

Глава 3. Частотные словари
Для нужд лексико-статистических исследований используются частотные словари. В качестве единиц этих словарей могут быть использованы либо словоформы (агглютинативные конструкции), либо исходные формы слов.
Различаются следующие типы частотных словарей:
1) алфавитно - частотный словарь словоформ и слов;
2) обратно - частотный словарь словоформ и слов;
3) ранговый частотный словарь словоформ и слов.
Алфавитно-частотные словари можно разделить на три вида.
В словаре первого вида при каждом слове может указываться только суммарная частота встречаемости слова или словоформы в исследуемом тексте. Такой частотный словарь будем именовать алфавитно-частотным словарем слов (словоформ).
В словаре второго вида при каждом слове или словоформе могут даваться номера страниц и источников. Такой вид словаря будем называть алфавитно-частотным словарем-словоуказателем (конкордансом).
В словаре третьего вида помимо указания на суммарную частоту и ее распределение по источникам (или страницам) приводится толкование слова. Такой частотный словарь будем называть алфавитно-частотным толковым словарем. К этому виду относятся частотные словари, составленные по произведениям отдельных авторов.
Последние два вида словарей составляются обычно относительно слов.
Частотный словарь, построенный по алфавиту концов слов или словоформ, будем называть обратно - частотным словарем.
Частотный словарь, упорядоченный по убыванию или по возрастанию частот, назовем ранговым частотным словарем слов (словоформ). В дальнейшем вместо термина ранговый частотный словарь будем употреблять термин частотный словарь.
Можно использовать и другие приемы упорядочения лексики, например, упорядочение по длине словоформ или слов.
Основным объектом нашего анализа выступает частотный словарь лексики, который является той статистической моделью, с помощью которой описываются распределения вероятностей отдельных лексических единиц.
В частотных словарях рядом с лексической единицей обычно даются и квантитативные характеристики.
Для исследования статистической структуры текста особо важную роль играет рассмотрение вместо самого частотного словаря лексики его спектров, в которых указаны статистические и информационные характеристики:
1) абсолютная
частота (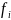 ),
),
2) накопленная
абсолютная частота (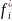 ),
равная сумме частоты
),
равная сумме частоты
данной лексической единицы и им предшествующих абсолютных частот,
3) относительная
частота
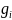 , равная отношению абсолютной частоты
лексической единицы к объему текста N,
, равная отношению абсолютной частоты
лексической единицы к объему текста N,
4) накопленная
относительная частота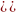 ),
равная отношению накопленной абсолютной
частоты
лексической единицы к объему текста
N,
),
равная отношению накопленной абсолютной
частоты
лексической единицы к объему текста
N,
5) удельная энтропия
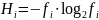 ,
,
6) накопленная энтропия, равная сумме удельных энтропий
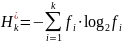 ,
,
7) среднее количество энтропии (информации), приходящееся на словоформу
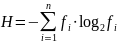 ,
,
8) C – индекс
дистрибуции (чем, эта величина больше,
тем богаче словарь) 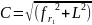
9) Ii – индекс итерации (индекс повторения слов в замкнутом тексте)
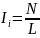
10) Ie – индекс исключительности (специфичности) лексики
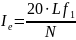
11) P– индекс предсказуемости (чем P меньше, тем привлекательнее текст)
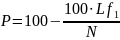 ,
,
где
N – объем текста - число лексических единиц в тексте
L – число лексических единиц в тексте, которые встретились в тексте хотя бы один раз.
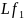 – лексические
единицы, которые встретились в тексте
только один раз
– лексические
единицы, которые встретились в тексте
только один раз