

ГОСЫ / Bilety
.pdfрезервированием для восстановления системы. Преимуществом резервирования журнала транзакций является то, что в большинстве случаев получившийся резервный файл будет меньше, чем аналогичный при полном резервировании и дифференциальном резервировании.
Совет. В некоторых случаях, резервная копия журнала транзакций может быть больше, чем резервная копия всей базы данных. Это возможно, если небольшая группа записей изменялась регулярно. В этом случае лучше сделать полное резервирование или создавать резервную копию журнала транзакций как можно чаще.
Четвертый тип - резервное копирование файлов и групп файлов – в этом случае создаются резервные копии отдельных файлов и групп файлов БД, а не всей базы данных целиком, то есть выполняется частичное архивирование данных (что позволяет сильно сэкономить время). В основе этого подхода лежит возможность привязывания таблицы или даже отдельного столбца к конкретному файлу или группе файлов. Все данные, принадлежащие столбцу, будут размещаться только в указанном файле. Используя данный тип резервирования, можно создать копию отдельной таблицы БД. Это бывает полезно, когда большую часть БД составляет практически неизменяемая справочная информация.
КАК ЧАСТО НАДО ВЫПОЛНЯТЬ РЕЗЕРВИРОВАНИЕ ДАННЫХ
Резервная копия БД – это ее снимок (фиксация) в определенный момент времени, а журнал транзакций содержит все изменения с тех пор, как был сделан этот снимок. Минимальные требования к активным системам – БД необходимо резервировать каждую неделю, разностную копию создавать раз в три дня, а журнал транзакций – каждый день.
Максимальные
Тип резервирования |
|
|
Частота |
|
|
|
|
|
|
Полное резервирование |
|
Ежедневно |
|
|
|
|
|
|
|
Разностная копия |
|
|
Каждые 4 часа |
|
|
|
|
||
Резервирование |
журнала |
|
Каждые |
30 |
транзакций |
|
|
минут |
|
|
|
|
|
|
Совет. Разрабатывая стратегию резервирования данных, сначала следует определить, какие данные являются более важными. Как правило, не требуется сохранять временную информацию. Также не необходимости в частом регулярном создании копий данных, доступных только для чтения.
Очевидно, что долго хранить абсолютно все резервные копии не имеет смысла. При соответствующем графике резервирования достаточно сохранять резервные копии не старше месяца. В каждом конкретном случае этот срок может изменяться как в сторону увеличения, так и в сторону сокращения.
Резервное копирование требует определенных затрат и может серьезно сказаться на производительности сервера в целом. По этой причине лучше всего выполнять его в момент наименьшей нагрузки сервера.
111
Но самое главное в любой схеме резервного копирования – это систематичность и регулярность.
РЕЖИМЫ РЕЗЕРВНОГО КОПИРОВАНИЯ
Резервное копирование может выполняться в следующих режимах:
1.режим холодного резервирования
2.режим горячего резервирования
3.режим зеркалирования
1.Как показывает практика, резервирование базы данных лучше всего проводить в «холодном» виде, когда перед резервированием БД закрывается и становится неактивной. Такое резервирование лучше всего выполнять в ночное время, когда пользователей можно отключить от базы. Однако во многих случаях этот вариант неприемлем. Во-первых, современные базы данных нередко достигают в объеме сотен и тысяч гигабайт, поэтому их копирование требует слишком много времени, особенно при копировании на магнитные ленты и даже целой ночи для этого может не хватить. Блокировать доступ к базе для выполнения резервирования на длительное время крайне нежелательно. Во-вторых, нередко СУБД работают в режиме on-line (например, на Internet - серверах), и отключение их в принципе невозможно.
