

Микропроцессорная техника Раздел 2. Универсальные микропроцессоры и микроконтроллеры
Стековая архитектура. Данная архитектура основана на базе стека (стековой памяти).
Стековое ЗУ состоит из множества логически взаимосвязанных ячеек, взаимодействующих по принципу «последним вошел, первым вышел» (LIFO, Last In First Out). Ячейки образуют одномерный массив, в котором соседние ячейки связаны друг с другом разрядными цепями передачи слов. Слова становятся доступными для чтения и записи только в определенном порядке. Каждое хранящееся слово привязано не к конкретной ячейке, а к своему положению относительно других хранящихся слов. Слова могут перемещаться по ячейкам, но при этом сохраняют свою взаимную упорядоченность. Поэтому достаточно обеспечить средства для чтения только определенной ячейки. Конкретное слово считывается в тот момент, когда в процессе перемещения по памяти оно оказывается в ячейке, из которой может производиться чтение. Аналогично достаточно обеспечить средства для записи только в определенную ячейку ЗУ.
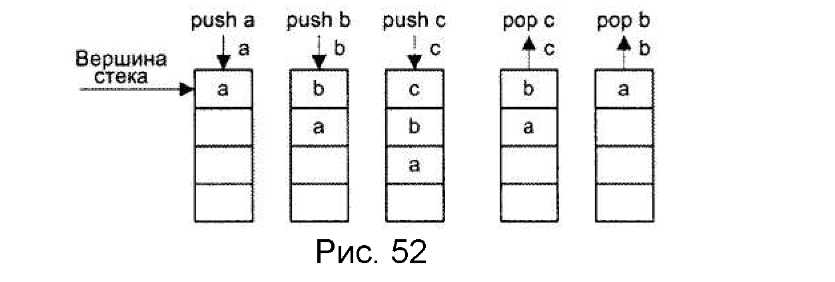
Стек можно представить в виде вертикально расположенного массива ячеек (рис. 52). Доступ осуществляется всегда к верхней ячейке, которая называется вершиной стека.
Для работы со стеком предусмотрены две операции: push (проталкивание данных в стек) и pop (выталкивание данных из стека). Запись возможна только в верхнюю ячейку стека, при этом вся хранящаяся в стеке информация предварительно проталкивается на одну позицию вниз. Чтение допустимо также
У
только из вершины стека. Извлеченная информация удаляется из стека, а оставшееся его содержимое продвигается вверх.
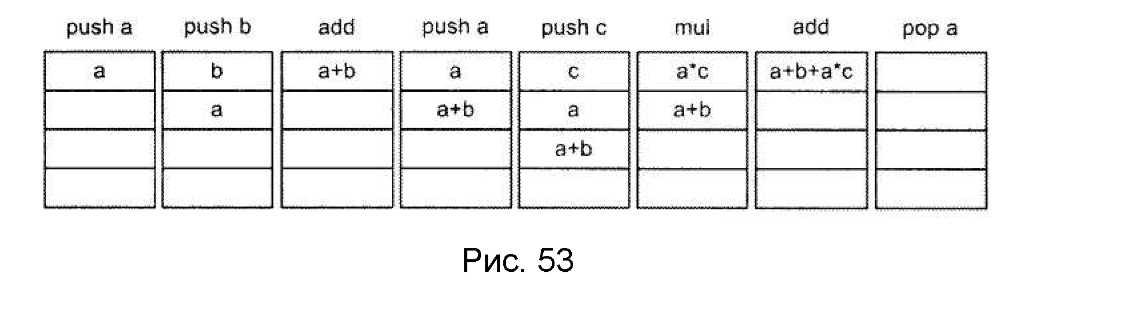
При описании вычислений с использованием стека обычно используется форма записи математических выражений, известная как обратная польская запись (обратная польская нотация), которую предложил польский математик Я. Лукашевич. Особенность ее в том, что в выражении отсутствуют скобки, а знак операции располагается не между операндами, а следует за ними (постфиксная форма). Запись математических выражений с использованием обратной польской нотации производится по следующему правилу. Исходное выражение просматривается слева направо и последовательно друг за другом выписываются встречающиеся операнды. Как только все операнды некоторой операции выписаны, записывается знак этой операции и продолжается запись операндов. Если операндом некоторой операции является результат предыдущей операции и ее знак выписан, считается что этот операнд выписан.
