

ГОСЫ / Bilety
.pdf18. TCP-соединение, поддержка TCP-соединения, завершение соединения
В отличие от традиционной альтернативы — UDP, который может сразу же начать передачу пакетов, TCP устанавливает соединения, которые должны быть созданы перед передачей данных. TCP соединение можно разделить на 3 стадии:
|
Установка соединения |
|
Передача данных |
|
Завершение соединения |
Состояния сеанса TCP
CLOSED
LISTEN SYN-SENT
Сервер получил запрос на соединение, отправил ответный запрос и ожидает SYN-RECEIVED подтверждения
ESTABLISHED FIN-WAIT-1
CLOSE-WAIT
FIN-WAIT-2
LAST-ACK
TIME-WAIT
CLOSING
Установка соединения
Процесс начала сеанса TCP называется «тройным рукопожатием». Клиент, который намеревается установить соединение, посылает серверу сегмент с номером последовательности и флагом SYN. Сервер получает сегмент, запоминает номер последовательности и пытается создать сокет (буфера и управляющие структуры памяти) для обслуживания нового клиента. В случае успеха сервер посылает клиенту сегмент с номером последовательности и флагами SYN и ACK, и переходит в состояние SYN-RECEIVED. В случае неудачи сервер посылает клиенту сегмент с флагом RST.
Если клиент получает сегмент с флагом SYN, то он запоминает номер последовательности и посылает сегмент с флагом ACK, если он одновременно получает и флаг ACK (что обычно и происходит), то он переходит в состояние ESTABLISHED. Если клиент получает сегмент с флагом RST, то он прекращает попытки соединиться.
Если клиент не получает ответа в течение 10 секунд, то он повторяет процесс соединения заново.
Если сервер в состоянии SYN-RECEIVED получает сегмент с флагом ACK, то он переходит в состояние ESTABLISHED. В противном случае после таймаута он закрывает сокет и переходит в состояние CLOSED.
21

Процесс называется «тройным рукопожатием», так как несмотря на то что возможен процесс установления соединения с использованием 4 сегментов (SYN в сторону сервера, ACK в сторону клиента, SYN в сторону клиента, ACK в сторону сервера), на практике для экономии времени используется 3 сегмента.
Завершение соединения
Завершение соединения можно рассмотреть в три этапа: 1. Посылка серверу от клиента флагов FIN и ACK на завершения соединения. 2. Сервер посылает клиенту флаги ответа ACK, FIN, что соединение закрыто. 3. После получение этих флагов клиент закрывает соединение и в подтверждение отправляет серверу ACK, что соединение закрыто.
Скользящее окно TCP
Для того, чтобы передающая сторона не отправляла данные интенсивнее, чем их может обработать приемник, TCP содержит средства управления потоком. Для этого используется поле «окно». В сегментах, направляемых от приемника передающей стороне в поле «окно» указывается текущий размер приемного буфера. Передающая сторона сохраняет размер окна и отправляет данных не более, чем указал приемник. Если приемник указал нулевой размер окна, то передача данных в направлении этого узла не происходит, до тех пор пока приемник не сообщит о большем размере окна.
В рамках установленного соединения правильность передачи каждого сегмента должна подтверждаться квитанцией получателя. Квитирование - это один из традиционных методов обеспечения надежной связи. В протоколе TCP используется частный случай квитирования - алгоритм скользящего окна.
Особенность использования алгоритма скользящего окна в протоколе TCP состоит в том, что, хотя единицей передаваемых данных является сегмент, окно определено на множестве нумерованных байтов неструктурированного потока данных, поступающих с верхнего уровня и буферизуемых протоколом TCP. Получающий модуль TCP отправляет «окно» посылающему модулю TCP. Данное окно задает количество байтов (начиная с номера байта, о котором уже была выслана квитанция), которое принимающий модуль TCP готов в настоящий момент принять.