2.В режиме горячего резервирования активная БД копируется на системный диск без остановки системы. Этот наиболее популярный подход к резервированию активных БД заключается в том, что в определенный момент времени начинает создаваться полная копия базы. Все последующие обращения к базе в момент резервирования либо кэшируются (то есть заносятся в специальный буфер-кэш), либо заносятся на диск с помощью переадресации. После завершения резервного копирования (получения полной копии) эти обновления вносятся в БД. Очевидно, чтобы сохранить целостность данных, БД должна устойчиво функционировать в момент резервирования
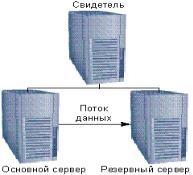
3.Зеркальное отображение баз данных работает на стандартном серверном аппаратном обеспечении и позволяет организовать непрерывный поток изменений журнала транзакций от сервера-источника (основной сервер) к серверу-получателю (резервный сервер).
В данном случае система развернута на двух функционально эквивалентных СУБДсерверах, каждый из которых поддерживает очередную резервную копию, то есть вся система дублируется. Средства зеркалирования баз данных позволяют обеспечить действительно высокую отказоустойчивость СУБД за счет создания в режиме реального времени точной копии базы данных на резервном сервере. В случае отказа основного сервера исполнение автоматически передается на резервный
сервер.
При организации зеркалирования в общем случае используются три SQL-сервера, два из которых представляют собой серверы высокой готовности. Это многопроцессорные системы с разделяемой памятью,
подключенные к RAID-дискам. Если первая система дает сбой, резервная запускается с системных дисков. Если сбой дает диск, то контроль четности RAID заставляет
112
сменить неисправный диск на запасной. Такая конфигурация выдерживает любой одиночный сбой диска или процессора.
На основном (principal) размещается главная база данных. Именно к этому серверу подключаются приложения; на нем же обрабатываются транзакции. Зеркальный сервер резерва (mirror) содержит копию; он является местом назначения переданных записей журналов транзакций и находится в состоянии ожидания. Третий сервер, свидетель (witness), отслеживает состояние двух других серверов и позволяет организовать автоматическое переключение в случае сбоя. Именно свидетель делает выбор сервера, поскольку знает, какой из них в данный момент является основным, а какой - зеркальным. Для автоматического переключения клиентов в случае отказа основного сервера используется функция автоматического перенаправления клиентов.
Вместо полного копирования журналов транзакций между серверами устанавливается специализированный сеанс зеркалирования, который используется для передачи между серверами отдельных записей транзакций. По мере того, как записи транзакций генерируются на основном сервере, они также сохраняются в журнале транзакций зеркального сервера, а изменения фиксируются в его базе данных. При этом резервные копии основной БД используются только для инициализации зеркальной БД на зеркальном сервере. Важно знать следующее:
если зеркальное отображение БД активировано, нельзя создавать обычные резервные копии и восстанавливать их для зеркальной БД;
резервную копию основной БД нельзя восстанавливать обычным образом, после переключения на зеркальный сервер, он сам скорректирует зеркальную БД.
Имеется дополнительная возможность организации доступа для чтения данных из зеркальной копии БД с использованием снимков (snapshot) базы данных. Снимок — это специальный объект, представляющий собой доступную только для чтения копию базы данных в определенный момент времени. Максимальный размер, который может иметь снимок, равен размеру исходной базы данных в момент создания.
SQL Server позволяет создавать множественные снимки базы данных в различные моменты времени. Можно настроить периодическое создание снимков — каждый день или каждый час. В случае непреднамеренного удаления данных их можно восстановить из наиболее свежего снимка. Рекомендуется создавать снимки базы данных перед выполнением сложных задач и запросов, в результате которых данные могут быть испорчены.
Сеанс зеркалирования может быть настроен для работы в синхронном или асинхронном режиме. В синхронном режиме изменения в базе основного сервера завершаются только в том случае, когда завершена запись этих изменений в базу данных на резервном сервере. В этом режиме задержки определяются скоростью передачи данных по сети и объемом изменений. Тем не менее, допустимой считается задержка не более, чем в одну или две транзакции. Асинхронный режим позволяет добиться увеличения скорости работы и сократить задержки, поскольку завершение изменений основным сервером осуществляется без подтверждения от резервной базы данных. В этом случае практически нет задержки записи.
