

Лекция 1.Краткое введение.
ОС – совокупность программ для выполнения двух функций:
- предоставление пользователю удобных средств управления ЭВМ (электронно-вычислительной машиной) путем моделирования более расширенной машины, которая может выполнять более сложные действия, чем реальный компьютер.
- более рациональное управление ресурсами компьютера, ведущее к повышению эффективности его работы.
Эти функции, очевидно, взаимосвязаны..
(истоки этих функций)
ОС как расширенная машина.
Так как пользователь не может запомнить язык машинных команд, дополняемый командами, необходимыми для управления внешними устройствами, то возникает потребность в посреднике между человеком и компьютером, которым становится ОС.

Вывод: предоставление пользователю дружественного интерфейса или, другими словами, организация интерфейса пользователя.
Рациональное управление ресурсами ЭВМ.
С т.з. пользователя и выполняемых им программ: если компоненты требуются, и они есть, то программа будет выполнена, а если необходимых компонентов нет, то она выполнена быть не может.
Ресурсы – это все те компоненты вычислительной системы, которые требуются для выполнения программ пользователя.

Состав системы управления ресурсами:
- управление процессором
- управление оперативной памятью
- управление данными (размещение их на внешних носителях и доступ к ним)
- управление устройствами
(с точки зрения аппаратной части)
- управление пользователями (доступ их к ресурсам для выполнения их задач)
(на самом деле пользователь не может получить доступ к ресурсам ЭВМ непосредственно, а только через некоторые программы)
Процесс – программа на стадии выполнения. *
- управление процессами
И т.о. можно дать определение, что ОС – система программ, выполняющая соответственные шесть функций.
* Процесс в ОС UNIX - это совокупность следующих компонент: программы, находящейся на стадии выполнения; данных, обрабатываемых этой программой; ресурсов, необходимых для выполнения программы и вспомогательных структур данных ядра операционной системы, использующихся для управления работой программы.
Лекция 2.
Развитие информационных систем шло параллельно с вычислительной техникой, поэтому их этапы развития связанны. Выделяют 4 поколения ЭВМ и соответственно 4 поколения ОС.
Сравним ЭВМ и ОС по параметрам: стоимость, объем памяти, быстродействие. Цифры условны, в пределах одного поколения могут различаться на порядок.
Поколения ОС.
1-ое поколение.
-45-55 г.г. – первое поколение ЭВМ. Наиболее распространенны ЭВМ на электронных лампах. Размеры ламп, по устройству более сложных, сопоставимы с лампами накаливания. Для записи одного бита требуется один триггер, составленный из 2-х ламп. Объем памяти 10 Кб, скорость несколько сотен операций в секунду, стоимость – несколько, около десятка, миллионов долларов. Такими ЭВМ пользовались, в основном, военные и ученые, разрабатывающие главным образом оружие. Количество машин исчислялось единицами, и легко было подготовить достаточное количество высококлассных специалистов. Задачи изменения интерфейса не стояло, существовал интерфейс машинных команд. Создавать такие программы трудно, а модифицировать – практически не возможно. Чаще всего такие компьютеры использовались для вычислительных задач и составления математических таблиц. ОС не существовало в нашем понимании, но были выделены общие алгоритмы, которые часто использовались, они объединялись в библиотеки, которые могли быть использованы программистами.
2-ое поколение.
-55-65 г.г.- Элементная база – транзисторы. Подешевели на порядок. Возможности выросли. Объем памяти – около 100 Кб, быстродействие – 10 тыс. оп./сек. Ресурсы возросли, но оставалась высокая цена. ЭВМ из уникальных устройств стали превращаться в компоненты, широко используемые в промышленности, а потому расширился круг пользователей. Стоимость упала на процессор и память, а внешние устройства оставались механическими, работали медленно. Для того, чтобы выполнить задачу необходимо сначала ввести информацию, затем в автоматическом режиме она обрабатывалась. Потом происходил вывод информации. Ввод/вывод информации занимали 90-99% времени, требовалось повысить эффективность работы ЭВМ. Ввод информации осуществлялся с помощью перфокарт, и так как это механический процесс, то ускорить его в этом виде мы не можем. Разработчики ОС пошли следующим путем: программисты должны готовить программы в особом виде: указать для программ объем памяти, требуемое время процессора, используемые устройства – на основе данных можно разработать план выполнения. Для описания задач был создан Язык Управления Заданиями.
Если в первом поколении программист сам запускал свою программу на работу и непосредственно управлял ЭВМ. Теперь для повышения эффективности нельзя позволять программисту самому управлять ЭВМ.
Задание = программа + данные
Программист готовит задание, относит его в вычислительный центр, там формируется очередь заданий и перезапись их на относительно быстрый носитель данных. Далее ОС в автоматическом режиме обрабатывала задания и распечатывает результаты. Для поддержки подобной системы созданы простейшие ОС. Они позволяли поддерживать Язык Управления Заданиями (ориентированные на удобство ЭВМ), автоматизировали процесс ввода/вывода данных. Начали разрабатываться, внедряться и распространяться ЯП высокого уровня, н-р Fortran, Algol и др., которые специализированны под свои задачи (ОС поддерживали ЯП высокого уровня), Основной принцип работы таких ОС – пакетный режим. Главная проблема- программист изолирован от ЭВМ, низкая эффективность труда программиста.
3-е поколение.
-65-80 г.г. Переход к новой элементной базе – интегральные схемы. Цена упала еще на порядок (сотни тысяч долларов). Объем памяти несколько, около 10, МБ. Скорость – несколько тысяч операций в секунду. Появились первые суперкомпьютеры. Количество компьютеров увеличивалось, их ресурсы возросли. Компьютеры теперь используются для хранения и обработки данных, в частности баз данных (БД). С компьютерами стали работать люди, занимающиеся ИС.
Создание семейств программ - вычислительных машин:
Семейство IBM 360, (в начале 70-х IBM 370).
Больше ресурсов, много пользователей, в том числе не-программистов – существенным фактором для развития ОС стало изменение интерфейса. Появилась тенденция к модернизации компьютеров, поэтому компьютеры одного семейства стали делать программно совместимыми. Стоимость компьютеров упала и стала сравнима с зарплатой персонала, который на них работают – требуется повысить эффективность работы персонала.
ОС:
- создавали развитый интерфейс
- обеспечивали эффективную работу как компьютера, так и персонала.
В ОС поддерживается принцип мультипрограммирования – в памяти компьютера единовременно находятся и могут по очереди выполняться несколько программ.
Процессор занят примерно 1/10 часть времени выполнения программы.
Эффективность работы персонала повысилась следующим образом: если программа А принадлежит программисту 1, а В – программисту 2, то два программиста одновременно решают свои задачи. При этом можно организовать диалоговый режим общения с программистом для коррекции выполнения задач, создаются терминалы. Такие системы получили широкое распространение, их называют системами разделения данных.
Мультипрограммирование повысило требования к ЭВМ и ОС.
Диалоговый режим подразумевает возможность запуска программы, ее корректировки, получения результатов.
Появился интерфейс командной строки (передавалось ОС непосредственно или опосредованно, что позволяло управлять работой вычислительной системы). Существовали разные режимы, в некоторых случаях число пользователей ограниченно, мультипрограммирование с фиксированным числом задач, память разбивалась на фиксированное число областей фиксированного размера (на более слабых компьютерах, так как надо меньше ресурсов для ОС). На более сложных компьютерах поддерживается система мультипрограммирования с переменным числом задач.
Компьютеры 3-его поколения стали использоваться для управления технологическими процессами. Главное требование для них стало: в качестве реакции на некоторый процесс время ответа должно быть фиксировано и не превышать определенное значение. Необходимость создания нового режима работы ОС, названного режимом работы в реальном времени. Основной же режим работы называется режим разделения реального времени.
Все равно существовали вычислительные задачи, которые требовали несколько суток, с использованием пакетного режима и без необходимости диалога. Т.о. ОС поддерживали три режима
4-ое поколение.
80-е г.г. – до настоящего времени. Элементная база – интегральные схемы с повышенным уровнем интеграции. ЭВЫМ 4-ого поколения конструктивно мало отличаются от 3-его., но резко упала цена и уменьшились размеры. История 4-ого поколения тесно связанна с появлением ПК. ПК получили самое широкое распространение, пользователи же стали малоквалифицированны. Основное требвание к ОС – дружественный интерфейс. Методы управления более наглядны и приближенны к бытовому пониманию. Ресурсы увеличились, что позволяет использовать развитые ОС. Сами ПК повторили по ресурсам развитие ЭВМ, кроме быстродействия. Интерфейс должен быть не ниже командной строки.
В -85г. разработан стандарт интерфейса работы пользователя. Изначально рассчитан на алфавитно-цифровые экраны, затем перенесен на графический интерфейс. По мере развития соответствующих средств развился к концу 80-х графический интерфейс, особенно с семейством Windows.
Черты ОС:
- поддержка стандартного интерфейса, в т.ч. графического.
-развитие сетевых средств.
- возможность запуска нескольких программ (просто удобство)- система мультипрограммирования.
-продолжается развитие многопользовательского режима.
Лекция 3.
Классификация ОС.
Единой классификации не существует. Признаки:
поддержка многозадачности
однозадачные (обработка и выполнение одной задачи – MS-DOS, Windows до 3.1 – в частности, не предусматривалась защита программ и их ресурсов от доступа других программ
многозадачные (одновременно выполняется несколько задач – управляют распределением ресурсов)
по распределению времени они делятся:
системы с невытесняющим режимом работы (Windows 3.1, 3.11)
вытесняющая многозадачность.(Unix, Windows NT и эта линейка)
имеется в виду, что время, выделяемое на выполнение ограниченно, затем ее работа приостанавливается, процессор переходит к другой задаче.
Поддержка многонитевости – иметь несколько управляющих потоков и вести вычисления параллельно
по числу пользователей
однопользовательские (нет средств защиты от несанкционированного доступа)
многопользовательские (защита выделенных ресурсов)
поддержка многопроцессорной работы
многопроцессорная система
система без такой поддержки
многопроцессорные:
симметричные – использует все процессоры, разделяя между ними работу поровну
ассиметричные – занимает один процессор, позволяя прикладным программам работать на других процессорах
иногда ОС разделяют по признакам ядра
Ядро – часть ОС, работающая в привилегированном режиме, не доступном другим программам.
система с монолитным ядром
система с микроядром
Монолитное ядро – перед началом работы формируется единственная программа, внутри которой выделяются части: управление ресурсами, управление данными и т.д. и часть системы, синхронизирующая и управляющая работой.
Микроядро – такое ядро, которое включает в себя только часть, отвечающую за управление работой и синхронизацию, а остальные части выносятся за пределы ядра и работают в обычном, непривилегированном режиме.
В системах с микроядром проще проверять работу программы, устранять ошибки, которая ограничивается одним модулем, обеспечивается переносимость ОС. Недостаток – менее эффективная работа из-за необходимости переключения между обычным и привилегированным режимом.
Пр-р: Windows NT 4.0
Часто приходится переделывать системы с микроядром в системы с монолитным ядром..
Управление
процессами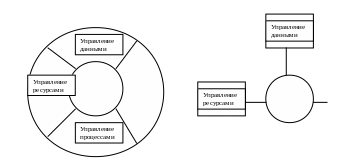

Базовые компоненты программной и аппаратно поддержки режима мультипрограммирования.
Термины:
Мультипрограммирование - режим работы компьютера, при котором в памяти компьютера одновременно находятся и поочередно выполняются несколько программ.
Пользователь – любой человек, которому разрешена работа на компьютере. Любая многозадачная система должна предусматривать авторизацию пользователя, выделение ресурсов и защиту ресурсов от несанкционированного доступа.
Программа – последовательность команд, которая должна быть выполнена для выполнения задач пользователя (прикладные) или управления (системные).
Управляющий поток команд или просто поток с точки зрения процессов можно рассмотреть программу как процесс, мы будем ее так называть, когда хотим указать на ее функции управления.
Ресурсы – компоненты программно-аппаратной среды, необходимые программе для ее выполнения.
Программные компоненты – компоненты ОС, которые выделяются для выполнения программы.
Процесс – для того, чтобы вести учет и распределение ресурсов, в ОС поддерживается абстрактное понятие процесса, поддерживающее концепцию управления и владения ресурсами.
Процесс = управляющий поток + ресурсы
Контекст процесса – совокупность данных, полностью характеризующая текущее состояние ЦП, а именно ресурсы и управляющие программы. Эта совокупность должна быть настолько полной, чтобы в случае необходимости, используя контекст процесса, можно возобновить выполнение процесса.
Концептуальная схема компьютера.
А
Процессор –
устройство работы с данными


 рхитектура
Фон Неймана (автоматизация
вычислительного_процесса).
рхитектура
Фон Неймана (автоматизация
вычислительного_процесса).
 )
)
ШИНА
Такое устройство в мультизадачном режиме не возможно.
Проблемы:
необходимо программное выделение времени процессора:
-возможность захвата процессора одной программой (бесконечные циклы)
-если процессор освободился от программы, то чтобы запустить следующую, он должен по каким-то признакам выбрать ее из очереди на выполнение
переключение процессора с выполнения одной программы на другую
-если ОС управляет аппаратурой, то только ОС должна ими управлять – централизация управления внешними устройствами
многопользовательский режим
-пользователи могут запустить столько программ одновременно, что ОП может не хватить. Необходимо обеспечить память, сколько бы задач не было запущено
-память не может быть такой же быстрой как ЦП, так как такая память очень дорогая – проблема уменьшения времени доступа к ОП.
-проблема распределения памяти
-из-за ошибок одна программа может получить доступ к области памяти другой программы – требуется защита памяти
3) Устройства ввода/вывода и длительное хранения данных
- эти устройства электромеханические, а ОП и ЦП – электронные, механические компоненты всегда очень медленные, максимальная скорость – около скорости звука. Т.е. эти устройства медленные конструктивно.
- распределение устройств между одновременно выполняемыми программами.
- обеспечение удобного интерфейса пользователя с этими устройствами.
4) шина
- чем сложнее компьютер, тем более узким местом станоится шина, а т.к. это единственный способ передачи данных, то используется несколько шин: управления, данных, адресная.
