

-
Кодирование информации, представление информации в компьютере
Информация редко используется только в момент возникновения и только в том месте, где она возникает. Поэтому она передается и хранится в виде сообщений с использованием естественных или искусственных каналов и средств связи.
Информация передается посредством сообщения (в форме представления, удобной для передачи, хранения), данных (в форме представления, удобной для переработки в вычислительных системах) на каком-либо языке.
Для удобства использования информации обычно пользуются кодированием, т.е. представлением символов одного алфавита символами другого. Например, азбука Морзе:
«а» – .— «1» – .— — — —
«б» – —... «2» – .. — — —
«в» – .— — «3» – ...— —
Естественные человеческие языки – системы кодирования понятий для выражения мыслей посредством речи. К языкам близко примыкают азбуки – системы кодирования компонентов языка с помощью графических символов.
Своя система существует и в вычислительной технике – она называется двоичным кодированием и основана на представлении данных последовательностью всего двух знаков: 0 и 1.
В основе работы такой системы представления информации лежит двоичная система счисления, которую мы рассмотрим подробней1.
Система счисления – это способ наименования и изображения чисел с помощью символов, имеющих определенные количественные значения.
В зависимости от способа изображения чисел системы делятся на позиционные и непозиционные.
В позиционной системе счисления количественное значение каждой цифры зависит от ее место положения (позиции) в числе. В непозиционной системе счисления цифры не меняют своего количественного значения при изменении их положения в числе.
Количество цифр, используемых для изображения числа в позиционной системе счисления, называется основанием системы.
В хорошо нам известной с детства десятичной позиционной системе счисления для записи любого числа используются десять цифр (основание системы 10) причем каждая цифра в числе несет двойную информацию: во-первых, свое собственное значение – 1; 2; 3; 4…., а во-вторых, место которое она занимает в записи числа1.
Рассмотрим пример числа: 555.
Занумеруем все разряды справа на лево, причем привычный нам разряд единиц будем считать нулевым; тогда разряд десятков будет первым, сотен вторым и так далее. Такая нумерация весьма естественна, поскольку единицы – это 10 в нулевой степени, десятки – 10 в первой, сотни – 10 во второй и т.д., то есть расположение той или иной цифры в записи числа есть не что иное, как прямое указание, какой степенью 10 его можно заменить. А само значение цифры показывает, сколько раз надо взять 10 в заданной степени. Таким образом, окончательно наше число запишется в следующем виде:
5102+5103+5100.
Теперь давайте выберем наименьшее из возможных оснований позиционной системы счисления 2 и посмотрим, как записать произвольное натуральное число при помощи суммы степеней двойки. Для записи двоичного числа используются только две цифры 0 и 1.
Пример перевода чисел от 0 до 10 запишем в виде таблицы:
|
Десятичные |
Двоичные |
|
0=020 |
0 |
|
1=120 |
1 |
|
2=121+020 |
10 |
|
3=121+120 |
11 |
|
4=122+021+020 |
100 |
|
5=122+021+120 |
101 |
|
6=122+121+020 |
110 |
|
7=122+121+120 |
111 |
|
8=123+022+021+020 |
1000 |
|
9=123+022+021+120 |
1001 |
|
10=123+022+121+020 |
1010 |
Для перевода десятичных чисел в двоичные числа можно использовать несложный алгоритм:
1. Разделить число на 2. Зафиксировать остаток (0 или 1) и частное.
2. Если частное не равно 0, то разделить его на 2, и так далее пока частное не станет равно 0. Если частное 0, то записать все полученные остатки, начиная с первого, справа налево.
Например, представим 23 в двоичной форме.
Получим: 10111.
Ч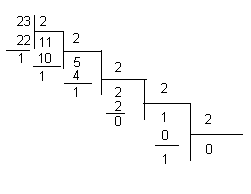 тобы
получить обратную операцию, необходимо
просуммировать степени двойки,
соответствующие ненулевым разрядам в
записи числа.
тобы
получить обратную операцию, необходимо
просуммировать степени двойки,
соответствующие ненулевым разрядам в
записи числа.