Принцип действия стекового процессора поясним на примере вычисления выражения a = a + b + a x c. Это выражение в польской записи имеет вид: а = ab+acx+. Данная форма записи не содержит скобок и однозначно определяет порядок загрузки операндов в стек и порядок выполнения операций (рис. 53), т. е. может рассматриваться как программа вычисления исходного математического выражения, если под буквами понимать команды загрузки соответствующих операндов в стек (такие команды содержат только адрес операнда в основной памяти), а под знаками операций — безадресные команды, содержащие только коды операций. Эти безадресные команды инициируют извлечение из стека двух (или одного) операндов, выполнение над ними указанной в команде операции и засылку результата в вершину стека.
И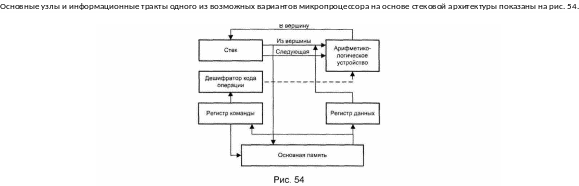 нформация
может быть занесена в вершину стека из
памяти или из АЛУ. Для записи в стек
содержимого ячейки памяти с адресом x
выполняется
команда push
х, по
которой информация считывается из
ячейки памяти, заносится в регистр
данных, а затем проталкивается в стек.
Результат операции из АЛУ заносится в
вершину стека автоматически.
нформация
может быть занесена в вершину стека из
памяти или из АЛУ. Для записи в стек
содержимого ячейки памяти с адресом x
выполняется
команда push
х, по
которой информация считывается из
ячейки памяти, заносится в регистр
данных, а затем проталкивается в стек.
Результат операции из АЛУ заносится в
вершину стека автоматически.
Сохранение содержимого вершины стека в ячейке памяти с адресом х производится командой pop х. По этой команде содержимое верхней ячейки стека подается на шину, с которой и производится запись в ячейку х, после чего вся находящаяся в стеке информация проталкивается на одну позицию вверх.
Для выполнения арифметической или логической операции на вход АЛУ подается информация, считанная из двух верхних ячеек стека (при этом содержимое стека продвигается на две позиции вверх, то есть операнды из стека удаляются). Результат операции заталкивается в вершину стека. Возможен вариант, когда результат сразу же переписывается в память с помощью автоматически выполняемой операции pop x.
Верхние ячейки стековой памяти, где хранятся операнды и куда заносится результат операции, как правило, делаются более быстродействующими и размещаются в процессоре, в то время как остальная часть стека может располагаться в основной памяти.
К достоинствам стековой архитектуры следует отнести возможность предельного сокращения адресной части команд, поскольку все операции производятся через вершину стека, т. е. адреса операндов и результата в командах арифметической и логической обработки информации указывать не нужно. Поэтому код программы получается компактным, что экономит память. Достаточно просто реализуется декодирование команд, что способствуют повышению производительности микропроцессора. Однако при такой структуре команд возникают осложнения с построением команд передачи управления и работы с портами ввода/вывода. Кроме того, стековая архитектура по определению не предполагает произвольного доступа к памяти, из-за чего компилятору трудно создать эффективный программный код, хотя создание самих компиляторов упрощается. Поэтому организация вычислений с использованием стековой памяти нашла применение только в специализированных микропроцессорах.
2. Форматы команд 32-разрядных процессоров фирмы Intel Набор команд, реализуемый 32-разрядными процессорами фирмы Intel, обеспечивает выполнение операций над операндами, которые находятся в регистре, памяти или непосредственно в команде. Операнды могут содержать 8, 16 или 32 разряда. В набор входят безадресные, одно- и двухадресные команды. Процессор реализует следующие типы двухадресных команд:
регистр - регистр;
память - регистр;
непосредственные данные - регистр;
регистр - память;
непосредственные данные - память.
Общий формат команды содержит следующие поля (рис. 55):
COP - код операции;
MDR/M, SIB - байты адресации;
DISP - байты смещения;
IMM - непосредственно заданный операнд.
COP (1 или 2 байта) |
MDR/M (0 или 1 байт) |
SIB (0 или 1 байт) |
DISP (0, 1, 2 или 4 байта) |
IMM (0, 1, 2 или 4 байта) |
Гис. 55
Для конкретной команды отдельные поля могут иметь различное число байт или вообще отсутствовать. Поэтому команды могут содержать от 1 до 12 байт. Перед кодом операции в ряде случаев вводятся один или несколько префиксных байтов, модифицирующих выполняемую команду.
