

Детальная проверка и сохранение результатов
Завершающая стадия работы с See5 обычно заключается в детальном просмотре результатов работы построенного классификатора в окне перекрестных ссылок. После нажатия соответствующей кнопки (Cross-Reference) на экране появляется диалоговое окно, в котором предлагается выбрать файл с данными для классификации (рис. 12). Это может быть исходный файл данных (в нашем случае USR.data), файл с тестовыми данными (USR.test) или файл, содержащий объекты с неизвестной классификацией (USR.cases).
В Рис. 12. Выбор файла
данных для классификации ыбрав
требуемый файл, нажимаем ОК. На экране
появляется окно перекрестных ссылок,
в левой половине которого сначала
изображено полное дерево решений, а в
правой представлен список объектов,
подвергнутых классификации. Некоторые
возможности работы с окном перекрестных
ссылок обсуждались выше. Здесь остановимся
еще на двух в
ыбрав
требуемый файл, нажимаем ОК. На экране
появляется окно перекрестных ссылок,
в левой половине которого сначала
изображено полное дерево решений, а в
правой представлен список объектов,
подвергнутых классификации. Некоторые
возможности работы с окном перекрестных
ссылок обсуждались выше. Здесь остановимся
еще на двух в
Первая заключается в возможности поэлементного просмотра для выбранного объекта ветви построенного дерева решения. Для этого нужно щелкнуть левой кнопкой мыши в правом поле окна перекрестных ссылок на требуемом объекте—в левом поле автоматически отобразится соответствующая ветка. Так, в случае, показанном на рис. 13, для изучения был выбран объект № 4 (около него появился темный кружок). Как видим, с этим объектом соотносится достаточно короткая ветка решения (Index<=0,69&Age>43&Accel<=85). Аналогичным образом можно разобрать результаты классификации всех других доступных объектов (нажатием кнопки Reset возвращается исходное изображение полного дерева решений).
