

tiit_ekzamen
.docx|
1.Интеллектуальная компьютерная система. Принципиальные отличия интеллектуальной компьютерной системы от традиционной. Интеллектуальная система — это техническая или программная система, способная решать задачи, традиционно считающиеся творческими, принадлежащие конкретной предметной области, знания о которой хранятся в памяти такой системы. Структура интеллектуальной системы включает три основных блока — базу знаний, решатель и интеллектуальный интерфейс. ИИС – это такая информационная система, которая работает со знаниями. Т.е. ее можно рассматривать как фабрику, производящую информацию, в которой заказом является информационный запрос, сырьем – исходные данные, продуктом – требуемая информация. (Способность к самообучению – возможность автоматического извлечения знаний для решения задач из накапливаемого опыта конкретных ситуаций.) Классификация ИИС:1)Системы с интеллектуальным интерфейсом.2) Экспертные системы. 3) Самообучающиеся системы.4) Интеллектуальные базы данных.5) Системы с естественно-языковым интерфейсом (ЕЯ системы)6) Гипертекстовые системы.7) Контекстные системы помощи.8) Системы с когнитивной графикой.9) Классифицирующие системы.10) Доопределяющие системы.11) Трансформирующие системы.12) Многоагентные системы.13) Индуктивные системы.14) Нейронные сети.15) Системы на прецедентах.16) Информационные хранилища.
|
2. Архитектура интеллектуальной системы. База знаний. Машина обработки знаний.
ПЕРВЫЙ АРХИТЕКТУРНЫЙ АСПЕКТ Функциональное назначение персональных информационных систем, реализация двух групп функций:
Проблемы, связанные с реализацией: автоформализация профессиональных знаний пользователей; интеллектуализация взаимодействия с автоформализованными профессиональными знаниями. ВТОРОЙАРХИТЕКТУРНЫЙ АСПЕКТ Технические возможности реализации информационных систем. Четыре уровня рассмотрения персональных информационных систем:
Два типа ИС:
ТРЕТИЙАРХИТЕКТУРНЫЙ АСПЕКТ Эстетические потребности пользователей, реализуемые в сфере деятельности и развития:
База знаний - это совокупность моделей, правил и факторов (данных), порождающих анализ и выводы для нахождения решений сложных задач в некоторой предметной области. Основная ценность в базе знаний – совокупность единиц знаний, которые представляют собой формализованные представления, отражения объектов проблемной области и взаимодействий, действий над объектами и другие элементы. В базах знаний можно хранить лишь множество аксиом, а все остальные знания получают путем логического вывода.
|
3. База знаний. Требования, предъявляемые к базам знаний. Критерии качества. База знаний — это семантическая модель, описывающая предметную область и позволяющая отвечать на такие вопросы из этой предметной области, ответы на которые в явном виде не присутствуют в базе. База знаний является основным компонентом систем Искусственного интеллекта и Экспертных систем. Большинство БЗ ограничены в некоторой специальной, обычно узкой предметной области, в которой они сосредоточены. При создании БЗ технология ИИ позволяет встраивать в компьютер механизм и способности вывода, основывающиеся на фактах и отношениях, содержащихся в БЗ. База знаний - это совокупность моделей, правил и факторов (данных), порождающих анализ и выводы для нахождения решений сложных задач в некоторой предметной области. Основная ценность в базе знаний – совокупность единиц знаний, которые представляют собой формализованные представления, отражения объектов проблемной области и взаимодействий, действий над объектами и другие элементы. В базах знаний можно хранить лишь множество аксиом, а все остальные знания получают путем логического вывода. Требования к БЗ: полнота сведений, корректность, непротиворечивость. Наиболее важный параметр БЗ — качество содержащихся знаний. Лучшие БЗ включают самую релевантную, достоверную и свежую информацию, имеют совершенные системы поиска информации и тщательно продуманную структуру и формат знаний. Виды знаний: факторы, закономерности(утверждения), алгоритмы (програмы). В зависимости от уровня сложности систем, в которых применяются базы знаний, различают:
Простые базы знаний могут использоваться для создания экспертных систем и хранения данных об организации: документации, руководств, статей технического обеспечения. Главная цель создания таких баз — помочь менее опытным людям найти существующее описание способа решения какой-либо проблемы предметной области. Онтология может служить для представления в базе знаний иерархии понятий и их отношений. Онтология, содержащая еще и экземпляры объектов не что иное, как база знаний. Системы основанные на знаниях реализуются на базе следующих интеллектуальных алгоритмов:
|
|
4.Виды знаний и модели их представления. Виды: Фактические и стратегические знания Знания определяются как «...основные закономерности предметной области, позволяющие человеку решать конкретные производственные, научные и другие задачи, то есть факты, понятия, взаимосвязи, оценки, правила, эвристики (иначе фактические знания), а также стратегии принятия решения в этой области (иначе стратегические знания)». Факты и эвристики Некоторые авторы разделяют знания на две большие категории: факты и эвристики. Первая категория (факты) указывает на хорошо известные в той или иной предметной области обстоятельства. Такие знания еще называют текстовыми, имея в виду достаточную их освещенность в специальной литературе и учебниках. Вторая категория знаний (эвристики) основывается на индивидуальном опыте специалиста (эксперта) в предметной области, накопленном в результате многолетней практики. Эта категория нередко играет решающую роль при построении интеллектуальных программ. Сюда относятся такие знания, как «способы удаления бесполезных гипотез», «способы использования нечеткой информации», «способы разрешения противоречий» и т. п. Декларативные и процедурные знания Под декларативными знаниями подразумевают знания типа «А это В», и они характерны для баз данных. Например «в час пик на улице много машин», «зажженная плита — горячая» К процедурным знаниям относятся сведения о способах оперирования или преобразования декларативных знаний. Интенсиональные и экстенсиональные знания Интенсиональные знания — это знания о связях между атрибутами объектов данной предметной области. Они оперируют абстрактными объектами, событиями и отношениями. Экстенсиональные знания представляют собой данные, характеризующие конкретные объекты, их состояния, значения параметров в пространстве и времени. Глубинные и поверхностные знания В глубинных знаниях отражается понимание структуры предметной области, назначение и