Код операции COP занимает 1 или 2 байта. Во многих командах пересылок, а также в логических и арифметических командах первый байт COP содержит разряд w, значение которого определяет разрядность операндов: w =0- операция с байтами; w = 1 - операция со словами (16 или 32 разряда). Разрядность слов (16 или 32 разряда) определяется режимом работы процессора. В реальном режиме и режиме виртуального 8086 по умолчанию используются 16-разрядные слова. В защищенном режиме разрядность устанавливается значением разряда D в дескрипторе сегмента кодов (при D = 0 - 16 разрядов, при D = 1 - 32 разряда). При выполнении отдельных команд разрядность операндов может меняться соответствующим префиксом.
В ряде команд первый байт COP содержит поля reg или sreg, определяющие выбор используемых регистров. Трехразрядное поле reg задает выбираемый регистр общего назначения в соответствии с разрядностью обрабатываемых операндов. Поле sreg определяет выбор сегментного регистра.
Байт адресации MDR/M содержит три поля (рис. 56). Поля MD и R/M задают адрес одного из операндов, который может храниться в регистре или ячейке памяти. Кодировка этих полей определяет выбираемый способ адресации.
7 |
|
6 5 3 |
2 |
0 |
|
||
|
MD |
REG/СОР |
R/M |
MDR/M |
|||
|
SS |
INDEX |
BASE |
SIB |
|||
|
|
Гис. 56 |
|
|
|||
В одноадресных командах поле REG/COP содержит дополнительные разряды кода операции. В двухадресных командах поле REG содержит код регистра, в котором хранится второй из операндов. Тип команды (одно- или двухадресная)
определяется первым разрядом COP. При этом в COP содержится разряд d, который задает выбор операндов, используемых в качестве источника и приемника информации при выполнении ряда двухадресных арифметических и логических операций:
d = 0 - код источника содержится в поле REG/COP, код приемника в поле R/M;
d = 1 - код источника содержится в поле R/M, код приемника в поле REG/COP. Эффективный адрес операнда ЕА является 16- и 32-разрядным и
формируется в зависимости от значения полей MD и R/M в байте адресации MDR/M. В общем случае ЕА образуется путем арифметического сложения трех компонент:
содержимого базового регистра;
содержимого индексного регистра;
8-, 16- или 32-разрядного смещения d8, d16 или d32, заданного в одном, двух или четырех байтах поля DISP команды.
В зависимости от значения полей MD и R/M для формирования ЕА используются все или часть этих слагаемых.
Для реализации ряда способов адресации при формировании 32-разрядного адреса используется байт SIB (Scale Index Base). Он содержит 3-разрядные поля INDEX и BASE, определяющие выбор регистров, используемых в качестве индексного и базового регистров, и поле SS, задающее масштабный коэффициент для модификации значения индекса. Правило формирования эффективного адреса при использовании байта SIB определяется следующим выражением:
EA = BR + (IR х F) + disp,
где BR - содержимое базового регистра, который задается полем BASE; (IR х F) -масштабированный индекс; IR - содержимое индексного регистра, который задается полем INDEX; F - масштабный коэффициент, значение которого определяется полем SS (1, 2, 4 или 8; задает размер элемента данных). В качестве базового регистра может использоваться любой из регистров общего назначения, в качестве индексного регистра также может использоваться любой из регистров общего назначения, кроме указателя стека ESP.
При выполнении операций с непосредственной адресацией один из операндов imm задается в последних байтах команды (поле IMM). В этом случае COP ряда команд содержит бит s, определяющий способ использования непосредственно задаваемых данных. Если операция выполняется над байтами (COP команды содержит разряд w = 0), то в качестве операнда используется один байт непосредственных данных im8, содержащихся в формате команды. Если операция выполняется над 16- или 32-разрядными словами (в COP команды разряд w = 1 или отсутствует), то возможны следующие варианты. При s = 0 непосредственные данные содержат два im16 или четыре im32 байта. При s = 1 непосредственные данные содержат один младший байт 16- или 32-разрядного операнда, остальные разряды которого принимают значение старшего (знакового) разряда младшего байта (расширение знаком).
3. Регистровые структуры универсальных микропроцессоров Функциональная неоднородность регистров. Количество и назначение регистров зависит от архитектуры микропроцессора. Часть регистров микропроцессора не используется в качестве средств программирования. Это объясняется не их физическим отсутствием, а тем, что программисту не предоставляются средства изменения содержимого этих регистров. Такие регистры называются программно недоступными. Для другой части регистров микропроцессора программисту предоставляются средства изменения их
содержимого. Такие регистры называются программно доступными. Они образуют регистровую область микропроцессора.
