-то, чтобы резало морковку на равные дольки, другому – нужно прокручивать мясо, третьему – приготавливать мороженное и т.д. Каждый из них может купить очень дорогой и громоздкий универсальный комбайн, который все это умеет делать. Подчеркнем, что покупка комбайна обойдется весьма не дешево, а нужна от него будет только одна, от силы несколько, функций. И вдруг эти люди узнают, что есть совершенно бесплатный конструктор, из деталей которого они могут собрать небольшие и эффективные аппараты для удовлетворения своих нужд.Rи есть тот «конструктор», из которого каждый пользователь – практик может с небольшими усилиями собрать свой статистический пакет. Впрочем, весьма возможно, что и усилий на сборку тратить не придется – ныне, благодаря энтузиастамR, существует огромная библиотека статистических процедур, доступная всем и бесплатно. Правда, в этой огромной бочке меда, есть все-таки ложечка дегтя. Все существующие версииRиспользуют командную строку для ввода данных, и еще – интерфейс вывода результатов очень аскетичный, в нем нет привычным для «больших» пакетов понятных почти всем представлений ответов на задаваемые вопросы. Пользователь попадает в среду диалога с компьютером характерную для 70х – 80х годов, где было нужно немножко знать программирование и помнить большое количество команд. Ну, каждый выбирает по своим силам и возможностям!
Еще немного истории. Язык Rявляется некоммерческим продолжением (ответвлением) языкаS, возникшего еще в 1976 году. На основеS(с 1988 года) был создан статистический пакетS-PLUS. Пакет хороший, универсальный, но дорогой. В 1993 году новозеландские ученые (RobertGentlemanиRossIaka) предлагают новую версию, названнуюR. Эта версия отличается отSобращением к переменным, работой с памятью и имеет уникальную по легкости систему написания дополнений или пакетов. Получить пакетRподWindowsи первоначальные сведения о нем можно на официальном сайтеwww.r-project.org.
Очень удобна версия Portable, которую можно скачать на сайтеhttp://sourceforge.net/projects/rportable/
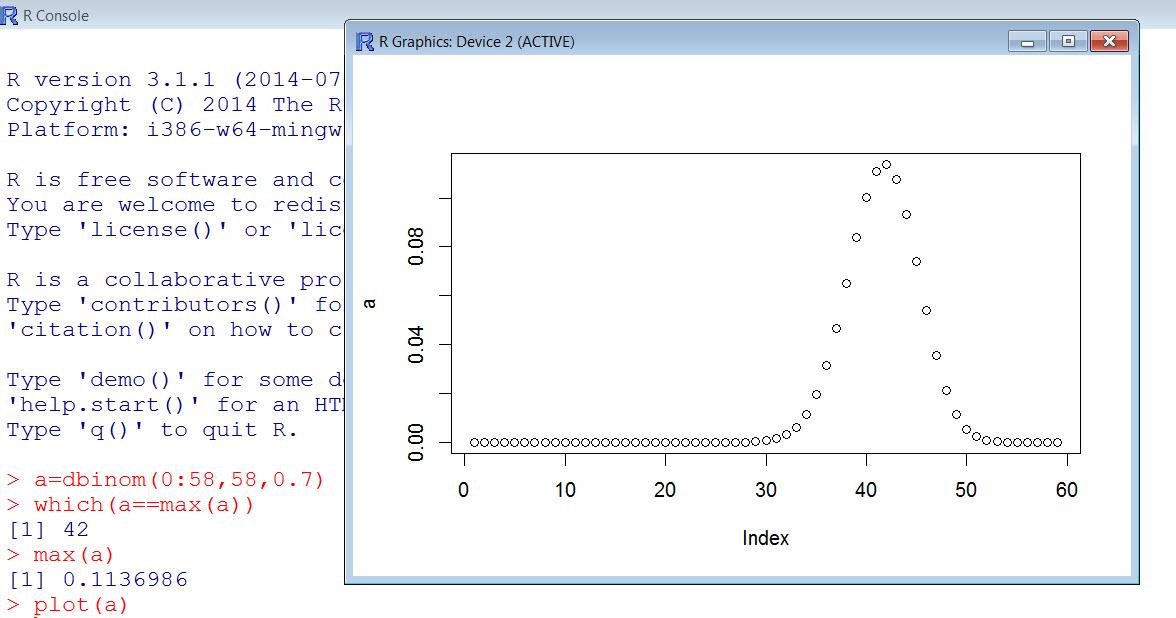
Теперь о возможностях R. Все предложенные выше задачи, кроме задачи 8 (нет процедур нахождения производных и интегралов), вRрешаются. Вот так выглядит решение задачи 1.
А вот решение задачи 10.
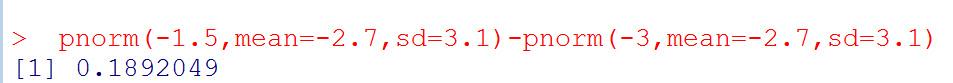
Даже эти простые примеры показывают, что по части наглядности и простоты общения, этот замечательный язык Rуступает статистическим пакетам и в качестве помощника в преподавании вряд ли может быть рекомендованы.
RapidMiner
Этот пакет сравнительно самый молодой в представленном выше списке. Проект RapidMiner был создан в 2001 году под названием YALE - Yet Another Learning Environment (дополнительная образовательная среда) в Дортмундском университете группой исследователей в области искусственного интеллекта. С 2004 года он становится проектом с открытым исходным кодом. Среди пользователей RapidMiner быстро набирает популярность и в 2009 году занимает второе место среди пакетов предназначенных для интеллектуального анализа данных (DataMining), причем 80% пользователей, использующих его как основной, собирались использовать его и далее (для пакетаRэтот показатель – 50%). В 2010 по этой же категории RapidMiner занимает первое место! В настоящее время он широко применяется при составлении и анализе реальных проектов в бизнесе, производстве, научных исследованиях и т.д., всюду, где приходится решать задачи классификации, выявления структурных связей, получения алгоритмов принятия решений на основе больших массивов данных.
На официальном сайте проекта (https://rapidminer.com/products/studio/) можно получить как бесплатную, укороченную, версиюCommunity Edition, так и расширенную платную –Enterprise Edition.
Интерфейс RapidMiner сильно отличается от стандарта общения с классическими статистическими пакетами. Вместо обработки данных при помощи выбора последовательности команд (требований), используется построение потоков данных проходящих через некоторые узлы. В пакете существует большое количество таких узлов, реализующих различные алгоритмы обработки (в бесплатной версии их около 300) В качестве ответа предлагается либо некоторая таблица, либо красивая графическая (древовидная) модель для выявления параметров, по которым принимаются решения.