В общем случае запись любого смешанного числа в системе счисления с основанием Р будет представлять собой ряд вида:
![]() ,
,
где нижние индексы определяют местоположение цифры в числе (разряд); положительные значения индексов – для целой части числа (m разрядов); отрицательные значения – для дробной (s разрядов).
В вычислительных машинах применяют две формы представления двоичных чисел:
– естественная форма или форма с фиксированной запятой (точкой);
– нормальная форма или форма с плавающей запятой (точкой).
С фиксированной точкой все числа изображаются в виде последовательности цифр с постоянным для всех чисел положением запятой, отделяющей целую часть от дробной.
С плавающей запятой каждое число изображается в виде двух групп цифр. Первая группа называется мантиссой, вторая порядком, причем абсолютная величина мантиссы должна быть меньше 1, а порядок – целым числом. В общем виде это будет выглядеть так:
![]() ,
,
где М – мантисса числа (|M|<1); r – порядок числа (r – целое число); Р – основание системы счисления.
Нормальная форма представления имеет огромный диапазон значений отображения чисел и является основной в современных ЭВМ.
При программировании иногда используется шестнадцатеричная система счисления. Перевод десятичных чисел в шестнадцатеричные осуществляется по тому же алгоритму, что и в двоичные, только основание деления берется 16. Для представления используются 16 символов: 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, A(10), B(11), C(12), D(13), E(14), F(15).
Вся информация в ПК представлена в виде двоичных кодов. Быстрый и точный доступ к обрабатываемой информации и программам, управляющим работой вычислительных машин возможен благодаря тому, что программы и данные кодируются в виде последовательностей электронных импульсов, каждый из которых соответствует одной двоичной цифре: 1 либо 0. Импульсы записываются в специальных микроэлектронных элементах, из которых строится оперативная память (ОЗУ – оперативное запоминающее устройство) вычислительного устройства. Каждый элемент хранит одну двоичную цифру (бит информации). Эти элементы группируются друг с другом, формируя более крупные единицы информации – байт и машинное слово.
Физически это выглядит следующим образом. Память компьютера состоит из тысяч электронных переключателей, и каждый из них может находиться в одном из двух состояний: «включено» или «выключено». Это и соответствует одному биту информации (1 или 0).
Бит слишком маленькая единица информации и если работать с каждым битом информации отдельно, то такая работа будет малопризводительной. Обработкой информации в компьютере занимается специальная микросхема, которая называется процессор. Один из первых персональных компьютеров имел микропроцессор, который мог параллельно обрабатывать 8 бит (такой микропроцессор назвали восьмиразрядным.). Поэтому с тех пор появилась новая единица измерения информации – байт. Байт это группа из восьми бит. Мы знаем, что один бит может хранить в себе один двоичный знак 0 или 1. Если учесть, что байты различаются не только количеством нулей и единиц, но и порядком их расположения, то можно сказать, что с помощью 1 байта можно выразить 256 различных единиц информации.
Кодирование текстовых данных. Если каждому символу алфавита сопоставить определенное целое число, то с помощью двоичного кода можно кодировать текстовую информацию. Восьми двоичных разрядов достаточно для кодирования 256 различных символов.
Этого хватит, чтобы выразить различными комбинациями восьми битов все символы английского и русского языков, как строчные, так и прописные, а также знаки препинания, символы основных арифметических действий и некоторые общепринятые специальные символы. В русском языке 33 буквы – для их кодирования достаточно 33 различных байта. Если учитывать разницу между прописными и строчными буквами, то потребуется 66 байт. Для строчных и прописных букв английского языка хватит 52 байт. Итого вместе 118. Добавим цифры от 0 до 9, всевозможные знаки препинания, скобки, математические операции, специальные символы. В итоге нам потребуется 152 байта. Теперь осталось разобраться, как собственно кодируются символы. Существует всеобщая договорённость – стандарт. Стандарт устанавливает таблицу, в которой записано, каким кодом должен кодироваться каждый символ. Такая таблица называется таблицей кодов или кодовой таблицей. В этой таблице должно быть 256 строк, в которых записывается, какой байт какому символу соответствует. Но в различных странах существуют различные потребности в текстовых символах. Поэтому было принято решение. Таблицу кодов разделить пополам: первые 128 кодов (от 0 до 127) должны быть стандартными и обязательными для всех стран и всех компьютеров, а во второй половине (128 до 255 кода) каждая страна может делать всё что её угодно.
