

Студентам ИТ / 3 ЛП_ИТ / ИТ_прогнозирования / ИТ_фин_произв_бизнесом_Excel
.pdf2.Выберите из списка «Инструменты анализа» пункт Генерация случайных чисел (курсор, левая кнопка мышки, кнопка [ОК]).
3.В появившемся диалоговом окне Генерация случайных чисел укажите в соответствующих аргументах: Число переменных – 1; Число случайных чисел (количество имитаций) – 500; Распределение – требуемый тип Нормальное; Среднее – 30; Стандартное отклонение – 3,54; Случайное рассеивание – 0; Выходной интервал – A13. После нажатия кнопки [ОК] блок ячеек – A13 : A512 будет заполнен сгенерированными случайными значениями.
Внимание ! Аргументы Среднее и Стандартное отклонение могут быть заданы только в виде констант. Использование адресов ячеек и их собственных имен не допускается.
Генерацию значений остальных переменных Q и P осуществите аналогичным образом, путем выполнения вышерассмотренных шагов 1 – 3 с тем лишь отличием, что необходимо изменить значения аргументов Среднее, Стандартное отклонение, Выходной интервал.
Для получения генеральной совокупности значений потоков платежей (NCF) и их чистой современной стоимости (NPV) скопируйте формулы ячеек D13 и E13. Решить проблему копирования больших диапазонов ячеек можно следующим образом.
1.Выделите и скопируйте в буфер ячейку D13.
2.Нажмите клавишу [F5], вызывая диалоговое окно Переход.
3.Укажите в поле Ссылка диапазон заполняемого блока ячеек - D13 : D512.
4.Нажмите клавишу [Enter].
5. |
Если в Excel установлен режим |
ручных вычислений (Сервис |
Параметры |
||
Вычисления), нажмите клавишу [F9]. |
|
|
|
||
Аналогично копируется формула из ячейки E13. |
|
|
|||
6. |
Сохраните необходимую в дальнейшем книгу Excel под именем Статистика! |
||||
Перейдите на лист Результаты анализа и проведите соответствующие вычисления, |
|||||
используя формулы, приведенные в таблице 7.7. |
|
|
|||
|
|
|
|
Таблица 7.7 |
|
Ячейка |
|
Формула |
|
|
|
B8 |
|
=СРЗНАЧ(Имитация!A13:A512) |
|
|
|
B9 |
|
=СТАНДОТКЛОНП(Имитация!A13:A512) |
|
|
|
B10 |
|
=B9/B8 |
|
|
|
B11 |
|
=МИН(Имитация!A13:A512) |
|
|
|
B12 |
|
=МАКС(Имитация!A13:A512) |
|
|
|
F13 |
|
=СЧЕТЕСЛИ(Имитация!E13:E512;”<0”) |
|
|
|
F14 |
|
=СУММАЕСЛИ(Имитация!E13:E512;”<0”) |
|
|
|
F15 |
|
=СУММАЕСЛИ(Имитация!E13:E512;”>0”) |
|
|
|
Полученный конечный результат анализа приведен в таблице 7.8.
31

|
|
|
|
|
Таблица 7.8 |
A |
B |
C |
D |
E |
F |
Показатели: |
Перем-ые, |
Объем, |
Цена, |
Посту-ния, |
Чист. прив. ст., |
|
EV |
Q |
P |
NCF |
NPV |
|
|
|
|
|
|
Среднее значение |
29,94 |
211,63 |
48,66 |
1487,22 |
3637,75 |
Стандартное отклонение |
3,58 |
55,09 |
5,51 |
577,71 |
2189,99 |
Коэффициент вариации |
0,12 |
0,26 |
0,11 |
0,39 |
0,60 |
Минимум |
19,30 |
47,78 |
32,27 |
107,98 |
-1590,68 |
Максимум |
42,13 |
399,25 |
67,43 |
3899,80 |
12783,32 |
Число cлуч. NPV< 0 |
|
|
|
|
16 |
Сумма убытков |
|
|
|
|
-12360,23 |
Сумма доходов |
|
|
|
|
1831235,10 |
|
|
|
|
|
|
Pr(E<=0) |
0,00 |
0,00 |
0,00 |
0,01 |
0,05 |
Pr(E<=МИН(E)) |
0,00 |
0,00 |
0,00 |
0,01 |
0,01 |
Pr(M(E)+ сигма<=E<= |
0,16 |
0,16 |
0,16 |
0,16 |
0,16 |
max) |
|
|
|
|
|
Pr(M(E)-сигма<= E <= |
0,34 |
0,34 |
0,34 |
0,34 |
0,34 |
M(E)) |
|
|
|
|
|
Величина ожидаемого NPV равна 3637,75 при стандартном отклонении 2189,99. Коэффициент вариации (0,60) меньше 1. Таким образом, риск данного проекта в целом ниже среднего инвестиционного портфеля фирмы. Шанс получить отрицательную величину NPV не превышает 5 %. Общее число отрицательных значений NPV в выборке составляет 16 из 500. Следовательно, с вероятностью около 95 % (95 случаев из 100) можно утверждать, что чистая современная стоимость проекта будет больше 0. При этом вероятность того, что величина NPV окажется больше чем M(NPV) + , равна 16 %. Вероятность попадания значения NPV в интервал {M(NPV) - ; M(NPV)} равна 34 %.
