

Пакет Gretl [сайт http://gretl.Sourceforge.Net ]
Небольшой по занимаемому объему (около 45 мб) статистический пакет, относящийся к свободно распространенным. Предназначен для эконометрического моделирования (регрессионный анализ, временные ряды). Позволяет получать большинство описательных статистик, строить графики, создавать скрипты. Данные для обработки можно создавать как в самом пакете, так и импортировать, например, из SPSSилиExcel. Имеет русскую локализацию (т.е. русифицирован). Хорошая наглядность, простой и интуитивно понятный интерфейс, но возможностей маловато.
Расширяет возможности вариантов обработки данных интеграции GretlсGNUR. Ниже Вы видите пример получения описательных статистик на выборкеa.
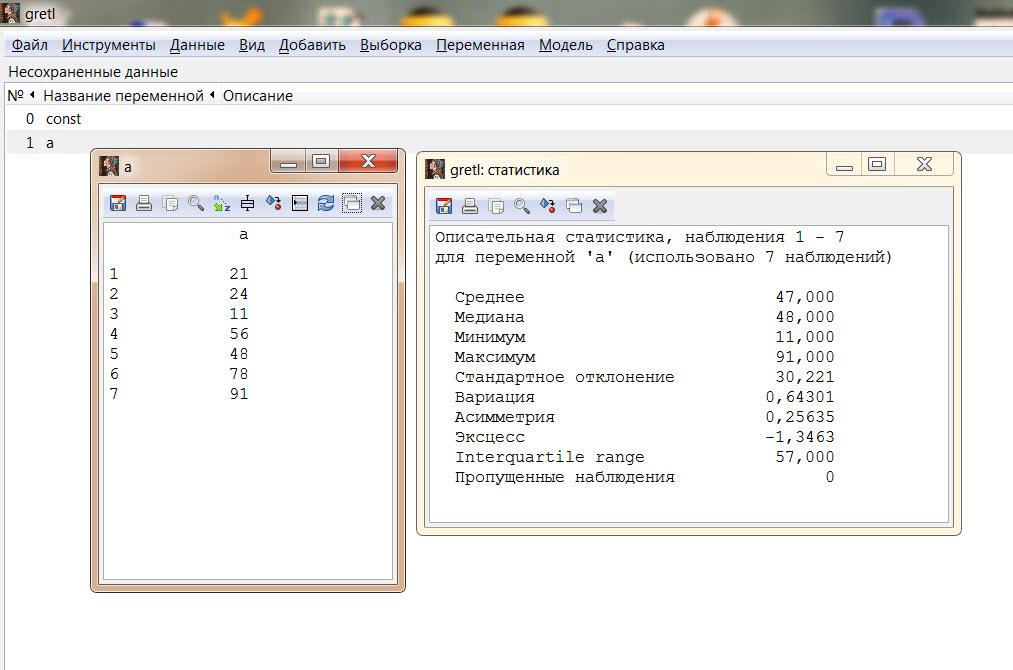
Результаты обработки можно получить в формате LaTeX. В июне 2013 в Оклахома – Сити была проведена третья конференция участников проектаgretl. Очень быстро растет база пользовательских программ, написанных сторонниками этого пакета.
GeoGebra
GeoGebra– это свободно распространяемая программа (математический пакет), использующаяся при обучении школьников и студентов в таких дисциплинах, как: геометрия, аналитическая геометрия, проективная геометрия, алгебра, теория чисел, математических анализ, теория вероятностей и статистика и другие смежные дисциплины. Она была создана австрийцем Маркусом Хохенвартером (MarkusHohenwarter), ныне профессором Флоридского Атлантического университета в США, в 2001 году.
GeoGebraнаписана на языкеJava(это обуславливается ее некоторую медлительность). Программа активно развивается и дополняется новыми возможностями. В версии 5.0.9.0. имеется 6 окон (Window): Панель объектов, Таблица,CAS, Полотно, Полотно 2, Полотно 3D(Терминология русскоязычной версии). На экране может присутствовать любое сочетание этих окон, которые представляют из себя некие «подпакеты» для выполнения конкретных математических задач. И хотя нас будут интересовать в основном окноCAS, Таблица и Калькулятор Вероятностей (именно в них и решаются задачи теории вероятностей и статистики) очень хочется отметить великолепное сочетание Панель объектов + Полотно. Это воплощенная мечта Декарта. Любое аналитическое действие в Панели объектов тот час отражается на Полотне, и наоборот – любое геометрическое построение на Полотне порождает цепочку аналитических выражений в Панели объектов.