С точки зрения клиента, восстановление в случае отказа основного сервера происходит автоматически и практически немедленно. Если основной сервер
113
становится недоступным, приложения переключаются на зеркальный сервер, который становится основным. А отключившийся основной сервер после восстановления берет на себя функцию зеркала и получает записи журналов транзакций.
Самым современным на сегодня методом зеркального копирования является метод глобального кворума. В этом случае главный и резервный сервер связаны посредством глобальной линии связи с высокой избыточностью. Клиенты могут подключаться к любому серверу, поскольку те работают параллельно, а взаимодействием серверов управляет распределенный менеджер блокировок. Дисковая подсистема высокой готовности RAID соединена с серверами в нескольких точках через вторую глобальную линию связи. Тактовые импульсы отслеживают наличие связи между различными дисками и процессорами. В этой архитектуре обе системы (и главная, и резервная) находятся в актуальном состоянии. Любой единичный сбой узла, процессора или диска незаметен для конечного пользователя, за исключением потери производительности. Эту архитектуру использует большинство приложений, поддерживающих денежные переводы, а также многие крупные биржи. К недостаткам относят:
1.Распределенный менеджер блокировок представляет собой потенциально узкое место системы
2.архитектура является дорогостоящей
3.для работы с такой системой нужны специально подготовленные специалисты
Выбор устройств и носителей для резервного копирования
Для создания резервных копий данных существует множество решений. Некоторые из них высокопроизводительны, но дороги. Другие – медленны, но очень надежны. Решение реализации резервного копирования, соответствующее индивидуальным требованиям каждой организации, зависит от следующих факторов:
емкость связана с объемом данных, резервные копии которых необходимо создавать регулярно;
надежность носителей и оборудования для резервного копирования определяет конечный результат восстановления системы после сбоя, при этом очевидно, что степень надежности зависит от бюджета организации, а также то, что увеличение надежности, как правило, увеличивает и временные затраты;
расширяемость означает возможность расширять решение резервного копирования за пределы его исходной емкости, то есть в случае увеличения объема данных, например, в результате роста организации;
скорость создания резервных копий и восстановления данных, чем выше скорость, тем выше затраты;
стоимость решения резервного копирования влияет на собственно его принятие
организацией или неприятие из-за отсутствия финансовых возможностей.
114
3.Восстановление корпоративных данных
Возвращение системы в актуальное состояние после сбоя выполняется согласно выбранной модели восстановления. На решение о выборе модели влияют типы резервируемых баз данных и регулярно выполняемого резервного копирования.
Простая модель восстановления (simple model) предназначена для баз данных, которые нужно восстанавливать до точки последнего резервного копирования. В этом случае стратегия резервирования данных должна предусматривать создание полной и дифференциальной резервных копий. Эта модель идеально подходит для большинства системных БД.
Полная модель (full model) – применяется для баз данных, которые необходимо восстанавливать до точки отказа либо до конкретной точки во времени. Стратегия резервного копирования при использовании этой модели возможна в двух вариантах; создание полных и дифференциальных резервных копий в сочетании с копиями журналов транзакций или же только полных копий и копий журналов транзакций.
Минимальное ведение журнала (bulk-logged) – сокращает использование пространства в журналах, но сохраняет большую часть возможностей полного резервного копирования. Массовые операции с данными заносятся в журнал минимально, что не позволяет контролировать каждую такую операцию в отдельности. Поэтому, если сбой данных произойдет перед создание очередной полной или дифференциальной копии, операции массовой загрузки данных придется повторить вручную. Стратегия резервного копирования при использовании этой модели возможна в двух вариантах: создание полных и дифференциальных резервных копий в сочетании с копиями журнала транзакций или же только полных копий и копий журналов транзакций.
Совет. Для каждой базы данных может быть задана своя модель восстановления. По умолчанию, как правило, используется простая модель.
Сервер горячего резерва – автоматически обновляемый сервер, начинающий работу немедленно после сбоя основного СУБД-сервера.
Сервер холодного резерва - сервер, обновляемый вручную, который в случае отказа основного СУБД-сервера нужно перевести в рабочий режим вручную.