Лабораторная работа № 8
Анализ рисков инвестиционного проекта с использованием инструмента Анализ данных.
Статистический анализ результатов имитационного моделирования инвестиционных рисков.
Корреляционный анализ данных.
Задача 8.1. Необходимо определить степень тесноты взаимосвязей между полученными в таблице 7.3 имитационными данными (блок ячеек А13 : E512): переменные затраты - EV, объем произведенной и реализованной продукции - Q, поступления (чистые платежи) - NCF, чистая приведенная стоимость - NPV.
В качестве меры степени тесноты взаимосвязей случайных данных X и Y будем использовать коэффициент корреляции
Cor(X,Y) = Cov(X,Y)/ x y,
определяемый через стандартные отклонения данных и их коэффициент ковариации
Cov(X,Y) = M{[X-M(X)][Y-M(Y)]}.
Решение.
1. Откройте сохраненную ранее под именем Имитация книгу Excel (таблица 7.3) на листе
Имитация.
Внимание ! Если строка A1 таблицы имела объединенные ячейки (например, с названием Исходные условия эксперимента), обязательно удалите их и перепишите название в одну ячейку!
32

2.Выберите в главном меню тему Сервис, пункт Анализ данных.
3.В появившемся диалоговом окне Анализ данных выберите из списка «Инструменты анализа» пункт Корреляция.
4.В появившемся диалоговом окне Корреляция заполните поля: Входной интервал –
А13 : E512; Группирование – по столбцам; Метки в первой строке – флажок ; Параметры вывода – Новый рабочий лист - Корреляция.
5. Удалите в книге лист Результаты анализа и сохраните ее под новым именем
Статистика.
Вид полученных на новом рабочем листе Корреляция результатов после элементарного форматирования показан в таблице 8.1.
|
|
|
|
|
|
Таблица 8.1 |
|
A |
B |
C |
D |
E |
F |
1 |
|
Переменные, |
Объем, Q |
Цена, P |
Поступления, |
Чист. пр. ст., |
|
|
EV |
|
|
NCF |
NPV |
2 |
Переменные, EV |
1 |
|
|
|
|
3 |
Объем, Q |
-0,08 |
1 |
|
|
|
4 |
Цена, P |
0,04 |
-0,02 |
1 |
|
|
5 |
Поступления, |
-0,42 |
0,63 |
0,62 |
1 |
|
|
NCF |
|
|
|
|
|
6 |
Чист. пр. ст., |
-0,42 |
0,63 |
0,62 |
1 |
1 |
|
NPV |
|
|
|
|
|
|
Корреляция |
Имитация |
Лист 3 |
|
|
|
Как следует из результатов корреляционного анализа, переменные EV, Q и P являются независимыми, т.к. их коэффициенты корреляции близки к 0. NPV напрямую зависят от NCF. Между NCF, NPV и Q, P существует корреляционная зависимость средней степени. Умеренная обратная (отрицательная) корреляционная зависимость существует между NCF, NPV и EV.
Следует заметить, что близкие к нулевым значения коэффициента корреляции указывают лишь на отсутствие линейной связи между исследуемыми переменными, но не исключают возможности нелинейной зависимости, какая в действительности и существует между Q и EV .
