

3.3.2. Распределение параметров
Хотя
требуемая плотность p(х)
неизвестна, предположим, что она имеет
известную параметрическую форму.
Единственно, что предполагается
неизвестным, это величина параметрического
вектора
![]() .
Тот факт, что р(х)
неизвестна, но имеет известный
параметрический вид, выразим
утверждением, что функция p(x|
.
Тот факт, что р(х)
неизвестна, но имеет известный
параметрический вид, выразим
утверждением, что функция p(x|![]() )
полностью известна. При байесовском
подходе предполагается, что неизвестный
параметрический вектор есть случайная
переменная. Всю информацию о
)
полностью известна. При байесовском
подходе предполагается, что неизвестный
параметрический вектор есть случайная
переменная. Всю информацию о
![]() до наблюдения выборок дает известная
априорная плотность p(
до наблюдения выборок дает известная
априорная плотность p(![]() ).
Наблюдение выборок превращает ее в
апостериорную плотность p(
).
Наблюдение выборок превращает ее в
апостериорную плотность p(![]() |
|![]() ),
которая, как можно надеяться, имеет
крутой подъем вблизи истинного значения
),
которая, как можно надеяться, имеет
крутой подъем вблизи истинного значения
![]() .
.
Основная
наша цель—это
вычисление плотности p(x|![]() ),
достаточно достоверной для того,
чтобы прийти к получению неизвестной
p(х).
Это вычисление мы выполняем посредством
интегрирования объединенной плотности
р(х,
),
достаточно достоверной для того,
чтобы прийти к получению неизвестной
p(х).
Это вычисление мы выполняем посредством
интегрирования объединенной плотности
р(х,
![]() |
|![]() )
по
)
по
![]() .
Получаем
.
Получаем
![]() =
=![]()
причем
интегрирование производится по всему
пространству параметра 6.
Теперь р(х,
![]() |
|![]() )
всегда можно представить как произведение
р(х,
)
всегда можно представить как произведение
р(х,
![]() |
|![]() )
)![]() .
Так как х и выборки из
.
Так как х и выборки из
![]() получаются независимо, то первый
множитель есть просто p(x|
получаются независимо, то первый
множитель есть просто p(x|![]() ).
Распределение величины
х, таким
образом, полностью известно, если
известна величина параметрического
вектора. В результате имеем
).
Распределение величины
х, таким
образом, полностью известно, если
известна величина параметрического
вектора. В результате имеем
p(x|![]() )
=
)
=
![]() (14)
(14)
Это
важнейшее уравнение связывает «условную
по классу» плотность p(x|![]() )
с апостериорной плотностью p(
)
с апостериорной плотностью p(![]() |
|![]() )
неизвестного параметрического
вектора. Если вблизи некоторого значения
)
неизвестного параметрического
вектора. Если вблизи некоторого значения
![]() функция p(
функция p(![]() |
|![]() )
имеет острый пик, то p(x|
)
имеет острый пик, то p(x|![]() )
p(x|
)
p(x|![]() ),
так что решение может быть получено
подстановкой оценки
),
так что решение может быть получено
подстановкой оценки
![]() в качестве истинной величины вектора
параметров. Вообще, если существует
большая неопределенность
относительно точного значения
в качестве истинной величины вектора
параметров. Вообще, если существует
большая неопределенность
относительно точного значения
![]() ,
это уравнение приводит к средней
плотности p(x\
,
это уравнение приводит к средней
плотности p(x\![]() )
по возможным значениям
)
по возможным значениям
![]() .
Таким
образом, в случае, когда неизвестные
плотности имеют известный
параметрический вид, выборки влияют
на p(x\
.
Таким
образом, в случае, когда неизвестные
плотности имеют известный
параметрический вид, выборки влияют
на p(x\![]() )
через апостериорную плотность р(
)
через апостериорную плотность р(![]() |
|![]() ).
).
3.4. Обучение при восстановлении среднего значения нормальной плотности
3.4.1. Случай одной переменной: p(|)
В
данном разделе мы рассмотрим вычисление
апостериорной плотности p(![]() |
|![]() )
и требуемой плотности р(x|
)
и требуемой плотности р(x|![]() )
для случая, когда р(x
|
)
для случая, когда р(x
|![]() )~N(
)~N(![]() ,
,![]() ),
а вектор среднего значения
),
а вектор среднего значения![]() есть
неизвестный вектор параметров. Для
простоты начнем с одномерного случая,
при котором
есть
неизвестный вектор параметров. Для
простоты начнем с одномерного случая,
при котором
р(x
|![]() )~N(
)~N(![]() ,
,![]() ), (15)
), (15)
где
единственной неизвестной величиной
является среднее значение
![]() .