Квитанция (подтверждение) посылается только в случае правильного приема данных, отрицательные квитанции не посылаются. Таким образом, отсутствие квитанции означает либо прием искаженного сегмента, либо потерю сегмента, либо потерю квитанции. В качестве квитанции получатель сегмента отсылает ответное сообщение (сегмент), в которое помещает число, на единицу превышающее максимальный номер байта в полученном сегменте. Это число часто называют номером очереди.
Направление движения окна ->
|
|
|
|
|
<- W – размер окна -> |
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Сегменты |
отправлены, |
Сегменты отправлены, |
Сегменты могут |
Сегменты которые еще |
||||||||||||
квитанции |
|
получены, |
квитанции пока нет |
быть отправлены |
нельзя отправлять |
|||||||||||
последняя |
|
квитанция |
|
|
|
|
|
|
|
|
|
|
|
|
||
на байт с номером N |
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
На рис. показан поток байтов, поступающий на вход протокола TCP. Из потока байтов модуль TCP нарезает последовательность сегментов. Для определенности на рисунке принято направление перемещения данных справа налево. В этом потоке можно указать несколько логических границ.
22
Первая граница отделяет сегменты, которые уже были отправлены и на которые уже пришли квитанции. Следующую часть потока составляют сегменты, которые также уже отправлены, так как входят в границы, определенные окном, но квитанции на них пока не получены. Третья часть потока - это сегменты, которые пока не отправлены, но могут быть отправлены, так как входят в пределы окна. И наконец, последняя граница указывает на начало последовательности сегментов, ни один из которых не может быть отправлен до тех пор, пока не придет очередная квитанция и окно не будет сдвинуто вправо. Т.о., окно будто скользит по байтовому потоку.
Повторная передача
Надежная TCP-служба требует, чтобы все сегменты, содержащие данные, были подтверждены получателем. Когда подтверждение для сегмента не принимается в течение определенного количества времени, отправитель повторно передает сегмент.
Отправитель может повторить передачу несколько раз перед тем, как отказаться от соединения.
Для каждого соединения протокол поддерживает переменную, называемую «задержка повторной передачи» (RTO). Ее значение соответствует количеству времени, в течение которого может отсутствовать подтверждение. Как только время истекает, осуществляется повторная передача сегмента.
Период кругового обращения (RTT):
1.Время прохождения сегмента от отправителя к адресату (в разных сетях – разное время)
2.Время обработки входящего сегмента адресатом
3.Время на создание ответа (ACK-сегмент): создание окна, подтверждение нескольких сегментов
4.Время прохождения сегмента от адресата к отправителю
5.Время обработки ACK-сегмента
RTT меняется со временем и должно постоянно измеряться на протяжении всего сеанса связи.
RTO>RTT.
RTO не должно быть слишком большим, иначе будет снижена производительность сети из-за простоя. Если RTO<RTT, то сегменты передаются повторно напрасно.
Повторная передача может случиться из-за:
1. ACK-сегмент отброшен маршрутизатором (из-за его перегрузки, например)
То, что посылали, не дошло до получателя - обросил маршрутизатор, не совпадает контрольная сумма, (из-за повреждения сигнала, например)
23
21. Протокол DNS
DNS (Domain Name System — система доменных имён) — компьютерная распределённая система преобразование символьного имени (just-networks.ru) в IP-адрес (91.106.203.89) и наоборот.
DNS была разработана Полом Мокапетрисом в 1983 году.
В сети интернет DNS выполняет важную задачу, для доступа к веб-серверу необходимо знать его IP-адрес. Необходимость использования DNS обусловлена тем, что людям легче запоминать буквенные (обычно осмысленные) адреса, чем последовательность четырех цифр IP – адреса, компьютерам, в свою очередь, удобнее обрабатывать численное представление адреса (IP-адрес). Также наличие символьного имени сервера позволяет использовать так называемые виртуальные серверы, например, HTTP-серверы, отличающиеся друг от друга именем запроса (доменным именем), но использующие один и тот же IP-адрес.