взаимосвязь отдельных понятий (глубинные знания в фундаментальных науках — это законы и теоретические основания). Поверхностные знания обычно касаются внешних эмпирических ассоциаций с каким-либо феноменом предметной области. Большинство экспертных систем основано на применении поверхностных знаний. Это, однако, нередко не мешает достигать вполне удовлетворительных результатов. Вместе с тем, опора на глубинные представления помогает создавать более мощные, гибкие и интеллектуальные адаптивные системы. Наглядным примером может служить медицина. Здесь молодой и недостаточно опытный врач часто действует по поверхностной модели: «Если кашель — то пить таблетки от кашля, если ангина — то эритромицин» и т. п. В то же время опытный врач, основываясь на глубинных знаниях, способен порождать разнообразные способы лечения одной и той же болезни в зависимости от индивидуальных особенностей пациента, его состояния, наличия доступных лекарств в аптечной сети и т. д. Глубинные знания являются результатом обобщения первичных понятий предметной области в некоторые более абстрактные структуры. Степень глубины и уровень обобщенности знаний непосредственно связаны с опытом экспертов и могут служить показателем их профессионального мастерства. Жесткие и мягкие знания Жесткие знания позволяют получать однозначные четкие рекомендации при заданных начальных условиях. Мягкие знания допускают множественные, «размытые» решения и различные варианты рекомендаций. Характеристика различных предметных областей по глубине и жесткости дает возможность проследить тенденцию развития интеллектуальных систем. Модели представления: Формальные логические методы. Логические модели представления знаний основаны на исчислении предикатов. Предикат – это высказывание, в которое можно подставлять аргументы. Если аргумент один – то предикат выражает свойство аргумента, если больше – то отношение между аргументами. В логических моделях факт – формула в некоторой логике, система знаний – совокупность формул. Таким образом, предметная область описывается в виде набора аксиом. Пример применения – Prolog-программа. Основные операции: логический вывод (доказательство теорем). Достоинства: - формальный аппарат вывода новых фактов (знаний) из известных фактов (знаний); - возможность контроля целостности; - простая и ясная нотация. Недостатки: - знания трудно структурировать и поэтому к предметной области предъявляются высокие требования и ограничения; - при большом количестве формул их совокупность трудно обозрима, и вывод идет очень долго. Семантические сети. Семантика – наука, устанавливающая соответствие между символами и объектами, которые они обозначают. Т. е. семантическая сеть – смысловая сеть. Первые семантические сети были разработаны в качестве языка-посредника для систем машинного перевода. Семантическая сеть – структура для представления знаний в виде узлов (понятий), соединенных дугами (отношения между понятиями). В качестве понятий обычно выступают абстрактные или реальные объекты. Типы отношений: - часть – целое (класс – подкласс, множество – элемент); - функциональные связи (определяются глаголами «производит», «влияет»); - количественные (больше, меньше, равно); - пространственные (за, под, далеко от); - временные (в течение, раньше, позже); - атрибутивные (имеет свойство, имеет значение); - логические связи («и», «или», «не»); - элемент класса – пример (собака – кличка собаки). Классификация семантических сетей по отношениям между понятиями: 1. По количеству отношений: - однородные – на графе представлен один тип отношений; - неоднородные – на графе представлены различные типы отношений. 2. По типу отношений: - бинарные – связаны пары объектов; - n-арные – отношениями связано более двух понятий или объектов. Проблема поиска решения в базе знаний типа «семантическая сеть» сводится к поиску фрагмента сети, соответствующего некоторой подсети, отражающей поставленный запрос. Основные операции: сопоставление с образцом, поиск, замена, взятие копии. Достоинства: - знания хорошо структурированы, структура понятна человеку; - соответствие организации долговременной памяти у человека. Недостатки: - сложность организации процедуры поиска; - при большом объеме сеть трудно обозрима. Фреймы. Фрейм (в переводе – каркас) – это абстрактный образ для представления некоторого стереотипа восприятия. Пример: фрейм комнаты – жилое помещение с 4-мя стенами, полом, потолком, дверью, n окнами и площадью m кв. м. Из этого описания нельзя убрать ни один из элементов, не изменив абстрактный образ, но можно описать реальную комнату, задав значение свойств и характеристик некоторым (или всем) элементам фрейма с помощью значений слотов. Слоты – это характеристики, свойства и уточнения элементов фрейма или фрейма в целом, существенные в разрабатываемой модели (в примере n и m). В общем случае слот определяется принадлежностью к элементу фрейма, именем, множеством значений, одно из которых он может принимать, способом получения своего значения, присоединенной процедурой для определения своего значения (при необходимости). Различают фреймы-образцы – фреймы, хранящиеся в базе знаний, у которых только часть слотов может иметь значения, и фреймы-экземпляры, у которых все слоты должны иметь значения и которые создаются для отображения реальных фактических ситуаций на основе поступающих данных. Способы получения слотом значения при формировании фрейма-экземпляра: - по умолчанию (от фрейма-образца); - через наследование свойств от другого фрейма в слоте «это»; - по формуле, указанной в слоте; - через присоединенную процедуру; - явно из диалога с пользователем; - из базы данных. Если в качестве значения слота выступает имя другого фрейма, то образуется сеть фреймов. Виды фреймов: - фреймы-структуры (залог, вексель); - фреймы-роли (кассир, клиент); - фреймы-сценарии (собрание, праздник, банкротство); - фреймы-ситуации (рабочий режим устройства, авария). Основные операции: присвоение слотам значений. Достоинства: - гибкость и наглядность; - отражают концептуальную основу организации памяти человека. Недостатки: - отсутствие формальной семантики, что затрудняет сравнение свойств представления знаний различных языков фреймов, а также полное логическое объяснение языка фреймов. Продукции. Продукционная модель (продукционные правила) представляет знания условными предложениями вида: ЕСЛИ (условие), ТО (действие). Условие – некоторое предложение-образец, по которому осуществляется поиск в базе знаний. При успешном исходе поиска выполняется некоторое действие. Действия могут быть промежуточными (выступающими далее как условия) илитерминальными (целевыми), завершающими работу системы. Здесь данные – это факты, хранящиеся в базе фактов, на основании которых запускается машина вывода (интерпретатор правил), обрабатывающая правила из продукционной базы знаний. Возможны два подхода к выводу: 1. Прямая цепочка рассуждений.