

Использование правил для принятия решений
Построенное множество правил применяется для принятия решения о принадлежности того или иного объекта какому-либо классу. При этом бывают ситуации, когда один и тот же объект подпадает под действие сразу нескольких правил, в том числе правил, описывающих разные классы. Подобные внутренние конфликты могут быть разрешены двумя способами. В первом способе предпочтение отдается одному правилу, имеющему более высокую степень доверия (более высокую точность). Второй способ связан с обобщением результатов разных правил для принятия окончательного решения.
В системе See5 принят второй способ — каждое сработавшее правило подает голос для отнесения какого-либо объекта к изучаемым классам. Голоса суммируются с весами, равными вычисленным степеням доверия, и объект считается принадлежащим к классу, для которого набирается наибольшая взвешенная сумма голосов.
Смягчение порогов
В системе See5 предусмотрена еще одна возможность улучшения качества классификации. Но на сей раз эта возможность касается не столько точности результатов, сколько повышения их устойчивости к возможным флуктуациям значений признаков. Она связана с введением нечетких (мягких) порогов, на сравнении с которыми основывается выбор той или иной ветви дерева решений.
В диалоговом окне для задания параметров алгоритма See5 (см. рис. 2) имеется специальный параметр для смягчения порогов. Это параметр fuzzy thresholds (размытые пороги). При обращении к нему вместо одного порога задается три значения - нижняя граница LB, верхняя граница UB и центральное значение Т. Если значение переменной лежит ниже LB или выше UB, то исследуются соответствующие единственные ветви дерева. Если же значение переменной попадает между LB и UB, то исследуются одновременно две ветви дерева и выбирается наиболее правдоподобный результат классификации. Значения LB, UB и Т система определяет автоматически.
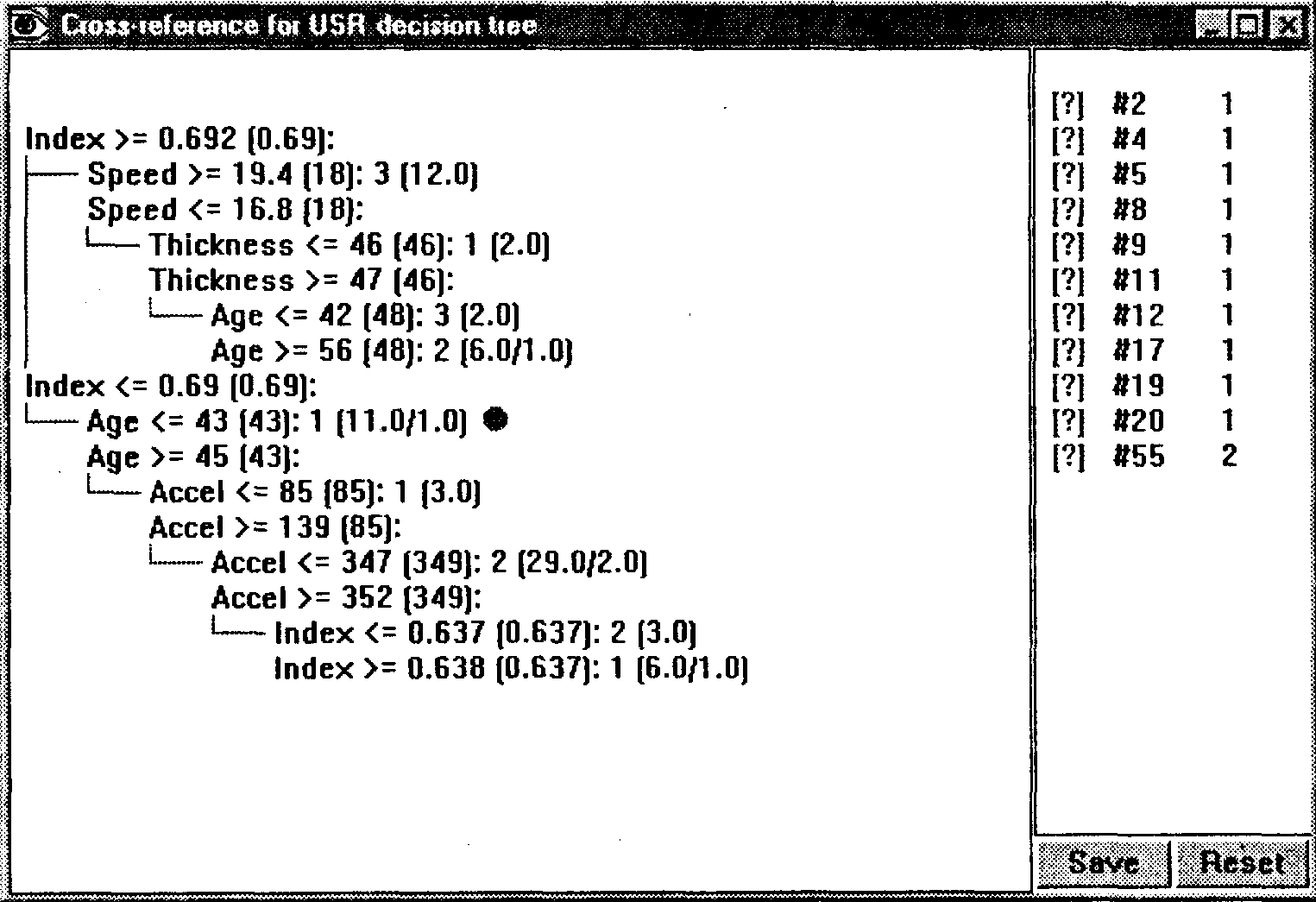
Пример дерева решений с размытыми порогами приведен на рис. 7. Здесь каждый порог представлен в виде <= LB (Т) или >= UB (Т).
Дополнительные настройки алгоритма
В системе See5 предусмотрены параметры для дополнительной настройки алгоритма построения деревьев решений. Они предназначены для пользователя, желающего поэкспериментировать и, возможно, попытаться улучшить найденный результат.
В
Рис.
7. Дерево решений с размытыми порогами
Во-вторых, на точность классификации может существенно влиять параметр Minimum... cases. В поле этого параметра выставляется число, ограничивающее минимальное количество объектов на ветке дерева решений. Чем меньше будет это число, тем более «кустистым» станет дерево и тем точнее производится «подгонка» дерева под требуемую классификацию.
Перекрестная проверка
Для получения надежных оценок качества построенных классификаторов в системе See5 используется так называемая перекрестная проверка. Она осуществляется следующим образом.
Вся выборка объектов разбивается на т блоков примерно одного размера и с одинаковым распределением классов. Затем последовательно каждый блок используется как контрольный набор объектов для тестирования классификатора, построенного на основе внешних для данного блока объектов. Число блоков вводится в поле crossvalidate диалогового окна для задания опций алгоритма конструирования классификатора. Результат перекрестной проверки отображается в нижней части окна отчета.