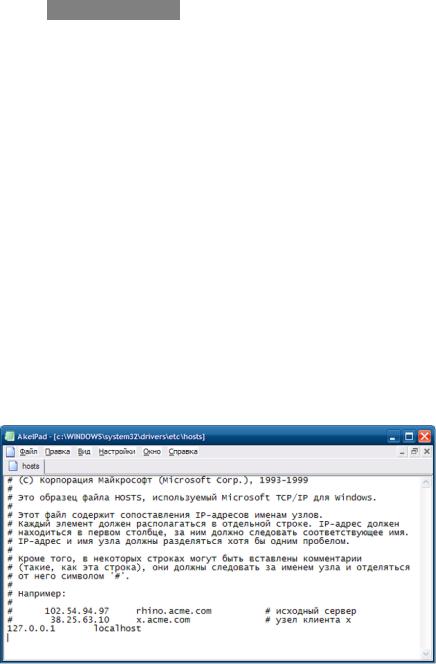
В начале для преобразования IP-адресов в символьные имена использовался текстовый файл hosts, расположенный:
В Windows: %SystemRoot%\system32\drivers\etc\hosts;
В Unix: /etc/hosts;
Пример файла hosts в Windows
Файл hosts заполнялся автоматически и централизовано на каждой ЭВМ в своей локальной вычислительной сети. Но данный подход со временем показал свою не-состоятельность, поскольку с ростом сети, количество записей в текстовом файле увеличивалось, как следствие увеличивался размер файла, ко всему прочему частая пересылка файла hosts загружала вычислительную сеть.
В итоге стала необходимость в разработке автоматизированного механизма, которым и стала распределенная система DNS.
Следует учесть, что файл hosts используется до сих пор, в частности, при настройке локального сервера на ЭВМ, в hosts записываются созданные локальные символьные имена. Например:
|
127.0.0.1 mysite.local |
24
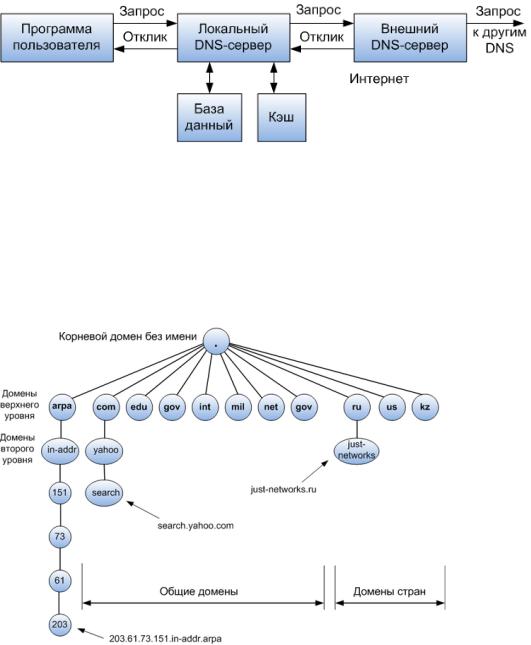
Иерархия имен в DNS
В связи с тем, что число узлов интернета растет с каждым днем, для эффективной работы DNS разработана распределенная база данных, поддерживаемая с использование иерархии DNSсерверов. Структура взаимодействия DNS серверов представлена на рисунке.
Данная схема позволяет разгрузить сервер DNS по нескольким серверам DNS, что и выполняет распределенная база данных.
В основе иерархической структуры DNS лежит представление о доменном имени и зонах. Каждый DNS сервер, отвечающий за имя, может передать ответственность за дальнейшую часть домена другому серверу, что позволяет делегировать ответственность за вновь добавленную информацию на серверы различных организаций (людей), ответственных непосредственно только за «свою» часть доменного имени.
Иерархия доменных имен начинается с корневого домена без имени (или еще как его называют «домен точка»), далее идут домены верхнего уровня или домены первого уровня. Домены верхнего уровня поделены на три зоны:
arpa это специальный домен, используемый для сопоставления адрес - имя
Семь трехсимвольных доменов называются общими (generic) доменами или организационными
(organizational) доменами.