Задается начальная ситуация (условие или набор условий). Необходимо на основании правил выполнить прогноз дальнейшего развития ситуации: «настоящее ® будущее». 2. Обратная цепочка рассуждений. Задается конкретная ситуация и необходимо проанализировать, какие условия и причины привели к этой ситуации: «прошлое ¬ настоящее». Основные операции: вывод (применение правила, определение правила-преемника и т.д.) Достоинства: - разделение знания и управления. Это обеспечивает высокую модульность продукционных правил, т. е. отсутствие синтаксического взаимодействия между правилами; - наглядность; - легкость дополнения и модификации; - простой механизм логического вывода. Недостаток: - при большом количестве правил их совокупность трудно обозрима, и вывод идет очень долго. |
5. Четкие и нечеткие множества и знания. Мн-во А – четкое мн-во, если А – часть некоторого универсального для прикладной задачи мн-во U, характеризующегося условиями:
Нечеткое мн-во – это модель мн-ва с нечеткими или «размытыми границами». Нечеткое
мн-во Ã характеризуется функцией
принадлежности, заданной на универсальном
мн-ве U
и принимающей значения во мн-ве [0,1]: Под
нечётким множеством А понимается
совокупность Функция Пусть А нечёткое множество с элементами из универсального множества Х и множеством принадлежностей М=[0,1] . Тогда -
Носителем (суппортом) нечёткого
множества suppA называется
множество -
Величина
-
Нечёткое множество пусто, если -
Нечёткое множество унимодально,
если -
Элементы Смысл термина нечеткость многозначен. Трудно претендовать на исчерпывающее определение этого понятия, поэтому рассмотрим лишь основные его компоненты, к которым относятся следующие:
Недетерминированность выводов. Это характерная черта большинства систем искусственного интеллекта. Недетерминированность означает, что заранее путь решения конкретной задачи в пространстве ее состояний определить невозможно. Поэтому в большинстве случаев методом проб и ошибок выбирается некоторая цепочка логических заключений, согласующихся с имеющимися знаниями, а в случае если она не приводит к успеху, организуется перебор с возвратом для поиска другой цепочки и т.д. Такой подход предполагает определение некоторого первоначального пути. Для решения подобных задач предложено множество эвристических алгоритмов, например, алгоритм А*, разработанный на этапах становления искусственного интеллекта. Многозначность. Многозначность интерпретации — обычное явление в задачах распознавания. При понимании естественного языка серьезными проблемами становятся многозначность смысла слов, их подчиненности, порядка слов в предложении и т. п. Проблемы понимания смысла возникают в любой системе, взаимодействующей с пользователем на естественном языке. Распознавание графических образов также связано с решением проблемы многозначной интерпретации. При компьютерной обработке знаний многозначность необходимо устранять путем выбора правильной интерпретации, для чего разработаны специальные методы, например, метод релаксации, предназначенный для систематического устранения многозначности при интерпретации изображений. Ненадежность знаний и выводов. Ненадежность знаний означает, что для оценки их достоверности нельзя применить двухбалльную шкалу (1 — абсолютно достоверные; 0 — недостоверные знания). Для более тонкой оценки достоверности знаний применяется вероятностный подход, основанный на теореме Байеса, и другие методы. Например, в экспертной системе MYCIN, предназначенной для диагностики и выбора метода лечения инфекционных заболеваний, разработан метод вывода с использованием коэффициентов уверенности. Широкое применение на практике получили нечеткие выводы, строящиеся на базе нечеткой логики, ведущей свое происхождение от теории нечетких множеств. Неполнота знаний и немонотонная логика. Абсолютно полных знаний не бывает, поскольку процесс познания бесконечен. В связи с этим состояние базы знаний должно изменяться с течением времени. В отличие от простого добавления информации, как в базах данных, при добавлении новых знаний возникает опасность получения противоречивых выводов, т.е. выводы, полученные с использованием новых знаний, могут опровергать те, что были получены ранее. Еще хуже, если новые знания будут находиться в противоречии со «старыми», тогда механизм вывода может стать неработоспособным. Многие экспертные системы первого поколения были основаны на модели закрытого мира, обусловленной применением аппарата формальной логики для обработки знаний. Модель закрытого мира предполагает жесткий отбор знаний, включаемых в базу, а именно: БЗ заполняется исключительно верными понятиями, а все, что ненадежно или неопределенно, заведомо считается ложным. Другими словами, все, что известно базе знаний, является истиной, а остальное — ложью. Такая модель имеет ограниченные возможности представления знаний и таит в себе опасность получения противоречий при добавлении новой информации. Тем не менее, эта модель достаточно распространена; например, на ней базируется язык PROLOG. Недостатки модели закрытого мира связаны с тем, что формальная логика исходит из предпосылки, согласно которой набор определенных в системе аксиом (знаний) является полным (теория является полной, если каждый ее факт можно доказать, исходя из аксиом этой теории). Для полного набора знаний справедливость ранее полученных выводов не нарушается с добавлением новых фактов. Это свойство логических выводов называется монотонностью. К сожалению, реальные знания, закладываемые в экспертные системы, крайне редко бывают полными. Неточность знаний. Известно, что количественные данные (знания) могут быть неточными, при этом существуют количественные оценки такой неточности (доверительный интервал, уровень значимости, степень адекватности и т.д.). Лингвистические знания также могут быть неточными. Для учета неточности лингвистических знаний используется теория нечетких множеств, предложенная Л. Заде в 1965 г. Этому ученому принадлежат слова: «Фактически нечеткость может быть ключом к пониманию способности человека справляться с задачами, которые слишком сложны для решения на ЭВМ». Развитие исследований в области нечеткой математики привело к появлению нечеткой логики и нечетких выводов, которые выполняются с использованием знаний, представленных нечеткими множествами, нечеткими отношениями, нечеткими соответствиями и т. д.
