26. Понятие архивации. Методы и форматы сжатия информации. Основные идеи алгоритмов rle, Лемпеля-Зива, Хаффмана.
Электронное архивирование— хранение электронной информации в неизменном виде.
Сжа́тие да́нных — алгоритмическое преобразование данных, производимое с целью уменьшения занимаемого ими объёма. Применяется для более рационального использования устройств хранения и передачи данных.
Все методы сжатия данных делятся на два основных класса:
Сжатие без потерь - метод сжатия данных (видео, аудио, графики, документов, представленных в цифровом виде), при использовании которого закодированные данные однозначно могут быть восстановлены с точностью до бита. При этом оригинальные данные полностью восстанавливаются из сжатого состояния. Этот тип сжатия принципиально отличается от сжатия данных с потерями. Для каждого из типов цифровой информации, как правило, существуют свои оптимальные алгоритмы сжатия без потерь.
Сжатие с потерями - метод сжатия (компрессии) данных, при использовании которого распакованные данные отличаются от исходных, но степень отличия не существенна с точки зрения их дальнейшего использования. Этот тип компрессии часто применяется для сжатия аудио- и видеоданных, статических изображений, в Интернете (особенно в потоковой передаче данных) и цифровой телефонии.
Кодирование длин серий (англ. run-length encoding, RLE) или кодирование повторов — алгоритм сжатия данных, заменяющий повторяющиеся символы (серии) на один символ и число его повторов. Серией называется последовательность, состоящая из нескольких одинаковых символов.
Алгори́тм Ле́мпеля — Зи́ва — это универсальный алгоритм сжатия данных без потерь, созданный Авраамом Лемпелем , Яаковом Зивом и Терри Велчем. Алгоритм разработан так, чтобы его можно было быстро реализовать, но он не обязательно оптимален, поскольку он не проводит никакого анализа входных данных.
Алгоритм Хаффмана — жадный алгоритм оптимального префиксного кодирования алфавита с минимальной избыточностью. Был разработан в 1952 году аспирантом Массачусетского технологического института Дэвидом Хаффманом при написании им курсовой работы.
27. База данных. Классификация. Модели баз данных. Достоинства и недостатки.
Ба́за да́нных — представленная в объективной форме совокупность самостоятельных материалов, систематизированных таким образом, чтобы эти материалы могли быть найдены и обработаны с помощью электронной вычислительной машины.
Классификация:
1. По модели данных:
Иерархическая
Сетевая
Реляционная
Объектная и объектно-ориентированная
Объектно-реляционная
Функциональная
2. По среде постоянного хранения:
Во вторичной памяти (традиционная)
В оперативной памяти
В третичной памяти
3. По содержимому:
Географическая
Историческая
Научная
Мультимедийная
4. По степени распределённости:
Централизованная
Распределённая
Неоднородная
Однородная
Фрагментированная
Тиражированная
5. Другие виды БД:
Пространственная
Временная
Пространственно-временная
Циклическая
Модель данных – это совокупность структур данных и операций их обработки. С помощью модели данных могут быть представлены информационные объекты и взаимосвязи между ними. Рассмотрим три основных типа моделей данных: иерархическую, сетевую и реляционную.
Иерархическая модель данных представляет собой совокупность элементов данных, расположенных в порядке их подчинения и образующих по структуре перевернутое дерево (рис. 1). К основным понятиям иерархической модели данных относятся: уровень, узел и связь. Узел – это совокупность атрибутов данных, описывающих информационный объект.
Иерархическая структура должна удовлетворять следующим требованиям:
каждый узел на более низком уровне связан только с одним узлом, находящимся на более высоком уровне;
существует только один корневой узел на самом верхнем уровне, не подчиненный никакому другому узлу;
к каждому узлу существует ровно один путь от корневого узла.

Сетевая модель данных основана на тех же основных понятиях (уровень, узел, связь), что и иерархическая модель, но в сетевой модели каждый узел может быть связан с любым другим узлом. На рис. 3 схематически изображена сетевая структура организации данных.
Примером сетевой структуры может служить структура базы данных, содержащей сведения о студентах, занимающихся в спортивных секциях. Возможно участие одного студента в нескольких секциях, возможно также участие нескольких студентов в одной секции.

Реляционная модель данных использует организацию данных в виде двумерных таблиц. Каждая такая таблица, называемая реляционной таблицей или отношением, представляет собой двумерный массив и обладает следующими свойствами:
все столбцы в таблице однородные, т.е. все элементы в одном столбце имеют одинаковый тип и максимально допустимый размер;
каждый столбец имеет уникальное имя;
одинаковые строки в таблице отсутствуют;
порядок следования строк и столбцов в таблице не имеет значения
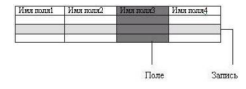
Основными структурными элементами реляционной таблицы являются поле и запись (рис. 5). Поле (столбец реляционной таблицы) – элементарная единица логической организации данных, которая соответствует конкретному атрибуту информационного объекта. Запись (строка реляционной таблицы) – совокупность логически связанных полей, соответствующая конкретному экземпляру информационного объекта.