Предположим, что любое исходное знание,
которое мы можем иметь о
.
Предположим, что любое исходное знание,
которое мы можем иметь о![]() ,
можно выразить посредствомизвестной
априорной плотности р(
,
можно выразить посредствомизвестной
априорной плотности р(![]() ).
Кроме того, можно предположить, что
).
Кроме того, можно предположить, что
p(![]() )~N(
)~N(![]() ,
,![]() ),
(16)
),
(16)
где
![]() и
и
![]() известны. Грубо говоря, величина
известны. Грубо говоря, величина![]() есть наше лучшее исходное предположение
относительно
есть наше лучшее исходное предположение
относительно![]() ,
а
,
а![]() отражает неуверенность в отношении
этого предположения. Предположение о
том, что априорное распределение для
отражает неуверенность в отношении
этого предположения. Предположение о
том, что априорное распределение для
![]() нормальное, в дальнейшем упростит
математические выражения. Однако
решающее предположение заключается
не столько в том, что априорное
распределение
нормальное, в дальнейшем упростит
математические выражения. Однако
решающее предположение заключается
не столько в том, что априорное
распределение![]() нормально, сколько в том, что оно
существует и известно.
нормально, сколько в том, что оно
существует и известно.
Выбрав
априорную плотность для
![]() ,
можно представить ситуацию следующим
образом. Вообразим, что величина
,
можно представить ситуацию следующим
образом. Вообразим, что величина
![]() ,
получена из множества, подчиняющегося
вероятностному закону р(
,
получена из множества, подчиняющегося
вероятностному закону р(![]() ).
Будучи однажды получена, эта величина
представляет истинное значение
).
Будучи однажды получена, эта величина
представляет истинное значение
![]() и полностью
определяет плотность для х.
Предположим теперь, что из полученного
множества независимо взято п
выборок x1,
. . . , xn.
Положив
и полностью
определяет плотность для х.
Предположим теперь, что из полученного
множества независимо взято п
выборок x1,
. . . , xn.
Положив
![]() ={x1,
. .
. , xn},
воспользуемся байесовским правилом,
чтобы получить выражение
={x1,
. .
. , xn},
воспользуемся байесовским правилом,
чтобы получить выражение
![]() (17)
(17)
где
![]() — масштабный
множитель, зависящий от
— масштабный
множитель, зависящий от
![]() ,
но не зависящий от
,
но не зависящий от
![]() .
Из этого уравнения видно, как наблюдение
выборочного множества влияет на
наше представление об истинном значении
.
Из этого уравнения видно, как наблюдение
выборочного множества влияет на
наше представление об истинном значении
![]() ,
«превращая»
априорную плотность р(
,
«превращая»
априорную плотность р(![]() )
в апостериорную плотностьp(
)
в апостериорную плотностьp(![]() |
|![]() ).
Так как
p(xk|
).
Так как
p(xk|![]() )N(
)N(![]() ,
,![]() )
иp(
)
иp(![]() )N(
)N(![]() ,
,![]() )
то имеем
)
то имеем
 (18)
(18)
где
множители, не зависящие от
![]() ,
включены в константы
,
включены в константы
![]() и
и![]() .
Таким
образом, p(
.
Таким
образом, p(![]() |
|![]() ),
представляющая собой экспоненциальную
функцию квадратичной функции от
),
представляющая собой экспоненциальную
функцию квадратичной функции от
![]() ,
также является нормальной плотностью.
Так как это остается в силе для любого
числа выборок, тоp(
,
также является нормальной плотностью.
Так как это остается в силе для любого
числа выборок, тоp(![]() |
|![]() )
остается нормальной, когда число п
выборок возрастает, и p(
)
остается нормальной, когда число п
выборок возрастает, и p(![]() |
|![]() )
называют воспроизводящей
плотностью.
Если воспользоваться p(
)
называют воспроизводящей
плотностью.
Если воспользоваться p(![]() |
|![]() )~N(
)~N(![]() ,
,![]() ),
то значения
),
то значения![]() и
и![]() могут быть найдены приравниванием
коэффициентов из уравнения
(18)
соответствующим коэффициентам из
выражения
могут быть найдены приравниванием
коэффициентов из уравнения
(18)
соответствующим коэффициентам из
выражения
p(![]() |
|![]() )
=
)
= (19)
(19)
Отсюда получаем
![]() (20)
(20)
и
![]() ,
(21)
,
(21)
где mn есть выборочное среднее
![]() .