|
6. Смысл. Смысловое представление знаний. Термин семантическая означает смысловая, а сама семантика — это наука, устанавливающая отношения между символами и объектами, которые они обозначают, то есть наука, определяющая смысл знаков. В самом общем случае семантическая сеть представляет собой информационную модель предметной области и имеет вид графа, вершины которого соответствуют объектам предметной области, а дуги — отношениям между ними. Дуги могут быть определены разными методами, зависящими от вида представляемых знаний. Обычно дуги, используемые для представления иерархии, включают дуги типа «множество», «подмножество», «элемент». Семантические сети, применяемые для описания естественных языков, используют дуги типа «агент», «объект», «реципиент». Понятиями обычно выступают абстрактные или конкретные объекты, а отношения — это связи типа: «это» («is»), «имеет частью» («has part»), «принадлежит», «любит». Характерной особенностью семантических сетей является обязательное наличие трех типов отношений:
Можно ввести несколько классификаций семантических сетей. Например, по количеству типов отношений:
По типам отношений:
Наиболее часто в семантических сетях используются следующие отношения:
Проблема поиска решения в базе знаний типа семантической сети сводится к задаче поиска фрагмента сети, соответствующего некоторой подсети, соответствующей поставленному вопросу. В семантических сетях существует возможность представлять знания более естественным и структурированным образом, чем в других формализмах. Основным преимуществом является то, что она более других соответствует современных представлениям об организации долговременной памяти человека. Недостатком этой модели является сложность организации процедуры поиска вывода на семантической сети. Для реализации семантических сетей существуют специальные сетевые языки (NET, SIMER+MIR и др.). Известны системы, использующие семантические сети в качестве языка представления знаний— PROSPECTOR, CASNET, TORUS.
|
|
7. Предметная область. Предметная область - множество всех предметов, свойства которых и отношения между которыми рассматриваются в научной теории. В логике - предполагаемая область возможных значений предметных переменных логического языка. Предметная область - это часть реального мира, рассматриваемая в рамках определенного контекста. Под контекстом можно понимать область исследования или область, которая является объектом определенной деятельности. Предметная область или: универсум рассуждения, область теории - множество объектов, рассматриваемых в пределах отдельного рассуждения, научной теории. Предметная область включает прежде всего индивиды, то есть элементарные объекты, изучаемые теорией, а также свойства, отношения и функции, рассматриваемые в теории. Например, предметная область в зоологии служит множество животных, в теории чисел - натуральный ряд чисел, в логике предикатов - любая фиксированная область, содержащая по меньшей мере один предмет. Предметная область, соединяющая в единство разнотипные объекты, изучаемые в какой теории, яввляе собой логическую абстракцию. Допущение существования предметной области нетривиальное, ибо в обычных рассуждениях далеко не всегда удается удовлетворить ему естественным образом. Следует заметить, что в настоящее время отсутствует общепризнанное формальное определение понятия предметной области. К сожалению, отсутствует и ее содержательное определение. Принято считать, что понятие предметной области не может быть формализовано как первичное понятие. Отсутствие конструктивного определения понятия предметной области существенно сдерживает развитие математической теории информационных систем и информационных технологий. По отношению к информационным системам предметная область – это та часть реального мира, о которой информационная система собирает информацию. Возглавляет предметную область её администратор (директор, начальник, ректор). Предметная область состоит из фрагментов. Каждый фрагмент предметной области характеризуется множеством объектов и процессов, использующих объект, а также множеством пользователей, объединяемые единым взглядом на предметную область. |
8. Онтология. Онтология – система, состоящая из набора понятий, на основе которых можно строить отношения, функции, классы, объекты и теории предметной области. O = <A, B, C> А – конечное множество понятий, терминов (концепций) предметной области, которые представляют данную онтологию. В – конечное множество отношений между концепциями (понятиями) данной предметной области. С – конечное множество функций интерпретации, заданной на A и B. Онтологии – это базы знаний специального типа, которые могут читаться, пониматься, отчуждаться или физически разделяться от разработчиков. Существует отдельная ветвь - онтологический инжиниринг. Онтология – это формальное описание результатов концептуального моделирования предметной области, представленная в форме, воспринимаемой человеком и компьютерной системой. Онтология состоит из примитивов представления знаний предметной области (определений основных понятий, таких как имена индивидуумов, классы, функции и другие сущности), а также различного рода семантических связей, поддерживаемых между ними. Онтологию предметной области можно рассматривать как словарь терминов, специфических для данной предметной области, вместе с совокупностью аксиом, которые обеспечивают интерпретацию и правильное использование этих терминов. Онтологическое представление знаний используется для семантической интеграции информационных ресурсов, адекватной интерпретации содержания текстовых документов и поисковых запросов, представленных на естественном языке. Такие описания на каждом иерархическом уровне поддерживают отношение эквивалентности на множестве классифицируемых сущностей, обеспечивающее его разбиение на попарно непересекающиеся классы. При этом сущности соседних уровней иерархии обычно находятся в отношении «целое-часть» или «род-вид». В более сложном случае онтология задается в виде формального определения на языках представления знаний, допускающих логический вывод. В настоящее время средства формального описания онтологии включают несколько альтернатив:
Дублинское ядро (Dublin Core, DC) – это набор элементов метаданных для представления онтологии предметной области. В терминах значений этих элементов можно описывать содержание различного рода текстовых документов и документов, представленных в иных средах. Привлекательность такого подхода связана с его простотой, что, конечно же, оборачивается ограниченностью его возможностей. Формальное описание онтологии предметной области на языках логики первого порядка допускает возможности логического вывода. Довольно широкое распространение для представления онтологии получил язык указанной категории KIF (Knowledge Interchange Format), разработанный в начале 90-х гг. в Лаборатории систем знаний (KSL) Стэнфордского университета. Первоначально он разрабатывался как формальный язык для обеспечения обмена знаниями между различными системами, основанными на знаниях. На основе расширения языка KJF в той же лаборатории была создана исследовательская система Ontolingua, поддерживающая формирование и представление онтологии в некотором каноническом формате, благодаря чему обеспечивается их совместное использование и/или переносимость в среды различных оперирующих с ними систем. Онтологию, заданную в каноническом формате, можно легко транслировать в разнообразные системы, использующие различный синтаксис для представления знаний и обладающие различными возможностями рассуждений. Стандарт языка описания онтологии для информационных ресурсов Web – OWL (Ontology Web Language)разрабатывается рабочей группой по онтологиям для Web консорциума W3C с 2001г. Язык OWL основан на логиках описаний и предназначен для интеллектуальных систем поиска информационных ресурсов в среде Web второго поколения. Замысел создания Web второго поколения направлен на превращение Web в систему семантического уровня. Поскольку Web первого поколения строился с ориентацией на обработку содержащейся в нем информации человеком, технологии Web нового поколения должны обеспечивать возможности автоматизированной семантической интерпретации и обработки информационных ресурсов. Еще одним способом описания онтологии предметной области, широко используемым в исследовательских и коммерческих системах текстового поиска, является это представление ее в форме тезауруса предметной области.
|
9. Высказывания и формальные теории.
|
|
10.Вопросы и информационные задачи. Основные задачи информационных систем - ИС:
Конкретные задачи, которые должны решаться информационной системой, зависят от той прикладной области, для которой предназначена система. Области применения информационных приложений разнообразны: банковское дело, управление производством, медицина, транспорт, образование и т.д.
|
11. Поведенческие цели и поведенческие задачи.
|
12. Информационно-поисковые задачи. Интеллектуализация информационного поиска. Информационно - поисковые системы (ИПС) Информационно-поисковые системы ориентированны на решение задач поиску информации, документа или факта в множестве источников информации (документов). Содержательная обработка информации в таких системах отсутствующая. Производят ввод, систематизацию, хранение, выдачу информации по запросу пользователя без сложных преобразований данных. Например, информационно-поисковая система в библиотеке билетов. В таких системах хранится информационный массив, из которого по требованиям пользователей выдается нужная информация. Поиск информации по требованию пользователя осуществляется либо автоматически, либо вручную. Поисковый образ документа (ПОД) получается в результате процесса индексирования, который состоит из двух этапов: выявление смысла документа и описание смысла на специальном информационно-поисковом языке (ИПЯ). Запрос к ИПС описывается также на этом языке. Поиск документа состоит в сравнении множества хранящихся в системе ПОД и текущего поискового образа запроса (ПОЗ), в результате чего пользователю выдается требуемый документ или отказ. Информационно-поисковые системы делятся на два типа. Документальные (документографические) Это системы, в которой объектом сохранения и обработки есть собственно документы.. В такой ИПС все хранимые документы индексируются некоторым специальным образом. Каждому документу (статье, отчету, протоколу и т.п.) присваивается индивидуальный код, составляющий поисковый образ документа. Поиск идет не по самим документам, а по их поисковым образам, которые содержат информацию (адрес) о местонахождении документа. Именно так ищут книги по заказам читателя в больших библиотеках (в маленьких библиотеках библиотекарь обычно ищет книги сам). По требованию читателя сначала находят карточку в каталоге, а потом по шифру, указанному на ней, отыскивается и сама книга. Различия документографических ИПС определяются тем, как устроен поисковый образ документа. В простейшем случае это просто его индивидуальное название (например, название, автор, год издания книги). В более сложных случаях нет однозначного соответствия между поисковым образом документа и самим документом. Вполне возможен случай, когда поисковый образ документа соответствует нескольким различным документам и, наоборот, один и тот же документ соответствует не одному, а нескольким поисковым образам. Фактографическая информационная поисковая система – ИПС Это система, где, объектом или сущностью есть то, что представляет для проблемной сферы многосторонний интерес (сотрудник, договор, изделие и т.п.). Ведомости об этих сущностях могут находиться во множестве разных входных и исходных сообщений.. В отличие от документографических ИПС в ИПС такого типа хранятся не документы, а факты, относящиеся к какой-либо предметной области . Хранимые факты могут быть извлечены из различных документов. В базе фактов они связываются между собой системой разнообразных отношений. Такая сеть в ИПС носит название тезауруса предметной области. Запросы, поступающие в фактографические ИПС, используют тезаурус для поиска ответов на запросы. Поиск осуществляется методом поиска по образцу, широко применяющемуся в базах знаний систем искусственного интеллекта. ИПС фактографического типа постепенно приближаются по своей организации и функционированию к развитым базам данных и знаний.
|
|
13. Трудноформализуемые задачи. Задачи, для которых отсутствует четкая постановка.
|
14.Классы задач и хранимые (интерпретируемые) способы их решения – программы.
|
15.Типология хранимых программ и их интерпретаторов.
|
|
16. Модели решения задач при отсутствии хранимых способов их решения.
