

2.11. Утилиты
Утилиты — это программы, разработанные для администратора и используемые при выполнении различных административных задач. Как уже упоминалось выше, некоторые утилиты выполняются на внешнем уровне системы и потому представляют собой не что иное, как приложения специального назначения; некоторые из них могут предоставляться даже не поставщиками СУБД, а скорее некоторыми сторонними поставщиками программного обеспечения. Однако другие утилиты выполняются непосредственно на внутреннем уровне (т.е. действительно являются частью сервера) и поэтому должны предоставляться поставщиками СУБД.
Ниже приводится несколько типичных примеров типов утилит, которые часто применяются на практике.
• Процедуры загрузки, применяемые для создания первоначальной версии базы данных из одного или более файлов, которые не принадлежат базе данных.
• Процедуры выгрузки-перезагрузки, применяемые для выгрузки базы данных или порции из нее, дублирования памяти с целью восстановления и перезагрузки данных из таких дублированных копий (конечно, "утилита перезагрузки", по существу, идентична рассмотренной утилите загрузки).
• Процедуры реорганизации, применяемые для перераспределения данных в базе данных по различным соображениям (обычно выполняется для повышения производительности), например, для группировки некоторых данных каким-то определенным способом на диске или освобождения пространства, занятого данными, которые больше не используются.
• Статистические процедуры, применяемые для вычисления различных статистических показателей производительности, таких как распределение размеров файлов или значений данных и счетчиков ввода-вывода и т.п.
• Процедуры анализа, применяемые для анализа только что упомянутой статистики.
Этот список охватывает лишь небольшую часть функций, предоставляемых утилитами. Кроме перечисленных видов функций, существует множество других.
2.12. Распределенная обработка
Как мы определили выше, термин "распределенная обработка" означает, что разные машины можно соединить в коммуникационную сеть так, что одна задача обработки данных распределяется на несколько машин в сети. (Термин "параллельная обработка" используется практически с тем же значением, за исключением того, что разные машины с физической точки зрения расположены близко друг к другу в "параллельных" системах. Это вовсе не обязательно в "распределенной" системе, например, они могут быть удалены географически.) Связь между различными машинами осуществляется с помощью специального программного обеспечения для управления сетью.
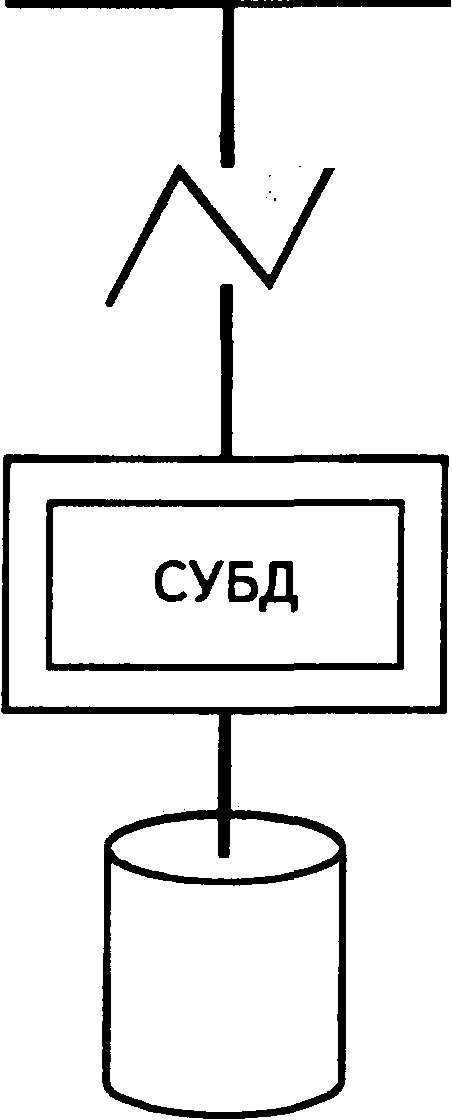
Распределенная обработка может быть самой разнообразной и осуществляться на разных уровнях. Как отмечалось выше, в одном из простых случаев запускается сервер СУБД на одной машине и клиентное приложение на другой (рис. 2.5).