Двухсимвольные домены, так называемые домены стран или географические домены (ru – Российская федерация, kz - Казахстан), основанные на кодах стран, в соответствии с ISO 3166.
25
Поскольку DNS поддерживает иерархию доменных имен, но никак не IP-адресов. Для решения “обратной” задачи есть специальный домен, структура которого совпадает со структурой IPадресов. Называется этот домен IN-ADDR.ARPA.
in-addr.arpa — специальная доменная зона, предназначенная для определения имени хоста по его IPv4-адресу, используя PTR-запись. Имена в домене IN-ADDR.ARPA образуют иерархию цифр, которые соответствуют IP-адресам. Правда, записываются эти имена в обратном порядке относительно написания IP-адреса.
Например, доменное имя just-networks.ru, которое имеет адрес 91.106.203.89 должна быть описана в домене in-addr.arpa как 89.203.106.91.in-addr.arpa, то есть адрес записывается в обратном порядке.
Рассмотрим на примере работу всей системы.
Предположим, мы набрали в браузере адрес ru.wikipedia.org. Браузер спрашивает у сервера DNS: «какой IP-адрес у ru.wikipedia.org»? Однако, сервер DNS может ничего не знать не только о запрошенном имени, но даже обо всём домене wikipedia.org. В этом случае сервер обращается к корневому серверу — например, 198.41.0.4. Этот сервер сообщает — «У меня нет информации о данном адресе, но я знаю, что 204.74.112.1 является ответственным за зону org.» Тогда сервер DNS направляет свой запрос к 204.74.112.1, но тот отвечает «У меня нет информации о данном сервере, но я знаю, что 207.142.131.234 является ответственным за зону wikipedia.org.» Наконец, тот же запрос отправляется к третьему DNS-серверу и получает ответ — IP-адрес, который и передаётся клиенту — браузеру.
В данном случае при разрешении имени, то есть в процессе поиска IP по имени:
браузер отправил известному ему DNS-серверу рекурсивный запрос — в ответ на такой тип запроса сервер обязан вернуть «готовый результат», то есть IP-адрес, либо пустой ответ и код ошибки NXDOMAIN;
DNS-сервер, получивший запрос от браузера, последовательно отправлял нерекурсивные запросы, на которые получал от других DNS-серверов ответы, пока не получил ответ от сервера, ответственного за запрошенную зону;
остальные упоминавшиеся DNS-серверы обрабатывали запросы нерекурсивно (и, скорее всего, не стали бы обрабатывать запросы рекурсивно, даже если бы такое требование стояло в запросе).
Иногда допускается, чтобы запрошенный сервер передавал рекурсивный запрос «вышестоящему» DNS-серверу и дожидался готового ответа.
При рекурсивной обработке запросов все ответы проходят через DNS-сервер, и он получает возможность кэшировать их. Повторный запрос на те же имена обычно не идет дальше кэша сервера, обращения к другим серверам не происходит вообще. Допустимое время хранения ответов в кэше приходит вместе с ответами (поле TTL ресурсной записи).
Рекурсивные запросы требуют больше ресурсов от сервера (и создают больше трафика), так что обычно принимаются от «известных» владельцу сервера узлов (например, провайдер предоставляет возможность делать рекурсивные запросы только своим клиентам, в корпоративной сети рекурсивные запросы принимаются только из локального сегмента). Нерекурсивные запросы обычно принимаются ото всех узлов сети (и содержательный ответ даётся только на запросы о зоне, которая размещена на узле, на DNS-запрос о других зонах обычно возвращаются адреса других серверов).
26

25. Транспортный протокол реального времени RTC
WebRTC (англ. real-time communications — коммуникации в реальном времени) — интернетпротокол, проект с открытым исходным кодом, предназначенный для организации передачи потоковых данных между браузерами или другими поддерживающими его приложениями по технологии точка-точка.
