

3.3. Класифікація на основі дискримінантної функції
З-поміж методів розпізнавання образів особливе місце посідає дискримінантний аналіз. На відміну від кластерного аналізу дискримінантний не утворює нових класів, а допомагає виявити різницю між існуючими класами і віднести новий (нерозпізнаний) об’єкт до одного з них за принципом максимальної схожості. Наприклад, банк, спираючись на певну систему характеристик фінансового стану клієнтів, які звертаються за позиками, класифікує їх на дві категорії: надійні та ненадійні. Дискримінантний аналіз використовується в медичній діагностиці, при визначенні ризику відмови приладів у технічних системах тощо. Основна проблема — звести помилку класифікації до мінімуму.
Дискримінантна функція — це лінійна комбінація певної множини ознак, які називаються класифікаційними і на основі яких ідентифікуються класи. Особливість дискримінантної функції полягає в тому, що класи представляються шкалою найменувань, а класифікаційні ознаки хі, де і = 1, 2, …, m, вимірюються метричною шкалою. Кількість останніх не може перевищувати (n – 2), де n — обсяг сукупності. Функціонально зв’язані та висококорельовані ознаки до ознакового простору моделі не включаються.
Дискримінантна функція fj визначається для кожного j-го класу (j = 1, 2, …, p):
![]() ,
,
де аіj — коефіцієнт функції (змістовної інтерпретації не має);
![]() — середнє
значення і-ї
ознаки в j-му
класі.
— середнє
значення і-ї
ознаки в j-му
класі.
Коефіцієнти функції аіj можна розрахувати за формулами [16, c. 113]:
![]() ,
,
де
bik
— елемент
матриці, оберненої до внутрішньогрупової
матриці сум попарних добутків
![]() ;
;
константа
![]() .
.
У геометричній інтерпретації fj — це уявна точка m-вимірного Евклідового простору, координатами якої є середні значення класифікаційних ознак j-го класу. Значення fj для p класів розглядаються як центри їх тяжіння і називаються центроїдами.
Процедура класифікації ґрунтується на геометричній близькості h-ї одиниці (з координатами значень ознак хih) до центроїдів виділених класів. Належність її до того чи іншого класу визначається на основі відстані Махаланобіса, яку можна записати так:
![]() .
.
Дискримінантна функція максимізує різницю між класами і мінімізує дисперсію всередині класу. Критерієм оптимального поділу сукупності на класи є максимум відношення міжкласової варіації до внутрішньокласової.
Міжкласову
варіацію характеризує квадрат різниці
центроїдів
![]() ,
а внутрішньокласову — середній квадрат
відстаней між
точками,
що належать j-му
класу хіjh,
і центроїдами цих класів f
j:
,
а внутрішньокласову — середній квадрат
відстаней між
точками,
що належать j-му
класу хіjh,
і центроїдами цих класів f
j:
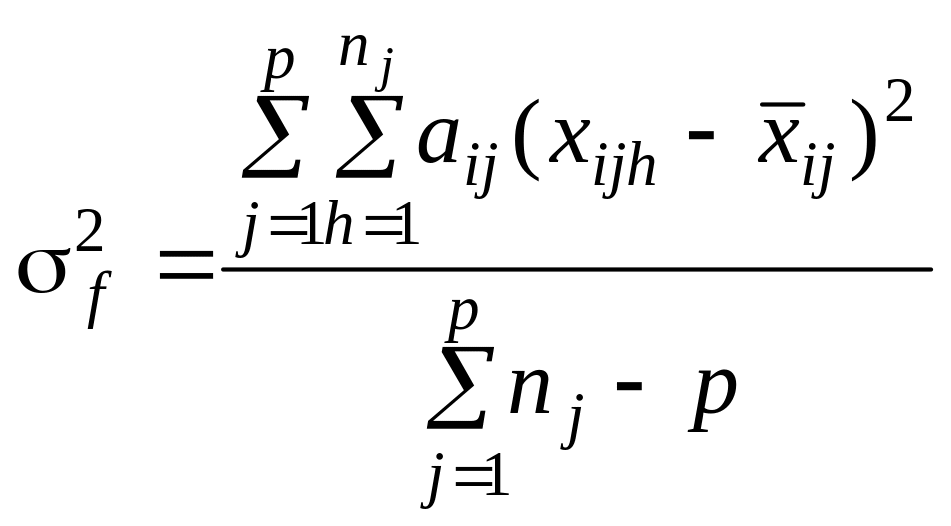 ,
,
де nj — кількість одиниць j-го класу.
