

Конвейерные конфликты и способы их минимизации

Подобная ситуация наз. конвейерным конфликтом, к-рый интерпретируется невозможностью прочитать r0 (см. стадию 4). r0 будет готов только в конце стадии W(4). Соотв. стадия останавливается (D). Стадия 5: очередной конфликт из-за r3. 2 дополн. стадии явл. необх.
Подобные типы конвейерных конфликтов наз. конфликтами по данным (Data Conflicts/Hazards).
Конфликты по данным бывают нескольких типов. В примере – Read after Write.
2 инструкции i и j, i выполняется перед j.
Write after Write: j пытается записать операнд, прежде чем его запишет i. Запись заканчивается в неправильном порядке.
Write after Read: j пытается записать приёмник, прежде чем его прочитает i. i получает некорректное новое значение.
Read after Write: j пытается прочитать источник, прежде чем i запишет его. j получает некорректное старое значение.
Помимо конфликтов по данным в классич. выч. арх-рах выделяют:
Конфликты по управлению
Структурные конфликты
Структурный конфликт приводит к принудительному простою конвейера из-за структурных аппаратных особенностей выч. ядра.
! Смысл устранения конфликтов – в минимизации выч. процесса по времени.
Решение стр-рных конфликтов: ввести многопортовую память, ставить несколько ALU.
КОНФЛИКТЫ ПО УПРАВЛЕНИЮ
Пример:
PC: add r0,r1,r2
PC+1: call P
PC+2: sub r3,r4,r5
…
P: mul r2,r3,r4
Программы имеют нелинейные участки, к-рые нелинейно изменяют PC. Инструкции наз. инструкциями перехода, к-рые вызывают изменение PC на конкр. значение: например, JUMP PC Address. Есть ещё CALL, IRQ, RET.
CALL:
PUSH PC+1 на вершину стека помещаем PC+1
PC New
Execute если до CALL были конвейерные простои, то конвейер дождётся их выполнения, а потом только CALL. При этом конвейер заново начнёт функционировать при новом значении PC.
RET:
Из стека достаётся старое значение команд, и все ступени конвейера сбрасываются. Конвейер возобновляет работу со стадии F с возвр. значением PC (??).
МЕТОДИКИ ОПТИМИЗАЦИИ ЧИСЛА КОНВЕЙЕРНЫХ КОНФЛИКТОВ
Простои неизбежны в реальных процессорах. Методики минимизации простоев исп. для оптимизации кода по действию.
Прогр. методики осн. на модификации графа вычислительного процесса исполняемого кода:
- пересмотр карты регистров общего назначения
- предсказание переходов
- разворачивание циклов
- inline-функции и т.д.
Пересмотр GPR осн. на пересмотре эквивалентных алгоритмических преобразований либо эквивалентных инструкций.
Конвейерные конфликты и способы их минимизации (продолжение)
Аппаратные методы осн. на внесении структурных преобразований в апп. составляющую соотв. ступеней:
- быстрая пересылка данных (Fast Forwarding)
- использование мультипортовых регистровых файлов (MultiPort REGFILE)
- применение суперскалярных подходов, например, множество ALU (SuperScalar (ALUs))
- Reconfig. Comput.
1. Fast Forwarding
Закл. в модификации ALU, к-рая подразумевает быструю пересылку рез-тирующих данных из RS не только в GPR, но и на один из входов ALU.
Б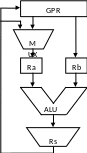 ыстрая
пересылка срабатывает только в момент
потенциального останова след. ступени
и закл. в пересылке рез-та Rs
на один из входов ALU. Тем
самым экономится время, необх. для
исполнения ступени W
(запись рез-та).
ыстрая
пересылка срабатывает только в момент
потенциального останова след. ступени
и закл. в пересылке рез-та Rs
на один из входов ALU. Тем
самым экономится время, необх. для
исполнения ступени W
(запись рез-та).
Наличие быстрой пересылки не отражается на процедуре записи данных в блок регистров GPR. Наличие схемы быстрой пересылки не означает полную ликвидацию простоев и требует совместного использования с прогр. методами оптимизации.
Пример (трансформация кода, Code Transformation):
add r2,r1,r0
add r3,r2,r1
add r4,r3,r1
Получается 10 конв. тактов!
Представим ассемблерный код след. обр.:
r2=r1+r0 r2=r1+r0 r5=3r1, r6=2r1, r2=r1+r0
r3=r2+r1 r3=2r1+r0 r4=r5+r0
r4=r3+r1 r4=3r1+r0 r3=r6+r0
mul r5,r1,3
mul r6,r1,2
add r2,r1,r0
add r4,r5,r0
add r3,r6,r0
Получается 8 ступеней.