В окне CAS(с анг.ComputerAlgebraSystems) можно выполнять большое количество операций доступных таким пакетам символьной математики какMaple,Mathematica,Deriveи другие. Это и работа с обыкновенными дробями, алгебраические преобразования, решение алгебраических уравнений и систем уравнений, нахождение пределов, дифференцирование и интегрирование, решение дифференциальных уравнений и т.д.

Работа в этом окне дает возможность проводить вычисления в задачах, например, на классическое определение вероятности. Возьмем задачу 1. Вероятность события A(k) находится по формуле
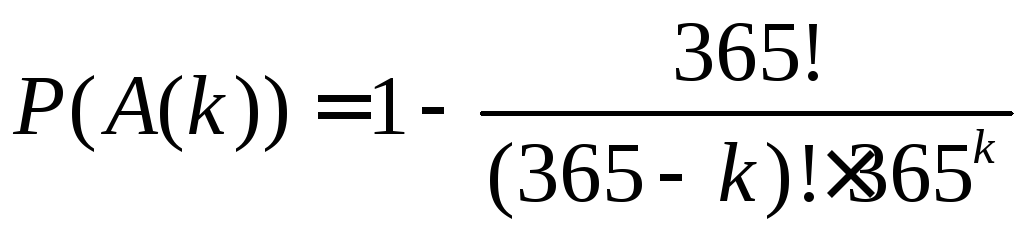 .
.
Вычисление с такими числами в Excelне проходят.GeoGebraже позволяет легко вычисляет эти значения при любыхk от 2 до 364.
Обратимся к задаче 5. Вероятность забросить мяч k-раз в корзину при 58 бросках находится по формуле Бернулли.
![]()
Наивероятнейшее число бросков
![]() можно найти из неравенства
можно найти из неравенства![]() .
Это 41 бросок. Сочетанию окон Панель
объектов и Полотно позволяет увидеть
график функций и интервал, в котором
следует искать
.
Это 41 бросок. Сочетанию окон Панель
объектов и Полотно позволяет увидеть
график функций и интервал, в котором
следует искать![]() .
Дополнительно вызванный исследователь
функций позволяет уже дать правильный
ответ.
.
Дополнительно вызванный исследователь
функций позволяет уже дать правильный
ответ.

рис.3.
Э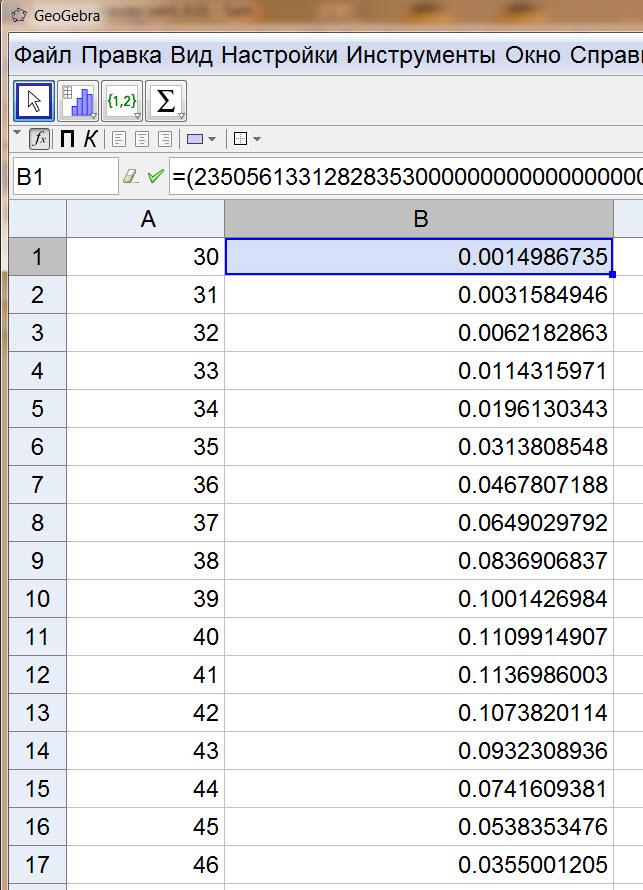 тот
же ответ можно получить и в окне Таблица.