Отже, критерій оптимального поділу на класи можна представити відношенням
 ,
,
яке називають узагальненою міжкласовою відстанню Махаланобіса.
Для оцінювання спроможності дискримінантної функції розпізнавати класи у багатовимірному ознаковому просторі використовують також λ-статистику Вілкса (Wilks lambda):
![]() ,
,
де λj — властиві значення матриці коваріацій.
λ-статистика враховує як відмінності між класами, так і однорідність кожного класу. Оскільки λ розраховується як обернена величина, то чим більше різняться центроїди, тим менше її значення, і навпаки, якщо центроїди збігаються, то λ прямує до 1. Отже, близькі до 0 значення λ свідчать про високу розпізнавальну спроможність дискримінантної функції. Істотність різниці значень центроїдів перевіряється також за допомогою критерію χ² чи дисперсійного F-критерію, які функціонально зв’язані з λ-статистикою.
У системі Statistica процедури дискримінантного аналізу об’єднані в модулі Discriminant Analysis — Дискримінантний аналіз. Порядок використання модуля розглянемо на умовному прикладі професійної психодіагностики, методика якої передбачає дискримінацію претендентів на заміщення вакансій на дві групи: відповідають (група С) і не відповідають (група NC) вимогам професії. Діагностичні ознаки: VAR2 — оперативна пам’ять, VAR3 — концентрацiя уваги. Значення цих ознак у балах наведено в табл. 3.9.
Таблиця 3.9
|
VAR1 |
VAR2 |
VAR3 |
1 |
C |
72 |
75 |
2 |
C |
57 |
70 |
3 |
C |
59 |
62 |
4 |
C |
67 |
72 |
5 |
C |
75 |
59 |
6 |
C |
62 |
73 |
7 |
NC |
67 |
50 |
8 |
NC |
56 |
59 |
9 |
NC |
58 |
54 |
10 |
NC |
47 |
60 |
За командами на стартовій панелі модуля проведемо селекцію ознак: незалежні (independent variable list) — VAR2 та VAR3; ідентифікатор груп (grouping variable) — VAR1; вкажемо метод аналізу — Standart. За результатами аналізу в інформаційній частині діалогового вікна вказується кількість класифікаційних ознак, значення λ-статистики та F-критерію:
Discriminant Function Analysis Results
Number of variables in the model: 2
Wilks'Lambda:,270128 approx.F(2,7)=9,45681 p < ,01024.
З
Таблиця 3.10
Classification Functions;
grouping: VAR1 (new. sta)
Continue…
C
p = ,60
NC
p = ,40
VAR2
1,9867
1,6938
VAR3
2,9689
2,4539
Constant
–167,0933
–117,5931
Установки аналізу Distances between groups і Squared Mahalanobis distances визначають міжкласову та внутрішньокласові відстані. Так, узагальнена міжкласова відстань Махаланобіса становить 11,258. Відстані окремих одиниць сукупності до центроїдів груп наведено в табл. 3.11. Частка правильно класифікованих одиниць сукупності становить 90 % (одна неправильно класифікована одиниця маркірована).
Таблиця 3.11
Squared Mahalanobis Distances from Group Centroids (new.sta) |
|||
Incorrect classifications are marked with * |
|||
Continue… |
Observed Classif. |
C p =,600 |
NC p =,400 |
1 |
C |
3,180 |
22,786 |
2 |
C |
1,227 |
6,898 |
*3 |
C |
3,051 |
1,653 |
4 |
C |
0,586 |
14,174 |
5 |
C |
3,140 |
8,023 |
6 |
C |
0,616 |
12,305 |
7 |
NC |
11,076 |
2,004 |
8 |
NC |
6,560 |
0,315 |
9 |
NC |
10,313 |
0,090 |
10 |
NC |
12,275 |
1,789 |
Нові, нерозпізнані об’єкти відносяться до того класу, для якого індивідуальні значення дискримінантної функції більші. Скажімо, в нашому прикладі новий претендент на заміщення вакансії набрав 65 балів по тесту «оперативна пам’ять» і 68 балів по тесту «концентрація уваги». Значення дискримінантної функції для групи С становить 163,957, для групи NC — 159,39. Оскільки перше значення функції більше, то претендент належить до групи С.
Розглянуту процедуру класифікації можна використати й тоді, коли кількість класів m > 2. Важливо, щоб кількість одиниць у кожному класі була не менша 2. Іноді метою дискримінантного аналізу є не віднесення об’єктів до того чи іншого класу, а визначення апостеріорних імовірностей належності до цих класів. Результати такого аналізу дає установка Posterior Probabilities.