|
17. Правдоподобные рассуждения. получивший распространение в настоящее время термин для охвата всех рассуждений недедуктивного характера. В правдоподобных рассуждениях истинность посылок не гарантирует истинности заключения (как в дедуктивных рассуждениях), а обеспечивает лишь большую степень его правдоподобия по сравнению с той, какая имеется без учета посылок.
|
18.Машина обработки знаний интеллектуальной системы как многоагентная система. Многоагентная или мультиагентные системы – это направление искусственного интеллекта, которое для решения сложной задачи или проблемы использует системы, состоящие из множества взаимодействующих агентов. |
|
19. Понятие многоагентной системы. Многоагентная или мультиагентные системы – это направление искусственного интеллекта, которое для решения сложной задачи или проблемы использует системы, состоящие из множества взаимодействующих агентов. В теории многоагентных систем (также часто встречается название «мультиагентные системы») за основу берется противоположный принцип. Считается, что один агент владеет всего лишь частичным представлением о глобальной проблеме, а значит, он может решить лишь некоторую часть общей задачи. В связи с этим для решения сложной задачи необходимо создать некоторое множество агентов и организовать между ними эффективное взаимодействие, что позволит построить единую многоагентную систему. В многоагентных системах весь спектр задач по определенным правилам распределяется между всеми агентами, каждый из которых считается членом организации или группы. Распределение заданий означает присвоение каждому агенту некоторой роли, сложность которой определяется исходя из возможностей агента. Многоагентные системы могут быть использованы для решения таких проблем, которые сложно или невозможно решить с помощью одного агента или монолитной системы. Примерами таких задач являются онлайн-торговля, ликвидация чрезвычайных ситуаций, и моделирование социальных структур. В многоагентной системе агенты имеют несколько важных характеристик:
Обычно в многоагентных системах исследуются программные агенты. Тем не менее, составляющими мультиагентной системы могут также быть роботы, люди или команды людей. Также, многоагентные системы могут содержать и смешанные команды. В многоагентных системах может проявляться самоорганизация и сложное поведение даже если стратегия поведения каждого агента достаточно проста. Это лежит в основе так называемого роевого интеллекта. |
20. Пользовательские интерфейсы как интеллектуальные системы Система с интеллектуальным интерфейсом – это интеллектуальная информационная система, предназначенная для поиска неявной информации в базе данных или тексте для произвольных запросов, составленных на ограниченном естественном языке. Существуют следующие виды таких систем: 1) Интеллектуальные базы данных – отличаются от обычных баз данных возможностью выборки по запросу необходимой информации, которая может явно не храниться, а выводиться из имеющейся в базе данных. В них осуществляется поиск по условию, которое должно быть доопределено в ходе решения задачи. Интеллектуальная система без помощи пользователя по структуре базы данных сама строит путь доступа к файлам данных. Формулирование запроса осуществляется в диалоге с пользователем, последовательность шагов которого выполняется в максимально удобной для пользователя форме. 2) Естественно-языковой интерфейс применяется для доступа к интеллектуальным базам данных, контекстного поиска, голосового ввода команд в системах управления, машинного перевода с иностранных языков. Он предполагает трансляцию естественно-языковых конструкций на внутримашинный уровень представления знаний. Для реализации естественно-языкового интерфейса необходимо решить адачи морфологического, синтаксического и семантическогоанализа и синтеза высказываний на естественном языке. Морфологический анализпредполагает распознавание и проверку правильности написания слов по словарям. Синтаксический контроль – разложение входных сообщений на отдельные компоненты (определение структуры) с проверкой соответствия грамматическим правилам внутреннего представления знаний и выявления недостающих частей. Семантический анализ – установление смысловой правильности синтаксических конструкций. Синтез высказываний заключается в преобразовании цифрового представления информации в представление на естественном языке. 3) Гипертекстовые системы предназначены для поиска по ключевым словам в базах текстовой информации. Интеллектуальные гипертекстовые системы отличаются от обычных более сложной семантической организацией ключевых слов, которая отражает различные смысловые отношения терминов. Механизм поиска работает сначала с базой знаний ключевых слов, а уже затем – с текстом. Аналогично может проводиться поиск мультимедийной информации, включающей кроме текстовой и цифровой информации графические, аудио- и видеообразы. 4) Системы контекстной помощи относятся к классу систем распространения знаний. В отличие от обычных систем помощи, навязывающих пользователю схему поиска требуемой информации, в интеллектуальных системах контекстной помощи пользователь описывает проблему (ситуацию), а система с помощью дополнительного диалога ее конкретизирует и сама выполняет поиск относящихся к ситуации рекомендаций. Такие системы используются как приложения к системам документации (например, технической документации по эксплуатации товаров). 5) Системы когнитивной графики (когнитивный – способствующий пониманию) ориентированы на общение ИИС с пользователем посредством графических образов, которые генерируются в соответствии с происходящими событиями. Когнитивная графика позволяет в наглядном виде представить множество параметров изучаемого явления, освобождает пользователя от анализа стандартных ситуаций, способствует быстрому освоению программных средств.