Это окно – табличный редактор, аналогичныйExcel. Получаем таблицу, из
которой непосредственно видно каковы
вероятности числа попаданий мяча в
корзину и какое из этих чисел имеет
наибольшую вероятность.
тот
же ответ можно получить и в окне Таблица.
Это окно – табличный редактор, аналогичныйExcel. Получаем таблицу, из
которой непосредственно видно каковы
вероятности числа попаданий мяча в
корзину и какое из этих чисел имеет
наибольшую вероятность.
Рассмотрим решение задачи 16 пункт 6 из области статистики. Необходимая часть таблицы данных для этой задачи через буфер обмена без проблем переносится в окно Таблица. Используя команды этого окна, находим сперва какие цвета глаз встречаются в списке и каковы их абсолютные частоты (команды «Едиственность[В1:В100]» и «Частота[В1:В100]»).
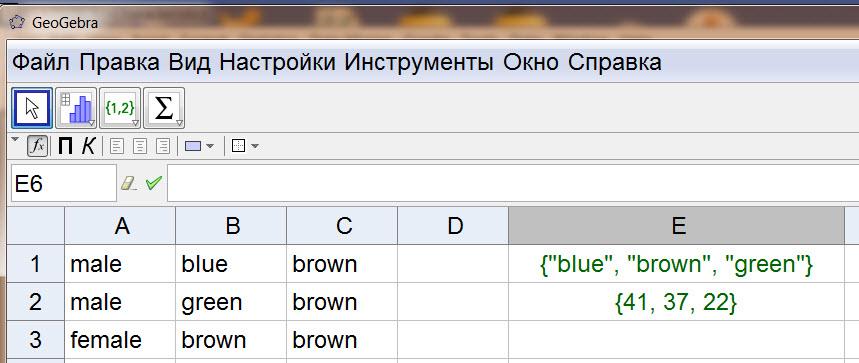
рис. 5.
Теперь нам нужно сравнить попарно
полученные частоты и выяснить, носит
ли их различия статистически значимый
характер на уровне значимости 0,05. Для
этого воспользуемся критерием
![]() Фишера (угловое преобразование Фишера).
Сравним, например, доли «голубоглазых»
и «кареглазых» в выборке.
Фишера (угловое преобразование Фишера).
Сравним, например, доли «голубоглазых»
и «кареглазых» в выборке.

Остается только сопоставить полученное
значение
![]() с табличным 1,64. Получаем, что эти доли
надо считать статистически одинаковыми.
И так далее.
с табличным 1,64. Получаем, что эти доли
надо считать статистически одинаковыми.
И так далее.
В GeoGebraесть отличный
Калькулятор Вероятностей (очень похожий
на инструмент с таким же названием вStatistica), который позволяет
с легкостью решать задачи на нахождение
вероятностей вида![]() при различных часто встречаемых законах
распределения случайной величины
при различных часто встречаемых законах
распределения случайной величины![]() .