Создавать резервные серверы позволяют такие возможности SQL Server, как зеркальное отображение баз данных, передача журналов транзакций и копирование БД.
4. Планирование резервного копирования корпоративных данных Планирование резервного копирования очень больших БД
Если необходимо разработать план резервного копирования и восстановления очень больших БД, следует воспользоваться преимуществами параллельного резервного копирования и восстановления, когда SQL Server применяет несколько потоков для чтения и записи данных и может работать одновременно со многими источниками данных. Процессы резервного копирования и восстановления используют параллельные операции ввода-вывода следующим образом:
резервное копирование/восстановление использует по одному потоку на каждое дисковое устройство, если БД была определена файлами, расположенными на разных дисках;
резервное копирование/восстановление использует по одному потоку на каждое устройство резервного копирования, когда набор резервных копий сохраняется на разные устройства резервного копирования. Стратегия резервного копирования должна быть реализована таким образом, чтобы БД использовали:
несколько дисковых накопителей для хранения данных;
несколько устройств резервного копирования для сохранения резервных копий и восстановления
данных.
115
5. Распределенные базы данных (РБД) КИС
ТЕХНОЛОГИИ РАСПРЕДЕЛЕННОЙ ОБРАБОТКИ ДАННЫХ
В рамках КИС должно быть обеспечено многоцелевое параллельное использование данных. При этом данные могут быть расположены, как на одном, так и на нескольких серверах. Стремление к интеграции и управляемости порождает стремление к централизации. Однако, на практике наблюдается и стремление к децентрализации, в значительно большей степени отражающей организационную структуру предметной области и технологию порождения и использования хранимых данных. Разные фрагменты корпоративных данных порождаются и используются, как правило, в разных подразделениях и организациях, часто географически разобщенных
(территориально распределенных). Реализация распределенных баз и технологий распределенной обработки существенно расширяет возможности, как создания, так и использования корпоративных данных.
РАСПРЕДЕЛЕННЫЕ БАЗЫ ДАННЫХ (РБД)
Распределенные базы данных (РБД) сегментируют хранимую информацию и перемещают отдельные ее блоки ближе к соответствующим клиентам. Способов организации таких баз данных много. Можно разместить таблицы на разных серверах или использовать несколько идентичных (симметричных) хранилищ. Во втором случае серверы должны взаимодействовать друг с другом с целью поддержания синхронизации, то есть, если на одном из серверов происходит обновление данных, оно должно распространяться и на все остальные серверы.
К недостаткам распределенных баз данных можно отнести возрастание сложности управления ими, но преимуществ больше. Главное из них — повышение производительности всей системы. Данные быстрее обрабатываются несколькими серверами, кроме того, данные располагаются ближе к тем пользователям, которые чаще с ними работают.
Система считается устойчивой, если она способна выдержать сбой, как минимум, одного из своих компонентов. В распределенной базе данных с симметричной схемой хранения останов одного из серверов приводит к замедлению работы пользователей, находящихся ближе к нему, но в целом система остается работоспособной. К тому же, она легко масштабируется, так как ее не нужно останавливать при добавлении еще одного сервера.
Внесимметричной системе лучше оптимизирована схема расположения данных. Чем ближе пользователи находятся к нужным им данным, тем меньше на их работу влияют сетевые задержки. В результате повышается производительность системы. Несимметричная схема способствует повышению безопасности данных, поскольку их можно физически хранить в тех подсистемах, где пользователи имеют право работать с соответствующими данными.
Вцелом, применение распределенных баз данных связано с более высоким риском. Например, требуется обеспечить соблюдение мер безопасности сразу на нескольких узлах, что достаточно не просто реализовать. Распределенные базы данных трудно проектировать и обслуживать. Порядок работы в системе может со временем поменяться, что повлечет за собой изменение схемы хранения данных. Как клиенты, так и серверы должны уметь обрабатывать запросы к данным, которые не расположены в ближайшей подсистеме. Плохо спроектированная РБД может демонстрировать меньшую производительность, чем одиночный централизованный сервер БД.