Первые 32 кода базовой таблицы, начиная с нулевого, отданы производителям аппаратных средств. В этой области размещаются управляющие коды, которым не соответствуют ни какие символы языков. Начиная с 32 по 127 код размещены коды символов английского алфавита, знаков препинания, арифметических действий и некоторых вспомогательных символов.
Первую половину таблицы кодов называют таблицей ASCII – ее ввел американский институт стандартизации ASCII (American Standard Code for Information Interchange – стандартный код информационного обмена США). За вторую половину кодовой страницы стандарт ASCII не отвечает. Разные страны могут создавать свои таблицы (национальные кодовые таблицы). ASCII – это своеобразный компьютерный алфавит, в котором каждому символу соответствует его порядковый номер в кодовой таблице (рис. 3). Компьютер переводит порядковый номер символа в двоичную систему счисления и далее работает уже не с символом, а с его кодом. Например, букве «A» английского алфавита соответствует номер 65.
«A» = 65 = 0100 0001 Так выглядит код буквы А, представленный с помощью 1 байта.
Кодировка символов русского языка, известная как кодировка Windows-1251, была введена «извне» – компанией Microsoft, но, учитывая широкое распространение операционных систем и других продуктов этой компании в России, она глубоко закрепилась и нашла широкое распространение.
Д
Рис
3. Таблицы кодировки ASCII
Международный стандарт, в котором предусмотрена кодировка символов русского языка, носит названия ISO (International Standard Organization – Международный институт стандартизации). На практике данная кодировка используется редко.
Если проанализировать организационные трудности, связанные с созданием единой системы кодирования текстовых данных, то можно прийти к выводу, что они вызваны ограниченным набором кодов (256). В то же время, очевидно, что если, кодировать символы не восьмиразрядными двоичными числами, а числами с большим разрядом то и диапазон возможных значений кодов станет на много больше. Такая система, основанная на 16-разрядном кодировании символов, получила название универсальной – UNICODE. Шестнадцать разрядов позволяют обеспечить уникальные коды для 65 536 различных символов – этого поля вполне достаточно для размещения в одной таблице символов большинства языков планеты.
Несмотря на тривиальную очевидность такого подхода, простой механический переход на данную систему долгое время сдерживался из-за недостатков ресурсов средств вычислительной техники (в системе кодирования UNICODE все текстовые документы становятся автоматически вдвое длиннее). Во второй половине 90-х годов прошлого века технические средства достигли необходимого уровня обеспечения ресурсами, и сегодня мы наблюдаем постепенный перевод документов и программных средств на универсальную систему кодирования.
Кодирование графических данных. Если рассмотреть с помощью увеличительного стекла черно-белое графическое изображение, напечатанное в газете или книге, то можно увидеть, что оно состоит из мельчайших точек, образующих характерный узор, называемый растром. Поскольку линейные координаты (x, y) и индивидуальные свойства каждой точки (яркость) можно выразить с помощью целых чисел, то можно сказать, что растровое кодирование позволяет использовать двоичный код для представления графических данных.
Общепринятым на сегодняшний день считается представление черно-белых иллюстраций в виде комбинации точек с 256 градациями серого цвета, и, таким образом, для кодирования яркости любой точки обычно достаточно восьмиразрядного двоичного числа.
Для кодирования цветных графических изображений применяется принцип декомпозиции произвольного цвета на основные составляющие. В качестве таких составляющих используют три основные цвета: красный (Red), зеленый (Green) и синий (Blue). На практике считается, что любой цвет, видимый человеческим глазом, можно получить механического смешения этих трех основных цветов. Такая система кодирования получила названия RGB по первым буквам основных цветов.