Вот как наглядно и просто решается в
нем Задача 10.
.
Вот как наглядно и просто решается в
нем Задача 10.
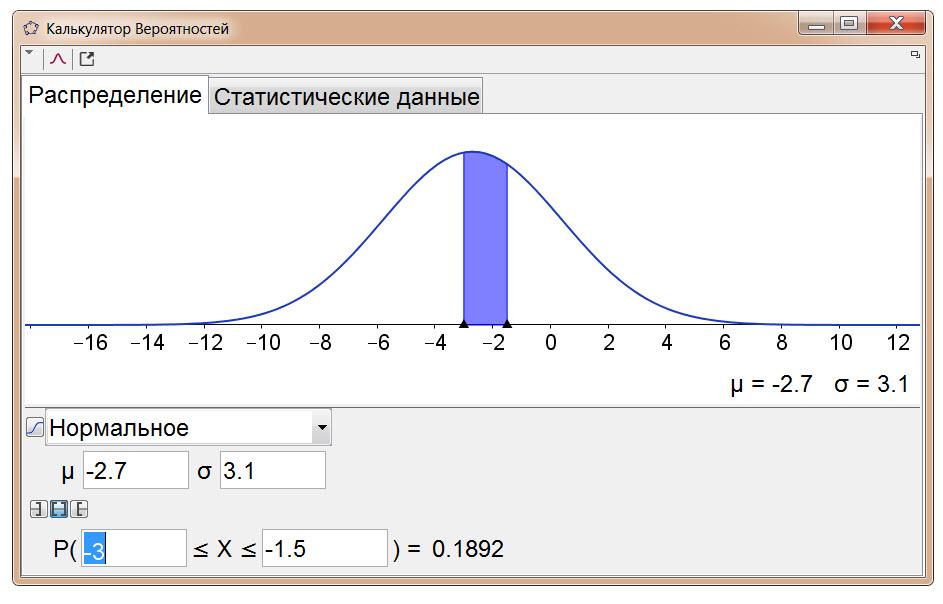
Кстати и решение задачи 5 в этом Калькуляторе Вероятностей выглядит весьма просто и наглядно

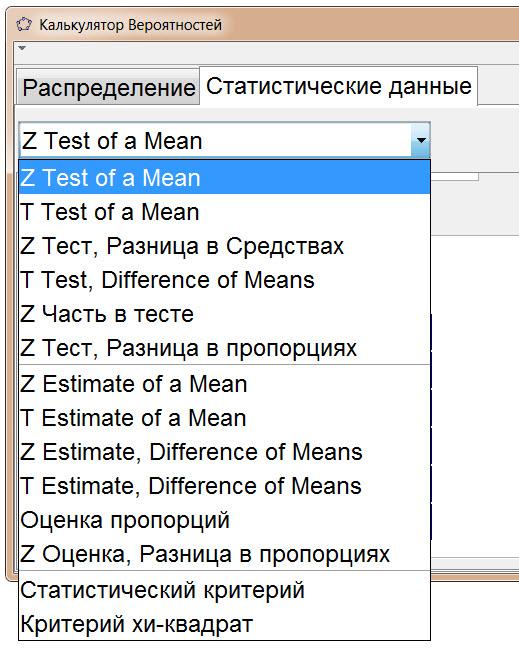
Использование вкладки Статистические данные в этом калькуляторе позволяет проверять следующие статистические гипотезы
Вывод: очень подходящая программа для сопровождения преподавания математики на начальных этапах. Из существенных недостатков надо отметить: отсутствие методической литературы на русском языке, постоянные мелкие изменения в интерфейсе при переходе на новые версии.
Excel
Один из наиболее известных табличных редакторов или электронная таблица, названный своими создателями несколько претенциозноExcel(сокращение от «excellent» - превосходный) появился в 1987 году. Разумный компромисс между возможностью быстрого освоения и широкими возможностями применения (бухгалтерия, экономика, финансы , анализ данных в различных науках и т.д.) сделалиExcelчрезвычайно популярным и часто используемым продуктом. А его включение в пакет Microsoft Office позволяет найти эту электронную таблицу практически на любом компьютере (ну если не самExcel, так его полные свободно распространяемые аналоги –CalcилиGnumeric).
Для решения задач теории вероятностей в Excelможно использовать встроенные математически-вычислительные функции, законы распределения наиболее часто встречающихся случайных величин (биномиальный, нормальный, t-распределение Стьюдента, распределение Пуассона, распределение Вейбулла и другие) и возможность построения различных графиков (гистограмма, график рассеяния, круговые диаграммы и еще и еще). Задачи этого цикла 1 – 7, 9 – 14 и даже задачу 15 в этом пакете можно решить. Вот примеры полученных ответов на задания 5 и 10.
Задача 5
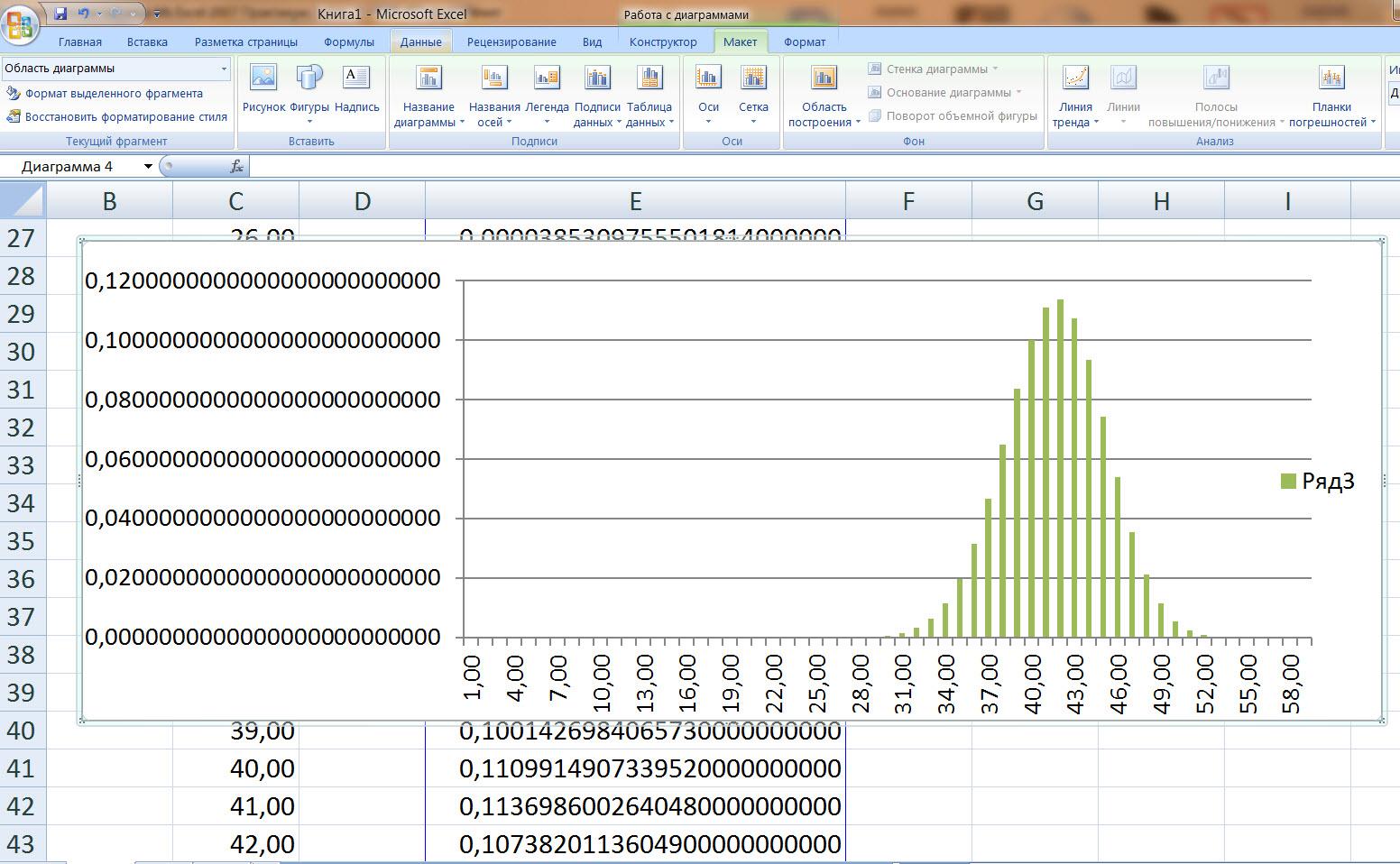
И аналитически и графически видно, что наивероятнейшее число бросков равно 41 и соответствующая вероятность равна 0,113698600264048.
Задача 10.
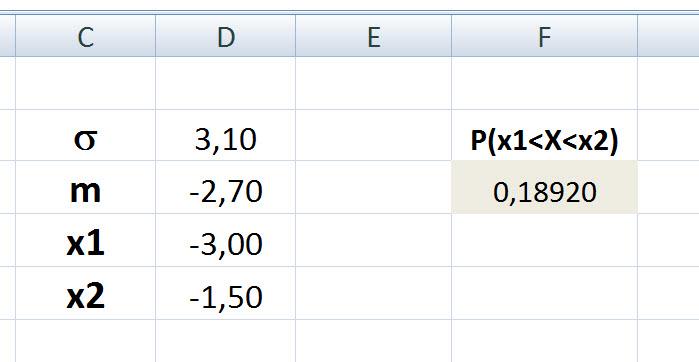
Искомая вероятность равна 0,18920.
Для статистической обработки данных используются возможности построения цепочек последовательных преобразований числовых массивов, встроенные статистические функции (в Excel2007 их около 90) и Пакет Анализа Данных. Эти средства позволяют получить решения всех пунктов Задачи 16. Приведем вид не полного ответа на следующие вопросы: существует ли статистически значимая (уровень значимости 0,05) корреляция между ростом и весом; между весом и результатами тестирования по тесту1. Первая часть подразумевает нахождение коэффициента линейной корреляции Пирсона, вторая – коэффициента корреляции Спирмена.
