

2.2. Иерархическая модель данных
Иерархические, или древовидные, структуры данных разработаны и используются достаточно давно. Например, большинство методов индексирования базируются именно на древовидных структурах данных. Иерархическая модель данных близка по своей идее к иерархической структуре данных. Но модель описывает не конкретные методы работы и манипулирования ссылками, а способ логического представления данных, то, какими терминами оперирует проектировщик структуры базы данных, когда отражает реальные зависимости с помощью имеющихся в СУБД механизмов.
Иерархическая модель позволяет строить иерархию элементов (автор просит прощения у читателей, уважающих чичстоту русского языка, за такой оборот). То есть у каждого элемента может быть несколько “наследников” и существует один “родитель”. Для каждого уровня связи вводится интерпретация, зависящая от предметной области и описывающая взаимоотношение между “родителями” и “наследниками”. Каждый элемент представляется с помощью записи. Структура данных, обычно используемая для представления этой записи об элементе, обычно содержит некоторые атрибуты, характеристики каждого элемента.
Попробуем представить себе базу данных для описания тематических сборников по некоторой теме. Прежде всего, выделим уровни иерархии. Первый уровень - это издательства. Каждое издательство характеризуется своим названием, юридическим адресом, номером счета в банке. Каждое издательство выпускает несколько сборников. То есть издательство является “родителем” для сборника и связано с сборником соотношением “издает” (разработчик, естественно, вправе выбрать и другой синоним для данной связи, например “публикует”, “печатает” и т.д.). Для каждого сборника появляются такие атрибуты, как размер, периодичность, цена, ответственный редактор, корректор и т.д. В каждом сборнике есть несколько статей (хотя бы, одна). То есть сборник и статья связаны соотношением “включает”. Далее, у каждой статьи есть название, авторы. Авторы представляются отдельным элементом и образуют следующий уровень иерархии. Каждый автор характеризуется фамилией, именем, отчеством, гонораром и т.д. Статьи связаны с автором соотношением “написаны”. Графическое представление этого примера приведено на Рис.2.2. Элементы нарисованы прямоугольниками, их названия даны обычным шрифтом. Связи нарисованы стрелками и их названия даны курсивом. Обращаем внимание читателей, что атрибуты для каждого элемента на этой схеме не показаны - они являются частью элемента данных.
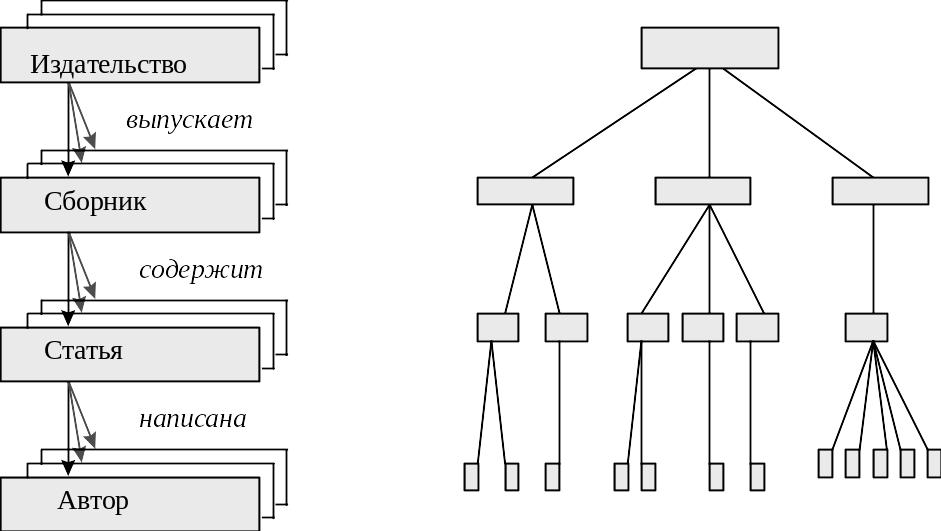
Рис. 2.2. Графическое представление иерархической модели данных (справа пример какой-то конкретной базы данных).