Применение и технология
После встраивания WebRTC в Chrome (а возможно ещё и в ряд других популярных браузеров), браузер от Google может составить конкуренцию Skype.[7]
Сторонние веб-разработчики смогут создавать собственные приложения, на основе технологии WebRTC, для голосовой и видеосвязи.
В WebRTC используются два аудиокодека, созданных в GIPS,[прояснить][каких?]
VP8 (WebM).
Черновик стандарта «WebRTC Audio Codec and Processing Requirements» от содержит требование поддержки клиентами форматов Opus и G.711.[8]
а также видеоформат
15 октября 2013 года
Интеграция в браузеры
Технология WebRTC в той или иной степени поддерживается в Google Chrome с 17 версии, Opera с 12 версии и Firefox с 18 версии (без флага — с 22-й). Для других браузеров можно использовать расширение webrtc4all[9].
В начале 2013 года осуществлён первый видеозвонок между Chrome и Firefox[10][11].
Пример использования
Браузеры, которые поддерживают WebRTC имеют функцию getUserMedia с вендорным префиксом. Она используется для получения доступа к устройствам и принимает на вход 3 параметра: вид устройства (аудио, видео или оба), функция, которая получит управление, если всё пройдёт успешно, и функция, которая получит управление в случае ошибки.[12]
navigator.getUserMedia({audio: true, video: true}, success, error);
function success(pLocalMediaStream){ /* обработка видео потока */
}
function error(pError){ /* вывод ошибки */ console.log(pError);
}
27
ОС UNIX Горьков
1. История ОС UNIX. Основные понятия ОС UNIX (Пользователь, интерфейс пользователя, привилегированный пользователь, программы, команды, процессы, перенаправление ввода/вывода).
Возникновение и первая редакция ОС UNIX
Принято считать, что исходным толчком к появлению ОС UNIX явилась работа Кена Томпсона по созданию компьютерной игры “Space Travel”. Он делал это в 1969 году на компьютере Honeywell 635, который до этого использовался для разработки проекта MAC. В это же время Кен Томпсон, Деннис Ритчи и другие сотрудники Bell Labs предложили идею усовершенствованной файловой системы, прототип которой был реализован на компьютере General Electric 645. Однако компьютер GE-645, который был рассчитан на работу в режиме разделения времени и не обладал достаточной эффективностью, не годился для переноса Space Travel. Томпсон стал искать замену и обнаружил, что появившийся к этому времени 18-разрядный компьютер PDP-7 с 4 килословами оперативной памяти и качественным графическим дисплеем вполне для этого подходит.
После того, как игра была успешно перенесена на PDP-7, Томпсон решил реализовать на PDP-7 разработанную ранее файловую систему. Дополнительным основанием для этого решения было то, что компания Bell Labs испытывала потребность в удобных и дешевых средствах подготовки и ведения документации. В скором времени на PDP-7 работала файловая система, в которой поддерживались: понятие inodes, подсистема управления процессами и памятью, обеспечивающая использование системы двумя пользователями в режиме разделения времени, простой командный интерпретатор и несколько утилит. Все это еще не называлось операционной системой UNIX, но уже содержало родовые черты этой ОС.
Название придумал Брайан Керниган. Он предложил назвать эту двухпользовательскую систему UNICS (Uniplexed Information and Computing System). Название понравилось, поскольку, помимо прочего, оно напоминало об участии сотрудников Bell Labs в проекте Multics. В скором времени UNICS превратилось в UNIX.
В ноябре 1971 года был опубликован первый выпуск документации по ОС UNIX (”Первая редакция”).
Вторая редакция появилась в 1972 году. Наиболее существенным качеством “Второй редакции” было то, что система была переписана на языке Би (”B”). Язык и интерпретирующая система программирования были разработаны Кеном Томпсоном под влиянием существовавшего языка
BCPL.
