

Смешанные архитектуры
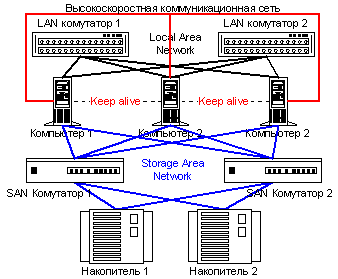 Рисунок
7. Высокоскоростной отказоустойчивый
кластер
Рисунок
7. Высокоскоростной отказоустойчивый
кластер
Сегодня часто можно встретить смешанные кластерные архитектуры, которые одновременно являются как системами высокой готовности, так и высокоскоростными кластерными архитектурами, в которых прикладные задачи распределяются по узлам системы.
Наличие отказоустойчивого комплекса, увеличение быстродействия которого осуществляется путем добавления нового узла, считается самым оптимальным решением при построении вычислительной системы.
Но сама схема построения таких смешанных кластерных архитектур приводит к необходимости объединения большого количества дорогих компонент для обеспечения высокого быстродействия и резервирования одновременно. И так как в High Performance кластерной системе наиболее дорогим компонентом является система высокоскоростных коммуникаций, ее дублирование приведет к значительным финансовым затратам.
Следует отметить, что системы высокой готовности часто используются для OLTP задач, которые оптимально функционируют на симметричных мультипроцессорных системах. Реализации таких кластерных систем часто ограничиваются 2-х узловыми вариантами, ориентированными в первую очередь на обеспечение высокой готовности. Но в последнее время использование недорогих систем количеством более двух в качестве компонент для построения смешанных HA/HP кластерных систем становится популярным решением.
Что подтверждает, в частности, информация агентства The Register, опубликованная на его страничке:
В ближайшее время Unіх сервера, на которых работает основная масса бизнес-приложений компании, будут заменены на блок серверов на базе процессоров Іntеl под управлением ОС Lіnuх. Введение поддержки кластеров при работе с приложениями и базами данных снижает затраты и повышает отказоустойчивость.
6.Средства реализации High Performance кластеров
Самыми популярными сегодня коммуникационными технологиями для построения суперкомпьютеров на базе кластерных архитектур являются:
Myrinet, Virtual Interface Architecture (cLAN компании Giganet - одна из первых коммерческих аппаратных реализаций), SCI (Scalable Coherent Interface), QsNet (Quadrics Supercomputers World), Memory Channel (разработка Compaq Computer и Encore Computer Corp), а также хорошо всем известные Fast Ethertnet и Gigabit Ethernet.
Рисунок 8. Скорость передачи непрерывного потока данных
Рисунок 9. Время передачи пакета нулевой длинны
Эти диаграммы (Рис. 8 и 9) дают возможность увидеть быстродействие аппаратных реализаций разных технологий, но следует помнить, что на реальных задачах и при использовании разнообразных аппаратных платформ параметры задержки и скорости передачи данных получаются на 20-40%, а иногда на все 100% хуже, чем максимально возможные.
Например, при использовании библиотек MPI для коммуникационных карточек cLAN и Intel Based серверов с шиной PCI, реальная пропускная способность канала составляет 80-100 MByte/sec, задержка - около 20 мксек.
Одной из проблем, которые возникают при использовании скоростных интерфейсов, например, таких как SCI является то, что архитектура PCI не подходит для работы с высокоскоростными устройствами такого типа. Но если перепроектировать PCI Bridge с ориентацией на одно устройство передачи данных, то эта проблема решается. Такие реализации имеют место в решениях некоторых производителей, например, компании SUN Microsystems.
Таким образом, при проектировании высокоскоростных кластерных систем и расчета их быстродействия, следует учитывать потери быстродействия, связанные с обработкой и передачей данных в узлах кластера.
Таблица 1. Сравнение высокоскоростных коммуникационных интерфейсов
Технология |
Пропускная способность MByte/s |
Задержка мксек/пакет |
Стоимость карточки/свича на 8 портов |
Поддержка платформ |
Комментарий |
Fast Ethertnet |
12.5 |
158 |
50/200 |
Linux, UNIX, Windows |
Низкие цены, популярная |
Gigabit Ethernet |
125 |
33 |
150/3500 |
Linux, UNIX, Windows |
Удобство модернизации |
Myrinet |
245 |
6 |
1500/5000 |
Linux, UNIX, Windows |
Открытый стандарт, популярная |
VI (сLAN от Giganet) |
150 |
8 |
800/6500 |
Linux, Windows |
Первая аппаратная промышленная реализация VI |
SCI |
400 |
1.5 |
1200/5000* |
Linux, UNIX, Windows |
Стандартизирована, широко используется |
QsNet |
340 |
2 |
N/A** |
True64 UNIX |
AlphaServer SC и системы Quadrics |
Memory Channel |
100 |
3 |
N/A |
True64 UNIX |
Используется в Compaq AlphaServer |
* аппаратура SCI (и программное обеспечение поддержки) допускает построение так называемых MASH топологий без использования коммутаторов
** нет данных
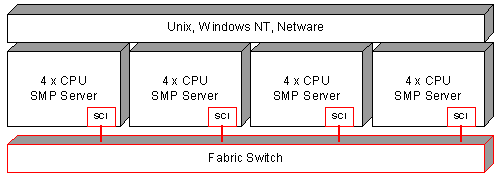 Рисунок
10. Тесно связанная мультипроцессорная
система с несимметричным доступом к
памяти
Рисунок
10. Тесно связанная мультипроцессорная
система с несимметричным доступом к
памяти
Одной интересной особенностью коммуникационных интерфейсов, которые обеспечивают низкие задержки, является то, что на их основе можно строить системы с архитектурой NUMA, а также системы, которые на уровне программного обеспечения могут моделировать многопроцессорные SMP системы.
Преимуществом такой системы является то, что вы можете использовать стандартные операционные системы и программное обеспечение, ориентированное на использование в SMP решениях, но в связи с высокой, в несколько раз выше по сравнению с SMP задержкой междупроцессорного взаимодействия, быстродействие такой системы будет малопрогнозируемо.