По типу пользовательского интерфейса различают текстовые (линейные), графические и речевые операционные системы.Пользовательским интерфейсом называется набор приемов взаимодействия пользователя с приложением. Пользовательский интерфейс включает общение пользователя с приложением и язык общения. Текстовые ОС Линейные операционные системы реализуют интерфейс командной строки. Основным устройством управления в них является клавиатура. Команда набирается на клавиатуре и отображается на экране дисплея. Окончанием ввода команды служит нажатие клавиши Enter. Для работы с операционными системами, имеющими текстовый интерфейс, необходимо овладеть командным языком данной среды, т.е. совокупностью команд, структура которых определяется синтаксисом этого языка. Первые настоящие операционные системы имели текстовый интерфейс. В настоящее время он также используется на серверах и компьютерах пользователей. Графические ОС Такие операционные системы реализуют интерфейс, основанный на взаимодействии активных и пассивных графических экранных элементов управления. Устройствами управления в данном случае являются клавиатура и мышь. Активным элементом управления является указатель мыши — графический объект, перемещение которого на экране синхронизировано с перемещением мыши. Пассивные элементы управления — это графические элементы управления приложений (экранные кнопки, значки, переключатели, флажки, раскрывающиеся списки, строки меню и т.д.). Примером исключительно графических ОС являются операционные системы семейства Windows. Стартовый экран подобных ОС представляет собой системный объект, называемый рабочим столом. Рабочий стол — это графическая среда, на которой отображаются объекты (файлы и каталоги) и элементы управления. В графических операционных системах большинство операций можно выполнять многими различными способами, например через строку меню, через панель инструментов, через систему окон и др. Поскольку операции выполняются над объектом, предварительно он должен быть выбран (выделен). Основу графического интерфейса пользователя составляет организованная система окон и других графических объектов, при создании которой разработчики стремятся к максимальной стандартизации всех элементов и приемов работы. Окно — это обрамленная прямоугольная область на экране монитора, в которой отображаются приложения, документ, сообщение. Окно является активным, если с ним в данный момент работает пользователь. Все операции, выполняемые в графических ОС, происходят либо на Рабочем столе, либо в каком-либо окне. Речевые ОС В случае SILK-интерфейса (от англ. speech – речь, image – образ, language – язык, knowledge – знание) – на экране по речевой команде происходит перемещение от одних поисковых образов к другим. Предполагается, что при использовании общественного интерфейса не нужно будет разбираться в меню. Экранные образы однозначно укажут дальнейший путь перемещения от одних поисковых образов к другим по смысловым семантическим связям. |
21.Внешние языки общения с пользователями: универсальные и специализированные. Универсальные языки используются для решения разных задач. Специализированные языки предназначены для решения задач одного, максимум нескольких, видов задач.(например, работы с базами данных, web-программирования или написание скриптов для администрирования операционных систем). Виды специализированных языков: 1.Языки для работы с базами данных: а)Языки, входящие в состав промышленных клиент-серверных систем управления базами данных.(СУБД) (PL-SQL в СУБД Oracle, Transact-SQL в Microsoft SQL Server) б)Языки являющиеся частью других видов СУБД (Visual FoxPro, Microsoft Access, Paradox и т.п.) 2. Языки предназначенные для web-программирования. а) Языки, исполняющиеся на сервере, поддерживающего Web-сайт.(РНР, Perl, VBScript) б) Языки, исполняющиеся на браузере (программе просмотра) клиента JavaScript, JScript, VBScript 3.Языки для математических расчетов 4.Языки для автоматизации работы определенных программных продуктов. (VBA в Microsoft Office) 6.Специализированные языки других видов. К универсальным языкам можно отнести языки Visual C++, Visual C++.Net, Visual C#.Net, Visual J#.Net, Java, Delphi, Borland C#, Borland C++ Builder. Хотя чаще всего специализированные языки происходят от универсальных языков например PHP, Perl и JаvаScript произошли от языка С++, VBScript и VBA произошли от языка Visual Bаsic'а, отличия между специализированными и универсальными языками очень значительны. Специализированные языки, чаще всего используются для написания не очень больших программ, поэтому они оптимизированы на быстрое написание программ и уменьшение размера исходного кода, и в меньшей степени на уменьшение ошибок, использование объектно-ориентированное программирования и разделения кода на модули. А универсальные языки, как правило, используются для создания больших и очень больших проектов, поэтому в них все сделано, чтобы уменьшить количество ошибок и облегчить проектирования программ, облегчение разработки крупных программ. Основное отличие специальных языков от универсальных: 1) В них меньше объектно-ориентированных средств и средств доступа технологий COM+, DCOM, CORBA, к функциям API операционных систем; 2)Меньше средств многопоточного программирования и распределенного программирования; 3)Используются только динамические типы (т.е. тип переменной определяется в зависимости от её значения, а не при объявление переменной), а не статические. Единственное исключение: в версии 9 языка Visual FoxPro можно использовать и статические типы переменных. |
|
22. Редакторы внешних информационных конструкций.
|
23. Синтаксический анализ вводимой информации. Синтаксический анализ — процесс сопоставления линейной последовательности лексем (слов, токенов) естественного или формального языка с его формальной грамматикой. Результатом обычно является дерево разбора (синтаксическое дерево). Обычно применяется совместно с лексическим анализом. Синтаксический анализатор — это программа или часть программы, выполняющая синтаксический анализ. В ходе синтаксического анализа исходный текст преобразуется в структуру данных, обычно — в дерево, которое отражает синтаксическую структуру входной последовательности и хорошо подходит для дальнейшей обработки. Как правило, результатом синтаксического анализа является синтаксическое строение предложения, представленное либо в виде дерева зависимостей, либо в виде дерева составляющих, либо в виде некоторого сочетания первого и второго способов представления.