(22)
.
(22)
Решая
уравнения в явном виде относительно
![]() и
и![]() ,
получаем
,
получаем
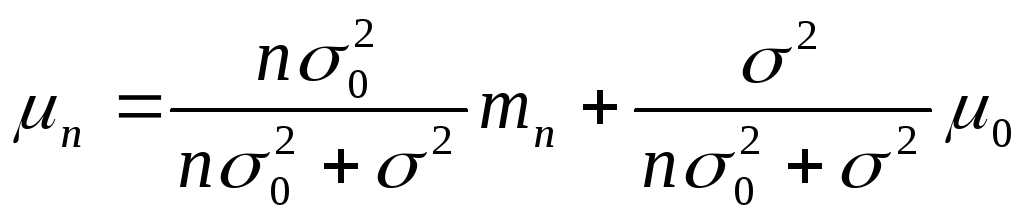 (23)
(23)
и
 .
(24)
.
(24)
Из
этих уравнений видно, как комбинация
априорной информации и эмпирической
информации выборок дает апостериорную
плотность p(![]() |
|![]() ).
Грубо говоря,
).
Грубо говоря,
![]() представляет
наше лучшее предположение относительно
представляет
наше лучшее предположение относительно
![]() после наблюдения п
выборок, а
после наблюдения п
выборок, а
![]() отражает нашу неуверенность относительно
этого предположения. Так как
отражает нашу неуверенность относительно
этого предположения. Так как
![]() монотонно убывает с ростом
n,
стремясь к
монотонно убывает с ростом
n,
стремясь к
![]() /п
при стремлении п
к бесконечности,
каждое добавочное наблюдение уменьшает
нашу неуверенность
относительно истинного значения
/п
при стремлении п
к бесконечности,
каждое добавочное наблюдение уменьшает
нашу неуверенность
относительно истинного значения
![]() .
При возрастании п.
функция p(
.
При возрастании п.
функция p(![]() |
|![]() )
все более заостряется, стремясь к
дельта-функции при n.
Такое поведение обычно называется
байесовским
обучением
(рис.
3.2).
)
все более заостряется, стремясь к
дельта-функции при n.
Такое поведение обычно называется
байесовским
обучением
(рис.
3.2).

Рис. 3.2. Обучение среднему при нормальной плотности.
Вообще
![]() представляет
линейную комбинациюmn
и
представляет
линейную комбинациюmn
и
![]() с неотрицательными коэффициентами,
сумма которых равна единице. Поэтому
значение
с неотрицательными коэффициентами,
сумма которых равна единице. Поэтому
значение
![]() , всегда
лежит между mn
и
, всегда
лежит между mn
и
![]() .
При
.
При![]() величина
величина![]() стремится к выборочному среднему при
стремлениип
к бесконечности.
Если
стремится к выборочному среднему при
стремлениип
к бесконечности.
Если
![]() ,
то получаем вырожденный случай, при
котором априорная уверенность в том,
что
,
то получаем вырожденный случай, при
котором априорная уверенность в том,
что
![]() =
=![]() ,
настолько тверда, что никакое число
наблюдений не сможет изменить нашего
мнения. При другой крайности, когда
,
настолько тверда, что никакое число
наблюдений не сможет изменить нашего
мнения. При другой крайности, когда![]()
![]() ,
мы настолько не уверены в априорном
предположении, что принимаем
,
мы настолько не уверены в априорном
предположении, что принимаем![]() =mn
, исходя при оценке
=mn
, исходя при оценке
![]() только из выборок. Вообще относительный
баланс между исходным представлением
и опытными данными определяется
отношением
только из выборок. Вообще относительный
баланс между исходным представлением
и опытными данными определяется
отношением![]() к
к
![]() ,
называемым иногдадогматизмом.
Если догматизм не бесконечен, то
после получения достаточного числа
выборок предполагаемые конкретные
значения
,
называемым иногдадогматизмом.
Если догматизм не бесконечен, то
после получения достаточного числа
выборок предполагаемые конкретные
значения
![]() и
и![]() не играют роли, а
не играют роли, а![]() стремится к выборочному среднему.
стремится к выборочному среднему.