Регистровую область или набор программно доступных регистров можно рассматривать как скоростное ОЗУ малой емкости, входящее в состав микропроцессора. Этот набор регистров используется для временного хранения данных, адресной информации, информации о состоянии микропроцессора и управляющей информации, контролируемых программистом. Короткая адресация регистровой области и быстрый доступ к ней обеспечивают создание эффективно исполняемых программ.
Регистры микропроцессора функционально неоднородны:
одни служат для хранения данных и/или адресной информации;
другие - для управления работой микропроцессора.
В соответствии с этим все регистры микропроцессора можно разделить на
регистры данных;
указатели или адресные регистры;
регистры специального назначения или специальные регистры.
Регистры данных участвуют в арифметических и логических операциях в качестве источников операндов и приемников результата, адресные регистры используются для вычисления данных и команд, расположенных в основной памяти. Специальные регистры служат для индикации текущего состояния микропроцессора и управления режимами его работы. Часть регистров может использоваться для хранения как операндов, так и адресов. Их называют регистрами общего назначения (РОН).
Функциональная неоднородность регистров микропроцессора связана с широким использованием неявной (подразумеваемой) адресации регистров, которая, в свою очередь, определяется стремлением к созданию коротких программ. В то же время функциональная специализация регистров затрудняет программирование, так как требует учета особенностей организации регистрового набора, присущих данному микропроцессору. Однако в результате программа выполняется быстрее и для ее хранения требуется меньше памяти.
На уровне символической записи (мнемоники) команд для прямой ссылки на конкретные регистры микропроцессора им присваиваются имена, например, A, B, C, D, SP, X или R0, R1, R2 и т.д. Обычно эти имена отражают функциональное назначение регистра и способствуют пониманию мнемоники команд.
Адресные регистры. Адресные регистры применяются для реализации различных методов непрямой (вычисляемой) адресации данных. К ним относятся (рис. 57):
регистр косвенного адреса DP (Data Pointer). Содержит непосредственно адрес операнда;
базовый регистр (регистр базы) BP (Base Pointer). Используется для хранения начального адреса массива;
индексный регистр X. Содержит относительный (по отношению к базе) адрес (индекс) операнда (элемента массива);
регистры автоинкрементной и автодекрементной адресации. Автоматически увеличивают или уменьшают свое содержимое до или после выполнения операции доступа в соответствии с длиной адресуемого ими операнда;
регистр расширения адресного пространства. Обеспечивает расширение адресного пространства путем переключения между несколькими банками основной памяти. Содержит номер текущего банка основной памяти;