Появление варианта системы, написанного не на языке ассемблера, было заметным продвижением. Однако сам язык Би во многом не удовлетворял разработчиков. Подобно языку BCPL язык Би был бестиповым, в нем поддерживался только один тип данных, соответствующий машинному слову. Другие типы данных эмулировались библиотекой функций. Деннис Ритчи, который всегда увлекался языками программирования, решил устранить ограничения языка Би, добавив в язык систему типов. Так возник язык Си (”C”). В 1973 году Томпсон и Ритчи переписали систему на языке Си. К этому времени существовало около 25 установок ОС UNIX, и это была “Четвертая редакция”.
Виюле 1974 года появилась “Пятая редакция” ОС UNIX.
В1975 году компания Bell Labs выпустила “Шестую редакцию” ОС UNIX, известную как V6 или Исследовательский UNIX. Эта версия системы была первой коммерчески доступной вне Bell Labs.
Кэтому времени большая часть системы была написана на языке Си. Небольшие размеры языка и наличие сравнительно легко переносимого компилятора придавали ОС UNIX V6 новое качество реально переносимой операционной системы. Кроме того, потенциальное наличие на разных аппаратных платформах компилятора языка Си делало возможным разработку мобильного прикладного программного обеспечения.
28

В настоящее время UNIX – настоящая Вавилонская башня. Различные варианты UNIX
разрабатывают Sun Microsystems (SunOS, Solans), Hewlett-Packard (HP-UX), IBM (AIX), SCO (SCO
UNIX); также существуют клоны UNIX, рассчитанные на работу на базе платформы Intel (BSD,
Linux).
Основные понятия
На первый взгляд UNIX выглядит неоправданно сложной операционной системой. Но под кажущейся сложностью скрывается очень простая и элегантная операционная система. Отдельные детали могут быть сложными, но общие принципы – просты.
Одним из достоинств ОС UNIX является то, что система базируется на небольшом числе интуитивно ясных понятий. Однако, несмотря на простоту этих понятий, к ним нужно привыкнуть. Без этого невозможно понять существо UNIX.
Пользователь
С самого начала ОС UNIX замышлялась как интерактивная система. Другими словами, UNIX предназначен для терминальной работы. Чтобы начать работать, человек должен “войти” в систему, введя со свободного терминала свое учетное имя (account name) и, возможно, пароль (password). Человек, зарегистрированный в учетных файлах системы, и, следовательно, имеющий учетное имя, называется зарегистрированным пользователем системы. Регистрацию новых пользователей обычно выполняет администратор системы. Пользователь не может изменить свое учетное имя, но может установить и/или изменить свой пароль. Пароли хранятся в отдельном файле в закодированном виде.
Все пользователи ОС UNIX явно или неявно работают с файлами. Файловая система ОС UNIX имеет древовидную структуру. Промежуточными узлами дерева являются каталоги со ссылками на другие каталоги или файлы, а листья дерева соответствуют файлам или пустым каталогам. Каждому зарегистрированному пользователю соответствует некоторый каталог файловой системы, который называется “домашним” (home) каталогом пользователя. При входе в систему пользователь получает неограниченный доступ к своему домашнему каталогу и всем каталогам и файлам, содержащимся в нем. Потенциально возможен доступ и ко всем другим файлам, однако он может быть ограничен, если пользователь не имеет достаточных привилегий.
Интерфейс пользователя
Традиционный способ взаимодействия пользователя с системой UNIX основывается на использовании командных языков (правда, в настоящее время все большее распространение получают графические интерфейсы). После входа пользователя в систему для него запускается один из командных интерпретаторов (в зависимости от параметров, сохраняемых в файле /etc/passwd). Обычно в системе поддерживается несколько командных интерпретаторов (пошаговое исполнение команд программы (в противоположность компиляции)) с похожими, но различающимися своими возможностями командными языками. Общее название для любого командного интерпретатора ОС UNIX – shell (оболочка), поскольку любой интерпретатор представляет внешнее окружение ядра системы.