-
Приложения
(Компьютер клиента)
Удаленный доступ
Компьютер сервера
Рис. 2.5. Клиент и сервер запускаются на разных машинах
Как уже говорилось, термин "клиент/сервер" фактически стал синонимом структуры, изображенной на рис. 2.5, в соответствии с которой клиент и сервер запускаются на разных машинах. В действительности существует множество аргументов в пользу такой схемы.
• Первый аргумент связан с параллельной обработкой, а именно: в этом случае для всей задачи применяется несколько процессоров и обработка сервера (базы данных) и клиента (приложения) осуществляется параллельно. Поэтому время ответа и производительное время должны уменьшиться.
• Машина сервера может быть изготовлена по специальному заказу, приспособлена для работы с СУБД ("машина базы данных") и может обеспечить лучшую производительность СУБД.
• Машина клиента может быть персональной станцией, приспособленной к потребностям конечного пользователя, и поэтому обеспечивать лучший интерфейс, полное соответствие требованиям, быструю реакцию и в целом дополнительные удобства при использовании.
• Несколько разных машин клиентов могут иметь доступ к одной и той же машине сервера. Поэтому одна база данных может совместно использоваться несколькими отдельными клиентными системами (рис. 2.6).
К сказанному выше можно добавить еще одно преимущество выполнения сервера и клиента на отдельных машинах — соответствие практической работе многих предприятий. Это довольно распространенный способ для отдельного предприятия; например, банк работает со многими компьютерами, сохраняющими данные для одной части предприятия на одном компьютере, а данные для другой части — на другом. Это также очень распространено среди пользователей, которым необходим, по крайней мере иногда, доступ с одного компьютера к данным, хранимым на другом компьютере. Следуя примеру