указатели сегментов и страниц.
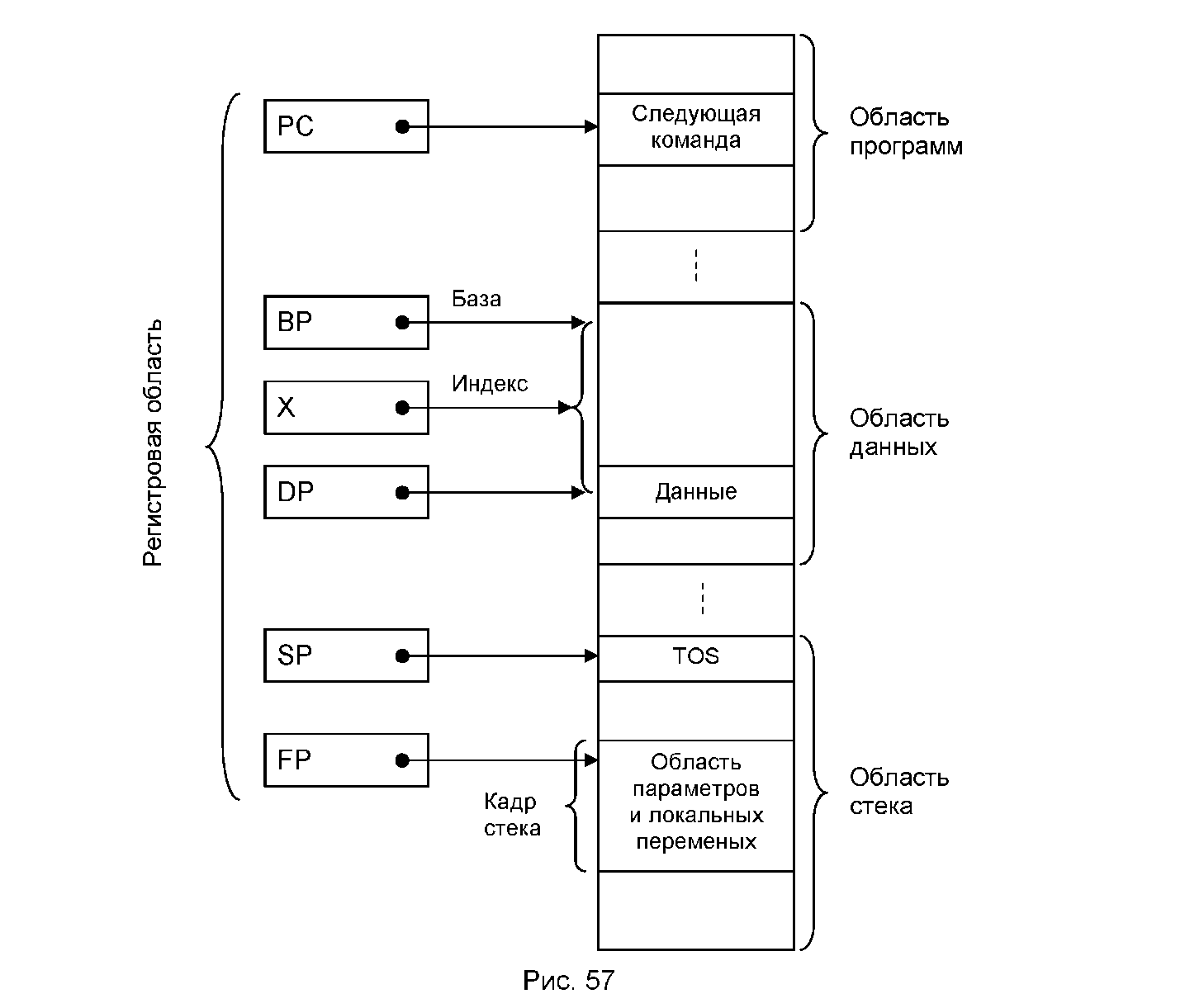
К классу адресных регистров с автоинкрементированием относится программный счетчик (счетчик команд, указатель команд) PC (Program Counter), содержимое которого после очередной выборки элемента командной последовательности увеличивается на длину этого элемента. За счет использования такого регистра в микропроцессоре процесс адресации следующего элемента командной последовательности в основном осуществляется неявно и автоматически. Изменение последовательности процесса выборки команд осуществляется специальными командами передачи управления, связанными с загрузкой в PC адреса, отличного от адреса следующей команды.
Частным случаем регистра с автомодификацией является указатель стека SP (Stack Pointer), который указывает на положение вершины стека.
При использовании стека для хранения локальных переменных и обмена параметрами между вызываемой и вызывающей процедурами может оказаться полезным специальный адресный регистр, указывающий на начало области локальных переменных и/или параметров в стеке, - указатель кадра FP (Frame Pointer). Значение указателя стека SP непрерывно меняется, поэтому применять его в качестве точки отсчета при доступе к данным в стеке неудобно. Процедуру доступа можно значительно упростить, если функцию точки отсчета отдать специально
зарезервированному для этой цели регистру - указателю кадра FP. Указатель кадра относится к классу базовых регистров.
Специальные регистры. При выполнении операций АЛУ генерирует ряд признаков, характеризующих их результат. Функцию хранения этих признаков, а также некоторых других выполняет специальный регистр состояния SR (Status Register) или слова состояния программы PSW (Program Status Word). С каждым признаком связывается одноразрядная переменная - флажок. Флажки, связанные с признаками результата операции, группируются в поле кода условия CC (Condition Code). Типовой состав флажков-признаков результата операции:
CF (Carry Flag) - флажок переноса из старшего разряда АЛУ при выполнении арифметических операций. При сдвигах CF равен выдвинутому значению младшего или старшего разряда;
ZF (Zero Flag) - флажок признака нуля;
SF (Sign Flag) - флажок знака результата. SF равен значению старшего разряда результата;
AF (Auxiliary carry Flag) - флажок дополнительного переноса (переноса из младшей тетрады);
OF (Overflow Flag) - флажок арифметического переполнения;
PF (Parity Flag) - флажок четности количества единичных разрядов в результате.
Удобно в поле кода условия CC иметь один или несколько флажков пользователя, функциональное назначение которых определяет он сам. Обычно эти флажки служат для связи между отдельными частями программы.
Состояние поля кода условия CC тестируется командами условного типа.
В состав PSW входит также ряд специальных флажков, управляющих работой микропроцессора, например: