

3.5. Геометрические модели.
В этом разделе рассмотрен пример геометрической модели, предложенной П. Б. Морандой и являющейся модификацией модели Джелинского-Моранды.
Модель основана на предположении, что начальное количество ошибок в программе B не является фиксированным значением (не ограничено), более того, не все ошибки встречаются с одинаковой вероятностью. Также предполагается, что чем дольше длится процесс отладки ПО, тем труднее становится обнаруживать в нем ошибки, и , таким образом, ПО никогда полностью не освобождается от ошибок. Основные предположения в этой модели следующие.
Общее количество ошибок в программе неограниченно;
Ошибки встречаются с разной вероятностью;
Процесс обнаружения ошибок не зависит от самих ошибок;
Интенсивность обнаружения ошибок изменяется по закону геометрической прогрессии, но между моментами обнаружения ошибок интенсивность постоянна.
Исходя из этих предположений, функцию риска можно записать следующим выражением:
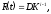
где t – временной интервал между обнаружением (i-1)-ой и i-той ошибок. Начальное значение этой функции R(0) = D, и функция риска убывает со скоростью геометрической прогрессии (0<K<1) по ходу процесса обнаружения ошибок. Скорость изменения R(t) пропорциональна инвертированному значению константы K:

что
приводит к убыванию шага изменения R(t)
в процессе обнаружения ошибок. Таким
образом, более поздние ошибки труднее
обнаружить, и они оказывают меньшее
влияние на уменьшение потока ошибок,
чем предыдущие ошибки. Если снова
положить
 (временной интервал между обнаружением
(i-1)-ой и i-той ошибок), тогда, согласно
второму и третьему предположению, Xi
распределены экспоненциально с плотностью
распределения
(временной интервал между обнаружением
(i-1)-ой и i-той ошибок), тогда, согласно
второму и третьему предположению, Xi
распределены экспоненциально с плотностью
распределения

Эта модель не позволяет определить, сколько ошибок осталось в ПО, но с ее помощью можно найти его "уровень чистоты". “Уровень чистоты” - это отношение
 (3.16)
(3.16)
Оценка
максимального правдоподобия для этого
значения будет

3.6. Модель Шнейдевинда.
Эта
модель основана на подходе, что чем
позже встречаются ошибки, тем большее
значение они имеют для процесса
предсказания ошибок в программе.
Предположим, что есть m интервалов
тестирования, и пускай на i-том
интервале обнаружено
 ошибок. Тогда возможно три различных
подхода:
ошибок. Тогда возможно три различных
подхода:
Использовать данные об ошибках на всех интервалах;
Не рассматривать данные об ошибках, обнаруженных на первых (s-1) интервалах, и использовать только данные с s-того по m-тый;
Использовать суммарное количество ошибок, обнаруженных с первого по (s-1)-ый интервал, т.е.
 ,
и отдельные ошибки с s-того по m-тый
интервалы.
,
и отдельные ошибки с s-того по m-тый
интервалы.
Подход 1 предлагается использовать в тех случаях, когда для предсказания будущего состояния ПО необходимы данные со всех интервалов тестирования. Подход 2 – когда есть причины полагать, что произошел некий перелом в процессе обнаружения ошибок, и только данные последних m – (s-1) интервалов имеет смысл учитывать в прогнозах на будущее. И наконец, подход 3 является компромиссом между первыми двумя подходами.
Модель основана на следующих предположениях:
Количество ошибок на интервале тестирования не зависит от количества ошибок на остальных интервалах;
Количество обнаруженных ошибок убывает от одного интервала к другому;
Все интервалы тестирования имеют одинаковую длину;
Интенсивность обнаружения ошибок пропорциональна количеству ошибок, содержащихся в программе в текущий момент времени.