

Cidr– бесклассовая междоменная маршрутизация
В течение многих лет IPоставался чрезвычайно популярным протоколом. Он работал просто прекрасно, и основное подтверждение тому - экспоненциальный рост сети Интернет. К сожалению, протоколIPскоро стал жертвой собственной популярности: стало подходить к концу адресное пространство. Эта угроза вызвала бурю дискуссий и обсуждений в Интернет-сообществе. В этом разделе мы опишем как саму проблему, так и некоторые предложенные способы ее решения.
В теперь уже далеком 1987 году некоторые дальновидные люди предсказывали, что настанет день, когда в Интернете будет 100 000 сетей. Большинство экспертов посмеивались над этим и говорили, что если такое когда-нибудь и произойдет, то не раньше, чем через много десятков лет. Стотысячная сеть была подключена к Интернету в 1996 году. И, как уже было сказано, нависла угроза выхода за пределы пространства IP-адресов. В принципе, существует 2 миллиарда адресов, но на практике благодаря иерархической организации адресного пространства (см. рис. 5.48) это число сократилось на миллионы. В частности, одним из виновников этого является класс сетей В. Для большинства организаций класс А с 16 миллионами адресов – это слишком много, а класс С с 256 адресами – слишком мало. Класс В с 65 536 адресами – это то, что нужно. В интернет- фольклоре такая дилемма известна под названием проблемы трех медведей (вспомнимМашу и трех медведей).
На самом деле и класс В слишком велик для большинства контор, которые устанавливают у себя сети. Исследования показали, что более чем в половине случаев сети класса В включают в себя менее 50 хостов. Безо всяких сомнений, всем этим организациям хватило бы и сетей класса С, однако почему-то все уверены, что в один прекрасный день маленькое предприятие вдруг разрастется настолько, что сеть выйдет за пределы 8-битного адресного пространства хостов. Сейчас, оглядываясь назад, кажется, что лучше было бы использовать в классе С 10-битную адресацию (до 1022 хостов в сети). Если бы это было так, то, возможно, большинство организаций приняло бы разумное решение устанавливать у себя сети класса С, а не В. Таких сетей могло бы быть полмиллиона, а не 16 384, как в случае сетей класса В.
Нельзя обвинять в создавшейся ситуации проектировщиков Интернета за то, что они не увеличили (или не уменьшили) адресное пространство сетей класса В. В то время, когда принималось решение о создании трех классов сетей, Интернет был инструментом научно-исследовательских организаций США (плюс несколько компаний и военных организаций, занимавшихся исследованиями с помощью сети). Никто тогда не предполагал, что Интернет станет коммерческой системой коммуникации общего пользования, соперничающей с телефонной сетью. Тогда кое-кто сказал, ничуть не сомневаясь в своей правоте: «В США около 2000 колледжей и университетов. Даже если все они подключатся к Интернету и к ним присоединятся университеты из других стран, мы никогда не превысим число 16 000, потому что высших учебных заведений по всему миру не так уж много. Зато мы будем кодировать номер хоста целым числом байт, что ускорит процесс обработки пакетов».
Даже если выделить 20 бит под адрес сети класса В, возникнет другая проблема: разрастание таблиц маршрутизации. С точки зрения маршрутизаторов, адресное пространство IPпредставляет собой двухуровневую иерархию, состоящую из номеров сетей и номеров хостов. Маршрутизаторы не обязаны знать номера вообще всех хостов, но им необходимо знать номера всех сетей. Если бы использовалось полмиллиона сетей класса С, каждому маршрутизатору пришлось бы хранить в таблице полмиллиона записей, по одной для каждой сети, в которых сообщалось бы о том, какую выходную линию использовать, чтобы добраться до той или иной сети, а также о чем-нибудь еще.
Физическое хранение полумиллиона строк таблицы, вероятно, выполнимо, хотя и дорого для маршрутизаторов, хранящих таблицы в статической памяти плат ввода-вывода. Более серьезная проблема состоит в том, что сложность обработки этих таблиц растет быстрее, чем сами таблицы, то есть зависимость между ними не линейная. Кроме того, большая часть имеющихся программных и программно-аппаратных средств маршрутизаторов разрабатывалась в те времена, когда Интернет объединял 1000 сетей, а 10 000 сетей казались отдаленным будущим. Методы реализации тех лет в настоящее время далеки от оптимальных.
Различные алгоритмы маршрутизации требуют от каждого маршрутизатора периодической рассылки своих таблиц (например, протоколов векторов расстояний). Чем больше будет размер этих таблиц, тем выше вероятность потери части информации по дороге, что будет приводить к неполноте данных и возможной нестабильности работы алгоритмов выбора маршрутов.
Проблема таблиц маршрутизаторов может быть решена при помощи увеличения числа уровней иерархии. Например, если бы каждый IP-адрес содержал поля страны, штата, города, сети и номера хоста. В таком случае каждому маршрутизатору нужно будет знать, как добраться до каждой страны, до каждого штата или провинции своей страны, каждого города своей провинции или штата и до каждой сети своего города. К сожалению, такой подход потребует существенно более 32 бит для адреса, а адресное поле будет использоваться неэффективно (для княжества Лихтенштейн будет выделено столько же разрядов, сколько для Соединенных Штатов).
Таким образом, большая часть решений разрешает одну проблему, но взамен создает новую. Одним из решений, реализуемым в настоящий момент, является алгоритм маршрутизации CIDR (ClasslessInterDomainRouting– бесклассовая меж- доменная маршрутизация). Идея маршрутизацииCIDR, описанной вRFC1519, состоит в объединении оставшихся адресов в блоки переменного размера, независимо от класса. Если кому-нибудь требуется, скажем, 2000 адресов, ему выделяется блок из 2048 адресов на границе, кратной 2048 байтам.
Отказ от классов усложнил процесс маршрутизации. В старой системе, построенной на классах, маршрутизация происходила следующим образом. По прибытии пакета на маршрутизатор копия IP-адреса, извлеченного из пакета и сдвинутого вправо на 28 бит, давала 4-битный номер класса. С помощью 16-альтернативного ветвления пакеты рассортировывались на А, В, С иD(если этот класс поддерживался): восемь случаев было зарезервировано для А, четыре для В, два для С и по одному дляDи Е. Затем при помощи маскировки по коду каждого класса определялся 8-, 16- или 32-битный сетевой номер, который и записывался с выравниванием по правым разрядам в 32-битное слово. Сетевой номер отыскивался в таблице А, В или С, причем для А и В применялась индексация, а для С – хэш-функция. По найденной записи определялась выходная линия, по которой пакет и отправлялся в дальнейшее путешествие.
В CIDRэтот простой алгоритм применить не удается. Вместо этого применяется расширение всех записей таблицы маршрутизации за счет добавления 32-битной маски. Таким образом, образуется единая таблица для всех сетей, состоящая из набора троек (IP-адрес, маска подсети, исходящая линия). Что происходит с приходящим пакетом при применении методаCIDR? Во-первых, извлекаетсяIP-адрес назначения. Затем (концептуально) таблица маршрутизации сканируется запись за записью, адрес назначения маскируется и сравнивается со значениями записей. Может оказаться, что по значению подойдет несколько записей (с разными длинами масок подсети). В этом случае используется самая длинная маска. То есть если найдено совпадение для маски /20 и /24, то будет выбрана запись, соответствующая /24.
Был разработан сложный алгоритм для ускорения процесса поиска адреса в таблице (Ruiz-Sanchezи др., 2001). В маршрутизаторах, предполагающих коммерческое использование, применяются специальные чипыVLSI, в которые данные алгоритмы встроены аппаратно.
Чтобы лучше понять алгоритм маршрутизации, рассмотрим пример. Допустим, имеется набор из миллионов адресов, начиная с 194.24.0.0. Допустим также, что Кембриджскому университету требуется 2048 адресов, и ему выделяются адреса от 194.24.0.0 до 194.24.7.255, а также маска 255.255.248.0. Затем Оксфордский университет запрашивает 4096 адресов. Так как блок из 4096 адресов должен располагаться на границе, кратной 4096, то ему не могут быть выделены адреса начиная с 194.24.8.0. Вместо этого он получает адреса от 194.24.16.0 до 194.24.31.255 вместе с маской 255.255.240.0. Затем Эдинбургский университет просит выделить ему 1024 адреса и получает адреса от 194.24.8.0 до 194.24.11.255 и маску 255.255.252.0. Все эти присвоенные адреса и маски сведены в табл. 5.7.
Таблица 5.7. Набор присвоенныхIP-адресов
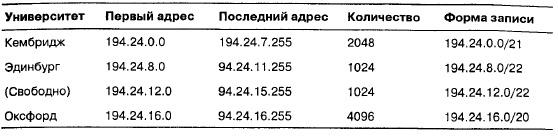
После этого таблицы маршрутизаторов по всему миру получают три новые строки, содержащие базовый адрес и маску. В двоичном виде эти записи выглядят так: Адрес Маска
К: 11000010 00011000 00000000 00000000 11111111 11111111 11111000 00000000
Э: 11000010 00011000 00001000 00000000 11111111 11111111 11111100 00000000
0:11000010 00011000 00010000 00000000 11111111 11111111 11110000 00000000
Теперь посмотрим, что произойдет, когда пакет придет по адресу 194.24.17.4.
В двоичном виде этот адрес представляет собой следующую 32-битную строку:
11000010 00011000 00010001 00000100
Сначала на него накладывается (выполняется логическое И) маска Кембриджа, в результате чего получается
11000010 00011000 00010000 00000000
Это значение не совпадает с базовым адресом Кембриджа, поэтому на оригинальный адрес накладывается маска Оксфорда, что дает в результате;
11000010 00011000 00010000 00000000
Это значение совпадает с базовым адресом Оксфорда. Если далее по таблице совпадений нет, то пакет пересылается Оксфордскому маршрутизатору. Теперь посмотрим на эту троицу университетов с точки зрения маршрутизатора в Омахе, штат Небраска, у которого есть всего четыре выходных линии: на Миннеаполис, Нью-Йорк, Даллас и Денвер. Получив три новых записи, маршрутизатор понимает, что он может скомпоновать их вместе и получить одну агрегированную запись, состоящую из адреса 194.24.0.0/19 и подмаски:
11000010 00000000 00000000 00000000 11111111 11111111 11100000 00000000
В соответствии с этой записью пакеты, предназначенные для любого из трех университетов, отправляются в Нью-Йорк. Объединив три записи, маршрутизатор в Омахе уменьшил размер своей таблицы на две строки.
В Нью-Йорке весь трафик Великобритании направляется по лондонской линии, поэтому там также используется агрегированная запись. Однако если имеются отдельные линии в Лондон и Эдинбург, тогда необходимы три отдельные записи. Агрегация часто используется в Интернете для уменьшения размеров таблиц маршрутизации.
И последнее замечание по данному примеру. Та же самая агрегированная запись маршрутизатора в Омахе используется для отправки пакетов по не присвоенным адресам в Нью-Йорк. До тех пор, пока адреса остаются не присвоенными, это не имеет значения, поскольку предполагается, что они вообще не встретятся. Однако если в какой-то момент этот диапазон адресов будет присвоен какой-нибудь калифорнийской компании, для его обработки понадобится новая запись: 194.24.12.0/22.