Система управления распределенными базами данных, или РСУБД, предоставляет клиентам унифицированный интерфейс доступа к данным, благодаря которому возникает иллюзия единого сервера. Если данные находятся в разных местах, РСУБД посылает запросы и обновления в соответствующие хранилища. В зависимости от того, с каким хранилищем ведется работа, производительность системы может оказаться разной, но, клиентам не приходится самим заниматься выбором сервера. В идеале, клиенты не знают, является система распределенной или нет – свойство прозрачности. Они лишь посылают ей запросы, а система возвращает клиентам результаты этих запросов. На практике распределенные базы данных проявляют разную степень "прозрачности".
116
ДВЕНАДЦАТЬ ПРАВИЛ ДЕЙТА для РБД
1.Независимость локального узла (local autonomy) – каждый локальный узел может действовать как независимая, автономная централизованная СУБД. Каждый узел отвечает за безопасность, управление параллельным выполнением, резервное копирование и восстановление данных
2.Независимость от центрального узла (no reliance on central site) – все узлы системы независимы м имеют равные возможности, а расположенные на них базы данных являются равноправными поставщиками в общее пространство данных. БД на каждом из узлов полностью защищена от НСД.
3.Независимость от сбоев (continuous operation) – функционирование всей системы не зависит от сбоя на каком-либо узле, система продолжает выполнение операций даже при неисправности узла или при расширении сети. Это возможность непрерывного доступа к данным (извест. как "24 часа в сутки, семь дней в неделю") в рамках ddb вне зависимости от их расположения и вне зависимости от операций, выполняемых на локальных узлах. Это качество можно выразить лозунгом "данные доступны всегда, а операции над ними выполняются непрерывно
4.Прозрачность расположения (location independence) – пользователь не обязан знать реальное, физическое расположение данных в РБД. Транспортировка запросов к базам данных осуществляется встроенными системными средствами
5.Прозрачность фрагментации (fragmentation independence) – пользователь видит единую логическую БД, у него нет необходимости знать структуру и имена фрагментов БД для получения доступа к ним
6.Прозрачность репликации или тиражирования данных (replication independence) – СУБД управляет всеми фрагментами так, что пользователь работает в рамках единой логической БД с актуальными данными,
7.Распределенная обработка запросов (distributed query processing) – может выполняться на нескольких узлах процессоров данных DP (Data Processor) в рамках обычного SQL-запроса. Оптимизацию запросов СУБД выполняет прозрачно для пользователя
8.Распределенная обработка транзакций (distributed transaction processing) – транзакции могут согласованно обновлять данные на нескольких различных узлах, выполнение распределенной транзакции на нескольких узлах DP происходит прозрачно для пользователя
9.Независимость от оборудования (hardware independence) – система должна выполняться на любой аппаратной платформе
10.Независимость от ОС (operationg system independence) - система должна выполняться в любой ОС
11.Независимость от сети (network independence) – система должна работать на любой сетевой платформе, то есть РСУБД должна поддерживать широкий спектр сетевых протоколов
12.Независимость от базы данных (database independence) – система должна поддерживать Базы Данных различных производителей
Правила Дейта описываю полностью распределенные базы данных, и хотя ни одна из современных РБД не соответствует всем этим правилам, тем не менее, ими следует руководствоваться при проектировании и разработке распределенной БД.
Основные практические проблемы РБД:
1. низкая и несбалансированная производительность сетей передачи данных, что в распределенных транзакциях сильно снижает общую производительность обработки данных
117
2.обеспечение целостности данных в распределенных транзакциях базируется на стандартном для транзакций принципе все или ничего и требует специального протокола двухфазного завершения транзакций, что приводит к длительной блокировке изменяемых данных
3.необходимость обеспечения совместимости данных стандартных типов, для хранения которых в разных системах используются разные физические форматы и кодировки
4.трудность выбора схемы размещения системных каталогов. Если каталог будет храниться в одной системе (централизация), то удаленный доступ будет относительно медленным. Если каталог размножить по узлам, то изменения в главном каталоге придется распространять и синхронизировать по всем узлам
5.увеличение потребностей в ресурсах для координации работы приложений с целью обнаружения и устранения тупиковых ситуаций в распределенных транзакциях
6.необходимость обеспечения совместимости СУБД разных типов
ТИПЫ РАСПРЕДЕЛЕННЫХ БД РБД подразделяются на однородные (гомогенные) или разнородные (гетерогенные).