Вызванный командный интерпретатор выдает приглашение на ввод пользователем командной строки. После выполнения очередной командной строки и выдачи на экран терминала или в файл соответствующих результатов, shell снова выдает приглашение на ввод командной строки, и так до тех пор, пока пользователь не завершит свой сеанс работы путем ввода команды logout или нажатием комбинации клавиш Ctrl-d.
Командные языки, используемые в ОС UNIX, достаточно просты, чтобы новые пользователи могли быстро начать работать, и достаточно мощны, чтобы можно было использовать их для написания сложных программ. Последняя возможность опирается на механизм командных файлов (shell scripts), которые могут содержать произвольные последовательности командных строк. При указании имени командного файла вместо очередной команды интерпретатор читает файл строка за строкой и последовательно интерпретирует команды.
29
Привилегированный пользователь
Ядро ОС UNIX идентифицирует каждого пользователя по его идентификатору (UID – User Identifier), уникальному целому значению, присваиваемому пользователю при регистрации в системе. Кроме того, каждый пользователь относится к некоторой группе пользователей, которая также идентифицируется некоторым целым значением (GID – Group IDentifier). Значения UID и GID для каждого зарегистрированного пользователя сохраняются в учетных файлах системы и приписываются процессу, в котором выполняется командный интерпретатор, запущенный при входе пользователя в систему. Эти значения наследуются каждым новым процессом, запущенным от имени данного пользователя, и используются ядром системы для контроля правомочности доступа к файлам, выполнения программ и т.д.
Понятно, что администратор системы, который, естественно, тоже является зарегистрированным пользователем, должен обладать большими возможностями, чем обычные пользователи. В ОС UNIX эта задача решается путем выделения одного значения UID (нулевого). Пользователь с таким UID называется суперпользователем (superuser) или root. Он имеет неограниченные права на доступ к любому файлу и на выполнение любой программы. Кроме того, такой пользователь имеет возможность полного контроля над системой. Он может остановить ее и даже разрушить.
Суперпользователь должен хорошо знать базовые процедуры администрирования ОС UNIX. Он отвечает за безопасность системы, ее правильное конфигурирование, добавление и исключение пользователей, регулярное копирование файлов и т.д.
Еще одним отличием суперпользователя от обычного пользователя ОС UNIX является то, что на суперпользователя не распространяются ограничения на используемые ресурсы. Для обычных пользователей устанавливаются такие ограничения как максимальный размер файла, максимальное число сегментов разделяемой памяти, максимально допустимое пространство на диске и т.д. Суперпользователь может изменять эти ограничения для других пользователей, но на него они не действуют.
Программы
ОС UNIX одновременно является операционной средой использования существующих прикладных программ и средой разработки новых приложений. Новые программы могут писаться на разных языках (Фортран, Паскаль, Модула, Ада и др.). Однако стандартным языком программирования в среде ОС UNIX является язык Си (который в последнее время все больше заменяется на C++). Это объясняется тем, что, во-первых, сама система UNIX написана на языке Си, а, во-вторых, язык Си является одним из наиболее качественно стандартизованных языков.
Поэтому программы, написанные на языке Си, при использовании правильного стиля программирования обладают весьма высоким уровнем мобильности, т.е. их можно достаточно просто переносить на другие аппаратные платформы, работающие как под управлением ОС UNIX, так и под управлением ряда других операционных систем (например, DEC Open VMS или MS
Windows NT).
Выполняемая программа может быть запущена в интерактивном режиме как команда shell или выполнена в отдельном процессе, образуемом уже запущенной программой.
Команды
Любой командный язык семейства shell фактически состоит из трех частей: служебных конструкций, позволяющих манипулировать с текстовыми строками и строить сложные команды на основе простых команд; встроенных команд, выполняемых непосредственно интерпретатором командного языка; команд, представляемых отдельными выполняемыми файлами.
Процессы
Процесс в ОС UNIX – это программа, выполняемая в собственном виртуальном адресном пространстве. Когда пользователь входит в систему, автоматически создается процесс, в котором выполняется программа командного интерпретатора. Если командному интерпретатору встречается
30