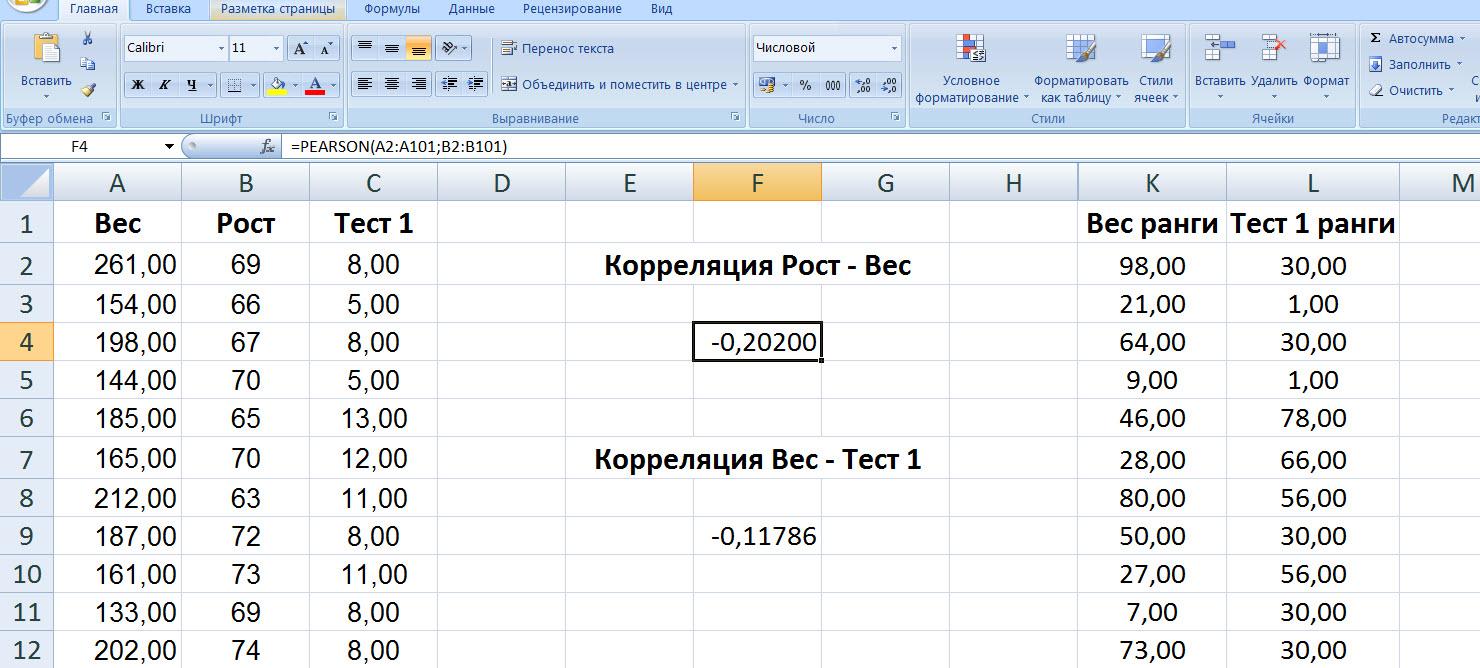
Сами числовые значения коэффициентов на представленном рисунке найдены. Коэффициент корреляции Пирсона (-0,20200) вычислен за счет встроенной функции PEARSON. А вот для Спирмена (-0,11786) нет встроенной функции! В столбцахKиLприведены результаты ранжирования данных столбцов А и С. Причем этотExcel’евский способ ранжировании отличен от принятого в статистике по части присвоения рангов совпадающим значениям выборки. Для правильного, пришлось бы еще «крутиться» (не хорошо поднаторевшему прикладнику) с таким вот блоком обработок (взято из книги «Психологический анализ в среде Excel» Сапегина А.Г., 2005. - стр. 26; взято с точность до имен столбцов).

Затем к полученным рядам чисел применена встроенная функция PEARSON(это можно так сделать в связи с большим количеством данных).
И еще не найдены уровни статистической значимости полученных коэффициентов корреляции. И еще, по-хорошему, надо бы найти поправки на повторяемости рангов и проверить все условия применимости нахождения коэффициента линейной корреляции Пирсона. Довольно громоздко! Кстати вот как выглядят результаты тех же ответов в пакете Statistica, причем ничего писать не надо, а нужно лишь несколько последовательных щелчков мышью по пунктам меню.