Воднородных системах все узлы используют один и тот же тип СУБД. Однородные системы значительно проще проектировать и сопровождать, добавляя новые узлы к уже существующей распределенной системе и повышая общую производительность за счет параллельной обработки данных.
Вразнородных системах на узлах могут функционировать различные типы СУБД, использующие различные модели данных. Разнородные системы обычно возникают в тех случаях, когда локальные узлы, уже эксплуатирующие свои собственные системы баз данных, интегрируются в глобальную распределенную систему. Для организации взаимодействия с различными типами СУБД требуется обеспечить автоматическое преобразование и синхронизацию потоков и протоколов данных.
Любая распределенная СУБД должна иметь следующий набор функциональных возможностей:
1.расширенные службы установки соединений, которые должны обеспечивать доступ к удаленным узлам и позволять передавать запросы и данные м/д узлами, входящими в сеть
2.расширенные средства ведения каталога, позволяющие сохранять сведения о распределении данных
3.средства обработки распределенных запросов
4.расширенные функции управления безопасностью, которые обеспечивают соблюдение правил авторизации и прав доступа к распределенным данным
5.расширенные функции управления параллельным выполнением транзакций позволяющие поддерживать целостность копируемых данных
6.расширенные функции восстановления, учитывающие вероятность отказов в работе отдельных узлов и линий связи
118
7.Технология репликации распределенных баз данных
РЕПЛИКАЦИЯ
(тиражирование) replication
ВРСУБД - механизм внесения изменений во вторичные БД непосредственно после завершения транзакции по мере доступности серверной или клиентской БД. Метод предполагает промежуточное хранение транзакций. Обеспечивает синхронизацию (согласованность) фрагментов распределенной базы данных.
Репликация – механизм распределения копий данных между серверами РБД, в том числе, территориально разделенных.
Задачи, решаемые при помощи репликации
Репликации используют для распределения нагрузки между серверами, когда в системе работает большое количество пользователей. В этом случае на несколько серверов устанавливаются копии одних и тех же данных, а пользователи, объединенные в группы, могут обращаться к выделенному серверу. Система с такой архитектурой легко масштабируется – по мере роста предприятия и увеличения количества пользователей добавляют новые серверы и реплицируют на них необходимые данные. Еще одной типичной задачей распределения и тиражирования данных является поддержка географически удаленных пользователей. Без репликации они вынуждены работать через глобальные сети (WAN –Wide Area Network), если установить в удаленных филиалах дополнительные серверы и создать на них реплики данных, это повысит скорость доступа к данным и разгрузит основной сервер предприятия.
Вкачестве примера использования репликации на уровне ОС Windows можно привести технологию обновления учетных записей в NTдоменах
Репликация использует интуитивно понятный принцип "публикации" изменяемых данных (на главном узле) и "подписки" на изменения (на локальных узлах). Процесс репликации выполняется автоматически, во время репликации в РБД сохраняется информация о состоянии репликации и реплицированных данных, что снижает опасность потери данных. Если процедура репликации прервана (например, из-за отказа источника питания), то она возобновится с точки отказа, как только системы снова будут работать в обычном режиме. Репликация автоматизирует задачу копирования и распространения данных.
Принцип публикации и подписки (часто его называют метафорой репликации) базируется на трех основных понятиях: издатели, дистрибьюторы и подписчики (см. рисунок на следующей странице).
