

1. Понятие структуры данных. Физическая и логическая структура данных. Структура данных – множество элементов и связей. Физическая - способ представления данных в памяти машины. Абстрактная - когда данные рассматриваем без учета ее представления в машине.
2. Понятие типа данных. Классификация типов данных в языке СИ. Классификация типов данных: простые – символьные, целые, перечисляемые, булевые или логические, с плавающей точкой, пустой. Сложные – массивы, функции, указатели, структуры, объединение.
3. Простые типы данных языка СИ. Простые – которые не могут быть расчленены на составные части больше чем на бит. Символьные значения или знаки (character), целые (integer), перечисляемые типы (enumeration), булевые или логические значения (bool), с плавающей точкой (floating point), пустой тип (void).
4. Массивы, структуры и объединения языка СИ. Массив – это совокупность элементов одного типа, которые расположены в памяти ЭВМ подряд, один за другим. Структура – это составной объект, в котором под одним именем объединяются элементы одного или разных типов. Элементы структуры переменные, массивы, указатели, объединения и др. виды. Объединения подобны структуре , но в отличии от структуры в каждый момент времени можно использовать только один из его компонентов (union).
5. Битовые поля в языке СИ. Структуры могут создать битовое поле. Тип <имя>: ширина поля; Типы:Char, Unsingchar, Int, Unsingint Если имя битового поля упущено, то мы не можем обратиться к нему, но ширина будет зарезервирована в памяти. Если ширина равна нулю, то следующее поле будет начинаться со следующего слова памяти. Битовые поле задается следующим образом: тип <имя поля>: ширина битового поля (в битах). Если имя битового поля опущена, а число бит задано, то битовое поле размещается в памяти, но доступа к битовому полю не будет. Если ширина битового поля равна нулю, то следующее поле будет начинаться со следующего поля в памяти.
6. Указатели (определение, операции над указателями). Указатели – объект заданного типа, который содержит адрес другого объекта. Объявить : тип * <имя указателя>. Операции над указателями: «++» - инкремент, «--» - декремент, «-», «+», «<», «>», «>=», «<=», «==», «!=».
7. Динамические объекты в языке СИ (понятие, функции выделения и освобождения памяти, время жизни динамического объекта, указание на произвольную ячейку памяти).
Динамический объект в отличие от заранее определенных создаются в процессе выполнения программ, а так же могут быть уничтожены так же в процессе программы. Для создания динамических объектов существует 2 типа функции: char*mallos,char *callos, size - определяет объем памяти, который нужно выделить создавая динамический объект. Elsize – определяет объем памяти, который нужно выделить под каждый элемент. Обе эти функции возвращают указатель на созданный динамический объект, а именно на участок в памяти, в котором находится динамический объект.
8. Связь между указателями и массивами. Массивы и указатели символьных строк. Указатели и структуры.
Имя массива – это указатель на его первый элемент. Int mass [] или int *mass. Обратиться ко второму элементу массива напрямую mass[1]=2. *(указатель + индекс), например: *(р+1)=2 – с помощью указателя. К многомерным массивам int mass[4][2]; int *p; p=mass;. Массивы и указатели различия: имя массива в отличии от просто указателя, это указатель типа константа. Соответственно мы не можем совершать операции инкремент, декремент. Например: char st1 [10][20]; char *2 [10]; char st1 [3][7]={«Яблоко», «Слива», «Груша»}; char *st2[3]= {«Яблоко», «Слива», «Груша»}; Указатели и структура: struct student { char name[25]; int age; char sex;};
9. Оператор описания типа. Операторы определения и описания в языке СИ. Оператор типа используется, чтобы все свойства какого-либо объекта собрать в одном месте и присвоить им имя. И это имя может использоваться для описания других объектов. Typedef _ спецификатор _ имя нового типа. Например: typedef struct {float x,y} point.