Коэффициент линейной корреляции Пирсона
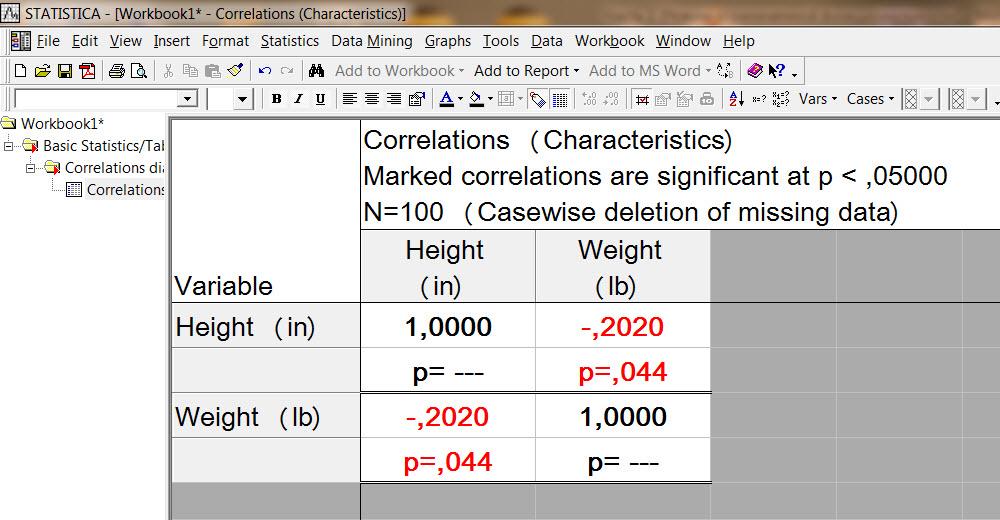
Уровень значимости ответы 0,044. На уровне значимости 0,05 можно говорить о существовании слабой корреляции между признаками.
Коэффициент корреляции Спирмена
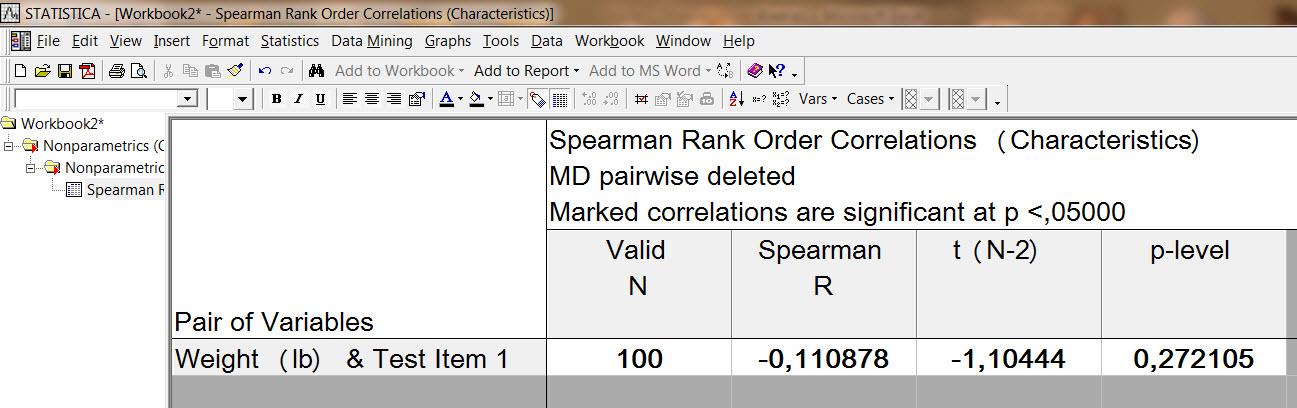
Уровень значимости ответа 0,272105. На уровне значимости 0,05 нельзя говорить о существовании корреляции между признаками.
Уже на этом простом примере видно:
– даже при ответе на простые вопросы надо помнить большое количество команд и уметь правильно их записывать (очень не удобно, что часть команд пишется на английском языке, а часть – на русском; приходится то и дело переключать регистр);
– на вопроса более «высокого» уровня ответы получаются настолько громоздко, что уж лучше уходить на более профессиональные пакеты, например R.
Вывод: для получения описательных статистик, построения графиков и при проверке некоторого, не очень большого круга, статистических гипотез этот пакет просто замечательный. Еще замечательности добавляет доступность и широкое распространение Excel. Но если в преподаваемом курсе речь будет идти, например, о факторном или дискриминантном анализах, кластеризации объектов, каноническом анализе, причинном моделировании и т.д., то надо искать какие то другие пакеты.