Человеческий глаз может различать десятки миллионов цветовых оттенков. Учитывая вышесказанное решили кодировать цвет используя 3 байта. С помощью 3 байт можно закодировать 16,5 мил цветов. Первый байт выделяется красной составляющей, второй – зелёной, третий – синей. В каждый байт записывается значение яркости соответствующей составляющей (от 0 до 255). Таким образом белый цвет кодируется тремя полными байтами 255 255 255. Черный цвет – 0 0 0.
Режим представления цветной графики с использованием 24 двоичных разрядов называется полноцветным (True Color).
Каждому из основных цветов можно поставить в соответствие дополнительный цвет, т.е. цвет, дополняющий основной цвет до белого. Нетрудно заметить, что для любого из основных цветов дополнительным будет цвет, образованный суммой пары остальных основных цветов. Соответственно дополнительными цветами являются: голубой (Cyan), пурпурный (Magenta) и желтый (Yellow). Принцип декомпозиции произвольного цвета на составляющие компоненты можно применять не только для основных цветов, но и для дополнительных, т.е. любой цвет можно представить в виде суммы голубой, пурпурной и желтой составляющей. Такой метод кодирования цвета принят в полиграфии, но в полиграфии используется еще и четвертая краска – черная (Black). Поэтому данная система кодирования обозначается четырьмя буквами CMYK (черный цвет обозначается буквой К, потому, что буква В уже занята синим цветом), и для представления цветной графики в этой системе надо иметь 32 двоичных разряда. Такой режим также называется полноцветным.
Если уменьшить количество двоичных разрядов, используемых для кодирования цвета каждой точки, то можно сократить объем данных, но при этом диапазон кодируемых цветов заметно сокращается. Кодирование цветной графики 16-разрядными двоичными числами называется режимом High Color.
При кодировании информации о цвете с помощью восьми бит данных можно передать только 256 оттенков. Такой метод кодирования цвета называется индексным.
Кодирование звуковой информации. Приемы и методы работы со звуковой информацией пришли в вычислительную технику наиболее поздно. К тому же, в отличие от числовых, текстовых и графических данных, у звукозаписей не было столь же длительной и проверенной истории кодирования. В итоге методы кодирования звуковой информации двоичным кодом далеки от стандартизации. Множество отдельных компаний разработали свои корпоративные стандарты, но среди них можно выделить два основных направления:
1. Метод FM (Frequency Modulation) основан та том, что теоретически любой сложный звук можно разложить на последовательность простейших гармонических сигналов разных частот, каждый из которых представляет собой правильную синусоиду, а, следовательно, может быть описан числовыми параметрами, т.е. кодом. В природе звуковые сигналы имеют непрерывный спектр, т.е. являются аналоговыми. Их разложение в гармонические ряды и представление в виде дискретных цифровых сигналов выполняют специальный устройства – аналогово-цифровые преобразователи (АЦП). Обратное преобразование для воспроизведения звука, закодированного числовым кодом, выполняют цифро-аналоговые преобразователи (ЦАП). При таких преобразованиях неизбежны потери информации, связанные с методом кодирования, поэтому качество звукозаписи обычно получается не вполне удовлетворительным и соответствует качеству звучания простейших электромузыкальных инструментов с окрасом характерным для электронной музыки. В то же время данный метод копирования обеспечивает весьма компактный код, поэтому он нашел применение еще в те годы, когда ресурсы средств вычислительной техники были явно недостаточны.
2. Метод таблично волнового (Wave-Table) синтеза лучше соответствует современному уровню развития техники. В заранее подготовленных таблицах хранятся образцы звуков для множества различных музыкальных инструментах. В технике такие образцы называют сэмплами. Числовые коды выражают тип инструмента, номер его модели, высоту тона, продолжительность и интенсивность звука, динамику его изменения, некоторые параметры среды, в которой происходит звучание, а также прочие параметры, характеризующие особенности звучания. Поскольку в качестве образцов исполняются реальные звуки, то его качество получается очень высоким и приближается к качеству звучания реальных музыкальных инструментов.
Перед тем как кодировать любую информацию нужно договориться о том, какие используются коды, в каком порядке они записываются, хранятся и передаются. Это называется языком представления информации.