10. Классы памяти в языке СИ. Класс памяти (может отсутствовать) _ тип данных _ имя объекта (определяемого). Все объекты имеют имена. Каждое имя объекта, который мы определяем характеризуется двумя свойствами временем жизни и областью действия. Время жизни – определяет период в течение, которого имени объекта соответствует конкретная область памяти. Область действия – часть программы, в которой имя объекта может быть использовано для доступа к связанному к ним участку памяти. Существуют 4 класса памяти:
1.auto - автоматически выделяемая локальная память, при определении с таким классом памяти, память определяется только при входе в блок, при выходе память освобождается. Всем объектам в блоке присваивается класс памяти auto.
2. Register (подобен auto) для размещения объекта используется регистровая память, если все регистры заняты будет использоваться основная память.
3. Static – объект с таким классом памяти существует в пределах всех блоков программ, в пределах одного файла. Память выделяется в начале программы. В отличие от auto память выделяется один раз и после этого она занята пока не выполнится программа.
4.extern доступен во всех блоках, всех файлов программы.
1 1.
Преобразование
типов в языке СИ (явное и неявное).
неявные
преобразования
– применяются для согласования аргумента,
операторов, или функции со значением ,
которые предполагаются в этих функциях.
Неявное присваивание - тип значения,
которое присваивается, преобразуется
к типу переменной, получающей это
значение (int
a;
long
b;
a=3;
b=2;).
Int
char,
short,
long.
Char
int,
short,
long.
Short
– аналогично int.Схема
преобразования типов арифметических
преобразований: 1.опреанды типа char
и short
– int.
2. Если хотя бы один операнд имеет тип
double
(int,
long),
то результат будет тоже с типом double(int,
long).
Явное
преобразование
типов делается посредством операции
приведения типов (cast),
которая имеет две формы: (имя_типа)
операнд – традиционная
форма, имя_типа
(операнд)
– функциональная форма, здесь имя_типа
задает
тип, а операнд
является
величиной, которая должна быть
преобразована к заданному типу. Во
второй форме имя_типа
должно быть просто идентификатором,
например полученным с помощью typedef.
Присваивание в явном виде: int
i=2;
long
l=3;
1.
Преобразование
типов в языке СИ (явное и неявное).
неявные
преобразования
– применяются для согласования аргумента,
операторов, или функции со значением ,
которые предполагаются в этих функциях.
Неявное присваивание - тип значения,
которое присваивается, преобразуется
к типу переменной, получающей это
значение (int
a;
long
b;
a=3;
b=2;).
Int
char,
short,
long.
Char
int,
short,
long.
Short
– аналогично int.Схема
преобразования типов арифметических
преобразований: 1.опреанды типа char
и short
– int.
2. Если хотя бы один операнд имеет тип
double
(int,
long),
то результат будет тоже с типом double(int,
long).
Явное
преобразование
типов делается посредством операции
приведения типов (cast),
которая имеет две формы: (имя_типа)
операнд – традиционная
форма, имя_типа
(операнд)
– функциональная форма, здесь имя_типа
задает
тип, а операнд
является
величиной, которая должна быть
преобразована к заданному типу. Во
второй форме имя_типа
должно быть просто идентификатором,
например полученным с помощью typedef.
Присваивание в явном виде: int
i=2;
long
l=3;
12. Основные операции над данными в языке си (операция присваивания, арифметические операции).
основные операции над данными в языке си(операции присваивания, арифметические операции).операции присваивания «=».c=t. выполняется слева направо, левый операнд адресное выражение, но не постоянная. Арифметическими операциями являются + - * / %.при делении целых дробная часть отбрасывается. Операция а%в применяется только к целым операндам и дает остаток от деления а на в.н-р: 10%3=1
13. Основные операции над данными в языке СИ (операция над битами, операции отношения, логические операции, операция условия).