банка, можно сказать, что весьма вероятно, пользователям одного отделения банка будет иногда необходим доступ к данным, сохраняемым в другом отделении. Следовательно, машины клиентов могут иметь свои собственные сохраняемые данные, а машина сервера может иметь свои собственные приложения. Поэтому, вообще говоря, каждая машина будет выступать в роли сервера для одних пользователей и в роли клиента для других (рис. 2.7); иными словами, каждая машина будет поддерживать полную систему баз данных.
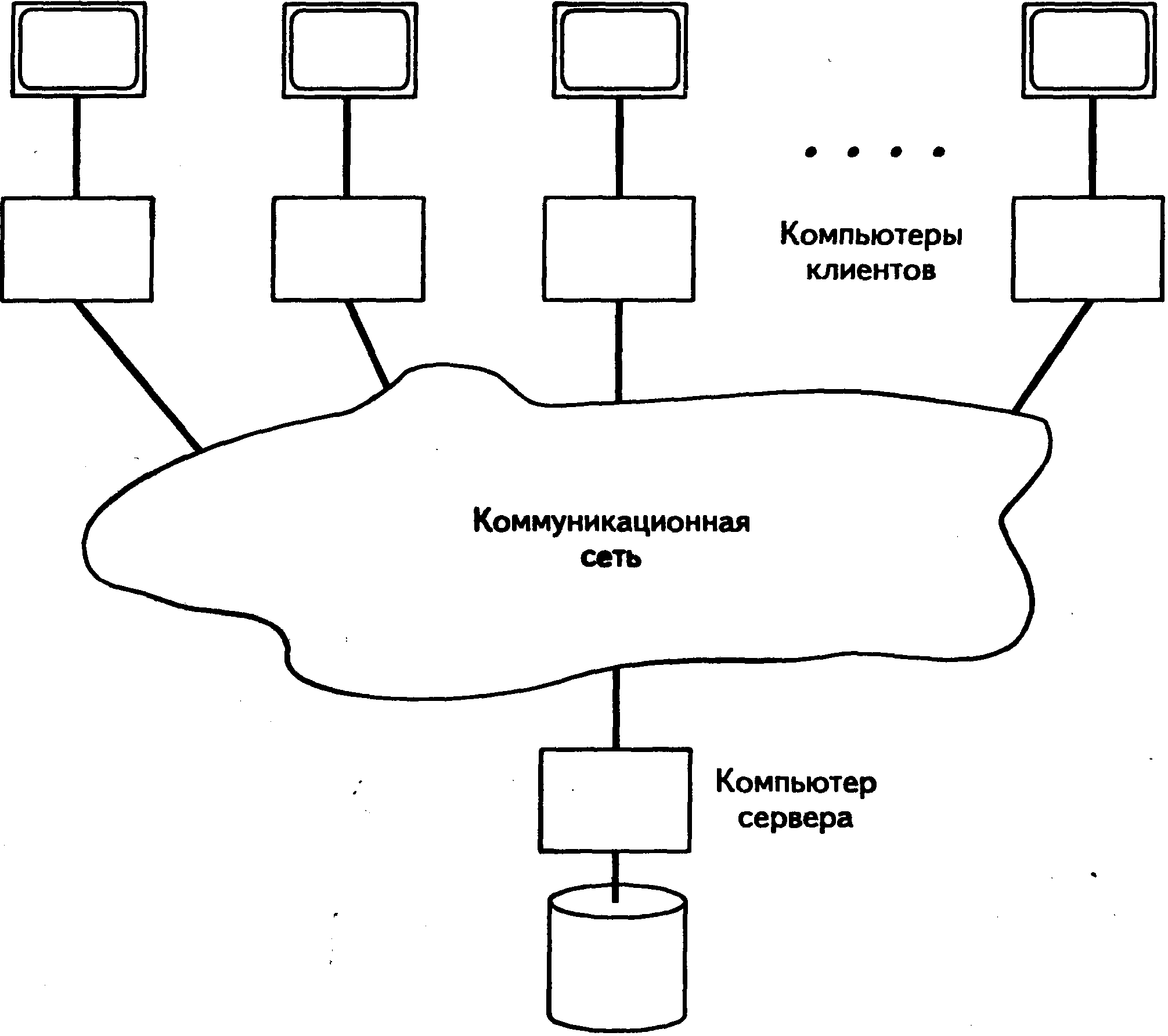
Рис. 2.6. Один сервер, много клиентов
В заключение отметим последнее преимущество, которое состоит в том, что отдельная машина клиента может иметь доступ к нескольким разным машинам серверов (противоположный случай иллюстрирует рис. 2.6). Это полезная возможность, поскольку, как уже упоминалось, предприятие обычно выполняет обработку данных таким образом, что полный набор всех данных не сохраняется на одной машине, а распределяется на отдельных машинах, а для приложений иногда необходим доступ к данным нескольких машин. Такой доступ в основном предоставляется двумя способами.
1. Клиент может получать доступ к любому количеству серверов, но лишь к одному в одно и то же время (т.е. каждый запрос к базе данных должен быть направлен только к одному серверу). В такой системе невозможно за один запрос получить комбинированные данные двух или более серверов. Кроме того, пользователь в такой системе должен знать, на какой именно машине какая часть данных содержится.
2. Клиент может получать доступ к любому количеству серверов одновременно (т.е. за один запрос можно получить комбинированные данные двух или более серверов). В этом случае серверы рассматриваются клиентом как один (с логической точки зрения), и пользователь может не знать, на какой именно машине какая часть данных содержится.