Как решаются проблемы:
Процессора:

Возможность автоматической обработки. Существует ряд операций, называемых базовыми операциями процессора. Все команды преобразуются к базовым операциям процессора. Процессор работает по следующему циклу:
чтение команды из памяти по адресу, находящемуся в счетчике команд
декодирование команды
изменение значения счетчика команд так, чтобы он указывал на следующую команду программы
выполнение команды
Основные проблемы, связанные с использованием процессора в режиме мультипрограммирования:
1.выбор программы, которая должна выполняться следующей (решение: планировщик процессора - определяет очередность выполнения программ)
2. централизация управления внешними устройствами
3. переключение процессора с выполнения 1 программы на другую и возможность захвата процессора 1 программой
Для режима мультипрограммирования
(в рамках схемы Фон Неймана е предусмотрено переключение между программами)
требуется сделать следующее
приостановить выполнение программы, сохранив значение IP и ОР
записать в IP новый адрес
Цикл ЦП бесконечен. Возможны приостановки и переключения на другую задачу – они реализованы аппаратно.
Выбор новой программы из списка на выполнение – задача планировщика процессов (решается программно).
Захват процессора одной программой избегается за счет следующего: выполнение программу необходимо приостановить, для чего используется режим квантования времени. Периодически происходит приостановка любой программы, выполняемой процессором, через определенные кванты времени. Приостановка происходит по сигналу системного таймера: процессор прекращает свой бесконечный цикл работы, переключаясь к ОС.
Централизация управления устройствами.
Должны существовать средства, которые не позволят пользователю вмешаться в управление. Для этого необходимо модифицировать процессор.
Все базовые операции процессора и соответственно можно (1 средство) разделить на: общие и привилегированные, которые должны выполняться только системными программами. (2 средство) Для процедур в режиме мультипрограммирования используются два режима: режим пользователя, в котором доступно выполнение только обычных команд, и режим ядра, в котором можно выполнять как обычные, так и привилегированные команду. (3 средство) Для определения режима работы процессор использует слово состояния процессора, Processor Status Word. Пользовательские программы могут слово состояния процессора только читать, а в режиме ядра системные программы – и писать. Т. О. для управления оборудованием пользовательские программы вынуждены обращаться к ОС, по завершении выполнения модуля ОС процессор вновь переключается в пользовательский режим. PWS содержит еще и служебную информацию.
Лекция 4.
Централизация управления устройствами.
Должны существовать средства, которые не позволят пользователю вмешаться в управление. Для этого необходимо модифицировать процессор.
Все базовые операции процессора и соответственно можно (1 средство) разделить на: общие и привилегированные, которые должны выполняться только системными программами. (2 средство) Для процедур в режиме мультипрограммирования используются два режима: режим пользователя, в котором доступно выполнение только обычных команд, и режим ядра, в котором можно выполнять как обычные, так и привилегированные команду. (3 средство) Для определения режима работы процессор использует слово состояния процессора, Processor Status Word. Пользовательские программы могут слово состояния процессора только читать, а в режиме ядра системные программы – и писать. Т. О. для управления оборудованием пользовательские программы вынуждены обращаться к ОС, по завершении выполнения модуля ОС процессор вновь переключается в пользовательский режим. PWS содержит еще и служебную информацию.
Прерывания. Обработка прерываний.
Прерывание – аппаратно реализуемая функция процессора, предназначенная для переключения процессора с одной программы на другую.
Группы прерываний:
программные прерывания – из-за ошибок в работе программы, когда дальнейшее выполнение программы невозможно.
Пример – деление на 0. пример – прерывание, возникающее из за превышения порядка (очень маленькое число) не прекращает выполнения программы, но вместо некорректного результата записывает 0.
Прерывания при обращении к ядру или ОС.
Инициализируются в программе, обычно когда необходимо получить информацию с внешних устройств или записать ее.
Прерывания ввода/вывода – инициализируются внешними устройствами: закончилось или не закончилось действие, требуется сообщить процессору
Внешние прерывания – от других УУ для синхронизации
Прерывания схем контроля
Существует специальная шина – шина прерываний – по которой передаются прерывания от устройств
Обработка прерываний.
Любая аппаратно реализуемая функция не может быть слишком сложной – требуется вмешательство ОС
В обработке прерываний участвуют:
1) процессор – выполняет стандартную последовательность действий
2) компонент ОС – обработчик прерываний –описывает действия, которые необходимо выполнить в ответ на прерывание, сложные действия, описываемые программой
3) вектор прерываний – фиксированная область памяти, содержит начальный адрес обработчиков прерываний
4) системный стек – область памяти, используемая ОС для временного хранения информации
в
системе может быть много видов прерываний,
система идентифицирует их по номеру.
Номер прерывания, соответственно, должен
быть известен процессору
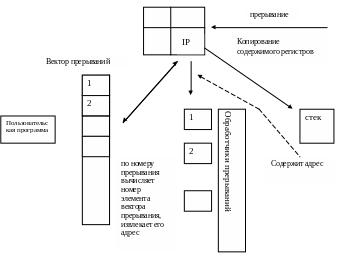
Обработка прерывания:
Получив сигнал прерывания процессор прекращает выполнение активной программы
Содержимое регистров процессора сохраняется в текущем стеке
В регистре PSW устанавливается режим ядра работы процессора
По номеру прерывания из вектора прерываний выбирается адрес соответствующего обработчика прерываний
Адрес обработчика прерываний загружается в счетчик команд процессора
Процессор извлекает и выполняет команду, адрес которой находится в счетчике команд, и, таким образом, начинается выполнение обработчика прерываний
Последним действием обработчика прерываний является извлечение из стека и загрузка содержимого регистров процессора, включая счетчик команд.
Обнаружив в счетчике команд адрес очередной команды прикладной программы, процессор продолжает ее выполнение.
Последовательность команд обработчика прерываний – взять данные из стека и скопировать их обратно. При помощи такой схемы всегда можно остановит время выполнения программы.
Если процессор получил несколько прерываний от различных внешних устройств, то есть две ситуации:
в стек помещается текущее прерывание, а вновь поступившее прерывание обрабатывается
обрабатывается более срочное прерывание или то, которое невыгодно прерывать. Тогда для остальных устанавливается запрет на прерывания.
Запрет на прерывания:
Маска прерывания – если бит установлен в 0, в данный момент прерывание этой группы может быть обработано, маска строится в соответствии с группами.
Сам пользователь может запретить обработку только некоторых прерываний, ОС на какой-то момент времени может теоретически запретить все прерывания.
Запрет на прерывания не означает, что поступившие прерывания вовсе не будут обработаны. Их требуется выполнить, определяя порядок обработки. Это осуществляет контроллер прерываний, к которому и подключается шина прерываний. Именно контроллер передает процессору номер прерываний.
Память.
Проблемы: уменьшения времени доступа и обеспечения достаточного объема.
Решаются
с помощью иерархической организации
памяти.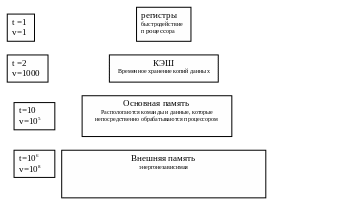
Единицы измерения условные, как сравнительная характеристика
Сокращается время доступа за счет копирования данных в КЭШ. При переключении между программами, содержимое КЭШ-а сохраняется. Обеспечение достаточного объема – во время выполнения конкретной команды происходит обращение только к некоторым командам и данным, они должны быть размещены, по крайней мере, в основной памяти, а остальные, неиспользуемые, могут размещаться во внешней памяти – виртуальная память.
Проблемы: распределение памяти и защита.
Для распределения необходимо вести учет памяти. Модуль управления памяти – менеджер либо планировщик памяти. Возникает еще проблема – существует область памяти, для выполнения программы. Как написать программу, чтобы она не выходила за пределы этой области. Вводятся два вида адресации: логическая, или относительная, и физическая адресация(?). Настройка по месту – определение физического адреса программы и соответственное значение прибавляется к логическим адресам. Это делает загрузчик ОС, который передается адрес, с которого будет выполняться программа.
Проблема дефрагментации памяти.
ОС периодически перемещает (уплотняет) программы в памяти. Т.Е. приходится преобразовывать логические адреса в физические во время выполнения программы. Для этого используются дополнительные регистры дополнительного назначения, н-р, для суммирования логических и физических адресов.
Обычно в ОС включаются регистры Memory Mementionate Omak (?) – MMO (между шиной и памятью).
Лекция 5.
Устройства ввода/вывода.
При работе устройств ввода/вывода и устройств хранения данных возникают сходные проблемы.
Проблемы:
это электро-механические устройства, и оказывается, что их быстродействие много меньше процессора. Возникает проблема выравнивания быстродействия.
исключительное разнообразие в конструктивных особенностях и принципах управления. Проблема организации управления этими устройствами.
Проблема организации доступа пользователя к этим устройствам
ОС должна обеспечивать организованный доступ к устройствам. Решения аппаратные и программные, имеется несколько уровней решения..
ВУ
– внешние устройства (ввода/вывода или
хранения данных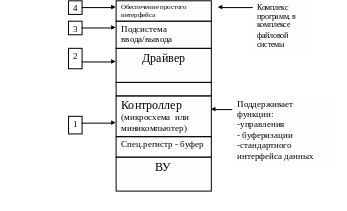 )
)
Производитель позволяет автоматизировать управление устройствами – чтение, сигналы об ошибках, формирование блоков, поиск.(1)
Буферизация помогает ускорить обмен данными – меньше обращений процессора к контроллеру(1).
Стандартный интерфейс данных. Преобразование данных из внутреннего бинарного вида (представления) в форму, пригодную для внешней обработки (1).
Однако контроллеры могут сильно отличаться друг от друга – необходимо стандартизировать обращение к устройству.(2)
Драйвер позволяет создать стандартный интерфейс записи и чтения с устройства. Задачи: преобразовать внешние обращения на чтение/запись в команды контроллера.
Устройства ВВ делятся на символьные (обмен побайтно) и битные..
Для первых вводится две операции: GET и PUT – считать или соответственно поместить один байт, для вторых – READ – прочитать и WRITE - записать блок.
Подсистема ВВ:
-преобразование запросов системных или прикладных программ в вызовы функции драйвера.
-управление согласованной работой между устройствами и распределение устройств между процессорами
- повышение производительности ВУ за счет кэширования данных.
Файловая система обеспечивает простоту интерфейса.
При работе с большими объемами данных даже буфер малоэффективен, для того, чтобы сократить время доступа к данным используется специальное устройство, которое дает возможность непосредственного обмена между контроллером и памятью, не процессор координирует их работу, а контроллер прямого доступа обращается к памяти – Direct Memory Access (DMA).
Чтобы быстрее передавать данные по шине используют мультишину (объединение нескольких шин).
Принципиальная схема компьютера:
Системный таймер
DMA
У-ва
хранения данных
контроллер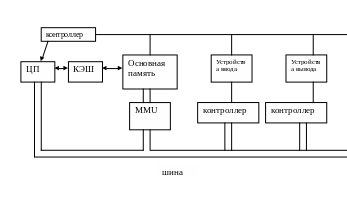
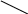




 Интерфейс
ОС с прикладными программами:
Интерфейс
ОС с прикладными программами:
Чтобы ПП могли обратиться к местам выполнения команд ОС, они должны знать точки доступа к системным адресам ОС – это называется системным вызовом. Application Program Interface – к этим программам обращается прикладная программа, чтобы выполнить требуемую функцию.
Лекция 6.
Файловая система:
Абстрактная модель файла предполагает, что наименьшей единицей хранения информации является именованный файл.
Задействуется механизм именования.
Наименьшей единицей хранения информации – файл. Интерфейс скрывает механизм сохранения файла на внешнем устройстве. Для получения доступа пользователю достаточно указать имя файла.
Распределение абстрактной системы:
Базовая модель последовательного файла. С точки зрения пользователя файл представляет множество элементов, называемых логическими записями, с точки зрения пользователя эти элементы – наименьшие, которые участвуют в обмене данных с внешними устройствами.
Основные свойства:
Если в файле отсутствует хотя бы одна логическая запись, то файл считается пустым, модель допускает существование такого файла.
Если файл не пустой, то мы всегда можем указать первую логическую запись, до которой не следует ни одна логическая запись и единственную последнюю запись, за которой не следует ни одна логическая запись. Для любой логической записи, отличной от первой и последней, можно указать предыдущую и следующую запись.
Каждая логическая запись имеет свою структуру, состоит из нескольких компонент, называемых полями записи. Количество и структуру полей определяет пользователь.
Обработка логических записей в файле.
Текущая позиция файла – указывает, какая логическая запись будет подвергнута обработке. Обычно текущая позиция указывается как смещение в байтах от начала файла, 0 соответствует начало файла.
Определяются базовые операции:
Запись write - операция записи в файл, начиная с текущей позиции размещается новая запись, значение текущей позиции увеличивается. Если текущая позиция указывается на последнюю запись, то его размер увеличивается, а текущая позиция смещается в конец.
Чтение read – начиная с текущей позиции считывается несколько байт, данные после этого не удаляются, а текущая позиция перемещается на соответствующее количество логических записей. Мы можем читать записи только последовательно – все записи обрабатываются последовательно.
Дополнительные операции – вне абстрактной модели:
Create – выполняется создание нового пустого файла.
Delete – удаление файла, удаляются все данные (не обязательно физически) с ВУ, освобождается пространство и элементы вспомогательных структур.
Open – открытие файла, необходимо для выполнения базовых функций.
Close – закрытие файла,
Если данные по какой-то причине данные не перемещены в логический файл, они перемещаются логически (?)
В любой абстрактной структуре непосредственный доступ к файлам невозможен.
Файловая система – совокупность данных файловых или системных данных и данных пользователя.
Требование к ОС: пользователь не должен иметь доступ ни к одному файлу.
Основные функции файловой системы:
Связывание имени файла с местом, выделенным этому файлу.
Распределение места между файлами, распределение свободной памяти, учет свободного места.
Должна обеспечивать надежность
Защита от несанкционированного доступа
Обеспечение доступа к файлам (физического)
Во многих ОС абстрактная модель одинакова. Методы сохранения файла сходны. Различие с точки зрения пользователя файловой системы
С точки зрения возможности, которые представляет пользователю
ОС может не сохранять, куда записывается файл
Методы организации структуры для пользователя
Организация защиты файлов от несанкционированного доступа
Средства управления файловой системой
Структура и методы доступа к файлу.
(структура последовательного файла)
Предполагаем, что обмен данными между ОП и записью на УВ осуществляется специальными логическими записями. Физическая и логическая структуры различны.
при выполнении файла файловая система не делает предположений о логической структуре файла. Файлы легко создавать и обрабатывать.
Нет ограничений в структуре файловой системы
Не осуществляется никакой оптимизации. Файловая система не знает об операциях файла
Методы реализации.