Основные операции над данными в языке СИ (операция над битами, операции отношения, логические операции, операция условия).Операции отношения < > => <= все они имеют одинаковое старшинство. За ними следуют операции (не)равенства == != операции отношения младше арифметических операций. операция сравнения определяет некоторое выражение. если условие выполняется, то 1, в противном-0.Логические опер. ! отриц&&конъюнкция ||дизъюнкция. Любых типов. вычисляются слева направо. результатом лог.опер.является или 1 или 0.приоритет ! && ||Побитовые.& и, | или, ^ исключающ. или, палочка приближенно равно-отрицание, << >> операции сдвигов. Любого целого типа. Операции условия. Операнд1 ? операнд2: операнд3.первый операнд может быть целого или плавающего типа для операции важно, является значение его 0 или нет. если операнд 1 не равен 0,то вычисляется операнд2, и его значение является результатом операции. если равен 0,то вычислятся операнд3, и его значение является результатом операции. вычисляется либо оп2, либо оп2, но не оба! Н-р: max=a<=b? b:a;если в условной операции оп2 и оп3 являются адресными выражениями, то тернарная операция может стоять слева от знака присваивания: a<b? a:b=c*x+d; здесь значение выражения c*x+d присваивается меньшей из двух переменных a и b
14. Пустой оператор в языке СИ.
Пустой оператор состоит из «;» он используется там, где по правилам языка должен находиться к-л оператор, а по логике программы там ничего выполнять не надо
15. Функции пользователя: понятие, операторы определения, описания и вызова функции. Формальные и фактические параметры.
Функция – самостоятельная единица программы, спроектированная для реализации конкретной задачи. Типичное определение функции имеет следующий вид: тип имя (список аргументов) // – заголовок функции { тело функции} Переменные, отличные от аргументов, описываются внутри тела функции, которое заключается в фигурные скобки. Вначале указывается заголовок функции, затем идёт открывающая фигурная скобка, приводится описание используемых переменных, даются операторы, определяющие работу функции, и, наконец, закрывающая фигурная скобка. Обратите внимание, что за заголовком функции не следует символ "точка с запятой"; его отсутствие служит указанием компилятору, что здесь определяется функция, а не используется. Аргументы, передаваемые в функцию при вызове, называются фактическими параметрами, а аргументы, перечисленные в заголовке функции при её описании, называются формальными параметрами. Формальные и фактические параметры должны согласовываться по количеству, порядку следования и типу. Переменные, известные только одной функции, а именно той, которая их содержит, называются локальными переменными; они действуют только в пределах этой функции. Наличие переменных, известных нескольким функциям - глобальные. Переменная является глобальной, если она описана вне тела какой-либо функции. Обычно глобальные переменные описываются в самом начале, сразу после команд препроцессора. Пример: #include <stdio.h> float a[10][20]; //массив описан как глобальный void my_func() { float b[10]; //массив описан как локальный b[0] = 0; a[0][0] = 0; ...} void main () { my_fuc(); printf("a00 = %f\n",a[0][0]); //правильно, т.к. используется //элемент массива а, описанного глобально printf("b0 = %f\n",b[0]); //неправильно, т.к. массив b здесь просто // "неизвестен" (он известен только внутри функции my_funk()!)} Таким образом, с помощью оператора return в вызывающую функцию можно передать только одну величину. Так как в языке Си при обращении к функции через параметры передаются конкретные значения соответствующих аргументов, то вернуть полученные значение через аргументы, перечисленные в заголовке функции, просто так не удастся. Если в вызывающую функцию требуется передать (вернуть) более чем одно значение, необходимо в качестве аргументов использовать указатели.
16. Изменение переменных в функции из других функций. Передача массивов в качестве параметра.
обмен:
Void swap(int *a, int*b)
{ int temp;
Temp=*d;
*a=*b
*b=temp
}
Main(0
{ int a, b;
A=3;
B=1
Swap(&a,&b)
}
Предать массив в функцию можно через его имя.имя-указатель на первый элемент.
Void mass (int n, float A[20])
{ int i
For (i=0; i<n; i++);
Scanf («%f», &A[i]);
}
Main ()
{
Float A[20]
B[20];
Int c,d;
Mas(c,A);
Mas(d,B);
17. Рекурсивный вызов функции пользователя.
Рекурсивные вызовы функций- функция вызывает сама себя. Массивы могут быть использованы в качестве формальных параметров. Во многих случаях рекурсивные функции можно заменить на эквивалентные нерекурсивные функции или фрагменты, используя стеки для хранения точек вызова и вспомогательных переменных.Void(int A[10]) int j=0 {def scanf(“%d”,A[i]}
18. Функции с переменным количеством параметров, перегрузка функций, передача функций в качестве параметров.
Тип функции имя(явные параметры,….)
{ тело функции
}
Long summa (int k,..)
{
Int*p=&k;
For(;k;k- -) t=t+*(++p);
Return t;
}
Main()
{ long r,p;
R=summa(2,4,6);
P=summa(1,2,3,4,5);
}
19. Что такое препроцессор. Директивы препроцессора (define, error, условной компиляции) языка СИ.
Препроцессор - программа, выполняющая обработку данных для другой программы. Препроцессор языка си рассматривает программу до компиляции. Директива #include включает в текст программы содержимое указанного файла. Эта директива имеет две формы: #include "имя файла" #include <имя файла>. Если имя файла указано в кавычках, то поиск файла осуществляется в соответствии с заданным маршрутом, а при его отсутствии в текущем каталоге. Если имя файла задано в угловых скобках, то поиск файла производится в стандартных директориях операционной системы, задаваемых командой PATH. Директива #include может быть вложенной, т.е. во включаемом файле тоже может содержаться директива #include, которая замещается после включения файла, содержащего эту директиву. Директива #define служит для замены часто использующихся констант, ключевых слов, операторов или выражений некоторыми идентификаторами. Идентификаторы, заменяющие текстовые или числовые константы, называют именованными константами. Директива #define имеет две синтаксические формы: #define идентификатор текст #define идентификатор (список параметров) текст Эта директива заменяет все последующие вхождения идентификатора на текст. Такой процесс называется макроподстановкой. Текст может представлять собой любой фрагмент программы на СИ, а также может и отсутствовать. В последнем случае все экземпляры идентификатора удаляются из программы. Пример: #define WIDTH 80 #define LENGTH (WIDTH+10) Во второй синтаксической форме в директиве #define имеется список формальных параметров, который может содержать один или несколько идентификаторов, разделенных запятыми. Формальные параметры в тексте макроопределения отмечают позиции на которые должны быть подставлены фактические аргументы макровызова. Каждый формальный параметр может появиться в тексте макроопределения несколько раз. Директива #undef используется для отмены действия директивы #define. Синтаксис этой директивы следующий #undef идентификатор Директива отменяет действие текущего определения #define для указанного идентификатора. Не является ошибкой использование директивы #undef для идентификатора, который не был определен директивой #define. Пример #undef WIDTH #undef MAX Эти директивы отменяют определение именованной константы WIDTH и макроопределения MAX.
20. Отразить сущность применения численных методов (схема вычислительного эксперимента с пояснениями).
Объект исследованияФизическая модель объектаМатематическая модельЧисленные методы (дискретная модель+вычисл.алгоритма) ( здесь схема поворачивает вниз) компьютерная программа(поворот налево) проведение вычислительного эксперимента. Анализ результатов. И замыкается схема. Дискретная модель должна соответствовать математической модели и быть адекватной. Должен быть корректным и реализуемым на компьютере.
21. Численные методы решение алгебраических уравнений: постановка задачи, табличный способ отделения корней.
Во многих научных и инженерных задачах возникает необходимость решения уравнений вида:F(x,p1,p2,..,pn)=0 где F - заданная функция, x - неизвестная величина, p1 ,p2 ,..pn - параметры задачи. Решениями или корнями уравнения (2.1) называются такие значения х, которые при подстановке в уравнение обращают его в тождество. Только для простейших уравнений удается найти решение в аналитическом виде, т.е. записать формулу, выражающую искомую величину х в явном виде. В большинстве же случаев приходится решать уравнение вида (2.1) численными методами. Хотя иногда, даже при наличии аналитического решения, имеющего сложный вид, бывает проще провести численное решение по известному алгоритму, чем программировать громоздкую аналитическую формулу. Численное решение уравнения (2.1) обычно проводят в два этапа. На первом этапе необходимо определить интервал изменения переменной х, где расположен один корень или, что означает то же самое, определить достаточно хорошее приближение окрестности этой точки. На втором этапе тем или иным численным методом определяется величина х, соответствующая корню уравнения (2.1) с заданной погрешностью. Для решения второй задачи существуют многочисленные методы метод половинного деления; метод Ньютона; метод секущих. Уравнение могут быть алгебр, транцендент..вычислим ряд значений левой части уравнения и результат вмещаем в таблицу, по которой можно построить график.1.вводим границы и шаг изменения2.циклически изменяем аргумент с шагом h.3.вычисляем левую часть выражения4.анализируем на каком из интервалов находится корень
22. Численные методы решение алгебраических уравнений: метод половинного деления. Численные методы решение алгебраических уравнений: метод половинного деления/ Для применения метода половинного деления необходимо установить окрестность или отрезок [a, b], на котором расположен один из корней уравнения, который необходимо уточнить с погрешностью Е .
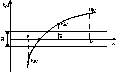
Пусть дано уравнение f(x)=0, где f(x) непрерывна на отрезке [a, b] и f(a)*f(b)<0/Метод половинного деления, или дихотомии, заключается в следующем. Для нахождения корня уравнения, принадлежащего отрезку [a, b], делим отрезок пополам, т.е. выбираем начальное приближение, равное:
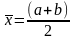
и
вычисляем значение функции
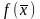 .
Если
.
Если
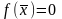 ,
то
,
то
 является корнем уравнения. Если
является корнем уравнения. Если
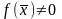 ,
то выбираем, одну из двух частей отрезка
,
то выбираем, одну из двух частей отрезка
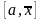 или
или
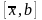 для дальнейшего уточнения корня.
Естественно, что корень будет находиться
в той половине отрезка, на концах которого
функция
для дальнейшего уточнения корня.
Естественно, что корень будет находиться
в той половине отрезка, на концах которого
функция
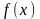 имеет разные знаки, а именно проверяем
условие:
имеет разные знаки, а именно проверяем
условие:
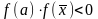 .
На рис.2.1 это будет отрезок
,
т. е. для очередного шага уточнения точку
b перемещаем в середину отрезка
.
На рис.2.1 это будет отрезок
,
т. е. для очередного шага уточнения точку
b перемещаем в середину отрезка
 (b=
)
и продолжаем процесс деления как с
первоначальным отрезком [a, b].
(b=
)
и продолжаем процесс деления как с
первоначальным отрезком [a, b].
Итерационный (повторяющийся) процесс деления будет продолжаться до тех пор, пока не будет выполнено условие:
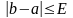 .
.
За приближенное решение принимается средняя точка последнего промежутка.
Таким образом, для реализации метода дихотомии необходимо:
Задать в явном виде уравнение f(x), корни которого необходимо определить.2/Определить начальный интервал [a, b], внутри которого лежит корень./3Задать точность нахождения корня уравнения f(x).4/Реализовать в программе итерационную процедуру, описанную выше.
23. Численные методы решение алгебраических уравнений: метод хорд. В этом методе очередное приближение к корню берется не в середине отрезка [a, b], а в точке x1, где хорда графика функции f(x), соединяющая точки f(a) и f(b), пересекает ось абсцисс В качестве нового интервала для продолжения итерационного процесса выбираем ту из двух частей ( [a, x1] или [x1, b] ) отрезка [a, b], на концах которого функция f(x) меняет знак. Процесс уточнения корня заканчивается, когда расстояние между очередными приближениями станет меньше требуемой погрешности ε вычислений: |x(n) − x(n−1)| < ε, или когда значения функции попадут в область шума, т.е. f (x) < ε1. Уравнение хорды в нашем случае имеет вид: y(x)=(f(b)-f(a))/(b-a)*(a-x)+f(a) откуда для x1 получаем: x(1)=a-(b-a)/(f(b)-f(a))*f(a) Метод хорд требует вдвое–втрое меньшего числа итераций, чем метод половинного деления, для отыскания корня с той же погрешностью. Однако, если функция f(x) в области пересечения с осью абсцисс достаточно пологая, то оче-
редная хорда может практически лечь на ось абсцисс, то есть полностью попасть в полосу шумов. В этой ситуации произойдет сильное увеличение ошибки вычислений, так как в (3) разность двух близких величин f(a)−f(b) стоит в знаменателе.В этом смысле метод половинного деления значительно устойчивее.