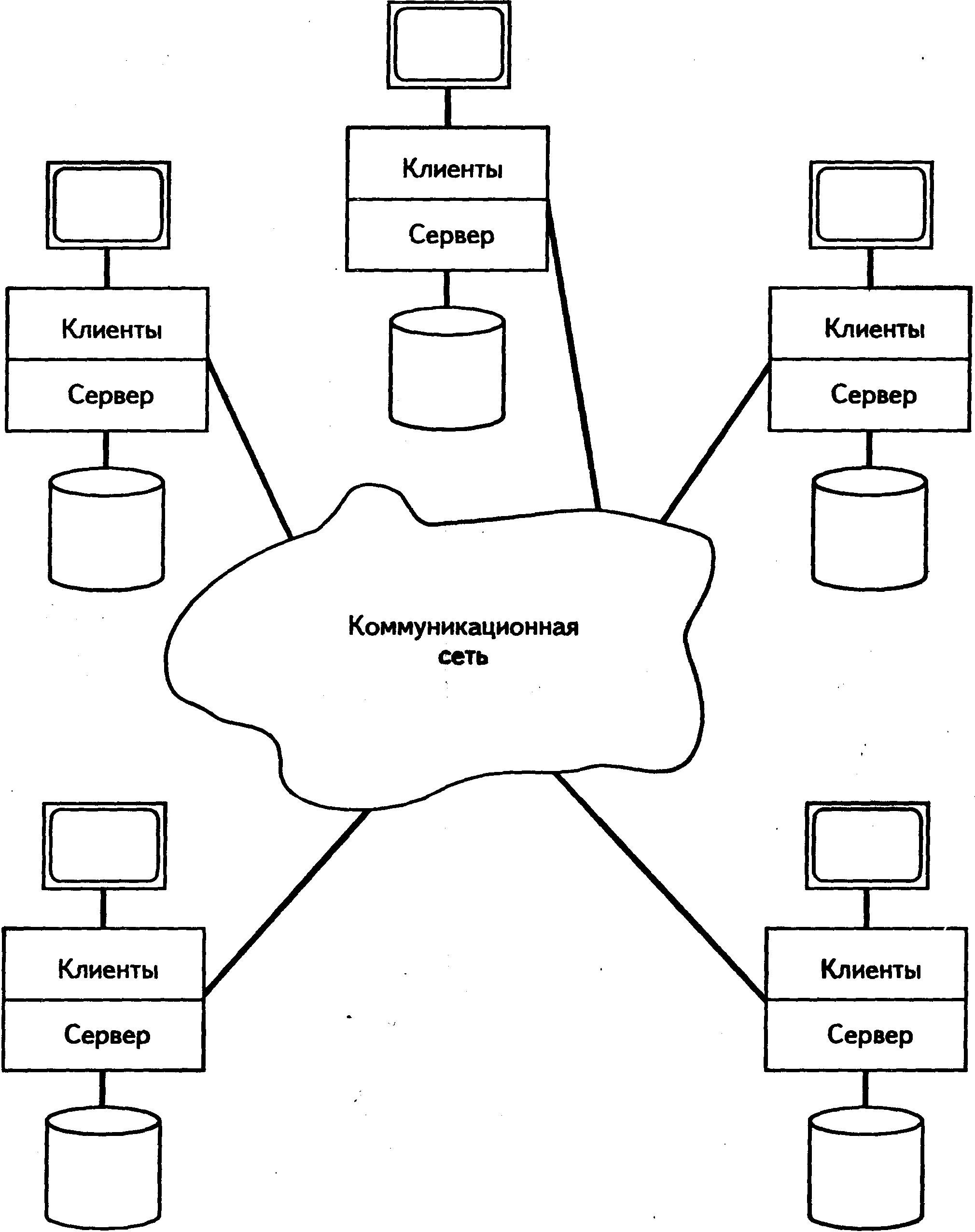
Рис, 2.7. Каждая машина одновременно является и клиентом и сервером
Второй случай — это пример системы, которую обычно называют распределенной системой баз данных. Тема распределенных баз данных сама по себе весьма обширна. Подводя ее к логическому завершению, отметим следующее: полная поддержка для распределенных баз данных означает, что отдельное приложение может "прозрачно" обрабатывать данные, распределенные на множестве различных баз данных, управление которыми осуществляют разные СУБД, работающие на многочисленных машинах с различными операционными системами, соединенных вместе коммуникационными сетями. Здесь понятие "прозрачно" означает, что приложение выполняет обработку данных с логической точки зрения, как будто управление данными полностью осуществляется одной СУБД, работающей на отдельной машине. Такая возможность может показаться невероятно трудной задачей, но весьма желанной с практической точки зрения; ну а производители напряженно работают, чтобы сделать подобные системы реальностью. (Подробнее распределенные базы данных рассматривается далее в этой книге.)