Вторая возможность заключается в сохранении полученных результатов. Причем здесь существенным является выборочное сохранение. А именно, после нажатия кнопки Save, расположенной в правом нижнем углу окна перекрестных ссылок, сохраняться в текстовом формате будут только результаты, относящиеся к текущему отображению дерева решений (целиком или его части).
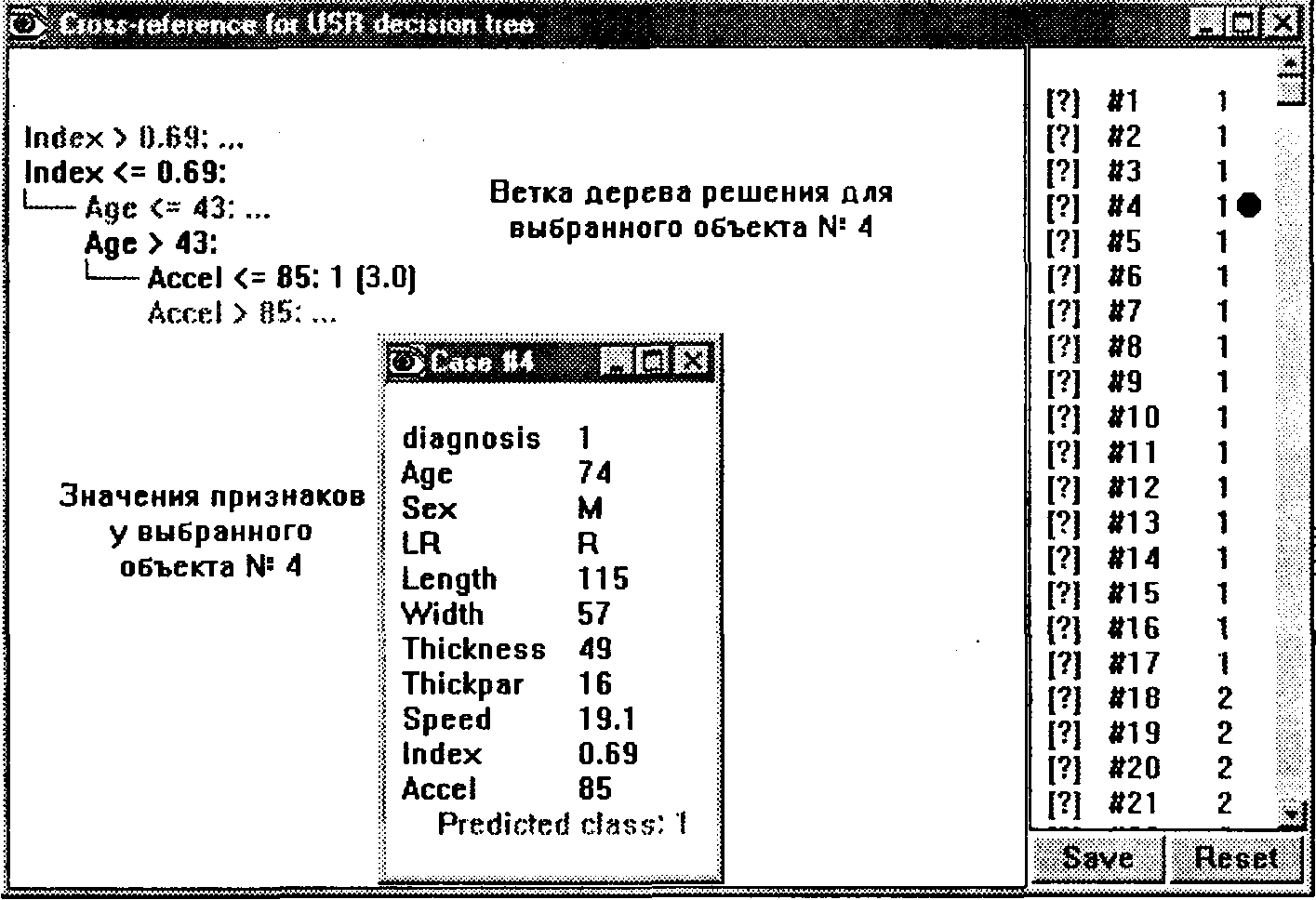
Рис.
5.20. Просмотр результатов классификации
в окне перекрестных ссылок
3 Задание на лабораторную работу
Изучить процесс построения деревьев решений в системе See5, выполнив приведенный в описании пример (файл URS.data и URS.names).
Самостоятельно провести анализ данных для примера по урожайности сельскохозяйственных участков (файл Example1). Анализ включает в себя этапы:
подготовку данных
Построение деревьев решений с целью выявления зависимостей типа «Если – То»
Сделать выводы по полученным результатам
Для полученного варианта задания выполнить вручную письменно построение дерева решений и извлечение правил с помощью алгоритма CLS.
Изучить процесс построения деревьев решений в системе Tree Analyzer и выполнить построение дерева для примера.
Сравнить результаты (деревья решений и правила), полученные с помощью системы Tree Analyzer и системы See5/C5. Сделать выводы.
Примечания.
Правила подготовки данных для работы в системе See-5 Вариант 1
Данные файла Example1.xls скопировать в новый файл. Преобразовать эти данные: создать столбец «класс» (класс А-№1, класс В - №2), удалить столбцы «урожайность» и «номер объекта».
Сохранить с расширением .csv (CSV разделители запятые
Открыть файл в Word (кодировка Unicode UTF-8). Произвести замену: «,» - на «.» и «;» - на «,».
Запомнить файл как текстовый (кодированный текст .txt).
Изменить расширение файла .txt на .data (если нет разрешения, то: «Вид», «Свойства папки», «Вид», отменить «не показывать расширения …»).
Создать в Word файл имен переменных в соответствии с требованиями, описанными в методичке.
Задать этому файлу расширение .names. Данные готовы.