Высокая корреляция не обязательно всегда означает наличие причинной связи, так как две исследуемые переменные могут зависеть от значения третьей.
Задача 8.2. Необходимо определить статистические характеристики полученных в таблице 7.3 имитационных данных (блок ячеек А13 : E512): переменных затрат - EV, объема произведенной и реализованной продукции - Q, поступлений (чистые платежи) - NCF, чистой приведенной стоимости - NPV.
Решение.
1.Откройте сохраненную ранее под именем Статистика книгу Excel на листе Имитация
ивыберите в главном меню тему Сервис, пункт Анализ данных. В появившемся диалоговом окне Анализ данных выберите из списка «Инструменты анализа» пункт Описательная статистика.
2.В появившемся диалоговом окне Описательная статистика укажите в соответствующих аргументах: Входной интервал – A12 : E512; Группирование – по
столбцам; Метки в первой строке – ; Параметры вывода – новый рабочий лист; Итоговая статистика – ; Уровень надежности – 95 %.
После нажатия кнопки [ОК] новый лист книги Статистика будет заполнен вычисленными характеристиками имитационных данных. Эти характеристики (после несложного форматирования и присвоения листу имени Статистика) показаны в таблице 8.2.
В третьей строке таблицы 8.2 показаны математические ожидания случайных величин,
33

вычисленных с погрешностями стандартная ошибка, определенными в четвертой строке. Медиана – значение случайной величины, которое делит площадь под кривой ее
распределения пополам. В симметричных распределениях значение медианы равно или достаточно близко к математическому ожиданию.
Мода – наиболее вероятное значение случайной величины. Если мода отсутствует, то Excel возвращает сообщение об ошибке (#Н/Д).
Эксцесс (e) – характеристика остроконечности (при положительном значении) или пологости (при отрицательном значении) распределения по сравнению с нормальной кривой.
Асимметричность (коэффициент асимметрии или скоса – s) – характеристика смещения распределения относительно математического ожидания (вправо – при положительном значении).
Для оценок значимостей коэффициента асимметрии и величины эксцесса рассчитывают их стандартные ошибки
s = [6(n-1)/(n+1)(n+3)]1/2,
e = [24n(n-2)(n-3)/(n-1)2(n+3)(n+5)]1/2,
где n – число значений случайной величины.
|
|
|
|
|
|
Таблица 8.2 |
|
A |
B |
C |
D |
E |
F |
|
|
|
|
|
|
|
1 |
|
Переменны |
Объем, Q |
Цена, P |
Поступления, |
Чист. пр. ст., |
|
|
е, |
|
|
NCF |
NPV |
|
|
EV |
|
|
|
|
2 |
|
|
|
|
|
|
3 |
Среднее |
30,148 |
210,036 |
49,012 |
1447,703 |
3487,934 |
4 |
Стандартная |
0,149 |
2,596 |
0,247 |
31,949 |
121,112 |
|
ошибка |
|
|
|
|
|
5 |
Медиана |
30,189 |
206,768 |
49,232 |
1380,257 |
3232,260 |
6 |
Мода |
34,343 |
214,232 |
45,736 |
#Н/Д |
#Н/Д |
7 |
Стандартное |
3,336 |
58,050 |
5,530 |
714,401 |
2708,142 |
|
отклонение |
|
|
|
|
|
8 |
Дисперсия |
11,128 |
3369,782 |
30,579 |
510368,855 |
7334033,276 |
|
выборки |
|
|
|
|
|
9 |
Эксцесс |
0,311 |
-0,475 |
-0,201 |
0,735 |
0,735 |
10 |
Асимметрич- |
0,090 |
0,095 |
0,033 |
0,718 |
0,718 |
|
ность |
|
|
|
|
|
11 |
Интервал |
22,703 |
307,002 |
30,728 |
4317,748 |
16367,662 |
12 |
Минимум |
19,767 |
50,734 |
33,977 |
62,605 |
-1762,679 |
13 |
Максимум |
42,470 |
357,736 |
64,704 |
4380,353 |
14604,983 |
14 |
Сумма |
15074,232 |
105017,822 |
24506,050 |
723851,582 |
1743967,001 |
15 |
Счет |
500,000 |
500,000 |
500,000 |
500,000 |
500,000 |
16 |
Уровень |
0,293 |
5,101 |
0,486 |
62,771 |
237,952 |
|
надежности |
|
|
|
|
|
|
(95,0 %) |
|
|
|
|
|
|
Статистика |
Корр-ция |
Им-ция |
|
|
|
Если отношение соответствующих величин к их стандартным ошибкам меньше трех (s/ s < 3 и e/ e < 3), то они считаются несущественными, а их наличие объясняется воздействием случайных факторов. В противном случае как асимметрия, так и эксцесс статистически значимы.
Например, в рассматриваемом случае (n = 500) для NPV получим s/ s = 0,718/0,108 6,648 > 3,
34

что свидетельствует о статистической значимости асимметрии или правосторонней скошенности распределения NPV.
Интервал – разность между максимальным и минимальным значениями случайной величины.
Счет – число значений в заданном интервале.
Сумма – сумма случайных величин в заданном интервале.
Уровень надежности – величина доверительного интервала для математического ожидания, соответствующая заданному уровню надежности (95 %). Так, например, с вероятностью 0,95 величина математического ожидания NPV попадает в интервал 3487,934 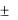 237,952.
237,952.
Следует заметить, что коэффициент асимметрии, величину эксцесса, доверительный интервал возможно вычислить с помощью функций СКОС(), ЭКСЦЕСС() и ДОВЕРИТ() мастера функций.
Для наглядности построим гистограмму распределения случайных величин NPV.
Предварительно заметим, что интервал 500 значений NPV в диапазоне |
|
|
|
(минимум = -1762,679 |
максимум = 14604,983) |
|
|
составляет величину 16367,662. Следовательно шаг составляет 16367,662/500 |
33. Для |
||
построения боле гладкой |
гистограммы необходимо выбрать ее шаг |
330 и |
выполнить |
следующие действия. |
|
|
|
1. На листе Имитация книги Статистика введите в ячейку G13 округленное |
|||
минимальное значение NPV |
-1763. |
|
|
2.С помощью инструмента Прогрессия (пункта Заполнить темы Правка главного меню) постройте арифметическую прогрессию (расположение - по столбцам) с шагом 330 и предельным значением 14605. В результате будет заполнен блок ячеек G13 : G62.
3.Выберите в главном меню тему Сервис, пункт Анализ данных. В появившемся диалоговом окне Анализ данных выберите из списка «Инструменты анализа» пункт Гистограмма. В качестве входного интервала укажите блок ячеек E13 : E512, а в качестве выходного интервала – блок ячеек G13 : G62. В параметрах вывода укажите новый рабочий лист и вывод графика.
Обратите внимание, что полученная гистограмма наглядно свидетельствует о скошенности распределения NPV вправо относительно своего среднего значения, равного
3487,934.
Литература
1.Краснов А.Е., Красников С.А., Сагинов Ю.Л., Чернов Е.А., Феоктистова Н.А. Информационные технологии автоматизированного управления. Учебно-практическое пособие для обучения аспирантов, магистров, студентов и бакалавров управленческих направлений подготовки. - М.: МГУТУ им. К.Г. Разумовского, 2014. - 76 с.
2.Краснов А.Е., Сагинов Ю.Л., Дишель Ю.Г. Феоктистова Н.А. Информационные технологии управления финансами производством и бизнесом. Учебно-практическое пособие. - М.: МГУТУ, 2014. - 48 с.
35
М |
Метро «Волгоградский проспект» |
|
(последний вагон из центра) |
Волгоградский проспект
Адрес УВЦ кафедры:
Москва, ул. Талалихина 31, комнаты:
28 (2 этаж), 50 (4 этаж)
Телефоны кафедры Информационных технологий МГУТУ им. К.Г. Разумовского
(факс) 8(495) 670-66-00; 8(495) 678-25-34; Email – kit2202@yandex.ru
Сайт кафедры – kafedrait.com
______________________________________________________
Краснов Андрей Евгеньевич, Сагинов Юрий Леонидович, Феоктистова Наталия Андреевна
Информационные технологии управления финансами, производством и бизнесом
Лабораторный практикум
Тираж: ___экз., заказ № ____
36