MathCAD, Mathematica и Maple.
Несколько слов об этих замечательнейших пакетах. В них можно решать наверно ВСЕ задачи, встречающиеся в процессе обучения не только теории вероятностей и статистике, но и ВСЕХ других дисциплин математического цикла. Но эти пакеты дорогие (MathematicaиMapleочень дорогие) и полноценное общение с ними требует знания нескольких сотен, а лучше тысяч, команд. И еще нужно хорошее знание математического содержания всех используемых процедур получения решений на поставленные вопросы. Нужно и знание и умение элементарных разделов программирования (составление блок-схемы решения задачи, организация циклов, программирование разветвляющихся алгоритмов и т.д.).
Из этих трех пакетов наиболее распространен
и популярен MathCAD. ВMathCADвходит хороший текстовый редактор,
позволяющий формировать отчеты о
вычислениях, не выходя из пакета.
Интерфейс с запись математических
выражений в их естественной форме делает
общение достаточно легким и даже
приятным. Программа обладает широкими
графическими возможностями. Множество
типов графиков обеспечивают наглядность
и визуальный анализ данных (2-х и 3-х
мерное изображение, декартовы и
полярные координаты, точечное и
параметрическое задание линий и
поверхностей, гистограммы, линии
уровней, анимация и динамическое
изображение и т.д.). Огромное количество
встроенных функций (для статистических
вычислений можно использовать такие
довольно экзотические команды как![]() определяющую матрицу Холесского размера
определяющую матрицу Холесского размера![]() для симметрического нормального
распределения при значениях параметров
для симметрического нормального
распределения при значениях параметров![]() и
и![]() ;
набор функции для обсчетов цепей Маркова
и т.д.)
;
набор функции для обсчетов цепей Маркова
и т.д.)
Вывод.Подитоживая все предыдущее, авторы предлагаю следующую схему приоритетов при выборе математического пакета в преподавании теории вероятностей и математической статистики
Excel
GeoGebra, Statistica, SPSS
MathCAD, Mathematica, Maple
R + Gretl или RapidMiner
Хочется сделать еще несколько замечании относительно как самих статистических пакетов, так и способов использования статистики вообще прикладниками.
Первое.В работах посвященным обработке практически значимых массивов информации в настоящее время весьма часто можно встретить словосочетаниеDataMining. Общепринятого перевода его на русский язык нет. Один из вариантов – интеллектуальный анализ данных – звучит несколько напыщенно и ничего не говорит о содержании (и как будто вся остальная статистика не «имеет отношение к способности человека мыслить»!). В наиболее консервативном варианте вDataMiningвключают анализ корреляционных связей, кластерный анализ, дискриминантный анализ, линейную и логистическую регрессию, построение деревьев решений. Более современные статистики добавляют сюда нейронные сети, методы поиска ассоциативных связей, эволюционное программирование, генетические алгоритмы и многое другое. В подавляющем большинстве используемые здесь процедуры не сопровождаются указанием на уровень значимости получаемых результатов. Критерием правильности полученных на их основе выводов должна(!) стать их практическая эффективность. При этой новой статистической парадигме стираются грани между математической статистикой, обыкновенным индуктивным выводом и экспертными оценками. Во всех, как платных так и в бесплатных, статистических пакетах с увеличение номера версии доля процедур обработки, относимых кDataMining, возрастает чрезвычайно быстро.
Второе.Один из путей удешевления проектов в бизнесе, производстве, науке – это использование свободно распространяемого программного обеспечения, при их составлении и реализации. Это путь по которому идут многие компании на Западе. Что касается статистической обработки данных, то в этом отношении весьма популярныRи RapidMiner. В русскоязычном множестве учебной и методической литературы им посвящены не более десятка(!) в основном интернет-заметок, пара малостраничных методичек поRи все. Бесплатные статистические пакеты у нас не пользуются никаким спросом. Это более чем странно и очевидно , что так долго продолжаться не может. Одна из задач подготовки студентов по теории вероятностей и статистике и должна заключаться в обзорном ознакомлении с эти свободным программным обеспечением, а одним из них – достаточно подробно.
1А.П. Куланчев
Методы и средства анализа данных в среде Windows.Statistica6.0 – М.: Информатика и компьютеры, 1996. – 257 с., ил.