Издатель (publisher) – это система (сервер) исходной базы данных, которая предоставляет данные (в виде подготовленных публикаций) для репликации. Публикация – это набор статей, сгруппированных как один блок. Например, можно создать публикацию, которая будет использоваться для репликации базы данных, состоящей из нескольких таблиц, каждая из которых определена как статья. Репликация базы данных в целом как одной публикации является более эффективной операцией, чем репликация таблиц по отдельности. Публикация может состоять из одной статьи, но почти всегда состоит из нескольких. Подписчик может подписываться только на публикации, но не статьи. Поэтому для подписки на одну статью нужно сконфигурировать соответствующую публикацию, содержащую только эту статью. Статья – это отдельный набор данных, который подлежит репликации. Статья может быть целой таблицей, подмножеством таблицы, состоящим из определенных столбцов или строк, или хранимой процедурой. Эти подмножества создаются с помощью фильтров. Фильтр, используемый для создания подмножества строк, называется горизонтальным. Фильтр, используемый для создания подмножества, состоящего из столбцов, называется вертикальным фильтром.
119
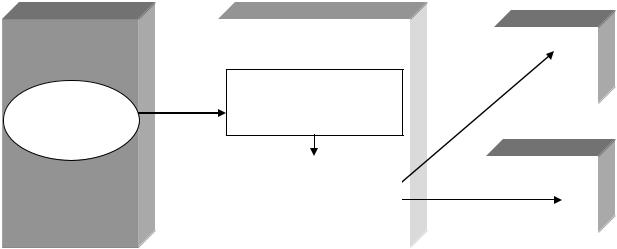
Дистрибьютор (distributor, распространитель) – это система (сервер), которая поддерживает специальную дистрибутивную базу данных (база данных распределения), используемую для поддержки и управления репликацией. В дистрибутивной БД хранится информация обо всех подписчиках и издателях.
Издатель и дистрибьютор не обязательно должны быть на одном сервере. На практике, чаще всего, для дистрибьютора используется выделенный сервер. Для каждого издателя при его создании должен быть задан дистрибьютор, и каждый издатель может иметь только одного дистрибьютора
Подписчик (subscriber) – это система (сервер), которая получает реплицированные данные и сохраняет их в реплицированной базе данных на узле. Подписчики также могут вносить изменения и являться издателями для других систем. Чтобы подписчик получал реплицированные данные, он должен подписаться на эти данные. Подписка на репликацию подразумевает конфигурирование подписчика для получения этих данных. Подписка – это информация базы данных, на которую вы подписываетесь
Среда репликации может содержать несколько подписчиков, но любой заданный набор данных, сконфигурированных для репликации, может иметь только одного издателя. Подписчик тоже может модифицировать и даже повторно публиковать данные.
Публикующий |
Распределительный |
|
сервер |
сервер |
подписчик |
|
|
Агент
Публикация репликации (публикуемые
данные)
|
Распределительный |
|
издатель |
агент |
подписчик |
|
|
|
|
|
|
СТРАТЕГИИ РЕПЛИКАЦИИ На практике выбирают одну из двух стратегий тиражирования данных в распределенной системе:
1. Тиражирование с полной репликацией – предусматривает размещение полной копии всей БД на каждом из узлов системы. РБД в данном случае называется полностью реплицированной. Стоимость устройств хранения данных и уровень затрат на передачу информации об обновлениях в этом случае будут самыми высокими. Для выполнения полной репликации рекомендуется использовать технологию снимков (SNAPSHOT). Снимок представляет собой копию БД в определенный момент времени. Эти копии обновляются через некоторый заданный интервал времени, например, 1 раз в час или в сутки. Снимок можно обновить принудительно командой REFRESH SNAPSHOT.
2. Тиражирование с избирательной репликацией – представляет собой комбинацию методов фрагментации, репликации и централизации. Одни массивы данных разделяются на локальные фрагменты. Другие, используемые на многих узлах, но редко обновляемые, подвергаются репликации. Все остальные данные хранятся централизованно. РБД в данном случае называется частично реплицированной. На практике в основном используется именно такой вариант
СПОСОБЫ РАСПРОСТРАНЕНИЯ РЕПЛИКАЦИИ
120