|
24. Семантический анализ вводимой информации. Семантический анализ предполагает установление смысловой правильности синтаксических конструкций. Семантический анализ текста – это компонентная оценка количества слов или фраз, определяющих основной смысл текста (семантическое ядро) и статистических показателей. Крепкое и грамотно сформированное семантическое ядро обеспечивает успех статье и публикующему её ресурсу. Статистика текста подразумевает подсчёт количества:
Количество символов – общая численность с учётом знаков препинания и пробелов. Количество символов без пробелов – то же самое, исключая пробелы. Численность уникальных слов – количество слов в тексте без учёта повторов. Численность значимых слов – так как существительные в большей степени определяют смысл текста, они и являются значимыми. Стоп-слова – частицы, предлоги междометия и иные связующие, не имеющие собственного смысла. К этой же категории относят и широко применяемые в интернете слова. Здесь уместно упоминание ещё о двух терминах: значимые и незначимые слова. К первым относятся слова, относительно редко употребляемые на просторах Всемирной паутины. А вторые составляют основу лексикона большинства пользователей. Вода – выражается в процентах. Вычисляется методом деления количества значимых слов на общее число слов в документе. Хотя прямая параллель между объёмом воды и качеством текста неуместна, не рекомендуется доводить водность до 65 процентов или выше. Текст, содержащий больше 75 процентов воды, нужно подкорректировать. Хотя абсолютно без воды работать не получится. Поэтому, если показатель не превышает 60 процентов, а материал легко воспринимается, оставляем его в покое. Классическая тошнота – это специфический термин, используемый только для семантического анализа текстов. Параметр указывает на количество повторений одного и того же слова в тексте. Чтобы его подсчитать, из количества повторов вычисляют квадратный корень. Наилучший показатель классической тошноты – 7. Повышение коэффициента тормозит продвижение ресурса в сети. Академическая тошнота – показатель тем выше, чем больше слов в тексте повторяются. Искусственно повышают его за счёт плотного ввода ключей. Семантика помогает пользователю понять суть текста. Особые комбинации слов формируют нить повествования. Грамотно сочетая слова и фразы, копирайтер создаёт статьи, направляющие читателя, привлекающие или побуждающие. |
|
25. Естественно-языковой интерфейс. Этот интерфейс предполагает трансляцию естественно-языковых конструкций на внутримашинный язык представления знаний. Для этого необходимо решать задачи морфологического, синтаксического и семантического анализа и синтеза высказываний на естественном языке. Морфологический анализ предполагает распознавание и проверку правильности написания слов по словарям. Синтаксический анализ предполагает разложение входных сообщений на отдельные компоненты с проверкой соответствия грамматическим правилам внутреннего представления знаний и выявления недостающих частей. Семантический анализ предполагает установление смысловой правильности синтаксических конструкций. Синтез высказываний решает обратную задачу преобразования внутреннего представления информации в естественно-языковое представление. ЕЯ интерфейс используется для следующих целей: 1) для доступа к интеллектуальным БД; 2) для контекстного поиска документальной текстовой информации; 3) для голосового ввода команд в системах управления; 4) для машинного перевода с иностранных языков.
|
26. Интеграция знаний |
27. Модель понимания.
|
|
28. Понятие многократно используемого компонента интеллектуальной системы.
|
29. Технология проектирования компьютерных систем. К основным требованиям, предъявляемым к выбираемой технологии проектирования, относятся следующие: • созданный с помощью этой технологии проект должен отвечать требованиям заказчика; • выбранная технология должна максимально отражать все этапы цикла жизни проекта; • выбираемая технология должна обеспечивать минимальные трудовые и стоимостные затраты на проектирование и сопровождение проекта; • технология должна быть основой связи между проектированием и сопровождением проекта; • технология должна способствовать росту производительности труда проектировщика; • технология должна обеспечивать надежность процесса проектирования и эксплуатации проекта; • технология должна способствовать простому ведению проектной документации. Технология проектирования должна обеспечивать выполнение требований заказчика к информационной системе в части функциональной полноты, достоверности и оперативности при минимизации стоимостных затрат на создание и эксплуатацию системы. Эти требования отражены в концептуальной модели проектировании информационной системы. Выбираемая технология проектирования должна позволить проектировщикам разработать проект в установленные сроки. Технология проектирования должна отвечать требованиям надежности функционирования информационной системы. Важным требованием к технологии проектирования является требование адаптивности проектных решений в процессе эксплуатации информационной системы. Наконец, должна быть обеспечена экономическая эффективность проектной деятельности, т.е. затраты на разработку проекта должны окупаться за счет доходов от его реализации. Основными ограничениями при выборе технологии могут служить: · наличие денежных средств на приобретение и поддержку выбранной технологии; · ограничение во времени проектирования; · наличие специалистов соответствующей квалификации.
|
30.Требования, предъявляемые к технологии проектирования интеллектуальных систем. К основным требованиям, предъявляемым к выбираемой технологии проектирования, относятся следующие: • созданный с помощью этой технологии проект должен отвечать требованиям заказчика; • выбранная технология должна максимально отражать все этапы цикла жизни проекта; • выбираемая технология должна обеспечивать минимальные трудовые и стоимостные затраты на проектирование и сопровождение проекта; • технология должна быть основой связи между проектированием и сопровождением проекта; • технология должна способствовать росту производительности труда проектировщика; • технология должна обеспечивать надежность процесса проектирования и эксплуатации проекта; • технология должна способствовать простому ведению проектной документации. Технология проектирования должна обеспечивать выполнение требований заказчика к информационной системе в части функциональной полноты, достоверности и оперативности при минимизации стоимостных затрат на создание и эксплуатацию системы. Эти требования отражены в концептуальной модели проектировании информационной системы. Выбираемая технология проектирования должна позволить проектировщикам разработать проект в установленные сроки. Технология проектирования должна отвечать требованиям надежности функционирования информационной системы. Важным требованием к технологии проектирования является требование адаптивности проектных решений в процессе эксплуатации информационной системы. Наконец, должна быть обеспечена экономическая эффективность проектной деятельности, т.е. затраты на разработку проекта должны окупаться за счет доходов от его реализации. Основными ограничениями при выборе технологии могут служить: · наличие денежных средств на приобретение и поддержку выбранной технологии; · ограничение во времени проектирования; · наличие специалистов соответствующей квалификации.
|


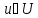 можно
четко определить, принадлежит он
данному мн-ву или нет.
можно
четко определить, принадлежит он
данному мн-ву или нет.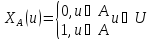
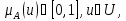 при этом
при этом указывает на степень принадлежности
элемента
указывает на степень принадлежности
элемента
 нечеткому мн-ву.
нечеткому мн-ву.