Пользователь должен уметь сохранять в файл логические записи. Все логические записи в файле имеют одинаковый размер. Нет необходимости сохранять дополнительный объем информации, кроме длины записи для такого файла.
Блокирование записей – несколько записей объединяются в блок, длина блока должна быть кратной длине записи.
Записи переменной длины. Обеспечивается дополнительная информация, включающаяся в служебный файл.
Объединение записей переменной длины в блоки и разбиение одной записи на блоки.
Для второго случая указывается не только длина записи, но и длина сегмента, а в последующих частях разбиения указание на то, чьим продолжением они являются.
Метод доступа к последовательному файлу – последовательный доступ. Обрабатывать файл последовательно не всегда удобно. Обычно определяются дополнительные операции: прочитать данные из файла и установить текущую позицию на начало файла – REWIND$ иногда необходимо повторное чтение записи, BACKSPACE – возврат на одну логическую запись назад: операция, которая позволяет установить произвольное значение текущей записи – SEEK.
Способы доступа:
-Прямой доступ – может быть организован для любого файла, который состоит из записей одинаковой длины и не блокируемых. (в любом другом случае его поддержка невозможна)
- последовательный - можно получить доступ к любой записи в любом порядке, доступ осуществляется по номеру строки
- индексно – последовательный доступ – изменяет внутреннюю структуру записей. Действует только для записей, которые можно идентифицировать по значению полей. В этом случае создается специальный файл обычно то поле, которое позволяет однозначно идентифицировать запись называется первичным путем условия однозначности.
Доступы по ключу
- прямой – записи в том порядке, в котором указан ключ.
- последовательный – обрабатывает последовательность по возрастающей последовательности ключа. Вспомогательные файлы называются индексными. Индексы создаются в зависимости от количества ключей.
Индексно – последовательный файл.
Имеет ту же структуру, что и обычный последовательный файл. Длина записи варьируется. Условие – поля можно использовать для идентификации, все записи содержат идентификационные поля, они находятся в одних (от начала записи) положениях.
Существует первичный ключ – уникальная запись и несколько альтернативных записей. Доступ может быть последовательным или в виде отсортированной последовательности. Количество файлов определяется количеством записей. Каждый файл содержит упорядоченную по возрастанию последовательность полей и некоторый указатель, который помогает найти запись (н-р, смещение).
Для каждого ключа создается свой файл. Такой поиск поддерживается ОС. Это означает, что ОС создает индексные файлы и может содержать быстрые алгоритмы поиска. Иначе пользователь вынужден создавать файлы сам или с использованием языков высокого уровня, что менее эффективно.
Лекция 7.
Логическая структура файловой системы. Директории.
Все файловые системы должны:
обеспечивать создание и поддержку определенной файловой системы
поддержка механизма именования файлов (скрыть механизм сохранения данных, механизм именования файлов должен обеспечивать однозначное определение положения файлов в логике файловой системы). ,Поддерживается с помощью специальных системных файлов, которые носят название директорий = каталогов = папок = оглавлений. Содержат не менее2-х параметров:
Имя файла |
Что-нибудь |
ссылка |
file |
|
|
file1 |
|
|
|
|
|

Ссылка – содержит в зависимости от ОС разные данные по-разному организованные. Указывает, где находятся данные. С директориями работают системные программы и только они. Пользователь ограничен в доступе.
Поддерживает операции:
create dir – создание «пустой» директории, с автоматической записью двух имен:
. – имя самой директории
.. – родительская директория (если предусмотрено)
delete dir – удаляет, но только «пустую» директорию
open dir – аналогично открытию обычного файла, но обычному пользователю запрещается открывать ее для модификации
close dir – очищает системные структуры данных
read dir – чтение директории
write dir – запись в директорию
link – включить ссылку на некоторый файл
unlink – выключить ссылку
Директория – это единственный системный файл, содержащий сведении об имени файлов
Если в составе вычислительной системы имеется несколько носителей данных, то на каждом носителе организуется своя файловая система.
Одноуровневые файловые системы.
- когда требуется максимальная эффективность работы ВУ, минимальная структурированность, минимальная систематизация информации, применяется на слабой аппаратуре
не предусмотрено разграничение доступов, любому пользователю доступны все файлы. Организуется один каталог, в котором помещаются все файлы.
В такой системе возникают две главные проблемы:
- нет средств защиты от несанкционированного доступа
- имена всех файлов, находящихся на одном носителе, должны быть уникальны.
Двухуровневые файловые системы.
корневой каталог содержит записи о каталогах
каталоги пользователей содержат только информацию о файлах, и не содержат информации о каталогах
решается проблема несанкционированного доступа и дублирования имен. Эффективность реализации высокая. Как правило предусмотрена регистрация пользователя, после чего он связывается с определенным каталогом и не имеет доступа к другим каталогам, за исключение каталогов общего пользования.
Иерархические файловые системы.
В каталоги таких систем моно включать информацию о каталогах и о файлах. Обычно имеется корневой каталог. Корневой каталог не указывается ни в одном другом каталоге файловой системы. ОС предусматривает сохранение его адреса.
Получающаяся логическая структура очень сложна.
Каждому пользователю (его процессу) можно назначить текущий каталог. (кроме того, в системе постоянно сохраняется имя корневого каталога – существует постоянная связь с двумя каталогами)
Один из каталогов системы, как правило, автоматически делается текущим после ограничения процесса регистрации – он называется домашним.
Каталог, в который включен данный – родительский, включенный в данный каталог подкаталог – дочерний.
Необходимо поддерживать систему идентификации файлов.
Пользователь при создании может выбрать файлу некоторе имя и по этому имени файл будет доступен другим процессам.
Ограничение на длину имени:
- короткие имена, до 20 символов
- длинные имена, до 255 символов
При коротких именах директории представимы в виде таблиц с одинаковой, фиксированной длиной поля.
При использовании длинных имен используются записи переменной длины, содержат длину имени файлов (логически директория все равно представляется таблицей).
Особенности идентификации файлов в иерархической файловой системе.
Система полных имен файлов.
Полное имя содержит собственное имя файла + перечень всех каталогов, которые необходимо просмотреть, чтобы найти ссылку на местоположение файла (называется «имя пути»). Имя пути может быть указано двумя способами:
- от корневого каталога – абсолютное имя
- от текущего каталога – относительное имя
Правила отличия:
- если имя пути не начинается с некоторого специального символа, то имеется ввиду относительное имя.
- если использован символ-разделитель, то имеется в виду абсолютное имя файла
Имя нужно ОС для получения ссылки. Должна быть процедура преобразования имени файла в ссылку.
Пр-р: (используя абсолютное имя)
/каталог1/каталог1.1/файл 1
ОС должна в каталоге 1.1 найти запись или ссылку на файл 1.
Процедура выполняет следующие действия:
? относительное или абсолютное имя файла
берется корневой (текущий) каталог, проверяются права доступа и другое, находится имя, следующее далее в имени каталога, читается его место, затем переходит к обработке следующего каталога
Лекция 8. Модификация логической структуры файловой системы.
Сократить запись, указывающую на точное местоположение файла в системе.
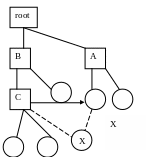
тек. каталог А – имя файла и есть ссылка на Х
тек. каталог С – необходимо задать относительный либо абсолютный путь, в некоторых случаях второй способ может быть неудобным
Использование техники связывания файлов:
Жесткая ссылка. Появилась раньше, реализуется проще. В каталог, из которого устанавливается связь, включается запись, содержащая ссылку на файл.. в одном из каталогов имя файла можно изменить, важно, что одинаковые данные содержатся в самой ссылке. Ссылки во всех каталогах равноправны, первоначального владельца невозможно установить. Необходимо создать счетчик числа ссылок, чтобы предотвратить физическое удаление файла при удалении одной из ссылок. Оно происходит только при счетчике, равном 0.
Недостаток: невозможно отличить ссылку, созданную при создании файла от остальных. Н-р, нельзя создать жесткую ссылку на каталог, см. рисунок - в С жесткая ссылка на В – получаем зацикливание, которое невозможно найти - жесткие ссылки на каталоги запрещены.
Символические (мягкие) ссылки. Представляют собой файл специального вида, содержащий имя файла в другом каталоге, на который создается ссылка. Вместо такого спец. Файла открывается файл другого каталога. При удалении ссылки удаляется только ссылка, а не файл. Можно таким образом создать сетевую ссылку. Можно создать ссылку такого вида на каталог, поставив ограничение на чтение файла-ссылки.
Монтирование файловых систем:
На любом физическом или логическом устройстве организуется новая файловая система.
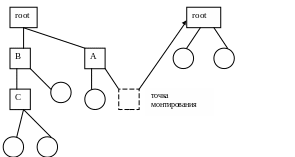
переход от одной файловой системы к другой: ОС должна знать характеристику устройств и их файловых систем. Монтирование файловой системы позволяет логически объединить несколько файловых систем.
Существует два способа монтирования:
-автоматическое
-в ручную
Автоматическое – при первом обнаружении устройства (при загрузке, н-р, для ЖД, для съемных в момент подключения). В этом случае таблица монтирования имеет вид:
Имя устройства |
Ссылка на корневой каталог |
А |
Каталог1 |
В |
Каталог2 |
|
|
ОС просматривает таблиц монтирования, находит ссылку на корневой каталог и от него начинает поиск
Логическая структура:
такое монтирование происходит в MS-DOS, Windows
Монтирование в ручную - все файловые системы на логических устройствах образуют одну логическую структуру и логическую иерархию
Maunt – выполнить монтирование
Unmaunt – выполнить размонтирование ФС.
После завершения системы загрузки корневая ФС доступна пользователю. Для монтирования следует выбрать каталог, желательно пустой, для начала монтирования – он называется точка монтирования. (см. рисунок). Т.о. необходимо указать точку монтирования и монтируемое устройство. Требуется модификация системы навигации
Таблица монтирования (в ручную).
Ссылка на точку монтирования |
Ссылка на устройство |
Ссылка на положение каталога монтирования файловой системы |
|
|
(Ф.С. – ссылка на буфер с описанием монтируемой Ф.С.) |
Как осуществляется поиск файла.
ФС доходит до каталога, который является точкой монтирования и в пределах данной ФС. является пустым. В этот момент проверяется таблица монтирования, и имя каталога заменяется именем корневого каталога устройства. Либо указать какую-то пометку для точки монтирования и никогда этот каталог не читать. Если путь задается в обратном направлении, то в момент, когда дошли до корневого каталога устройства и попытались обратиться к его родительскому, процедура именования обращается к таблице монтирования.
Защита и права доступа.
Один из способов реализации прав доступа – с файлом ассоциируется список, называемый списком контроля доступа, который содержит информацию о пользователе и правах доступа такого пользователя к файлу.
Три вида действий:
- читать данный файл r
- писать в файл w
- запускать файл на выполнение x
если имени пользователя нет в файле-списке прав доступа, то никаких прав доступа к файлу нет.
При этом все процедуры, запущенные пользователем, должны содержать идентификатор пользователя. Схема требует больших затрат, так как число пользователей может быть очень большим.
Модификация (Unix):
пользователь
-группа пользователя
остальные
для хранения этих данных необходимо выделить место, обычно вместе с остальной информацией, группа носит название атрибута файлового доступа.
Типы файлов.
При выполнении любой процедуры обычно определяется тип файла для корректной работы.
Файлы:
регулярные
- системные
директории
файл-ссылка
необходимо сохранять информацию о типе файлов. Иногда необходимы дополнительные сведения – когда файл был создан, модифицирован, и т.д.
ФС обычно производит регистрацию. Все характеристики называют атрибутами файла.
ФС хранит атрибуты по-разному, но обычно в директориях или структурах данных, либо распределяется.
Интерфейс файловой системы.
ФС- совокупность системных программ, системных данных и данных пользователя.
ФС должна обеспечивать интерфейс для обработки и сохранения данных.
Компоненты:
интерфейс системных вызовов (написать программу, который позволяет получить доступ к файлу).
Предоставить пользователю набор команд (который обращается к системным вызовам).
Реализация ФС.
Абстрактная модель данных реализуется для любых устройств, которые могут быть источниками или приемниками данных. Устройства делят на символьные и блочные (считается, что все блоки имеют одинаковый размер, наименьшая порция данных, которую можно в этом случае прочитать – физический блок. Пр-р: НЖМД).

зона, которая может быть прочитана при фиксированном положении блока – дорожка, а все дорожки, прочитанные всеми головками – цилиндр. Дорожка разбита на сектора. Сектор соответствует физическому блоку, обычно 512 байт. Происходит нумерование головок, дорожек цилиндров, фиксированных положений головок. Получившийся уникальный номер – линейный адрес. Для сокращения числа обращений к диску – логическое объединение нескольких блоков.
Логический блок – имеет фиксированную длину, кратную физическому блоку.
Лекция 9.
Абстрактная модель данных реализуется для любых устройств, которые могут быть источниками или приемниками данных. Устройства делят на символьные и блочные (считается, что все блоки имеют одинаковый размер, наименьшая порция данных, которую можно в этом случае прочитать – физический блок. Пр-р: НЖМД, зона, которая может быть прочитана при фиксированном положении блока – дорожка, а все дорожки, прочитанные всеми головками – цилиндр. Дорожка разбита на сектора. Сектор соответствует физическому блоку, обычно 512 байт. Происходит нумерование головок, дорожек цилиндров, фиксированных положений головок. Получившийся уникальный номер – линейный адрес. Для сокращения числа обращений к диску – логическое объединение нескольких блоков.
Логический блок – имеет фиксированную длину, кратную физическому блоку.
ФС должна хранить связь именованного файла с дисковыми блоками, адреса занятых блоков, адреса свободных блоков, текущая позиция в файле, режим доступа к файлу, атрибуты файла. ОС могут поддерживать несколько ФС, существенно различных. Данные могут храниться на носителе данных или в памяти.
Структуры в памяти:
директории – связь имени файлов и дисковых блоков.
таблица открытых файлов- ФС сохраняет сведения об открытых файлах
Таблица открытых файлов
Текущая позиция файла |
Режим доступа (определяется при открытии файла, соответствует правам доступа) |
Ссылка на местоположение данных (существенно зависит от реализации ФС) |
Некий счетчик системы |
|
Rwx |
|
|
Запись заносится при выполнении системного вызова open, из которого и берутся соответствующие параметры.
Каждый такой вызов создает новую запись в таблице вызовов. Размер таблицы ограничен, а поэтому ограничено и количество одновременно открываемых файлов. Таблица открытых файлов одна для всей ФС.
Вспомогательная таблица – таблица дескрипторов.
Таблица дескрипторов.
Порядковый номер |
Адрес записи в таблице открытых файлов |
0 |
ввода |
1 |
вывода |
2 |
Стандартного протокола |
Заполняется системным вызовом open/ общепринято, что для каждого нового процесса создается своя таблица дескрипторов и всегда передается три дескриптора (см. выше).
Счетчик табл. открытых файлов используется, когда разные процессы обращаются к одной и той же записи в табл. открытых файлов. (данные носят временный характер)
ФС имеет склонность копировать в ОП некоторые блоки.
Общая структура подсистемы управления файлов.

Методы выделения дискового пространства.
Подходы:
пространство на диске выделяется непрерывной последовательностью блоков
Преимущества: для определения, какие блоки принадлежат файлу, достаточно записать адрес первого блока и размер файла, что сохраняется в директории. Адрес первого блока – ссылка на данные. Повышается производительность. Однако, когда в результате удаления файлов остается свободная область памяти и в нее записывается новый файл, может остаться несколько свободных блоков, размер которых недостаточен для записи какого-либо файла – т.е. происходит фрагментация. Если мы неправильно указали размер файла, то такой файл использоваться не может, и поэтому файл неизменяем.
Выход: разрешить дописывать к фалу непрерывные блоки. Для каждой области в директории указывается свое распределение. Фрагментация при этом усиливается..
выделение памяти кусками, наименьший из которых – блок.
Должны быть запомнены адреса всех блоков данного файла.
А) создание связанных файлов (в реальности не существует)
имя |
… |
Адрес первого блока |
|
|
Данные + указатель |
В последнем блоке нет указателя.
Ссылка = адрес первого блока
Недостатки: обращение к блокам – только последовательно, ненадежная система – ссылка теряется при возникновении сбойного блока, увеличивается размер блока, он становится некратным 2.
Б) связанный список с использованием индекса
Информация о положении блоков хранится во вспомогательной индексной таблице – File Allocation Table (FAT) .
|
|
|
|
|
|
|
|
|
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
… |
|
Количество ячеек – по количеству дисковых блоков. Во второй ячейке – адрес следующего дискового блока. Вместо адреса для пустого файла записывается специальный код. (Используется MS-DOS, Windows).
Проблема – может быть потеряна индексная таблица. Кроме того, индексная таблица должна практически полностью размещаться в памяти.
В) для хранения информации в системе организуется специальная структура данных – индексный узел ( i -note). Для каждого файла организуется свой i –note. Все i –note объединяются в таблицу. В директории указывается номер индексного узла (№ строки в таблице). Ссылки – номер i –note.
Структура i –note.
Индексный узел может иметь фиксированный размер, но должен хранить информацию о всех блоках файла.
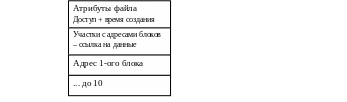
вместо адреса непосредственно блока с данными может храниться адрес, указывающий остальные ссылки на блоки с данными – косвенная адресация.
- м.б. использована двойная косвенная адресация
адрес -> адрес блоков -> блок с данными
- тройная косвенная адресация
Пр-р: адрес – 32 бита (4 байта), размер логического блока – 1 Кб (1024 бита). Какое адресное пространство можно адресовать с помощью 34-байтного индексного узла?
Прямая адресация – 10Кб.
Косвенная – 1024/4= 256 адресов с блоками данных – 256 КБ
Двойная косвенная – 256*256=64МБ
Тройная косвенная – 10 ГБ.
Ни один процесс не хранит информации о блоках файла. Чтение/запись на диск производит файловая система: преобразует текущую позицию в адрес блока и смещение от начала блока. Упрощается таблица размещения файлов..
Таблица размещения файлов – узнать, куда входит текущее смещение по таблице открытых файлов, поделив смещение на размер блока, смещение внутри блока – остаток от деления.
Индексная таблица.
Пр-р:
Размер логического блока 1024
Тек позиция 90000
9000-1024*8=808 – смещение внутри 9-ого блока
350000 – очевидно, не прямая адресация
10=1054002565 байт
1=256Кб=262144Б
272384 б.
350000-272304=77616
каждый блок прямой адресации – 1024
77161/1024=75
т.е. 76 блок адресации
76616-75*1024=816
Лекция 10.
Ни один процесс не хранит информации о блоках файла. Чтение/запись на диск производит файловая система: преобразует текущую позицию в адрес блока и смещение от начала блока. Упрощается таблица размещения файлов..
Таблица размещения файлов – узнать, куда входит текущее смещение по таблице открытых файлов, поделив смещение на размер блока, смещение внутри блока – остаток от деления.
Индексная таблица.
Пр-р:
Размер логического блока 1024
Тек позиция 90000
9000-1024*8=808 – смещение внутри 9-ого блока
350000 – очевидно, не прямая адресация
10=1054002565 байт
1=256Кб=262144Б
272384 б.
350000-272304=77616
каждый блок прямой адресации – 1024
77161/1024=75
т.е. 76 блок адресации
76616-75*1024=816
Управление свободным дисковым пространством.
Существует две основные стратегии учета:
учет свободных дисковых блоков с помощью битовой карты
выделяется область памяти – битовая карта, соответственно, если устанавливаем бит в 0, блок свободен, в 1 – блок занят.
Достоинство – при организации нового файла можем найти последовательность нулей соответствующего размера и выделить подряд идущие блоки. Недостаток – с ней можно эффективно работать, только если она размещается в памяти целиком.
Учет при помощи организации связанного списка свободных блоков
на диске выделено место, которое хранит адрес первого свободного дискового блока
недостаток – чтобы получить несколько свободных блоков, надо каждый раз обращаться к диску для чтения адреса следующего свободного блока. Усовершенствование – в один из свободных блоков помещается несколько адресов свободных блоков. Последний адрес позволяет перейти по списку к следующему свободному специальному блоку. При этом добавляется специальный счетчик, который указывает на начало списка и увеличивается, когда блок используется под запись. Когда счетчик показывает, что все адреса в этом специальном свободном блоке использованы, происходит переход к следующему блоку. При этом в памяти хранится только адрес текущего блока.
Размер логического блока.
Чем больше размер логического блока, тем менее громоздки вспомогательные системы данных, но так как место под файл выделяется целыми блоками, будет теряться существенная часть дискового блока, кроме того, много файлов меньше логического блока – возникает внутренняя фрагментация.
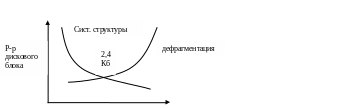
Распределение дискового пространства.
Системная область |
Область данных |
|
Загрузочный сектор |
Служебные структуры данных ФС |
|
|
|
|
ФС делит диск на несколько частей. Загрузочный сектор – располагается на диске в зафиксированной области памяти. Содержимое считывается программой загрузки, иногда добавляются данные о расположении файлов и т.д.
Для ОС Unix служебная область содержит:
суперблок – сохранение информации о ФС в целом – н-р, имя ФС.
- указывается размер логического блока
- размер файловой системы в целом
- размер таблицы индексных узлов
и т.д. Этот блок ограничен – число файлов на диске так же ограниченно.
- битовая карта либо один блок из списка свободных блоков, сохраняются соответствующие счетчики.
- список свободных индексов и список свободных счетчиков
таблица индексов (размер фиксирован)
При использовании табл. размещения файлов, она включается в систему загрузки, хранится размер системы размещения файлов. Существует несколько копий этих файлов. Служебная область содержит таблицу таймингов и корневой каталог диска. Корневой каталог может содержать ограниченное число файлов.
Реализация директорий.
(директория – это файл, имеющий определенный системный формат)
Директория хранит ссылки на файлы.
В MS-DOS директория организуется следующим образом: таблица размещении файлов должна быть целиком помещена в ОС.ОС организуется так, чтобы она могла получить доступ к любому файлу. Логически директория – таблица с записями.
Запись
имя |
расширение |
атрибут |
Не используется |
Время создания файла |
Дата создания |
Номер первого блока |
размещение |
8 байт |
3 |
1 |
10 |
2 |
2 |
2 |
4 |
FAT 2^16 – максимальная нумерация файлов
FAT 12 – адрес до 2х Мб.
FAT16
FAT32 – длина адреса – 28 бит
Рассчитана на работу с директориями. Для выделения большего места под имя необходимо как-то увеличить размер соответствующего поля.
Директории в Windows: система длинных имен и поддержка FAT32в структуру директории включается указатель на длинное имя. Оставляется так же запись для совместимости с MS-DOS, образующаяся по внутренним правилам.
1 Мб – совместимость с Windows NT.
1 Мб – контрольная сумма для длинных имен
в 10 байт записывается:
4б - дата создания
2б – дата последнего доступа
2б – старшие биты № начального блока
используется 10-разрядная адресация
Дополнительные записи для хранения длинного имен:
поля атрибутов – указывают на заведомо неправильную комбинацию символов в дополнительных записях, которые предшествовали описанию положения файла и нумеровались.
MS-DOS не знает о дополнительных записях в директориях, Для обеспечения совместимости MS-DOS и Windows каждому файлу присваивается два имени – длинное и короткое. Проблема: MS-DOS – не должна размещать на не удаленные длинные имена новые файлы – чтобы такого не произошло используются контрольные суммы.
Директории Unix: имеют простую структуру, вся дополнительная информация – в индексах.
имя |
Номер индекса |
|
|
Сохраняются сведения о длине длинных имен.
Лекция 11.
Надежность файловой системы:
Выделяют два вида сбоев:
Жесткие сбои – связанные с радикальной поломкой оборудования.
Мягкие сбои – возникают при внезапном отключении питания.
Жесткие сбои.
Единственный способ восстановления ФС – из резервной копии на другом носителе. Разработчики ФС создают средства, которые обеспечивают создание копий и напоминать о создании копий пользователю.
Мягкие сбои.
Нарушение данных ФС, носитель с данными остается неповрежденным, но данные могут быть потеряны. Для обнаружения сбоев существует понятие – целостность файловой системы – подразумевает непротиворечивость хранящихся в ней данных. Атомарность – неделимость. В ФС существуют атомарные операции, прерывание которых влечет нарушение целостности системы в результате потери данных в ОП. Целостность подразумевает целостность системных данных и данных пользователя. Однако, разработчики заботятся о целостности служебных данных.
Пр-р: блоки из файла удалены, но не добавлены в блок свободной памяти не включены – потерянные блоки.
Пр-р: в файл размещаются данные, блок уже занят, но не исключен из списка свободных блоков.
Средства:
- позволяющие уменьшить возможный вред при потере данных – включается на этапе разработки
- позволяющие восстановить целостность ФС (при повреждении данных пользователем либо при некорректном выключении самой ОС)
-предотвращающие повреждения
1 группа – выбирается рациональный порядок действий
Пр-р: создание жесткой ссылки: необходимо создать запись в каталоге, указывающую на i-узел, а в узле изменить число ссылок. Следует сначала изменить счетчик, так как в случае ошибки пользователь заметит нехватку ссылки в каталоге, а иначе при удалении одной из ссылок файл был бы потерян. Однако в этом случае даже при удалении всех ссылок файл не удалится, а значит будет потеряно дисковое место, но не информация.
2 группа – scan disk или file system check
Непротиворечивость блоков с данными – fsck
создается таблица
Адрес или номер блока |
Ставится счетчик, если блок занят |
Ставится счетчик, если блок свободен |
|
|
|
Сканируются i-узлы. В этой таблице любой блок может встретиться ровно один раз в двух последних столбцах. Если в обоих столбцах напротив бока стоит ноль, то это потерянный блок, включается в список свободных, если в обоих по единице – исключается из списка свободных, если блок занят 2-мя файлами, то непонятно, какую информацию он в итоге содержит, он копируется в свободный блок, и по одной из ссылок записывается адрес этого нового блока.
Проверка целостности каталогов:
Корректируется таблица индексов и существующее число ссылок. Приводится в соответствие с количеством ссылок. Если файл не включен ни в один каталог, его место освобождается.
3 группа – сделать файловые операции неделимыми.
Любая операция – транзакция, и либо выполняется полностью, либо не выполняется вообще. Н-р, применяется занесение действий в журнал (журналируемые ОС) транзакций. При сбое происходит откат.
Все эти действия снижают эффективность данной системы.
Производительность ФС:
Определяется длительностью дисковых операций, на что не могут повлиять разработчики ОС. Т. о. стремятся уменьшить число дисковых операций с помощью их удачного расположения а так же с помощью кэширования дисковых блоков.
Рассмотрим методы модификации алгоритмов чтения – записи.
Кэширование блоков.
В ОП создается буферный КЭШ. Предусматриваются буферы различной емкости. Можно записывать индексные файлы. Сохраняется первый элемент связанных блоков и индекс блоков. Если происходит обращение к блоку, проверяется, есть ли блок в буфере, а затем ищется на диске. Проблема: накапливаются различия в информации- необходимо обеспечить доступ в две стороны и обмен. Вторая проблема – ограниченность памяти.
Кэширование со сквозной записью (MS-DOS) –данные моментально записываются в постоянную память.
Структура буферного КЭШа в ОС Unix:
Любой буфер состоит из двух частей:
- заголовочной
- области данных
в памяти могут располагаться в разных местах.
Область данных совпадает по размерам с дисковым блоком, заголовок состоит из нескольких полей для определения:
- номер устройства
- номер блока=адрес блока (идентифицируется по номеру устройства)
- указатель текущего состояния – заблокирован (занят, т.к. с ним работают ОС или непосредственно процессор) или доступен – определяется по флагу
- флаг, указывающий на то, произошли ли изменения данных в блоке и тебуется ли его перезапись
- путь к соответствующему блоку
- ФС поддерживает в рамках ОС буфера КЭШ структуры
- поддерживает ХЭШ - очередь
- указатели на следующий и предыдущий буферы
ХЭШ – очередь создается в виде таблицы. Эта таблица состоит из массива, каждый элемент которого может содержать несколько ключей, определение идет по индексу
Список свободных буферов:
Каждый буфер, который не занят вводом/выводом, должен находиться в списке свободных буферов. Ос обращается к этому списку и забирает первый немодифицированный блок. После освобождения блока, он возвращается в список буферов, если ошибок не было, блок включается в конец списка, иначе - в начало. В буферном ХЭШе хранятся как системные, так и пользовательские данные, но сохраняются по-разному. Для быстрого доступа к буферам организуется ХЭШ – таблица.
В любых данных выделяется поле – ключ. Поиск организуется по ключу. Данные представляются массивом, в котором порядковый номер данных совпадает с ключом: индекс=ключ. Возникает проблема: массив не может быть слишком большим, а диапазон значений требуемых ключей существенно больше индексов. Или наоборот, набор используемых ключей оказывается существенно меньше определяемого массивом диапазона. Т.о. массив индексов берется небольшой, а массив ключей отображается на реальное значение индексов. Значение ключа приводится к диапазону индексов целочисленным делением. Но в этом случае несколько ключей попадают на один элемент массива. В ХЭШ- табл. С элементом массива сопоставляется список элементов с разным значением ключа для одного индекса.
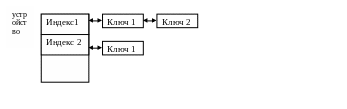
стараются, чтобы ХЭШ – очереди, в которых придется выполнять линейный поиск, были небольшие. ХЭШ – функция или функция хэширования должна как можно более случайно сопоставлять ключ и индекс.
В ХЭШ – функцию необходимо передать номер устройства и номер блока.
Этапы:
- вычисляется ХЭШ – функция
- вычисляется индекс
- осуществляется линейный поиск
список свободных буферов и ХЭШ – таблица накладываются друг на друга, список свободных блоков переписывается в ХЭШ – таблице, однако в ней не отображаются неоднозначно свободные блоки.
Хранение индексов:
Дисковый блок занят только на момент ввода/вывода, остальное время свободен и доступен другим приложениям.
Для хранения индексов организуется ХЭШ - таблица свободных блоков и таблица свободных индексов.
Индекс свободен только когда завершены все процессы, которые с ним связаны, что накладывает ограничение на общее число открытых файлов.
Организация работы ядра ОС с буферным КЭШем. Если ядро обращается за поиском блока, оно обрпfoftncz к ХЭШ – таблице. Если в данный момент блок свободен, не блокирован другой процедурой, то ядру немедленно предоставляется блок. Если же блок занят, то новый процесс приостанавливается (редактирование и перезапись). Если происходит обращение к блоку, которого нет в таблице блоков, то выделяется свободный буфер и в него считывается информация с диска. Если список свободных буферов пуст, процесс приостанавливается.
Лекция 12.
Ратификация алгоритма дисковых блоков.
Алгоритм отложенной записи
Модификация буфера не вызывает немедленной перезаписи буфера. Алгоритм работает по-разному с пользовательскими данными и системным данными. Для последних перезапись обычно производится быстро. Для пользовательских данных возникает проблема: начинают существовать отличия в соответственных блоках ОП и блоках ЖД. В некоторых ОС этот алгоритм не используется, и перезапись происходит мгновенно. Пр-р MS-DOS – КЭШ со сквозной записью. Обычно специальные команды не дают напрямую записывать данные в буфер, а предварительно обрабатывают.
Модификация алгоритма чтения.
Сокращение дисковых операций с использованием опережающего чтения блоков. Вместе с текущим блоком из файла считывается еще несколько блоков. Хорошо действует если п прямой доступ к файлу, в противном случае может не повысить, а существенно снизить производительность ФС: необоснованно тратится время, занимаются свободные буферы, бессмысленные перезаписи на диск и наконец, в скором времени системе могут понадобиться новые данные и системе придется снова их считывать. Поэтому проводится статистика текущих вызовов SEEK – перейти на новую текущую позицию.
Оптимизация перемещения блока головок.
Большой промежуток времени тратится на перемещение головок между цилиндрами.
Первый подход. При размещении данных на ЖД ФС старается записать все данные на один цилиндр (Windows).
Второй
подход. При организации ФС, данные
располагаются наиболее оптимально.
Отдельно сохраняются пользовательские
и системные данные. При размещении
системных данных в центре диска время
доступа к ним уменьшается.
Реализация некоторых файловых операций в ОС Unix:
вся дальнейшая работа инициализируется без дисков.
операция открытии файлов Open – системный вызов, его параметры:, полное имя файла, режим открытия для чтения, записи, чтения/записи. Алгоритм: 1) преобразование полного имени файла в номер индекса, просматриваются все соответствующие директории с проверкой прав доступа, из последней извлекается запись с соответствующим именем и индексом;
обращается к таблице вызовов в КЭШе и ищет индекс, если находит, то просто увеличивает счетчик. Иначе системный вызов по номеру индекса обращается к таблице индексов и копирует индеек для существующего файла. Если файл не существует и индекс неоткуда копировать индекс, то если указано, что файл может быть создан, то находится свободный индекс, заполняет даны, вносит данные о файле в директорию, вносит данные на диск.
Заполняется отдельная(!) строка таблицы открытых файлов. Число ссылок устанавливается 1, текущая позиция обычно 0, режим доступа копируется из директории, указывается ссылка на индекс.
память
Заполнение таблицы дескрипторов.
Адрес элемента таблицы открытых файлов |
Возврат номера соответствующего дескриптора |
|
|
Лекция 13.
После системного вызова open возвращается дескриптор, с которым и продолжает работать операционная система.
Системные вызовы:
- read (дескриптор, буфер размещения данных с диска, размер)
ФС обрабатывает его следующим образом
по дескриптору определят элемент таблицы открытых файлов
соответствие режима доступа и операции «чтение».
Из таблицы открытых файлов выбирается значение позиции текущего файла и ссылка на индексный узел
Преобразование текущей позиции и индексный узел в адрес дискового блока и положение в нем
В ХЭШ – таблице ищется соответствующий дисковый блок, если такой блок находится, то соответствующее количество байт читается с соответствующей позиции.
Может оказаться, что количество данных меньше указанного размера. В этом случае читается столько, сколько есть. При этом read возвращает количество реально прочитанных байт
если в ХЭШ – таблице блок не найден, тогда из списка свободных буферов выбирается один, в него записываются данные из логического блока. сли данные длиннее, то считывается и несколько последующих блоков.
После этого происходит смещение на реальное количество бай
- write (дескриптор, буфер, размер)
по дескриптору обращается к таблице открытых файлов .
проверяются права доступа
из таблицы получает i-узел и текущую позицию, из них вычисляет блок и позицию в блоке
если блок присутствует в ХЭШ – таблице, то на выходе получаем его адрес
если это конец файла и свободного блока нет, то перезаписываем в конец следующим образом: из списка свободных буферов выбираем один, включаем его в ХЭШ – таблицу;
происходит запись с заданного значения
текущая позиция увеличивается на число реально прочитанных байт
- close (дескриптор) – системный вызов закрытия файла
по дескриптору определяем номер в таблице открытых файлов
если больше нет ссылок на этот файл, то сканируется, есть ли еще его блоки в ХЭШ – таблице, они переписываются на диск
Счетчик в таблице открытых файлов: индекс всегда один, а ссылок может быть несколько. Иногда может понадобится использовать две копии файла, дается возможность к одному и тому же файлу присоединить два дескриптора к одной строке в таблице открытых файлов. Используется при переключении системного ввода/вывода. Счетчик считает количество дескрипторов на одну строку таблицы открытых файлов. Нужно для открытия/закрытия файлов ввода/вывода. Н-р, после закрытия файла, получили новый файл стандартного вывода
Лекция 14.
После системного вызова щpen возвращается дескриптор, с которым и продолжает работать операционная система.
Системные вызовы:
- read (дескриптор, буфер размещения данных с диска, размер)
ФС обрабатывает его следующим образом
по дескриптору определят элемент таблицы открытых файлов
соответствие режима доступа и операции «чтение».
Из таблицы открытых файлов выбирается значение позиции текущего файла и ссылка на индексный узел
Преобразование текущей позиции и индексный узел в адрес дискового блока и положение в нем
В ХЭШ – таблице ищется соответствующий дисковый блок, если такой блок находится, то соответствующее количество байт читается с соответствующей позиции.
Может оказаться, что количество данных меньше указанного размера. В этом случае читается столько, сколько есть. При этом read возвращает количество реально прочитанных байт
если в ХЭШ – таблице блок не найден, тогда из списка свободных буферов выбирается один, в него записываются данные из логического блока. сли данные длиннее, то считывается и несколько последующих блоков.
После этого происходит смещение на реальное количество бай
- write (дескриптор, буфер, размер)
по дескриптору обращается к таблице открытых файлов .
проверяются права доступа
из таблицы получает i-узел и текущую позицию, из них вычисляет блок и позицию в блоке
если блок присутствует в ХЭШ – таблице, то на выходе получаем его адрес
если это конец файла и свободного блока нет, то перезаписываем в конец следующим образом: из списка свободных буферов выбираем один, включаем его в ХЭШ – таблицу;
происходит запись с заданного значения
текущая позиция увеличивается на число реально прочитанных байт
- close (дескриптор) – системный вызов закрытия файла
по дескриптору определяем номер в таблице открытых файлов
если больше нет ссылок на этот файл, то сканируется, есть ли еще его блоки в ХЭШ – таблице, они переписываются на диск
Счетчик в таблице открытых файлов: индекс всегда один, а ссылок может быть несколько. Иногда может понадобится использовать две копии файла, дается возможность к одному и тому же файлу присоединить два дескриптора к одной строке в таблице открытых файлов. Используется при переключении системного ввода/вывода. Счетчик считает количество дескрипторов на одну строку таблицы открытых файлов. Нужно для открытия/закрытия файлов ввода/вывода. Н-р, после закрытия файла, получили новый файл стандартного вывода
Процессы.
Если система мультипрограммная, то в память должно размещаться одновременно несколько процессов.
Процесс – программа на стадии выполнения + выделенные ей ресурсы. (На самом деле прямого соответствия нет. Для одной программы может быть выполнено несколько процессов или в одном процессе может выполняться несколько программ.
Поочередно работают в ОС и пользовательские процессы. Они реализуют абстрактное понятие интерфейса. ОС для этого должна характеризовать множество процессов и определять набор данных процесса, а так же распределять между ними ресурсы. Главный ресурс – это время процесса.
Должны быть определены операции над процессом:
используется концепция состояния процесса, в рамках которой предполагается с помощью фиксированных значений, фиксированных состояний описать, как проходит процесс при выполнении
для выполнения: любая программа может выполняться или быть приостановлена, из чего возникают соответствующие два состояния процесса !) выполняется, 2) приостановлен.

Принципы приостановки
ОС
насильственно отбирает процессор у
процесса и переключает управление. Если
процесс сделал системный вызов, требуется
его завершение для перевода процесса
в состояние готов.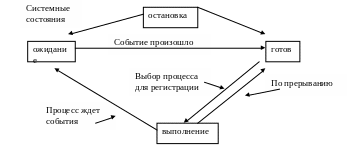
При выборе нового процесса на выполнение ОС учитывает процессы, которые попадают в состояние готов, при этом учитывая некоторые собственные характеристики процесса, такие как приоритет. Для приостановленных процессов ОС сохраняет системные прерывания. После завершения процесса необходимо очистить соответствующую строку в таблице.
Процедура swapping позволяет удалить процесс из ОП, сохранив его на диск. Приходится разделить процессы, ожидающие в памяти и на диске.. Т.о. если требуемое событие произошло, то для процесса определяется состояние 1) готов в памяти или 2) готов на диске. Состояние выполняется так же подразделяется на два: 1) выполняется в режиме ядра и 2) выполняется в режиме пользователя.
Лекция 15.
Состояния процесса помогают описать жизненный цикл процесса.
Блок управления процессом.
ОС должна хранить сведения о процессе, достаточно полные для работы системы.
PCB – Process Control Block – блок управления , включающий в себя данные о процессах. Т.е. это такое подмножество данных, которое регулирует процессы и должно быть доступно ОС независимо от того, в каком состоянии пргоцесс пребывает.
PCB включает в себя:
Таблица процессов.
Каждому процессу соответствует запись с данными для ядра ОС для постоянного доступа.
Остальные данные требуются ОС если процесс находится в состоянии выполнения. В области памяти, размещаемой в области памяти ядра для всех выполняемых процессов выделяется пространство процесса.
Таблица процессов содержит сведения, идентифицирующие процесс, в частности сведения, которые изменяются асинхронно, например, процесс остановлен, а сведения изменяются.
Для любого процесса ОС создает PIO – Process Identifier – идентификатор, целое число, генерируемое ядром при создании процесса. Он обязательно сохраняется в таблице. В зависимости от реализации ОС процессор может сохранять другие данные, такие как:
- Parent PID – идентификатор родительского процесса
- идентификаторы пользователя, запустившего процесс
- указание текущего состояния процесса
- параметры, которые позволяют ядру выбрать, какой процесс будет запущен после освобождения процессора – параметры планирования
- счетчики сигналов, посланных ОС и не обработанных. На каждый сигнал свой счетчик
- если процесс чего-то ожидает, то в таблице процессов сохраняется соответствующий дескриптор, который указывает на изменения
Для пространства процесса:
- сведения о выделенной для выполнения программы памяти
- таблица дескрипторов открытых файлов (не доступна напрямую процессу)
Работа с файлами
- информация о правах доступа , по умолчанию для создаваемого файла используется маска
-сохраняются ссылки на текущий каталог и на корневой каталог (на корневой каталог текущего устройства)
-поле возвращаемого значения для системного вызова
- поле записи ошибок системного вызова
- вспомогательные данные (завися от реализации, например, таймеры)
- использованное время процессора
-другое
Для обработки сигналов поступивших процессу, ОС испозует конструкцию, содержащую адреса обработчиков сигналов
Так как процесс должен переходить из одного состояния в другое и более соответственно не выполняться, то ОС должна сохранять данные, по которым можно восстановить работу с процессом – контекст процесса
Контекст процесса:
Содержит множество данных, которые позволяют охарактеризовать работу процесса
Его разновидности:
- регистровый контекст – сохранение текущего состояния процесса: счетчик команд, слово состояния процесса, РОН, указатель вершины текущего стека, необходимых при сохранении и восстановлении состояния процесса
Хранение данных о реализации процессов и другого органиуется в виде стека.

Место под хранение этой информации выделяется в пространстве процесса
Системный контекст процесса:
-запись в таблице процессов, пространство процесса, пользовательский дескриптор и т.д.
-содержимое стека и ядра
-системная часть для регистрации
Пользовательский контекст процесса
- полная характеристика программы-текущее состояние области кода, стека, данных, различных выделенных специально для процесса областей памяти
Основные операции (соответствуют переходам между состояниями процесса)
-создание и завершение процесса
-блокирование и разблокирование (состояние ожидания – состояние гоов
- выгрузка на диск –загрузка в память (swapping –загрузка: 0готов на диске –готов в памяти; выгрузка: ожидается в памяти – ожидается на диске)
Операции делятся на одноразовые и многоразовые.
К одноразовым относятся создание и завершение.
Создание будет произведено:
инициализация системs;о создания процесса
- высокоприоритетные –взаимодействия с пользователем
- фоновые или daemon - функции
выполнение системным процессом системного вызова, приводящего к созданию процесса
запрос пользователя на создание процесса (создается процессом оболочкам)
процесс, инициализирующий создание процесса – родительский. Созданный процесс – дочерний, процесс-ребенок.
ОС может сохранять или не сохранять, какой процесс каким создан. Первый процесс запускается при инициализации системы. Возможно построить генеалогическое дерево процессов. Если при инициализации ОС запускается множество процессов, то можно построить генеалогический лес.
При создании процесса ОС
- вырабатывает уникальный идентификатор процесса
-выделяет процессу ресурсы
Существуют следующие варианты
- дочерний процесс получает ресурсы за счет родительского процесса – существеннее ограничение числа порождаемых процессов
- процесс-ребенок получает ресурсы непосредственно от ОС
В любом случае, запись в таблице процессов так же является ограниченным ресурсом
-подготавливает область памяти
В области памяти загружается информация: данные, стек, код.
- устанавливает начальное значение программного счетчика (формируется регистровый контекст)
Далее процесс переходит в состояние готов
Существуeт два подхода заполнения областей памяти: путем копирования соответствующих областей родительского процесса, то есть создается точная копия настоящего процесса, кроме IP или происходит чтение из файла данных для загрузи, имя файла указано в системном вызове. ОС Unix – полное копирование родительского процесса ОС Windows – только вторым способом, данные считываются из файла с исполняемым кодом.
При создании процесса ему выделяются ресурсы.
Завершение процесса:
При завершении процесса требуется освободить ресурсы.
Завершение инициализруется, если
- выполнена последняя команда
-выход в связи с обработанной в программе ошибкой
-выход по неисправимой ошибке
-процесс уничтожен другим процессом
Освобождаются выделенные ресурсы, а именно области памяти, пространство процесса, запись в таблице процессов.
Если система поддерживает регистрацию родительских отношений процессов, то часто используется код завершения процесса, что помогает родительскому процессу провести диагностику дочерних процессов, иногда указываеся, что родительский процесс не заинтересован в коде завершения дочернего процесса, требуется, однако, указывать это явно. Иначе сведения о коде завершения сохраняются как запись в таблице процессов. Процесс считается полностью завершенным только после удаления записи из таблицы. Процесс, от которого осталась только такая запись с кодом завершения называется зомби. Прекращают работу такие процессы либо когда родительский процесс спросил код завершения, либо когда сам был завершен.
Многоразовые операции – выполняются неоднократно,не связаны с выделением памяти.
Выбор на выполнение – планирование процессов (переход состояний готов-выполняется)
Блокирование процесса – когда процесс не может продолжать работу, выполняется с помощью специального системного вызова.
Разблокирование – после того, как произошло требуемое событие, находится из таблицы по дескриптору.
Выгрузка процесса – копирование на диск содержимого областей памяти – ожидание на диске (выгружается пользовательский контекст).
Загрузка – просматриваются процессы в состоянии «готов на диске», выделяется тот, который можно разместить в освободившуюся часть ОП.
Процессы в ОС Unix
9 состояний процесса:
-выполнение
-готовность
-ожидание
-создание
-завершение
-ожидание на диске
-готовность на диске
+ выполняется:
-выполняется в режиме ядра
-выполняется в режиме задачи
Переход только из «выполняется в режиме ядра» в «выполняется в режиме задачи», по окончанию опять возвращается в режим ядр, из которого может перейти в состояние «готов» или «ожидается».
Поддержка сигналов.
В таблице процессов включается счетчик сигналов. Так как ядро имеет доступ к счетчикам постояноо, то сигналы можно посылать асинхронно. Второе множество данных, связанное с сигналамии, - вектор с адресами обработки сигналов. Стандартная обработка = пректращение работы. Кнеему добавляется вектор, показывающий, когда сигналы следует игнорировать.
Пр каждом переходе «выполняется в режиме ядра»->»выполняется в режиме задачи» при ненулевом значении счетчиков сигналов запускается обработка сигналов. Только после обработки сигналов происходит обащение к задаче.
Добавляется состояние процесса – зарезервирован.
Когда процесс находится при работе и происходит прерывание, то проиходит пееключени в режим ядра и процессс переходит в режим «зарезервирован». Это дает процессу возможность до конца использовать выделенный квант времени
Структуры данных.
Таблица процессов.
Пространство процесса состоит из 4-х областей аблица процессов содержит информацию об идентификаторах, адреса обработчиков прерываний и другие стандартные структуры.
Операции над процессами в Unix/
Создание поцесса – выполнение системного вызова. PID=fork(). – его значение – идентификатор процесса. При обработке такого вызова создается дочерний процесс. Различие дочернего и родительского процесса – родительскому процесу будет возвращаться идентификатор дочернего процесса, а дочернемцу- идентификаторр родительского. Таким образом возврат из fork() должен осуществляться в оба процесса. В Unix процесс получается копированием родительского.
Этапы:
проверяется наличие ресурсов. В случае неудачи возвращается отрицательный иидентификатор.
Выделяется место в таблице процессов
Систма вырабатывает и присваивает процессу уникальный идентификатор.
ОС делает логическую копию родителького процесса (содержит не все элементы, а некоорые из них существенно различаются)
Системные структуры: содержание записи в таблице процессов копируется для процесса-ребенка, кроме идентификатора процесса. Копируются. Копируются область данных и стека, регистровый контекст так же может быть копирован. Счетчики сигналов для дочернего процесса должны быть сброшены. В системе соответственно появляются две одинаковые таблицы дескрипторов и таблица открытых файлов – соответствующие счетчики увеличиваются.
Вызов fork() прекращается при возвращении двух разных значений PID/
Лекция 16.
Переключение контекста
Осуществляется по принципу: A->B->C->B (в действительности выполняется несколько процедур параллельно) – сохранить сведения о процессе Аб сохранить, а затем восстановить сведения о процессе В и т.д.
Переключение контекста происходит кода:
процесс завершил свою работу
выполнение системного вызова и блокирование работы
Данный процесс не является наиболее подходящим для выполнения (после системного вызова и обработки прерываний)
Следует заметить, что переключение контекста занимает много больше времени, чем одна операция процесса, и если при решении задачи необходимо создать несколько процессов, то это может быть связано с большими временными затратами, связанными с частыми переключениями.
Если не хочется переключать контекст процесса,то требуется иметь в рамках одного процесса нелинейную обработку данных. Ввоится понятие нитей исполнения.
Под процессом мы понимаем программу на стадии исполнения в совокупности с ресурсами, которые ей выделены. Разделим понятие программы и ресурсов. Часть процесса, отвечающая за управление – программа. После окончания выполнениявсех команд программы процессвыполнит какую-то задачу. Порамма по отношению к выислительнойистеме играет управляющую роль – управляющий поток
К потоку добавлены ресурсы для его нормального выполнения. Потоки- некоторые операции, поочередно выполняемые на процессоре.
Характеристика управляющего потока:
1) -содержимое регистров процессор
-указатель команд
-сожержиммое РОН
2) –текущее состояние стеков (проверка вызовов подпрограмм)
Необходимо распределить ресурсы внутри одного процесса, когда алгоритм имеет характеристику паралелизма.
Пример:
Ввод массива А
Ввод массива В
Ввод массива С
A[i]]:=A+B
A:=A+C
Вывод А
- в этой программе присутствует паралелизм и операции блокирования
Паралелизм: после ввода А и В уже можно посчитать их сумму, а потом блокироваться на ввод С, это обеспечивает быстроту.
Существует две возможности реализовать паралелизм
1) после ввода 2-х массивов организовать новый процесс для их суммирования, для суммирования с третьим – еще одинпроцесс, обеспечить всем процессам совместный доступ к областям памяти. Существенный недостаток такого подхода: при запуске второго процесса требуется выделить, а затем освободить ресурсы. Выигрыш по времени исчезает
2) не привлекать ОС и не создавать новый процесс
Нить – управляющий поток внутри текущего процесса. Они позволяют перераспределить, а не выделяют новые ресурсы..
Необходимо вести учет и контроль этих дополнительных потоков и хранить ссылки на текущий контекст и текущий стек. Желательно создать отдельно таблицу нитей и таблицу процессов.
Нить должна быть идентиыфицированна, причем внутри и вне процесса. Вне процесса к идентификатору нити добавляется идентификатор самого процесса.
Для нити вводится понятие состояния:
- состояние готов процесса – если хотя бы она нить находится в состоянии готов
- процесс находится в состоянии ожидания – если все нити находятся в состоянии ожидания
-процесс выполняется – если хотя бы одна из нитей испоняется
Процесс создается с одной нитью. Процесс с одной нитью назывется традиционным.
Для переключения нитей из одного состояния в друго служат специальные операции.
Существует два способа реализации нитей: реализация в процессе пользователя и реализация средствами ОС.
Реализация в процессе пользователя. Ос не выпоняет никаких действий по отношениюк нитям, не переключает их состояние и не ведет их учет. Это делает система поддержки выполнения программ.
Создание нити нить создается путем вызова подпрограммы, но не традиционным способом, а выполняется параллельно с другими программами.
Система поддержки так же переключает выполнение с одной нти на другую.
Таким образом, можно выполнять поддержку нитей даже при условии, что ОС ‘juj не предусматривает. Переключение состояния нитей не требует обращения к ядру. ОС требовала бы единого алгоритма планирования, а в данном случае алгоритм индивидуален для процесса и может повысить эффективность выполнения процесса. В противном случае ОС должна была бы иметь доступ к данным нитей, и значит эти даные должны храниться в пространстве ОС. При большом количестве нитей это вызывает проблемы.
Недостатки: ели ОС не знает о сущетвовании нитей и одна из нитей вызывает блокирование процесса, то будет блокирован весь процесс. Если в ОС непредусмотренно специальных средств, то собственно нитей реализовsdать не имеет смысла. Таким образом в ОС должна быть предоставлена возможность неблокирующих вызовов, которые совпадают по смыслу с блокирующими вызовами, но не прекращают работу процесса в целом. Так же отсутствует возможность отобрать у нити процессор, если она сама его не освобождает. Обычно нити используются при частом блокировании ОС. А это случается при обращении к ядру. А в этом случае О могла бы и переключить нить.
Реализация нитей в ядре. В этом случае ядру необходимо передавать информацию о том, что создается новый управляющий поток. Для идентификаци нитей необходим использовать отдельную систему. Но в случае, если все нити всех процесов будут считаться равноправными и и время процессора выделяется на каждую нить, а не на процесс, то процесс с большим количеством нитй получит необоснованное преимущество при выполнении. Поэтому при идентификации нитей используется и идентификатор процесса.
Блокирование в данном случае будет осуществлено для нити, а не для всего главного потока. Решается поблема захвата процессора одной из нитей.
Недостатки: требуется постоянное обращение к ядру ОС и требуется выделение места в памяти ОС, что ограничивает количество создаваемых нитей.
Обчно используются обе возможности.
Пример – Windows
Лекция 17.
Операции над процессами в Unix/
Создание поцесса – выполнение системного вызова. PID=fork(). – его значение – идентификатор процесса. При обработке такого вызова создается дочерний процесс. Различие дочернего и родительского процесса – родительскому процесу будет возвращаться идентификатор дочернего процесса, а дочернемцу- идентификаторр родительского. Таким образом возврат из fork() должен осуществляться в оба процесса. В Unix процесс получается копированием родительского.
Этапы:
проверяется наличие ресурсов. В случае неудачи возвращается отрицательный иидентификатор.
Выделяется место в таблице процессов
Систма вырабатывает и присваивает процессу уникальный идентификатор.
ОС делает логическую копию родителького процесса (содержит не все элементы, а некоорые из них существенно различаются)
Системные структуры: содержание записи в таблице процессов копируется для процесса-ребенка, кроме идентификатора процесса. Копируются. Копируются область данных и стека, регистровый контекст так же может быть копирован. Счетчики сигналов для дочернего процесса должны быть сброшены. В системе соответственно появляются две одинаковые таблицы дескрипторов и таблица открытых файлов – соответствующие счетчики увеличиваются.
Вызов fork() прекращается при возвращении двух разных значений PID/
На начальном этапе процесс в Unix представляет дочернюю оболочку. Для выполнения ей действий следует изменить пользовательский контекст процесса.
Системный вызов exec() – изменение контекста пользователя, набор нескольких функций? Предполагается, что пользовательский контекст описан в файле.
exec (полное имя файла с текстом программы, arg (указатель на массив параметров, которые должны быть переданы программе), env (указатель на массив параметров, составляющих среду процесса))
алгоритм выполнения:
проверка существования файла
проверка формата файла
Проверка прав доступа
Создается новый пользовательский контекст с соответствующими ресурсами: ранее выделенные области памяти не могут быть использованы (код, стек, данные), поэтому выделение ресурсов, в том числе областей памяти, происходит в два этапа: сначала освобождаются старые области, а затем к процессу присоединяются новые выделенные области. Размер области кода соответствует исполняемому файлу, размер данных определяется – для статических – из переданного файла, для инициализируемых – в соответствии с содержимым файла в конце трансляции, для динамических выделяется область стандартного размера, которая по возможности модифицируется. Возникают проблемы с областью стека: новой программе должны быть переданы аргументы и переменные окружения, поэтому они передаются через указатели, а для самих массивов место выделяется отдельно
Модификация системного и регистрового контекста
Системный контекст:
- пользовательские обработчики сигналов были потеряны, нужно стереть адреса старых обработчиков, заменив на стандартные
- может быть дано указание игнорировать сигналы – замена пользовательского контекста на это не влияет, сигналы новой программы будут по-прежнему игнорироваться
Регистровый контекст:
- ОС должна очистить регистровый контекст – установить начальные значения на данные новой программы, в частности, счетчик команд – на начало программы
ОС ставит процесс в состояние готов
Процесс остается тем же, но в рамках процесса выполняется новая программа. Контекст процесса во многом сохраняется, н-р, таблица дескрипторов открытых файлов, что позволяет обращаться к одним и тем же файлам, н-р, при организации конвейера
Системный вызов exit() - завершение выполнения процесса.
отменяет обработку всех сигналов в силу бессмысленности последней
просматривает дескрипторы открытых файлов и выполняет процесс завершения
записывает данные на диск
освобождает индексы текущего корневого каталога и текущей директории
освобождает области памяти процесса состояния
переводит процесс в стадию завершения существования в таблицу процессов записывается код завершения процесса
запись в таблице остается до запроса родительского процесса или до его закрытия
Планирование процессов
Планирование заданий используется в качестве долгосрочного планирования процессов. Оно отвечает за порождение новых процессов в системе, определяя ее степень мультипрограммирования, т. е. количество процессов, одновременно находящихся в ней. Если степень мультипрограммирования системы поддерживается постоянной, т. е. среднее количество процессов в компьютере не меняется, то новые процессы могут появляться только после завершения ранее загруженных. Поэтому долгосрочное планирование осуществляется достаточно редко, между появлением новых процессов могут проходить минуты и даже десятки минут. Решение о выборе для запуска того или иного процесса оказывает влияние на функционирование вычислительной системы на протяжении достаточно длительного времени. Отсюда и название этого уровня планирования – долгосрочное. В некоторых операционных системах долгосрочное планирование сведено к минимуму или отсутствует вовсе. Так, например, во многих интерактивных системах разделения времени порождение процесса происходит сразу после появления соответствующего запроса. Поддержание разумной степени мультипрограммирования осуществляется за счет ограничения количества пользователей, которые могут работать в системе, и особенностей человеческой психологии. Если между нажатием на клавишу и появлением символа на экране проходит 20–30 секунд, то многие пользователи предпочтут прекратить работу и продолжить ее, когда система будет менее загружена.
Планирование использования процессора применяется в качестве краткосрочного планирования процессов. Оно проводится, к примеру, при обращении исполняющегося процесса к устройствам ввода-вывода или просто по завершении определенного интервала времени. Поэтому краткосрочное планирование осуществляется, как правило, не реже одного раза в 100 миллисекунд. Выбор нового процесса для исполнения оказывает влияние на функционирование системы до наступления очередного аналогичного события, т. е. в течение короткого промежутка времени, чем и обусловлено название этого уровня планирования – краткосрочное.
В некоторых вычислительных системах бывает выгодно для повышения производительности временно удалить какой-либо частично выполнившийся процесс из оперативной памяти на диск, а позже вернуть его обратно для дальнейшего выполнения. Такая процедура в англоязычной литературе получила название swapping, что можно перевести на русский язык как "перекачка", хотя в специальной литературе оно употребляется без перевода – свопинг. Когда и какой из процессов нужно перекачать на диск и вернуть обратно, решается дополнительным промежуточным уровнем планирования процессов – среднесрочным
Планирование – упорядоченное распределение ограниченных ресурсов, для которых существует большое число потребителей.
От планирования процессов зависят внешние характеристики ОС, в частности производительность.
Уровни планирования:
- планирование заданий
- планирование подкачки
- планирование использования процессора
Планирование заданий (в настоящее время редко используемый уровень)
Появился в пакетных системах. Выбранное задание выполнялось достаточно долго – планирование называлось долгосрочным.Позволяло определить степень многозадачности системы (означало реальное количество запущеннных параллельно задач).
Современные системы работают в режиме реального времении квантования времени, задачи выполняются по запросу пользователя
Планирование подкачки:
Когда не хватает памяти , происходит выгрузка процессов на диск. Следует определить принцип, по которому процессы загружаются с диска обратно в память. Среднесрочное планирование. Реализуется во всех ОС, где реализована во всех ОС, где реализуется подкачка (во всех современных ОС).
Планирование использования процессов:
В мультипрограмируемой сстеме, в которой несколько процессов может быть в состоянии готов. Производится многократно о определяет жизнь системы на короткий период. Краткосрочное планирование. Система планирования основывается на алгоритме планиирования.
Критерии планирования и алгоритм планирования
Критерии:
- справедливость – распределение дефицитных ресурсов: в рамках системы всем процессам будет выделено время процессора, невозможность захвата одним процессом слишком большого количества времени процесса
- эффективность – оптимизация степени загрузки вычислительной системы (обычно н превышает 5%, редко достигает 90%).алгоритм должен загружать процесор на 100%, учитывая и загрузку остальных устройств
- минимизация полного среднего времени выпонения процесса (от момента запуска до момента окончания)
-минимизация среднего времени ожидания (процесс находится в состоянии готов, а процессор не выделяется)
- минимизация времени отклика
Свойства алгоритмов планирования
- они должны быть предсказуемы- одно и то же задание на одной ивычислительной системе должно выполняться одно и то же время-
- минимальные накладные расходы
- равномерная загрузка ресурсов вычислительной истемы
- обладают свойством масштабируемости
Параметры планирования:
Параметры планирования – численные характеристики , показывающие степень выполнения критериев
- статические – которые не изменяются в процессе работы вычислительной системы
- динамические – изменяемые
|
З
100%
Где сооотв. Надписи означают работу соотв. Устройств
Таким образом, программу можно описать в виде последовательности загружает процессор/ожидает EDD
- интервал времени непрерывной загрузки процессора
= интервал времени непрерывного выполнения операций ввода/вывода
Лекция 18
Вытесняющее и невытесняющее планирование
Процесс планирования осуществляется частью операционной системы, называемой планировщиком. Планировщик может принимать решения о выборе для исполнения нового процесса из числа находящихся в состоянии готовность в следующих четырех случаях.
Когда процесс переводится из состояния исполнение в состояние закончил исполнение.
Когда процесс переводится из состояния исполнение в состояние ожидание.
Когда процесс переводится из состояния исполнение в состояние готовность (например, после прерывания от таймера).
Когда процесс переводится из состояния ожидание в состояние готовность (завершилась операция ввода-вывода или произошло другое событие). Подробно процедура такого перевода рассматривалась в лекции 2 (раздел "Переключение контекста"), где мы показали, почему при этом возникает возможность смены процесса, находящегося в состоянии исполнение.
В случаях 1 и 2 процесс, находившийся в состоянии исполнение, не может дальше исполняться, и операционная система вынуждена осуществлять планирование выбирая новый процесс для выполнения. В случаях 3 и 4 планирование может как проводиться, так и не проводиться, планировщик не вынужден обязательно принимать решение о выборе процесса для выполнения, процесс, находившийся в состоянии исполнение может просто продолжить свою работу. Если в операционной системе планирование осуществляется только в вынужденных ситуациях, говорят, что имеет место невытесняющее (nonpreemptive) планирование. Если планировщик принимает и вынужденные, и невынужденные решения, говорят о вытесняющем (preemptive) планировании. Термин "вытесняющее планирование" возник потому, что исполняющийся процесс помимо своей воли может быть вытеснен из состояния исполнение другим процессом.
Невытесняющее планирование используется, например, в MS Windows 3.1 и ОС Apple Macintosh. При таком режиме планирования процесс занимает столько процессорного времени, сколько ему необходимо. При этом переключение процессов возникает только при желании самого исполняющегося процесса передать управление (для ожидания завершения операции ввода-вывода или по окончании работы). Этот метод планирования относительно просто реализуем и достаточно эффективен, так как позволяет выделить большую часть процессорного времени для работы самих процессов и до минимума сократить затраты на переключение контекста. Однако приневытесняющем планировании возникает проблема возможности полного захвата процессора одним процессом, который вследствие каких-либо причин (например, из-за ошибки в программе) зацикливается и не может передать управление другому процессу. В такой ситуации спасает только перезагрузка всей вычислительной системы.
Вытесняющее планирование обычно используется в системах разделения времени. В этом режиме планирования процесс может быть приостановлен в любой момент исполнения. Операционная система устанавливает специальный таймер для генерации сигнала прерывания по истечении некоторого интервала времени – кванта. После прерывания процессор передается в распоряжение следующего процесса. Временные прерывания помогают гарантировать приемлемое время отклика процессов для пользователей, работающих в диалоговом режиме, и предотвращают "зависание" компьютерной системы из-за зацикливания какой-либо программы.
First-Come, First-Served (FCFS)
Простейшим алгоритмом планирования является алгоритм, который принято обозначать аббревиатурой FCFS по первым буквам его английского названия – First-Come, First-Served (первым пришел, первым обслужен). Представим себе, что процессы, находящиеся в состоянии готовность, выстроены в очередь. Когда процесс переходит в состояние готовность, он, а точнее, ссылка на его PCB помещается в конец этой очереди. Выбор нового процесса для исполнения осуществляется из начала очереди с удалением оттуда ссылки на его PCB. Очередь подобного типа имеет в программировании специальное наименование – FIFO1), сокращение от First In, First Out (первым вошел, первым вышел).Такой алгоритм выбора процесса осуществляет невытесняющее планирование. Процесс, получивший в свое распоряжение процессор, занимает его до истечения текущего CPU burst(Промежуток времени непрерывного использования процессора) . После этого для выполнения выбирается новый процесс из начала очереди.Преимуществом алгоритма FCFS является легкость его реализации, но в то же время он имеет и много недостатков. Среднее время ожидания и среднее полное время выполнения для этого алгоритма существенно зависят от порядка расположения процессов в очереди. Если у нас есть процесс с длительным CPU burst , то короткие процессы, перешедшие в состояние готовность после длительного процесса, будут очень долго ждать начала выполнения. Поэтому алгоритм FCFS практически неприменим для систем разделения времени – слишком большим получается среднее время отклика в интерактивных процессах.
Round Robin (RR)
Модификацией алгоритма FCFS является алгоритм, получивший название Round Robin (Round Robin – это вид детской карусели в США) или сокращенно RR. По сути дела, это тот же самый алгоритм, только реализованный в режиме вытесняющего планирования. Можно представить себе все множество готовых процессов организованным циклически – процессы сидят на карусели. Карусель вращается так, что каждый процесс находится около процессора небольшой фиксированный квант времени, обычно 10– 100 миллисекунд (см. рис. 3.4.). Пока процесс находится рядом с процессором, он получает процессор в свое распоряжение и может исполняться.

Рис. 3.4. Процессы на карусели
Реализуется такой алгоритм так же, как и предыдущий, с помощью организации процессов, находящихся в состоянии готовность, в очередь FIFO. Планировщик выбирает для очередного исполнения процесс, расположенный в начале очереди, и устанавливает таймер для генерации прерывания по истечении определенного кванта времени. При выполнении процесса возможны два варианта.
Время непрерывного использования процессора, необходимое процессу (остаток текущего CPU burst ), меньше или равно продолжительности кванта времени. Тогда процесс по своей воле освобождает процессор до истечения кванта времени, на исполнение поступает новый процесс из начала очереди, и таймер начинает отсчеткванта заново.
Продолжительность остатка текущего CPU burst процесса больше, чем квант времени. Тогда по истечении этого кванта процесс прерывается таймером и помещается в конец очереди процессов, готовых к исполнению, а процессор выделяется для использования процессу, находящемуся в ее начале.
Легко увидеть, что среднее время ожидания и среднее полное время выполнения для обратного порядка процессов не отличаются от соответствующих времен для алгоритма FCFS и составляют 2 и 8 единиц времени соответственно.На производительность алгоритма RR сильно влияет величина кванта времени. При очень больших величинах кванта времени, когда каждый процесс успевает завершить свой CPU burst до возникновения прерывания по времени, алгоритм RRвырождается в алгоритм FCFS. При очень малых величинах создается иллюзия того, что каждый из n процессов работает на собственном виртуальном процессоре с производительностью ~ 1/n от производительности реального процессора. Правда, это справедливо лишь при теоретическом анализе при условии пренебрежения временами переключения контекста процессов. В реальных условиях при слишком малой величине кванта времени и, соответственно, слишком частом переключении контекста накладные расходы на переключение резко снижают производительность системы.
Shortest-Job-First (SJF)
При рассмотрении алгоритмов FCFS и RR мы видели, насколько существенным для них является порядок расположения процессов в очереди процессов, готовых к исполнению. Если короткие задачи расположены в очереди ближе к ее началу, то общая производительность этих алгоритмов значительно возрастает. Если бы мы знали время следующих CPU burst для процессов, находящихся в состоянии готовность, то могли бы выбрать для исполнения не процесс из начала очереди, а процесс с минимальной длительностью CPU burst. Если же таких процессов два или больше, то для выбора одного из них можно использовать уже известный нам алгоритм FCFS. Квантование времени при этом не применяется. Описанный алгоритм получил название "кратчайшая работа первой" или Shortest Job First (SJF).
SJF-алгоритм краткосрочного планирования может быть как вытесняющим, так и невытесняющим. При невытесняющем SJF-планировании процессор предоставляется избранному процессу на все необходимое ему время, независимо от событий, происходящих в вычислительной системе. При вытесняющем SJF-планировании учитывается появление новых процессов в очереди готовых к исполнению (из числа вновь родившихся или разблокированных) во время работы выбранного процесса. Если CPU burst нового процесса меньше, чем остаток CPU burst у исполняющегося, то исполняющийся процесс вытесняется новым.
Основную сложность при реализации алгоритма SJF представляет невозможность точного знания продолжительности очередного CPU burst для исполняющихся процессов. В пакетных системах количество процессорного времени, необходимое заданию для выполнения, указывает пользователь при формировании задания. Мы можем брать эту величину для осуществления долгосрочного SJF-планирования. Если пользователь укажет больше времени, чем ему нужно, он будет ждать результата дольше, чем мог бы, так как задание будет загружено в систему позже. Если же он укажет меньшее количество времени, задача может не досчитаться до конца.
Гарантированное планирование
При интерактивной работе N пользователей в вычислительной системе можно применить алгоритм планирования, который гарантирует, что каждый из пользователей будет иметь в своем распоряжении ~1/N часть процессорного времени. Пронумеруем всех пользователей от 1 до N. Для каждого пользователя с номером i введем две величины: Ti – время нахождения пользователя в системе или, другими словами, длительность сеанса его общения с машиной и τi – суммарное процессорное время уже выделенное всем его процессам в течение сеанса. Справедливым для пользователя было бы получение Ti/N процессорного времени. Если
τi<<Ti/N
то i-й пользователь несправедливо обделен процессорным временем. Если же
τi>>Ti/N
то система явно благоволит к пользователю с номером i. Вычислим для процессов каждого пользователя значение коэффициента справедливости
τiN/Ti
и будем предоставлять очередной квант времени готовому процессу с наименьшей величиной этого отношения. Предложенный алгоритм называют алгоритмом гарантированного планирования. К недостаткам этого алгоритма можно отнести невозможность предугадать поведение пользователей. Если некоторый пользователь отправится на пару часов пообедать и поспать, не прерывая сеанса работы, то по возвращении его процессы будут получать неоправданно много процессорного времени.
Приоритетное планирование
Алгоритмы SJF и гарантированного планирования представляют собой частные случаи приоритетного планирования. При приоритетном планировании каждому процессу присваивается определенное числовое значение – приоритет, в соответствии с которым ему выделяется процессор. Процессы с одинаковыми приоритетами планируются в порядке FCFS. Для алгоритма SJF в качестве такого приоритета выступает оценка продолжительности следующего CPU burst. Чем меньше значение этой оценки, тем более высокий приоритет имеет процесс. Для алгоритма гарантированного планирования приоритетом служит вычисленный коэффициент справедливости. Чем он меньше, тем больше у процесса приоритет.
Алгоритмы назначения приоритетов процессов могут опираться как на внутренние параметры, связанные с происходящим внутри вычислительной системы, так и на внешние по отношению к ней. К внутренним параметрам относятся различные количественные и качественные характеристики процесса такие как: ограничения по времени использования процессора, требования к размеру памяти, число открытых файлов и используемых устройств ввода-вывода, отношение средних продолжительностей I/O burst( промежуток времени непрерывного ожидания ввода-вывода) к CPU burst(Промежуток времени непрерывного использования процессора) и т. д. Алгоритмы SJF и гарантированного планирования используют внутренние параметры. В качестве внешних параметров могут выступать важность процесса для достижения каких-либо целей, стоимость оплаченного процессорного времени и другие политические факторы. Высокий внешний приоритет может быть присвоен задаче лектора или того, кто заплатил $100 за работу в течение одного часа.Планирование с использованием приоритетов может быть как вытесняющим, так и невытесняющим. При вытесняющем планировании процесс с более высоким приоритетом, появившийся в очереди готовых процессов, вытесняет исполняющийся процесс с более низким приоритетом.
Многоуровневые очереди (Multilevel Queue)
Для систем, в которых процессы могут быть легко рассортированы по разным группам, был разработан другой класс алгоритмов планирования. Для каждой группы процессов создается своя очередь процессов, находящихся в состоянии готовность. Этим очередям приписываются фиксированные приоритеты. Например, приоритет очереди системных процессов устанавливается выше, чем приоритет очередей пользовательских процессов. А приоритет очереди процессов, запущенных студентами, ниже, чем для очереди процессов, запущенных преподавателями. Это значит, что ни один пользовательский процесс не будет выбран для исполнения, пока есть хоть один готовый системный процесс, и ни один студенческий процесс не получит в свое распоряжение процессор, если есть процессы преподавателей, готовые к исполнению. Внутри этих очередей для планирования могут применяться самые разные алгоритмы. Так, например, для больших счетных процессов, не требующих взаимодействия с пользователем (фоновых процессов), может использоваться алгоритм FCFS, а для интерактивных процессов – алгоритм RR. Подобный подход, получивший название многоуровневых очередей, повышает гибкость планирования: для процессов с различными характеристиками применяется наиболее подходящий им алгоритм.
Многоуровневые очереди с обратной связью (Multilevel Feedback Queue)
Дальнейшим развитием алгоритма многоуровневых очередей является добавление к нему механизма обратной связи. Здесь процесс не постоянно приписан к определенной очереди, а может мигрировать из одной очереди в другую в зависимости от своего поведения.Для простоты рассмотрим ситуацию, когда процессы в состоянии готовность организованы в 4 очереди, как на рисунке 3.6. Планирование процессов между очередями осуществляется на основе вытесняющего приоритетного механизма. Чем выше на рисунке располагается очередь, тем выше ее приоритет. Процессы в очереди 1 не могут исполняться, если в очереди 0 есть хотя бы один процесс. Процессы в очереди 2 не будут выбраны для выполнения, пока есть хоть один процесс в очередях 0 и 1. И наконец, процесс в очереди 3 может получить процессор в свое распоряжение только тогда, когда очереди 0, 1 и 2 пусты. Если при работе процесса появляется другой процесс в какой-либо более приоритетной очереди, исполняющийся процесс вытесняется новым. Планирование процессов внутри очередей 0–2 осуществляется с использованием алгоритма RR, планирование процессов в очереди 3 основывается на алгоритме FCFS.Схема миграции процессов в многоуровневых очередях планирования с обратной связью. Вытеснение процессов более приоритетными процессами и завершение процессов на схеме не показано
Родившийся процесс поступает в очередь 0. При выборе на исполнение он получает в свое распоряжение квант времени размером 8 единиц. Если продолжительность его CPU burst меньше этого кванта времени, процесс остается в очереди 0. В противном случае он переходит в очередь 1. Для процессов из очереди 1 квант времени имеет величину 16. Если процесс не укладывается в это время, он переходит в очередь 2. Если укладывается – остается в очереди 1. В очереди 2 величина кванта времени составляет 32 единицы. Если для непрерывной работы процесса и этого мало, процесс поступает в очередь 3, для которой квантование времени не применяется и, при отсутствии готовых процессов в других очередях, может исполняться до окончания своего CPU burst. Чем больше значение продолжительности CPU burst, тем в менее приоритетную очередь попадает процесс, но тем на большее процессорное время он может рассчитывать. Таким образом, через некоторое время все процессы, требующие малого времени работы процессора, окажутся размещенными в высокоприоритетных очередях, а все процессы, требующие большого счета и с низкими запросами к времени отклика, – в низкоприоритетных.Миграция процессов в обратном направлении может осуществляться по различным принципам. Например, после завершения ожидания ввода с клавиатуры процессы из очередей 1, 2 и 3 могут помещаться в очередь 0, после завершения дисковых операций ввода-вывода процессы из очередей 2 и 3 могут помещаться в очередь 1, а после завершения ожидания всех других событий – из очереди 3 в очередь 2. Перемещение процессов из очередей с низкими приоритетами в очереди с высокими приоритетами позволяет более полно учитывать изменение поведения процессов с течением времени.Многоуровневые очереди с обратной связью представляют собой наиболее общий подход к планированию процессов из числа подходов, рассмотренных нами. Они наиболее трудны в реализации, но в то же время обладают наибольшей гибкостью. Понятно, что существует много других разновидностей такого способа планирования, помимо варианта, приведенного выше. Для полного описания их конкретного воплощения необходимо указать:
Количество очередей для процессов, находящихся в состоянии готовность.
Алгоритм планирования, действующий между очередями.
Алгоритмы планирования, действующие внутри очередей.
Правила помещения родившегося процесса в одну из очередей.
Правила перевода процессов из одной очереди в другую.
Изменяя какой-либо из перечисленных пунктов, мы можем существенно менять поведение вычислительной системы.
Лекция 19
Причины взаимодействия процессов:
Повышение скорости работы. Пока один процесс ожидает наступления некоторого события (например, окончания операции ввода-вывода), другие могут заниматься полезной работой, направленной на решение общей задачи. В многопроцессорных вычислительных системах программа разбивается на отдельные кусочки, каждый из которых будет исполняться на своем процессоре.
Совместное использование данных. Различные процессы могут, к примеру, работать с одной и той же динамической базой данных или с разделяемым файлом, совместно изменяя их содержимое.
Модульная конструкция какой-либо системы. Типичным примером может служить микроядерный способ построения операционной системы, когда различные ее части представляют собой отдельные процессы, взаимодействующие путем передачи сообщений через микроядро.
Наконец, это может быть необходимо просто для удобства работы пользователя, желающего, например, редактировать и отлаживать программу одновременно. В этой ситуации процессы редактора и отладчика должны уметь взаимодействовать друг с другом.
Процессы не могут взаимодействовать, не общаясь, то есть не обмениваясь информацией. "Общение" процессов обычно приводит к изменению их поведения в зависимости от полученной информации. Если деятельность процессов остается неизменной при любой принятой ими информации, то это означает, что они на самом деле в "общении" не нуждаются. Процессы, которые влияют на поведение друг друга путем обмена информацией, принято называть кооперативными или взаимодействующими процессами , в отличие от независимых процессов, не оказывающих друг на друга никакого воздействия.
Категории средств обмена информацией
Процессы могут взаимодействовать друг с другом, только обмениваясь информацией. По объему передаваемой информации и степени возможного воздействия на поведение другого процесса все средства такого обмена можно разделить на три категории.
Сигнальные. Передается минимальное количество информации – один бит, "да" или "нет". Используются, как правило, для извещения процесса о наступлении какого-либо события. Степень воздействия на поведение процесса, получившего информацию, минимальна. Все зависит от того, знает ли он, что означает полученный сигнал, надо ли на него реагировать и каким образом. Неправильная реакция на сигнал или его игнорирование могут привести к трагическим последствиям. Вспомним профессора Плейшнера из кинофильма "Семнадцать мгновений весны". Сигнал тревоги – цветочный горшок на подоконнике – был ему передан, но профессор проигнорировал его. И к чему это привело?
Канальные. "Общение" процессов происходит через линии связи, предоставленные операционной системой, и напоминает общение людей по телефону, с помощью записок, писем или объявлений. Объем передаваемой информации в единицу времени ограничен пропускной способностью линий связи. С увеличением количества информации возрастает и возможность влияния на поведение другого процесса.
Разделяемая память. Два или более процессов могут совместно использовать некоторую область адресного пространства. Созданием разделяемой памяти занимается операционная система (если, конечно, ее об этом попросят). "Общение" процессов напоминает совместное проживание студентов в одной комнате общежития. Возможность обмена информацией максимальна, как, впрочем, и влияние на поведение другого процесса, но требует повышенной осторожности (если вы переложили на другое место вещи вашего соседа по комнате, а часть из них еще и выбросили). Использование разделяемой памяти для передачи/получения информации осуществляется с помощью средств обычных языков программирования, в то время как сигнальным и канальным средствам коммуникации для этого необходимы специальные системные вызовы. Разделяемая память представляет собой наиболее быстрый способ взаимодействия процессов в одной вычислительной системе.
Различают два способа адресации: прямую и непрямую. В случае прямой адресации взаимодействующие процессы непосредственно общаются друг с другом, при каждой операции обмена данными явно указывая имя или номер процесса, которому информация предназначена или от которого она должна быть получена. Если и процесс, от которого данные исходят, и процесс, принимающий данные, указывают имена своих партнеров по взаимодействию, то такая схема адресации называется симметричной прямой адресацией . Ни один другой процесс не может вмешаться в процедуру симметричного прямого общения двух процессов, перехватить посланные или подменить ожидаемые данные. Если только один из взаимодействующих процессов, например передающий, указывает имя своего партнера по кооперации, а второй процесс в качестве возможного партнера рассматривает любой процесс в системе, например ожидает получения информации от произвольного источника, то такая схема адресации называется асимметричной прямой адресацией .
При непрямой адресации данные помещаются передающим процессом в некоторый промежуточный объект для хранения данных, имеющий свой адрес, откуда они могут быть затем изъяты каким-либо другим процессом. Примером такого объекта может служить обычная доска объявлений или рекламная газета. При этом передающий процесс не знает, как именно идентифицируется процесс, который получит информацию, а принимающий процесс не имеет представления об идентификаторе процесса, от которого он должен ее получить.
При использовании прямой адресации связь между процессами в классической операционной системе устанавливается автоматически, без дополнительных инициализирующих действий. Единственное, что нужно для использования средства связи, – это знать, как идентифицируются процессы, участвующие в обмене данными.
При использовании непрямой адресации инициализация средства связи может и не требоваться. Информация, которой должен обладать процесс для взаимодействия с другими процессами, – это некий идентификатор промежуточного объекта для хранения данных, если он, конечно, не является единственным и неповторимым в вычислительной системе для всех процессов.
Информационная валентность процессов и средств связи
Следующий важный вопрос – это вопрос об информационной валентности связи. Слово "валентность" здесь использовано по аналогии с химией. Сколько процессов может быть одновременно ассоциировано с конкретным средством связи? Сколько таких средств связи может быть задействовано между двумя процессами?
Понятно, что при прямой адресации только одно фиксированное средство связи может быть задействовано для обмена данными между двумя процессами, и только эти два процесса могут быть ассоциированы с ним. При непрямой адресации может существовать более двух процессов, использующих один и тот же объект для данных, и более одного объекта может быть использовано двумя процессами.
К этой же группе вопросов следует отнести и вопрос о направленности связи. Является ли связь однонаправленной или двунаправленной? Под однонаправленной связью мы будем понимать связь, при которой каждый процесс, ассоциированный с ней, может использовать средство связи либо только для приема информации, либо только для ее передачи. При двунаправленной связи каждый процесс, участвующий в общении, может использовать связь и для приема, и для передачи данных. В коммуникационных системах принято называть однонаправленную связь симплексной , двунаправленную связь с поочередной передачей информации в разных направлениях –полудуплексной , а двунаправленную связь с возможностью одновременной передачи информации в разных направлениях – дуплексной . Прямая и непрямая адресация не имеет непосредственного отношения к направленности связи.
Особенности передачи информации с помощью линий связи
Как уже говорилось выше, передача информации между процессами посредством линий связи является достаточно безопасной по сравнению с использованием разделяемой памяти и более информативной по сравнению с сигнальными средствами коммуникации. Кроме того, разделяемая память не может быть использована для связи процессов, функционирующих на различных вычислительных системах. Возможно, именно поэтому каналы связи из средств коммуникации процессов получили наибольшее распространение. Коснемся некоторых вопросов, связанных с логической реализацией канальных средств коммуникации.
Буферизация
Может ли линия связи сохранять информацию, переданную одним процессом, до ее получения другим процессом или помещения в промежуточный объект? Каков объем этой информации? Иными словами, речь идет о том, обладает ли канал связи буфером и каков объем этого буфера. Здесь можно выделить три принципиальных варианта.
Буфер нулевой емкости или отсутствует. Никакая информация не может сохраняться на линии связи. В этом случае процесс, посылающий информацию, должен ожидать, пока процесс, принимающий информацию, не соблаговолит ее получить, прежде чем заниматься своими дальнейшими делами (в реальности этот случай никогда не реализуется).
Буфер ограниченной емкости. Размер буфера равен n, то есть линия связи не может хранить до момента получения более чем n единиц информации. Если в момент передачи данных в буфере хватает места, то передающий процесс не должен ничего ожидать. Информация просто копируется в буфер. Если же в момент передачи данных буфер заполнен или места недостаточно, то необходимо задержать работу процесса отправителя до появления в буфере свободного пространства.
Буфер неограниченной емкости. Теоретически это возможно, но практически вряд ли реализуемо. Процесс, посылающий информацию, никогда не ждет окончания ее передачи и приема другим процессом.
При использовании канального средства связи с непрямой адресацией под емкостью буфера обычно понимается количество информации, которое может быть помещено в промежуточный объект для хранения данных.