

3.2 Простая экспоненциальная модель.
Основное различие между этой моделью и моделью Джелинского-Моранды, рассмотренной в предыдущем разделе, в том, что эта модель не использует предположение 6, и, таким образом, допускает, что функция риска может меняться между моментами обнаружения ошибок, то есть она больше не является константой на этих интервалах. Пусть N(t) – число ошибок, обнаруженных к моменту времени, и пусть функция риска пропорциональна количеству ошибок, оставшихся в программе после момента t.

Продифференцируем обе части этого уравнения по времени:
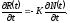
Учитывая,
что
 - это R(t) (количество ошибок, обнаруживаемых
в единицу времени), получаем дифференциальное
уравнение для R(t)
- это R(t) (количество ошибок, обнаруживаемых
в единицу времени), получаем дифференциальное
уравнение для R(t)
 (3.10)
(3.10)
Если рассмотреть начальные значения N(0)=0, R(0)=KB, то решением уравнения (3.10) будет
 (3.11)
(3.11)
Обозначим: a = ln (KB); b = - K.
Решением уравнения (3.11) будет
 (3.12)
(3.12)
 (3.13)
(3.13)
 (3.14)
(3.14)
3.3. Модель Шика-Уолвертона.
Эта модель основана на предположении, что функция риска пропорциональна не только количеству ошибок в программе, но и продолжительности процесса тестирования. Кроме того, предполагается, что чем дольше ПО тестируется, тем больше появляется шансов на обнаружение последующих ошибок, поскольку в процессе отладки некоторые участки программы “подчищаются”, что облегчает ее дальнейшее тестирование.
Модель основана на следующих предположениях:
Все ошибки в программе равновероятны и независимы друг от друга.
Все ошибки считаются одинаково серьезными.
Исправление ошибок происходит без внесения в программу новых ошибок.
Функция риска для данной модели:

В
этой формуле Xi - время между моментом
 обнаружения (i-1)-й ошибки до текущего
момента
обнаружения (i-1)-й ошибки до текущего
момента .
.
Вероятность безотказного функционирования программы на интервале Xi равна:
 ,
,
что дает плотность вероятности отказа

3.4. Модели Липова.
Эти модели являются обобщением моделей Джелинского-Моранды и Шика-Уолвертона. В отличие от этих моделей, модели Липова допускают более одной ошибки в интервале тестирования, и кроме того, допускают, что не все из ошибок, обнаруженных а этом интервале, могут быть исправлены. Первая модель Липова (обобщение модели Джелинского-Моранды) основана на следующих предположениях:
Все ошибки равновероятны и независимы друг от друга.
Все ошибки считаются одинаково серьезными.
Интенсивность обнаружения ошибок постоянна на всем интервале тестирования.
На i-том интервале тестирования обнаруживается
 ошибок, но только
ошибок, но только из них исправляется.
из них исправляется.
Последнее
предположение значительно отличает
данную модель от всех моделей, рассмотренных
ранее. Таким образом, функция риска
определяется следующим выражением:
 где
где
 -
общее количество ошибок, исправленных
к моменту времени
-
общее количество ошибок, исправленных
к моменту времени ,
а
,
а - это время окончания i-го интервала
тестирования (измеренное обычным
способом или таймером процессора). Еще
одно отличие данной модели от модели
Джелинского-Моранды в том, что интервалы
- это время окончания i-го интервала
тестирования (измеренное обычным
способом или таймером процессора). Еще
одно отличие данной модели от модели
Джелинского-Моранды в том, что интервалы фиксированные, а не произвольные.
фиксированные, а не произвольные.
Вторая модель Липова (обобщение модели Шика-Уолвертона) основана на следующих предположениях. Интенсивность обнаружения ошибок пропорциональна текущему количеству ошибок в ПО и общему времени, затраченному на его тестирование, включая также “среднее” время поиска ошибки, обнаруженной на интервале тестирования. С учетом этих предположений, функция риска задается следующим выражением:
 (3.15)
(3.15)
где
 - общее количество ошибок, исправленных
к моменту времени
- общее количество ошибок, исправленных
к моменту времени .
Формула (3.15)
отличается от первой модели Липова
вторым множителем -
.
Формула (3.15)
отличается от первой модели Липова
вторым множителем -
 ,
отражающем изменение интервала
тестирования.
,
отражающем изменение интервала
тестирования.