Что касается способов описания конкретных схем, базирующихся на иерархической модели, или языков манипулирования данными, работающими с такой моделью, то они зависят от конкретной реализации. Например, в достаточно давно разработанной системе IMS фирмы IBM (эта система является классическим примером иерархической СУБД) схема для нашего примера будет описана следующим образом3):
DBD NAME = ТЕМАТИЧЕСКИЕ_СБОРНИКИ SEGM NAME = ИЗДАТЕЛЬСТВО FIELD NAME = НАЗВАНИЕ FIELD NAME = АДРЕС FIELD NAME = СЧЕТ SEGM NAME = СБОРНИК, PARENT = ИЗДАТЕЛЬСТВО FIELD NAME = НАЗВАНИЕ FIELD NAME = ПЕРИОДИЧНОСТЬ FIELD NAME = ЦЕНА FIELD NAME = ОТВЕТСТВЕННЫЙ_РЕДАКТОР SEGM NAME = СТАТЬЯ, PARENT = СБОРНИК FIELD NAME = НАЗВАНИЕ SEGM NAME = АВТОР, PARENT = СТАТЬЯ FIELD NAME = ФИО FIELD NAME = ГОНОРАР
В данном примере мы не именовали явно связи, которые существуют между разными элементами (в терминологии IMS для нашего понятия “элемент” используется термин “сегмент”). Язык доступа к данным, который поддерживает IMS позволяет обращаться к элементам напрямую, зная название и, возможно, дополнительное условие. Например, можно распечатать названия всех сборников, ответственным редактором которых является некто по фамилии Буквоедов:
GET UNIQUE СБОРНИК WHERE ОТВЕТСТВЕННЫЙ_РЕДАКТОР = “БУКВОЕДОВ” /* получили первый сборник */ while true do print СБОРНИК.НАЗВАНИЕ /* переходим к следующему сборнику */ GET NEXT СБОРНИК WHERE ОТВЕТСТВЕННЫЙ_РЕДАКТОР = “БУКВОЕДОВ” end while
Выбрав один из сборников в предыдущем примере, можно спуститься “вниз” по иерархии и, например, просмотреть все статьи из выбранного сборника. Для этого существует оператор “движения вниз по иерархии” GET NEXT WITHIN PARENT. Этот оператор позволяет перебрать все элементы-потомки, принадлежащие выбранному элементу. Предположим, мы хотим напечатать не только названия сборников, но и входящие в них статьи:
GET UNIQUE СБОРНИК WHERE ОТВЕТСТВЕННЫЙ_РЕДАКТОР = “БУКВОЕДОВ” /* выбрали первый сборник */ while true do print “Сборник ”, СБОРНИК.НАЗВАНИЕ GET NEXT WITHIN PARENT СТАТЬЯ while true do print СТАТЬЯ.НАЗВАНИЕ GET NEXT WITHIN PARENT СТАТЬЯ end while GET NEXT СБОРНИК WHERE ОТВЕТСТВЕННЫЙ_РЕДАКТОР = “БУКВОЕДОВ” end while
У иерархических СУБД есть достоинства и недостатки. К достоинствам относится возможность реализовать фантастически быстрый поиск нужных значений, когда условия запроса соответствуют иерархии в схеме базе данных. Например, приведенный выше запрос отработает очень быстро. С другой стороны, если запрос не соответствует имеющейся иерархии, то и его программирование, и его исполнение, потребуют значительных усилий. Например, попытки реализовать запрос типа “в скольких сборниках статей опубликовал свои статьи господин Плагиаторов” может оказаться весьма трудной задачей (мы можем искать в направлении от статьи к автору, но не наоборот).
Другим недостатком иерархической модели является сложность внесения в нее изменений. Если, по каким-то причинам изменились условия задачи, и модель предметной области перестала быть иерархической (например, в нашем примере, мы хотим иметь не только зависимость авторов от статьи, но и статей от автора), то приведение схемы базы данных в соответствие предметной области становится нетривиальной задачей.
Недостатки иерархической модели проистекают от того, что данная модель слишком жесткая. Иерархическая модель очень хорошо подходит для устоявшихся предметных областей с четкими зависимости “родитель-потомок”, то есть к моделям, где есть четкая субординация между понятиями. Там же, где эти условия выполнены, проявляются достоинства иерархической модели - очень быстрая скорость поиска.