

Весовые коэффициенты
До сих пор рассматривались отдельно взятый документ, не принимая во внимание, что он входит в базу данных наряду со множеством других документов. Если все документы одной и той же тематики или направления представить в виде одного, очень большого документа, то и к такому составному документу также применимы законы Зипфа.
Использование составного документа позволяет повысить качество выборки значащих слов (или их рейтинг) путем введения нового понятия инверсная частота термина, которая характеризует вес или значимость термина. Под термином может пониматься не только отдельное слово, но и единое по смыслу словосочетание
Инверсная частота термина i определяется выражением
 , (1.1)
, (1.1)
Где n ‑ общее число рассмотренных документов,
m – количество документов, содержащих данный термин.
Использование инверсной частоты позволяет снизить опасность попадания малозначащих терминов в состав выборки. С учетом инверсной частоты вес или значимость термина в каждом документе определится выражением
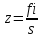 , (1.2)
, (1.2)
где z — вес или значимость термина в некотором документе;
f— частота повторения термина в рассматриваемом документе;
i — инверсная частота этого термина в группе документов;
s— количество значащих слов в рассматриваемом документе.
Кстати, вес или значимость одного и того же термина в различных документах обычно существенно отличается друг от друга.
Роль инверсной частоты в приведенной формуле состоит в том, чтобы уменьшить вес слов и устойчивых словосочетаний, которые выполняют вспомогательные функции в документе, обеспечивая стиль и определенный характер повествования. Для случайных слов и сочетаний мала частота повторения терминов f, а для стоп-слов и вспомогательных понятий стремится к нулю инверсная частота i. Таким образом, вес или значимость термина z позволяет выделить именно ключевые слова и сочетания. Этот же параметр позволяет также ранжировать значащие слова, т. е. построить их последовательность в порядке значимости.
Автоматизация построения ипт
Используя специальное программное обеспечение, можно автоматизировать процессы построения ИПТ, в настоящее время автоматизированы следующие процессы:
-
формирование словника;
-
анализ частоты встречаемости слов и словосочетаний;
-
алфавитная сортировка словника;
-
формальная проверка непротиворечивости ссылок, их взаимности;
-
формирование алфавитного, пермутационного указателей и указателя иерархических отношений;
-
распечатка в требуемых формах.
При автоматизации процессов создания и ведения тезаурусов наиболее часто используют следующие методы: статистический метод, метод свободного индексирования, метод пополнения и коррекции тезауруса в процессе эксплуатации.
Статистический метод применяют для установления степени смысловой близости пар элементов тезауруса, характеризуемой коэффициентом ассоциации. Коэффициент ассоциации определяется как отношение числа документов, в которых встречаются оба слова, к общему числу документов, в которых встретилось хотя бы одно из них. В результате в статью тезауруса включаются слова, коэффициент ассоциации которых с заглавным словом превышает.
Метод свободного индексирования используется на этапе отбора лексических единиц. Свободное индексирование входных документов обеспечивает полноту списка ключевых слов и его непрерывное обновление и пополнение. В процессе автоматического составления списка ключевых слов по текстам документов используются данные о частоте совместной встречаемости слов и скорости появления новых слов. Кроме того, используются списки запрещенных к употреблению слов. Могут использоваться и методы формализованного выделения лексики из документов. В основе этих методов лежат принципы морфологического и синтаксического анализа текста.
Одним из важных этапов автоматизации ведения тезауруса является его обновление, заключающееся в удалении существующих и включении новых дескрипторов на основании критериев используемости. Каждый дескриптор сопровождается информацией о частоте его используемости. Такая же информация сопровождает и новые слова, которые отсутствуют как в тезаурусе, так и в списке запрещенных слов. Регулярно проверяется соответствие частоты используемости каждого дескриптора критерию значимости, если частота не соответствует критерию, то такой дескриптор перемещается в список запрещенных слов. И наоборот, если частота использования нового слова соответствует критерию значимости, то тезаурус пополняется данным словом, которое автоматически включается в соответствующие иерархические деревья тезауруса и формируются ассоциативные связи.
Отношения между словами устанавливают в одном направлении: от рода к виду или целого к части. Обратные связи осуществляются ЭВМ автоматически путем инверсии установленных отношений.
Чтобы реализовать автоматизацию вышеперечисленных процессов, а также ввести их в АИС, при создании тезауруса для каждого дескриптора создаются отдельные записи в определенном формате. Для этих целей используют Российский коммуникативный формат представления авторитетных и нормативных записей, а также RUSMARC.